關聯規則中Apriori算法的研究與改進
2012-10-17 03:07:04宋小小陳曉輝劉沖
網絡安全技術與應用 2012年3期
宋小小 陳曉輝 劉沖
桂林理工大學 廣西 541004
0 引言
數據挖掘是一門新興起的交叉學科,主要研究事務數據庫、關系數據庫中的數據項之間潛在有用的新穎的規律。它的主要方法包括:分類、關聯規則、聚類、特征、回歸分析、變化和偏差分析等。關聯規則挖掘就是從海量的數據中尋找數據項間的關聯關系,它是數據挖掘領域中研究的熱點問題。關聯規則表示數據庫中一組對象之間具有某種關聯關系的規則,其主要挖掘對象是事務數據庫。這種數據庫大量的應用在零售業,而條形碼技術的發展使得數據的收集變得更加方便、更加完整。關聯規則就是在這些交易項目中去尋找某種關聯關系。1993年,Agrawal等人首先提出了挖掘顧客交易項目中項集間的關聯規則問題,此后諸多的研究人員對關聯規則挖掘問題進行了大量的研究與改進。
1 Apriori算法
1.1 算法簡介
Apriori算法是1993年由Agrawal等人提出的一個經典的挖掘關聯規則算法,它通過對事務數據庫的多趟掃描來發現所有的頻繁項目集。
該算法采用“逐層搜索”的迭代方法,利用向下封閉特性,由 k-頻繁項目集生成(k+1)-頻繁項目集。第一趟掃描數據庫計算出 1-頻繁項目集集合(記為:L1);接著,反復行下面的兩個步驟計算k-頻繁項目集,直到生成k-頻繁項目集的集合(記為:Lk)為空:
(1) 連接:(k-1)-頻繁項目集集合進行自連接運算,生成候選k-項目集集合。
(2) 剪枝:上一步生成的候選k-項目集集合是k-頻繁項目集集合的超集。通過掃描數據庫計算候選k-項目集集合中每個候選項目集的支持度,并與給定的最小支持度進行比較,較大的就是k-頻繁項目集。
1.2 算法分析
經典的Apriori挖掘算法在執行“連接,剪枝”步驟中,需要多次掃描數據庫并生成大量的候選項目集。當數據庫太大或者挖掘層次太深時, 算法耗時太多甚至無法完成。在剪枝步,由大量的候選項目集而造成的頻繁模式匹配問題,這些都嚴重影響了Apriori 算法的效率。
1.3 算法的基本原理
性質1 K項數據項目集是頻繁項目集的必要條件是它的所有k-1項子集均是頻繁項目集。
性質2 K頻繁項目集的所有K-1維非空子集均是頻繁項目集。
定理1 若K維數據項目集X = { i1, i2,…,ik}中,存在一個j∈X,使得|Lk-1(j)| < k-1,則X不是頻繁項目集。
其中,|Lk-1(j)|表示(K-1)維頻繁項目集的集合 Lk-1中包含j的個數。
證明 假設X是K維頻繁項目集,根據性質1,X的k個(k-1)項目子集都在Lk-1中,其中每一個項目p∈L均出現k-1次,故?p∈L,均有| Lk-1(p)|≥k-1,這與條件矛盾,故X不是頻繁項目集。
推論1 如果k-1維頻繁項集集合Lk-1中包含單個項目i的個數小于k-1,則i不可能包含在頻繁k-項集中。
2 改進的Apriori算法
Apriori算法中對數據庫的處理,目前普遍采用的是水平數據庫結構。本文借鑒文獻的思想,將水平結構變換為垂直對應關系。經過這樣變換,很容易計算1-項目集的支持度,同時很容易計算候選項目集的支持度,并且只在計算1-項目集時需要對整個數據庫進行訪問。
改進的Apriori算法思路如下:
(1) 首先掃描整個數據庫,記錄支持每個項目的事務ID號。經過統計后,計算出每個項目的支持度,并與最小支持度進行比較,進而得出1-項目集。
(2) 由1-項目集中的項目進行兩兩連接,生成候選2-項目集。然后計算候選 2-項目集中每個項目集的事務計數(事務計數等于項目集中的每個項目事務的交集),與最小支持事務數進行比較,進而得出2-項目集。
(3) 以此類推,生成候選k-項目集。根據定理1和推論1,刪除候選k-項目集中不可能為k-項目集的項目,然后計算候選k-項目集中每個項目集的事務計數,與最小支持事務數進行比較,進而得出k-項目集。
(4) 重復步驟3,直到生成K頻繁項目集的集合為空。
改進的Apriori算法描述如下:



3 實驗與結果分析
與經典的Apriori挖掘算法相比, 改進后的挖掘算法有如下優點:
(1) 算法只在計算頻繁1-項目集時需要對整個數據庫進行訪問,在計算候選k項目集的支持度時,僅需要數據庫中頻繁k-1項集信息。而隨著k的增大,頻繁項目集的數目不斷減少。
(2) 算法采用垂直對應數據庫結構,通過該數據庫結構很容易計算候選項目集的支持度。
(3) 算法在生成一個候選項目集后就計算其頻繁度,避免了模式匹配,減少內存的使用。
為了進一步驗證算法的有效性,實驗在內存為512MB,CUP主頻為1.7GHZ,操作系統為Windows XP2的環境下進行,并用VC++ 6.0分別實現了經典Apriori算法和本改進算法。數據由筆者隨機生成,有2800個數據,90個項集,最小支持度為15%,實驗結果如表1所示。
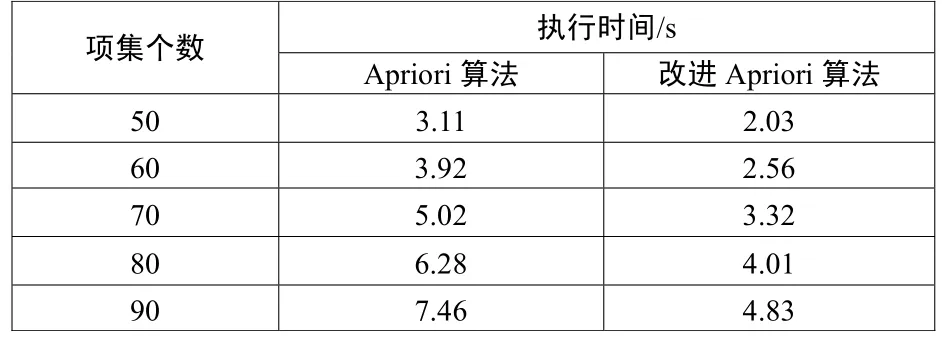
表1 兩種算法在不同項集個數下的運行時間
從表中可以看出,經過改進的Apriori算法在執行速度上有了較大的提高。
4 結語
本文通過深入分析經典Aprior算法的優缺點,在此基礎上提出了改進的Apriori關聯規則挖掘算法,并給出了詳細的算法描述。經實驗證明,改進的Apriori算法比經典的Apriori算法有著更好的頻繁項集的提取速率。
[1]陳應霞,陳艷.關聯規則中的 Apriori挖掘算法改進[J].長江大學學報(自然科學版).2008.
[2]徐章艷,劉美玲,張師超等.Apriori算法的三種優化方法[J].計算機工程與應用.2004.
[3]李云峰,陳建文,程代杰,關聯規則挖掘的研究及對 Apriori算法的改進[J].計算機工程與科學.2002.
[4]曾萬聰,周緒波,戴勃等.關聯規則挖掘的矩陣其法[J].計算機工程.2006.
[5]Agrawl R, Shafer J.Parallel Minging of Association Rules:Design,Implementation,and Experience[P].USA: CA95120.1996.
[6]K1einberg J,Papadimitriou C,Raghavan P.Segmentation Problems [A] Proceedings of the 30th Annual Symposiumon the Theory of Computing [C].New York: ACM Press.1998.
[7]毛國君,段立娟,王實,石云.數據挖掘原理與方法.北京:清華大學出版社.2007.
[8]劉君強,孫曉瑩,潘云鶴.關聯規則挖掘技術研究的新進展[J].計算機科學.2004.
[9]王偉勤,鄭海.Apriori算法的進一步改進[J].計算機與數字工程.2009.
[10]楊啟昉,馬廣平.關聯規則挖掘Apriori算法的改進.計算機應用[J].2008.
[11]馬盈倉.挖掘關聯規則中 Apriori算法的改進.計算機應用與軟件[J].2004.
[12]Brin S,Motw ani R,Silverstein C.Beyond Market Baskets:Generlizin g Association Rules to Correlations [A].Proceedings of the ACM SIGMOD [C] New Yor k: ACM Press.1996.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
