基于FPGA的全流水雙精度浮點矩陣乘法器設計
2012-09-24 13:45:08劉沛華魯華祥龔國良劉文鵬
智能系統學報 2012年4期
關鍵詞:設計
劉沛華,魯華祥,龔國良,劉文鵬
(中國科學院半導體研究所神經網絡實驗室,北京100083)
矩陣乘法是數字信號處理領域中的基本操作,廣泛應用于各種電路計算中,例如數字通信領域的DCM變換、快速FFT變換以及圖像處理中的3-D變換等都用到了大規模的矩陣乘法運算.由于矩陣乘法計算復雜性較高(通常為O(n3)),其計算性能直接影響到系統的整體性能.然而傳統的矩陣乘法多用處理器串行計算來實現,嚴重制約了計算速度.要提高矩陣乘法的計算性能,可以通過提升工作頻率和算法并行度來實現.現場可編程門陣列(field programmable gate array,FPGA)具有強大的計算性能和邏輯分析能力,特別是它具有并發式的硬件結構和出色的浮點計算性能,適合對矩陣乘法進行硬件加速,是當前的研究熱點.
目前,采用FPGA實現矩陣乘法計算的研究已經取得一些成果.在定點矩陣乘法方面,Amira等在FPGA上實現了8位定點的矩陣乘法器,但是該設計所需要的帶寬與矩陣規模成比例增加,限制了該設計的可擴展性[1];Jang等設計的矩陣乘法器只需要固定的帶寬,但是所需要的存儲單元大小與矩陣規模成正比[2].在浮點矩陣乘法方面,Campell等設計了一個并行結構矩陣乘法器,該設計中的各個計算單元之間不需要通訊,具有可擴展性,但其所需的存儲空間隨矩陣維數的增加而增大,并且計算效率不高[3];田翔等設計了一個實時雙精度矩陣乘法器,并在FPGA上完成了方案的實現,但是其計算單元的工作頻率不高,限制了計算性能的提升[4].
本文設計并在FPGA上實現了一個計算性能較高、可擴展性良好的并行雙精度浮點矩陣乘法器.為提高工作頻率,乘法器中的計算單元采用流水線結構,并運用C-slow時序重排技術解決了環路流水線上“數據相關沖突”的問題,提高了計算效率.此外,本設計所需要的帶寬和存儲單元大小都是固定的,故可擴展性好.
1 矩陣乘法器設計
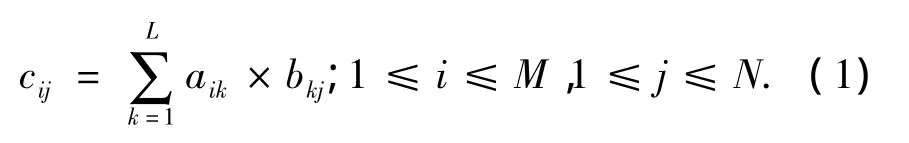
式(1)的計算復雜度為2×M×N×L,即O(n3).為降低算法復雜度,本文設計了一個包含P個處理單元(processing element,PE)的并行雙精度浮點矩陣乘法器,其中PE采用流水線結構,并運用C-slow時序重排技術解決環路流水線上“數據相關沖突”的問題,提高了計算效率.設計中所有操作數均為符合IEEE 754標準的64bit雙精度浮點數.
1.1 處理單元設計
PE是構成浮點矩陣乘法器的基本單元.每個PE包含一個浮點乘法器、一個浮點加法器和用于存儲計算結果的存儲單元(Shift register),其結構如圖1所示.
對于矩陣乘法C=A×B,其中A、B和C分別是M×L、L×N和M×N維矩陣,其計算方法如式(1):
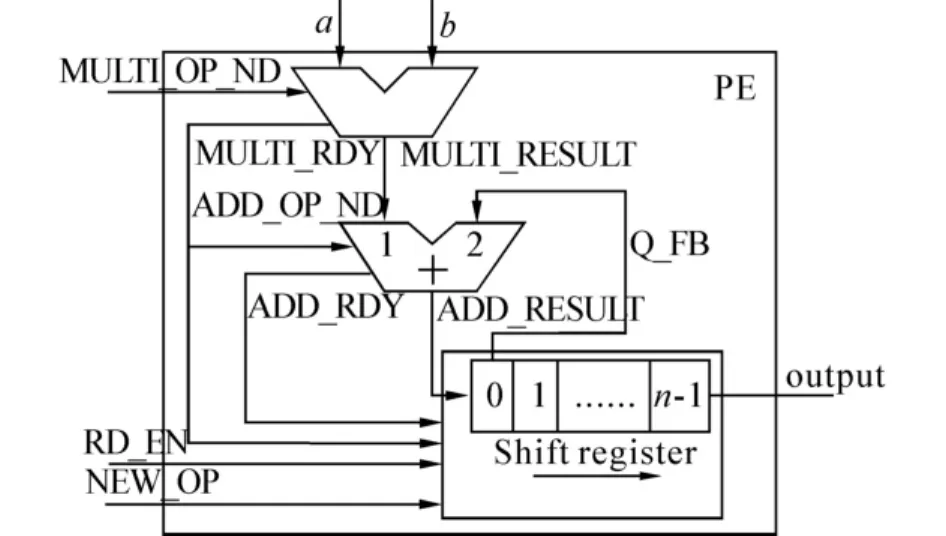
圖1 PE單元結構Fig.1 Structure of PE
圖1中信號分為2類:數據信號和控制信號.其中 a、b、MULTI_RESULT、ADD_RESULT、Q_FB 和output都是64 bit數據信號,其他都是控制信號,具體功能描述見表1.

表1 FPGA內部資源使用情況Table 1 Usage of FPGA internal resources
PE工作時,MULTI_OP_ND置高表示乘法器的輸入(a,b)有效,此時啟動乘法器,當浮點乘法器計算完畢時,MULTI_RDY輸出高電平表示MULTI_RESULT有效;當ADD_OP_ND變為高電平時啟動浮點加法器,當浮點加法器計算完畢時,ADD_RDY輸出高電平表示乘加過程結束.此外,MULTI_RDY和ADD_RDY還作為Shift register的控制信號,控制Shift register移位.當一組元素計算完畢之后,將輸入信號RD_EN置為高電平,讀取Shift register中存儲的結算結果;當需要計算新的元素時,將NEW_OP置為高電平,Shift register的寄存器全部清零,便可以進行新一輪的乘加運算.
1.2 環路流水線設計
為了提高計算吞吐率,整個PE采用流水線結構.與一般的結構相比,流水線結構能達到更高的時鐘頻率,但是輸出結果與輸入之間會有時鐘延遲,延遲的時鐘周期數等于流水線的級數.流水線的級數(Latency)越高,乘法器與加法器的工作頻率就越高.
對于無反饋回路的流水線結構來說,輸出結果相對輸入之間的延遲不會影響整個系統的順序執行.但是當流水線結構中存在反饋回路時,若不妥善解決延遲問題,流水線上就會出現“數據相關沖突”.以PE的數據通道為例,圖1中加法器端口2的輸入數據來自于上一次乘積累加操作的結果,這便構成了一個反饋回路,只有保證MULTI_RESULT到達加法器端口1的時間與上次乘累加的結果(Q_FB)到達端口2的時間一致,才能確保PE的正確運行.否則,必然導致流水線時序紊亂,無法完成給定的計算任務,這就是所謂的“數據相關沖突”.下面通過剖析圖2來闡述這個問題.
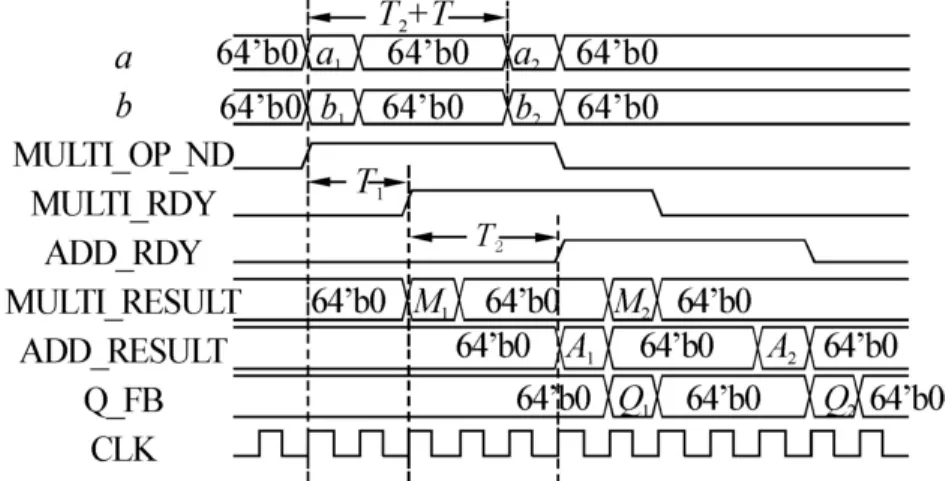
圖2 PE的時序波形Fig.2 Timing diagram of PE
如圖2所示,MULTI_RDY比MULTI_OP_ND延遲T1;ADD_RDY比 ADD_OP_ND(即圖2中的MULTI_RDY)延遲T2.設CLK的周期為T,浮點乘法器和浮點加法器的Latency值分別為u和v,則T1=uT,T2=vT.設某個計算元素c的前后2組輸入數據分別是 a1、b1和 a2、b2.開始計算時 Shift register的寄存器被全部清零,A1=a1b1+0,A1經過一個寄存器延遲得到 Q1;同樣,M2=a2b2.由圖2可以看出,只有當a2、b2和a1、b1之間保持v+1個時鐘周期的延遲時(T2+T=(v+1)T),才能保證M2和Q1同時到達浮點加法器2個輸入端口,進而得到正確的累加結果:A2=Q1+M2.否則,就會導致M2和Q1到達浮點加法器輸入端口的時間不一致,發生“數據相關沖突”,無法得到正確的計算結果.

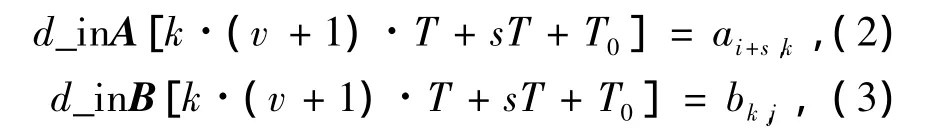
式中:T0為計算的起始時間,d_inA[t]、d_inB[t]分別表示 t時刻 a、b 端口的輸入數據,1≤k≤L,0≤s≤v.由式(2)、(3)可知,上述操作的目的是把求解cij,ci+1,j,…,ci+v,j這 v+1 個計算任務交叉編排在一條流水線上執行.同時,上述操作能保證對于cij的計算任務而言,前后2組輸入數據保持v+1個時鐘周期的延遲,而且不同cij的輸入數據不發生重疊.所以,這樣一條流水線上能完成v+1計算任務的交叉執行,即一個PE單元花費L(T2+T)時間能完成cij,ci+1,j,…,ci+v,j的 v+1 個元素的求解過程.從而,圖 1所示的shift register需要v+1個寄存器來存儲計算結果,即n=v+1.
1.3 并行結構矩陣乘法器設計
根據矩陣乘法的簡單并行算法,在FPGA芯片上實現P個PE單元,這些PE單元按照圖3所示的1×P陣列形式排列.PE單元之間不存在信息交互,它們獨立地完成各自的計算任務.由式(2)和(3)可知,每個PE單元進行計算時要用到A的n行和B的某1列數據,整個PE陣列一次計算需要用到A的n行和B的P列數據.將輸入矩陣A、B分別按行和按列進行分塊:A=[AT1AT2… ATM]T,B=[B1B2…BN],其中Ai表示A的第i行,Bj表示B的第j列.將A的n行和B的P列作為圖3所示系統的輸入,圖中預處理模塊1和預處理模塊2的功能分別對Ai和Bj進行處理,使得它們分別滿足式(2)和(3)中d_inA[t]、d_inB[t]的要求并將其送入各個 PE單元的a、b端口進行計算.
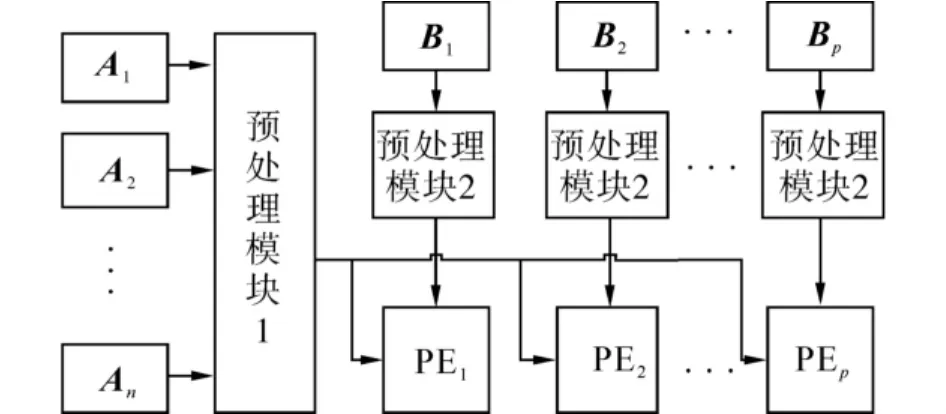
圖3 并行矩陣乘法器結構Fig.3 Timing diagram of PE
通過這種PE的陣列結構,可以完成任意維數的矩陣乘法運算.假設A和B分別為M×L、L×N維矩陣,對于任意的M、N和L值,可以通過下述算法計算C=A×B的結果:
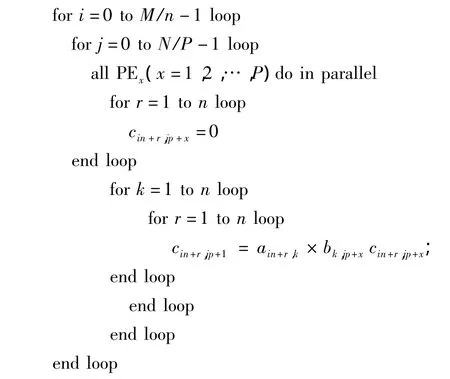
從以上算法可以看出,使用并行矩陣乘法器進行計算時,循環的次數是傳統串行算法的1/P,即計算復雜度降低為O(n3/P).同時由于該并行矩陣乘法器中的各個PE單元是相互獨立的,因此可以方便地擴展到多片FPGA上實現并行計算.
2 矩陣乘法器性能分析
下面以在FPGA上實現的并行矩陣乘法器來對上述設計的性能進行分析.本文選用Xilinx Virtex-5 LX155芯片實現該設計.PE中的浮點乘法器和浮點加法器使用Xilinx公司提供的floating-point IP核生成.通過對運行速度及該器件中DSP48E單元、CLB單元等資源進行綜合考慮,對并行矩陣乘法器進行如下設置:1)IP核生成浮點乘法器時,DSP48E的使用等級設置為Medium Usage(即單個浮點乘法器使用9個DSP48E單元),Latency的值設定為15;2)IP核生成浮點加法器時,DSP48E的使用等級設置為No Usage,Latency的值設定為9;3)設定矩陣乘法器中PE單元的個數P=10.本設計中所使用的FPGA開發環境和仿真環境分別為Xilinx ISE Design Suite 13.1 和 Mentor Graphics Modelsim SE 6.5a.
2.1 峰值計算性能
理想情況下,每個PE單元在一個時鐘周期內可以完成1次雙精度浮點乘法操作和1次雙精度浮點加法操作,因此整個矩陣乘法器的計算性能可計算為
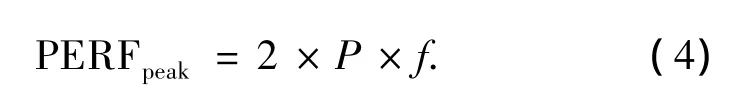
式中:PERFpeak表示矩陣乘法器的峰值計算性能(每秒百萬次浮點操作),P為矩陣乘法器中PE單元的個數,f為矩陣乘法器工作的時鐘頻率.
FPGA內部資源的使用情況見表2.根據布局布線后仿真的結果,該矩陣乘法器在未做優化的情況下工作頻率能達到250 MHz.由此可知該矩陣乘法器的峰值計算性能可達到5 000 MFLOPS.
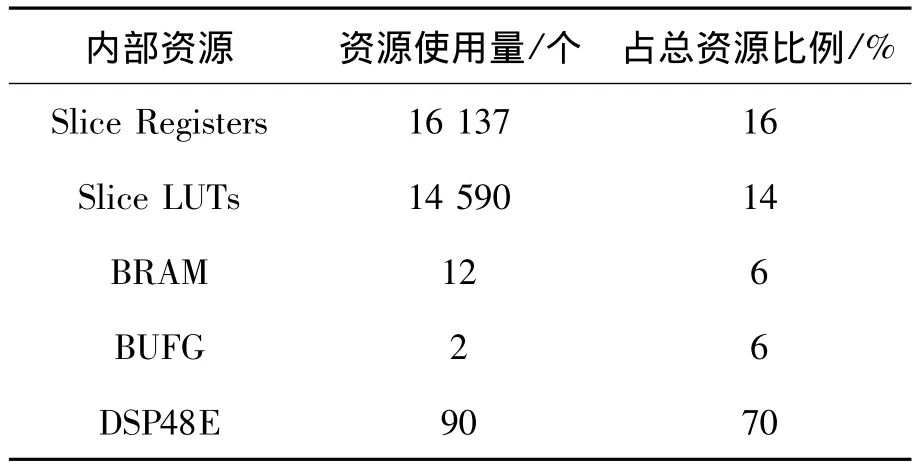
表2 FPGA內部資源使用情況Table 2 Usage of FPGA internal resources
2.2 平均計算性能
并行矩陣乘法器的平均計算性能可以通過計算
2個矩陣相乘所需的總時間來求得,如式(5)所示.

式中:PERF表示并行矩陣乘法器的平均計算性能,F表示2個矩陣相乘總共需要完成的雙精度浮點操作次數,t為計算時間.
本文分別以2個128 bit×128 bit的矩陣相乘和2個256 bit×256 bit的矩陣相乘的實例來分析該設計的平均計算性能,如表3所示.

表3 平均計算性能對比Table 3 Comparison of computation performance
由表2、3可以看出,本文設計的并行矩陣乘法器的峰值計算性能可達到5 000 MFLOPS,平均計算性能可以保證在峰值計算性能的85%左右.而田翔等的設計A未采用流水線結構,工作頻率只有60 MHz,即使在一片FPGA上集成了25個PE單元,它的峰值計算性能只能達到3 000 MFLOPS[4].而且,設計A的平均浮點計算性能只能保持在峰值計算性能的50%左右.由此可見,本文設計在計算性能上有大幅度提高.
在矩陣乘法計算中,若FPGA的I/O帶寬小于一定值,并行矩陣乘法器中的PE單元就會出現等待狀態,此時,帶寬便成為制約計算性能的因素.當I/O帶寬達到或者高于這個值后,每個PE單元的計算性能則成為制約并行矩陣乘法器計算性能的主要因素.在本文的設計中,PE的計算性能主要由工作頻率決定,在工作頻率為250 MHz的情況下,只要I/O帶寬達到4 GB/s,便不會對整個系統的計算性能產生影響.
3 結束語
本文設計了一個全流水結構的并行雙精度浮點矩陣乘法器,并在Xilinx xc5vlx155 FPGA上實現了該方案.矩陣乘法器內部的PE單元采用流水線結構,并運用C-slow時序重排技術解決了環路流水線中“數據相關沖突”的問題,提高了計算效率.實驗結果表明,對于不同維數的矩陣乘法,本設計都有較高的計算性能.同時,本文設計的并行矩陣乘法器結構,其內部的各個PE單元相互獨立,因而具有很好的可擴展性.在后續的研究工作中,需要提出更為合理的并行結構,通過多片FPGA的并行計算來進一步提高矩陣乘法器的計算性能.
[1]AMIRA A,BENSAALI F.An FPGA based parameterizable system for matrix product implementation[C]//IEEE Workshop on Signal Processing Systems(SPIS’02).San Diego,2002:75-79.
[2]JANG J,CHOI S,PRASANNA V K K.Area and time efficient implementations of matrix multiplication on FPGAs[C]//2002 IEEE International Conference on Field Programmable Technology.Seoul,Korea,2002:93-100.
[3]CAMPBELL S J,KHATRI S P.Resource and delay efficient matrix multiplication using newer FPGA devices[C]//Proceedings of the 16th ACM Great Lakes Symposium on VLSI.Philadelphia,USA,2006:308-311.
[4]田翔,周凡.基于FPGA的實時雙精度浮點矩陣乘法器設計[J].浙江大學學報:工學版,2008,42(9):1611-1615.
TIAN Xiang,ZHOU Fan.Design of field programmable gate array based real-time double precision floating-point matrix multiplier[J].Journal of Zhejiang University:Engineering Science,2008,42(9):1611-1615.
[5]LEISERSON C,ROSE F,SAXE J.Optimizing synchronous circuitry by retiming[C]//Proceedings of the 3rd Caltech Conference On VLSI.Rockville,Maryland,1983:87-116.
[6]SU Ming,ZHOU Lili.Maximizing the throughput-area efficiency of fully-parallel low-density parity-check decoding with C-slow retiming and asynchronous deep pipelining[C]//The 25th International Conference on Computer Design.Washington,DC,USA,2007:93-100.
[7]肖宇,王建業,張偉.基于IP核的數選式浮點矩陣相乘設計[J].集成電路應用,2011,37(6):52-55.
XIAO Yu,WANG Jianye,ZHANG Wei.Floating-point matrix multiplication design based on IP core[J].Application of Integrated Circuits,2011,37(6):52-55.
[8]許芳,席毅,陳虹.基于FPGA Nios-Ⅱ的矩陣運算硬件加速器設計[J].電子測量與儀器學報,2011,25(4):376-383.
XU Fang,XI Yi,CHEN Hong.Design and implementation of matrix hardware acceleration based on FPGA/Nios-II[J],Journal of Electronic Measurement and Instrument,2011,25(4):376-383.
[9]黎鐵軍,李秋亮,徐煒遐.一種128位高性能全流水浮點乘加部件[J].國防科技大學學報,2010,32(2):56-60.
LI Tiejun,LI Qiuliang,XU Weixia.A high performance pipeline architecture of 128 bit floating-point fused multiply add unit[J].Journal of National University of Defense Technology,2010,32(2):56-60.
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
