遺忘曲線的協同過濾推薦模型
2012-10-26 13:33:48印桂生崔曉暉馬志強
哈爾濱工程大學學報 2012年1期
印桂生,崔曉暉,馬志強
(哈爾濱工程大學 計算機科學與技術學院,黑龍江 哈爾濱 150001)
網絡技術的發展帶來了信息過載[1]現象.作為一種信息過濾手段,協同過濾推薦系統[2]根據用戶對某些資源的歷史評價信息,主動提供其可能感興趣的資源列表.
現有協同過濾推薦系統,如Tapestry System[3],Grouplens[4],Yahoo Tomoharu[5]等,將發生于不同時刻下的歷史信息等同對待,缺乏對其時效量化分析.一種合理的思維是:距離當前時刻越近的歷史評價信息在評價預測中具有更高的推薦效用,反之,距離當前時刻越遠的歷史評價效用越低,即時效隨時間發生衰減[6].一些研究成果采用線性或非線性衰退函數量化評價時效隨時間變化情況.KOYCHEV[7]采用線性函數作為時效量化基礎.KUKAR[8]采用核函數計算時效隨時間衰減情況.DIND[9]指出時效量化是一個隨時間發生梯度逐漸下降過程,故指數函數更加適合時效量化.上述模型雖然一定程度上滿足時效隨時間發生衰退的基本特征,但沒有考慮資源的時效衰退差異性問題.在推薦系統中,用戶興趣漂移[10]普遍存在導致時效衰退程度發生動態改變,表現為受歡迎的資源其時效衰減速率較慢.因此,如何根據用戶興趣,探索時效隨時間衰退特征,是提高時效量化在推薦系統中實用價值的主要途徑.
基于此,提出一種應用遺忘曲線的協同過濾推薦模型(FC-CFRM:forgetting curve based collaborative filter recommendation model).該模型從用戶興趣漂移角度揭示資源時效遺忘速率的差異化規律,通過多階段時效量化方法和時間單位映射函數,計算具有記憶特征的歷史信息時效值,為合理量化歷史信息時效和提高推薦效果提供基礎.
1 推薦模型
FC-CFRM 可定義為 6 元組 <U,O,R,P,δ,f>.其中,U={ui},表示用戶集合;O={oj}表示資源集合;R={ri,j}表示用戶ui對資源oj的使用評價信息;P={pj(t,k)}表示不同資源的時效量化函數,pj(t,k)?[0,1],t表示當前時間步,k 控制時效隨時間衰減的遺忘速率;δ稱為惰性更新因子,δ越大,同一階段用戶反饋對遺忘速率調整越小;f為效用函數,也稱推薦預測函數,用于計算用戶對于未知資源的推薦值,即f:U×O×T→R.FC-CFRM的目的是找到那些推薦值最高的資源形成評價列表L.例如:針對用戶ui,如果令其評價過的資源集合為O*,max為最大值函數,則推薦列表L的形式化表述為
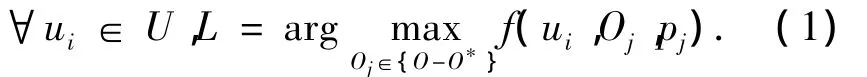
FC-CFRM具體執行過程分為2個階段:相似度計算和評價預測.
1.1 相似度計算
根據用戶資源歷史評價信息,相似度計算用于確定不同資源之間的相似程度,為后續評價預測提供基礎.常見的相似度計算方法包括:類歐式距離法,條件概率法和皮爾森法.
1.1.1 類歐式距離法
將資源看作是用戶評價流形子空間中的點,資源間相似程度由點間距離決定.點間距離越大,相似度越低.如果令U(a,b)表示同時參與評價資源oa和ob的用戶集合,則類歐式距離法計算過程表示為
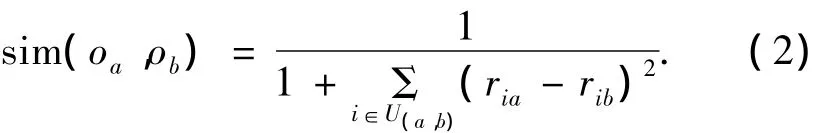
1.1.2 條件概率法
將資源相似程度看作是在某一資源受到指定用戶評價的條件下,另一資源也同時受到該用戶評價的概率p(oa|ob).如果令Freq(oa)和Freq(oa,ob)分別表示資源oa的評價用戶數和同時評價資源oa和ob的評價用戶數,則條件概率法的計算過程表示為
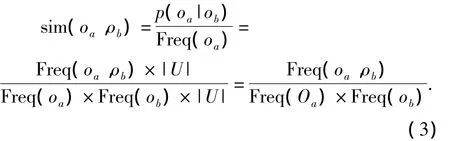
1.1.3 皮爾森法
皮爾森法采用數理統計的思想,將資源評價看作是同一樣本空間中,重復實驗下的抽樣結果.如果令r和r分別表示資源o和o資源所得到用ab戶平均評分,U(a,b)定義同類歐式距離法,則皮爾森法的計算過程表示為
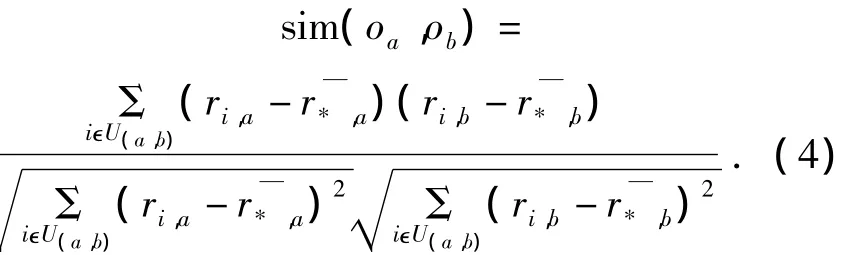
與其他相似度計算方法相比,皮爾森法具有最佳的線性逼近程度,能夠應對“分數膨脹”和“分數貶值”問題.
實際中,采取何種資源相似度計算方法依賴于推薦系統評價數據集特征.
1.2 評價預測
評價預測(效用函數f)根據相似度計算結果,對與未知評價資源oj相似的所有資源進行評價值聚合運算,從而得到指定用戶ui對oj的評價預測值.考慮到資源歷史評價信息的時效特征,引入時效量化函數后的評價預測方法表示為
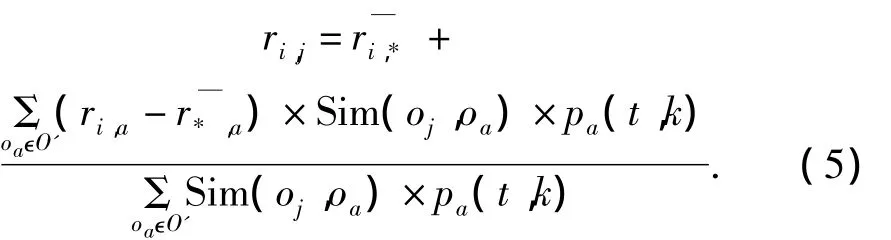
式中:O'表示用戶ui評價過且與oj相似的資源集合;r表示這|O'|個資源的歷史評價的平均值;pa(t,k)根據不同時間步t和控制參數k,量化oa歷史評價的時效值;pa(t,k)是模型的研究重點.
2 資源時效量化方法
德國心理學家艾賓浩斯采取無意義音節作為材料,以重學法揭示遺忘過程中,記憶時效隨時間變化特征,如圖 1[11]所示.
在推薦系統中,指定資源的評價信息反映了用戶對該資源的主觀認可程度.這種主觀認可程度必然隨時間發生與遺忘過程類似的衰減情況.同時,根據記憶心理學研究成果,不同的記憶源存在遺忘衰減程度差異,用戶感興趣的記憶材料更容易被記牢.這與推薦系統中不同資源存在時效衰減差異的要求相同.基于此,將描述記憶特征的遺忘曲線作為衡量資源的時效變化基礎,具有一定實際性和參考性.
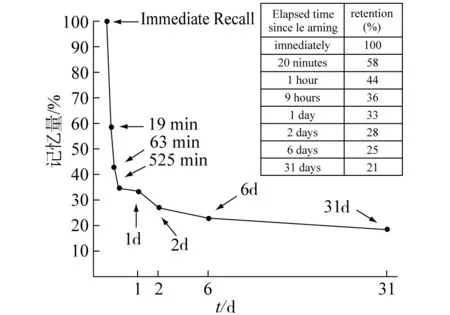
圖1 遺忘過程遺忘曲線Fig.1 Time-utility Curve of forgetting procedure
本節首先獲得遺忘曲線的基本量化函數,該函數體現出單個階段內時效隨時間變化趨勢.然后,根據用戶反饋,動態調整時效衰減程度,確定任意時刻擬合用戶興趣的多階段時效量化方法.最后,設計時間單位映射函數.
2.1 單階段時效量化方法
如果將當前時效發生體看成一個信息量儲藏室,初始時效性作為該室的輸入,則根據遺忘特征,資源歷史評價信息的時效保持量為時間步t的函數pa(t,k),其中k用于控制時效的遺忘速率,該過程如圖2所示.
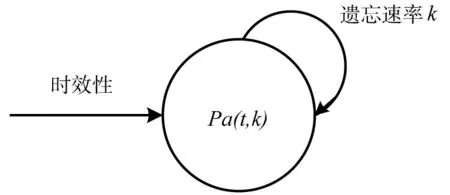
圖2 記憶的一室模型Fig.2 One-compartment model of memory
將圖2的動態過程轉換為微分方程形式,表示為
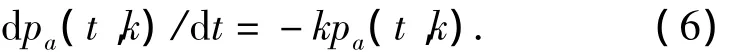
求解式(6)的原函數 pa(t,k),表示為

式中:t∈(0,∞),表示的遺忘曲線應取坐標系第一象限;p0為該曲線在y軸上的截距,即時效的初始值,由于被試材料的初始記憶時效值均從100%開始進行衰退,故取p0=1.
根據上述參數設定,資源oa的單階段時效量化方法以式(8)為基礎,根據當前時間步t及遺忘速率k獲得資源歷史評價信息的時效值.

式中:遺忘速率k是反映資源遺忘曲線衰減差異的主要參數.在后續內容中,將根據用戶興趣漂移,動態學習式(8)中k的數值,建立時效多階段量化方法.
2.2 多階段時效方法
本節根據憶心理學中記憶加強現象,將控制參數k的確定方法理解為多個階段的遺忘曲線的調整過程.
針對同一被試資料,記憶加強是指經過學習,記憶出現階躍(恢復完全記憶)并產生具有更低遺忘速率的新階段遺忘過程.如果令t1、t2和t3分別表示發生3次重新學習的時間步,則遺忘曲線調整過程如圖3所示.
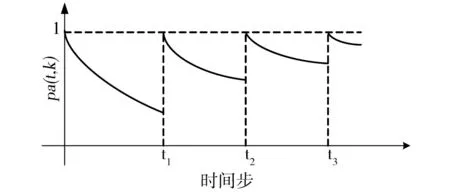
圖3 多階段遺忘曲線調整Fig.3 Curve update in multiple procedures
圖3可看作是由用戶興趣變化而導致的遺忘速率動態調整過程.如果令tn-1和tn為遺忘曲線發生記憶加強現象的任意相鄰時間步,kn-1為遺忘曲線從tn-1到tn的遺忘速率,則對于資源oa,表示該遺忘階段的時效量化函數表示為式中:還需進一步確定kn-1的學習策略.根據推薦系統的實際運行特征,將用戶反饋作為刺激遺忘速率發生改變的基本因素.
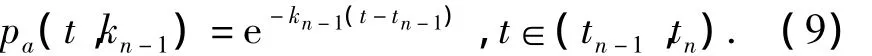
為便于分析相鄰階段遺忘曲線的調整方式,將遺忘速率調整后的新遺忘曲線向x軸反向平移,使之與原遺忘曲線具有共同起點.令調整前后的遺忘速率分別為kn-1和kn,則上述操作過程如圖4所示.
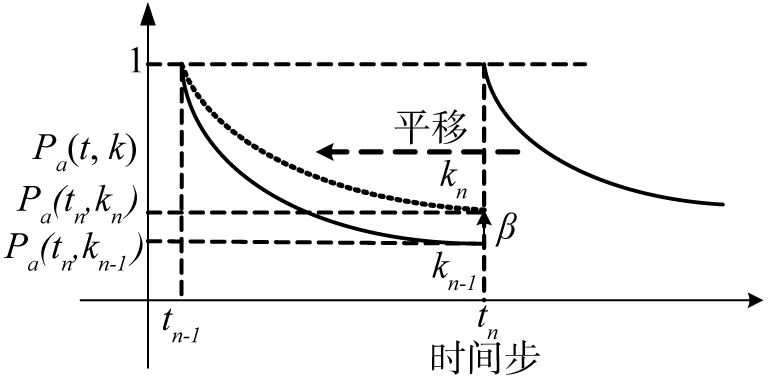
圖4 時效遺忘速率調整分析Fig.4 Analysis of forgetting-ratio update
在圖4中,根據用戶評價反饋,發生曲線遺忘速率調整.若令β表明在時間步tn時新舊遺忘曲線的衰退差異,則根據式(9),β的數值大小表示為
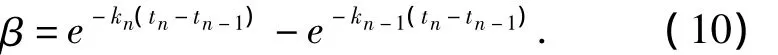
化簡式(10),由β建立kn-1和kn的數值關系,表示為
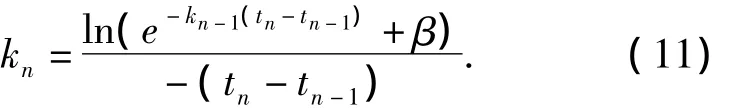
式中:(1-pa(tn,kn-1))為遺忘曲線在時間步tn時β取值的上限.為控制每次用戶反饋對曲線的調整程度,將(1 -pa(tn,kn-1))劃分為 δ個線段,調整程度β與時效保持程度的量化關系表示為
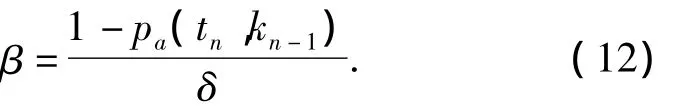
在推薦系統中,δ可設定為一個大于1的正整數.將式(12)代入式(10),消去β,得到的kn的計算公式,表示為
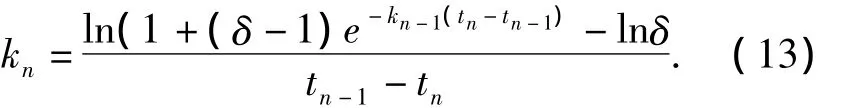
式中:遺忘速率的調整過程呈現遞歸關系,如果令初始遺忘速率為k0,結合式(9)和式(13),可確定資源歷史評價信息在多階段遺忘過程中任意時刻的時效量化函數,從而滿足評價預測過程中相關要求.
2.3 時間單位映射函數
“時間步”是實際時間單位的一種離散化表示,常用于研究與時間特征耦合的系統中.在將系統付諸實踐時,需根據系統應用背景,設計實際系統時間到時間步的時間單位映射函數.
考慮到不同時間單位在時效量化方面的等價性,設計線性函數將系統時間“毫秒”映射到FCCFRM所能夠識別的時間步.時間單位映射函數的構造過程為
1)針對單階段時效量化函數,當pa(t,k)∈(0,1]時,f需滿足從系統時間 T:[0,∞)到時間步t:[0,∞)的一一映射,表示為
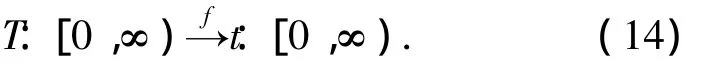
2)根據式(3),當 pa(t?,k)=0.1 時,表明當前時間步該評價記錄已基本喪失推薦效用,如果時效繼續下降,則對該記錄的時效量化過程無任何實際意義.基于此,在式(3)中引入臨界時間步 t?,表示為
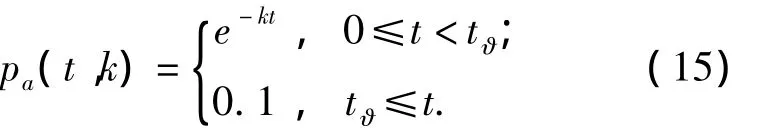
如果用T?表示t?對應的臨界系統時間,則結合式(15),式(14)可進一步表示為
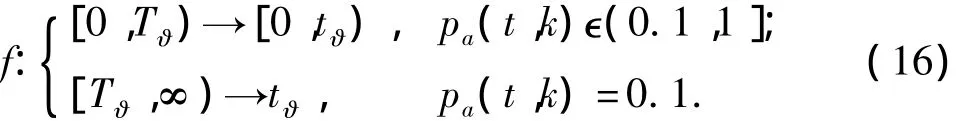
根據式(16),單階段時效量化方法的時間單位映射函數可表示為

3)針對多階段時效量化方法,將遺忘速率km代入式(15)求.根據線性函數的等價特性,利用式(17)已確定的函數形態求遺忘速率km下對應的,表示為
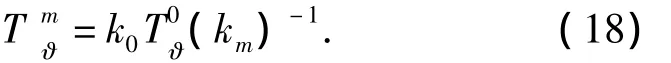
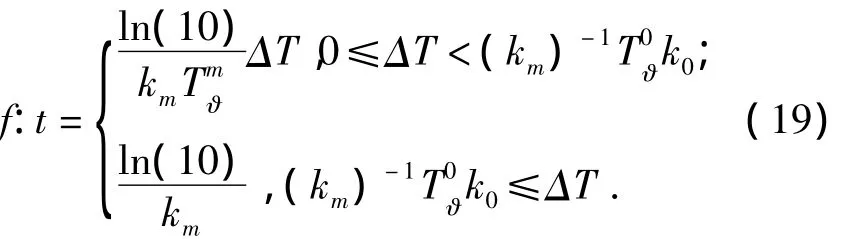
式中:k0表示初始遺忘速率,ΔT表示當前系統時間距上一次用戶反饋的系統時間增量.
3 仿真分析
3.1 數據準備
將推薦系統中經典的數據集MovieLens[4]用于仿真分析.MovieLens由真實網絡中71 567個用戶對10 681個不同電影所進行的超過10 000 000條評價組成.每一條評價記錄包括用戶標識,電影標識,評價數值和時間戳.為驗證FC-CFPM系統的推薦效果,取原始數據集中前10 000條時間相鄰的資源歷史評價信息為初始仿真數據集.采用交叉驗證的方式將初始實驗數據集分成訓練集和測試集,劃分百分比為0.2,即8 000條訓練數據和2 000條測試數據.其中,訓練集用于獲取資源歷史評價信息的遺忘速率,測試集將根據訓練得到的時效分析結果進行評價預測.
測試過程采取增量學習的方法,其過程為:根據測試記錄中資源標識,獲取該資源的時效遺忘速率,并根據系統時間差,計算時效數值進行推薦.當推薦結束后,針對該記錄反饋的資源進行遺忘速率的調整,同時,將評價預測后測試記錄移入訓練集的末尾,為后續推薦過程中計算資源間相似度提供基礎.
平均絕對誤差(mean absolute error,MAE)作為衡量FC-CFPM在不同實驗中推薦效果,其計算方法如式(20)所示.其中,b(n)表示推薦系統計算得到的預測數值,bp(n)表示根據用戶反饋得到的真實評價值.MAE體現推薦預測值與實際用戶反饋值之間的平均差異.顯然,MAE的值越小,說明推薦系統的評價預測效果越優秀.
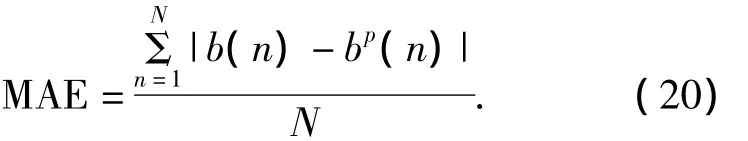
3.2 參數設定

表1 參數設定Table 1 Setting of parameters
k0的數值在仿真過程中會發生動態調整,僅需設定初值即可.
3.3 惰性因子δ取值分析
惰性因子δ用于控制遺忘速率調整程度.δ越大,用戶評價反饋對該資源的時效遺忘速率更新效果越不明顯.惰性因子δ的取值無法同其他系統參數一樣,或通過計算訓練集上相關統計特性獲取,如初始臨界時間,或通過訓練過程動態調整.基于此,在惰性因子δ取10、20、50和100的基礎上,運行FC-CFRM,根據MAE結果,確定δ的合理取值,仿真結果如圖5所示.
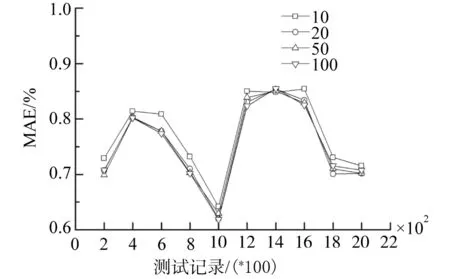
圖5 δ取值對推薦效果影響Fig.5 Effects of various values ofδ on recommendation
圖5中,每條曲線表示不同δ取值下FC-CFRM的10次分段MAE采樣情況,分段長度為200.根據采樣結果,FC-CFRM在不同測試記錄分段上的MAE變化趨勢相同,數值上呈現波動狀態.
其中,δ=10的MAE數值僅在第1 200~1 400條測試記錄上與其他實驗結果相當(MAE=0.848 17),在其他數據分段上,均具有較高的MAE值,表現為更差的推薦效果.
當δ=20、50、100時,MAE在不同數據分段下的差異最大值為0.014 8,位于δ=20和δ=100的第1 600~1 800條記錄上,最小值為0.009,位于取20和50的曲線的第800~1 000條記錄上,均值為0.000 312.對 δ=20、50、100 的 MAE 曲線采取線性擬合方式做相似度分析,其擬合后的直線基本吻合.
基于上述分析,當惰性因子δ取大于10的正整數時,FC-CFRM的推薦效果不因δ取值的改變而出現較大的波動.在后續試驗中,采用δ=50.
3.4 推薦效果對比分析
推薦效果對比分析用于衡量不同模型在測試集上推薦效果.實驗中所采取的對比方法包括:缺乏考慮資源歷史評價信息時效性的經典協同過濾推薦模型(N-CFRM)[5],采取簡單指數k=1時效量化的協同過濾推薦模型(E-CFRM),基于機械遺忘曲線時效量化的協同過濾推薦模型(F-CFRM)[14],基于遺忘曲線的協同過濾推薦模型(FC-CFRM).推薦效果分析利用式(21)計算其他推薦模型*-CFRM與N-CFRM的MAE差異程度,若該值為負數,說明其推薦效果較N-CFRM更差.反之,若該值為正數且其值越大,則推薦效果越優.實驗結果如圖6所示.
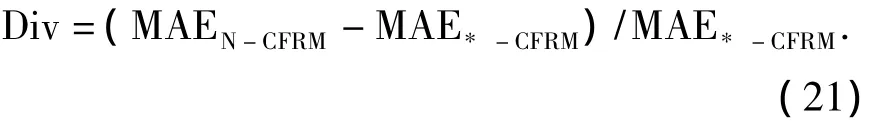
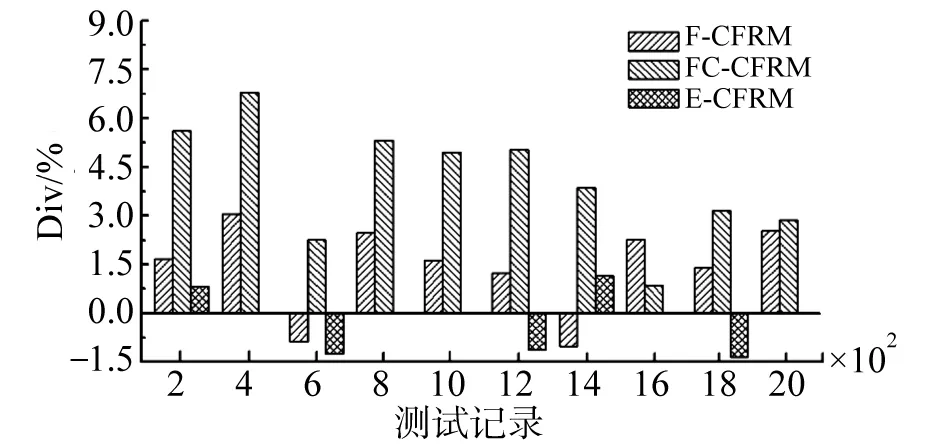
圖6 推薦效果對比分析Fig.6 Comparison analysis of effect of recommendation
在圖6中,每一分段中包含了3種推薦模型與N-CFRM的MAE差異程度,分段長度為200.總體上,所有推薦模型的推薦誤差度在不同分段數據集上呈現出波動狀態.其中,E-CFRM有7個正數分段,3個負數分段.F-CFRM有8個正數分段,2個負數分段.FC-CFRM全部為正數分段.針對每一種推薦模型,表明其具體推薦效果的MAE統計特征量如表2所示.
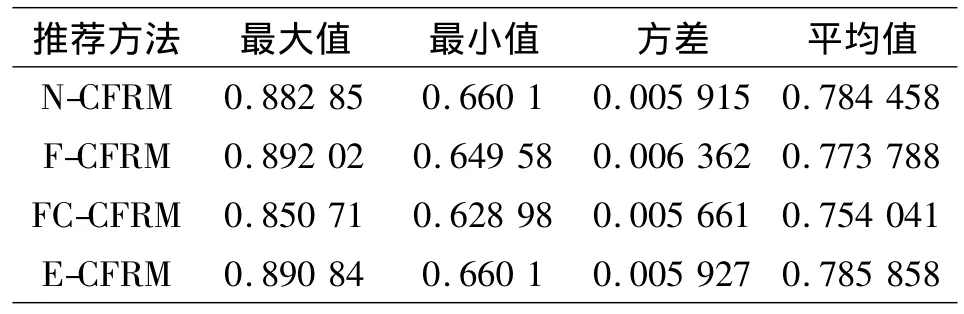
表2 MAE統計分析Table 2 Statistic analysis of MAE
根據表2,各推薦方法的平均推薦效果排序:E-CFRM<N-CFRM<F-CFRM<FC-CFRM.穩定性排序:F-CFRM<E-CFRM<N-CFRM<FC-CFRM.
由于E-CFRM采取人工方式設定指數函數的遺忘速率,忽略用戶興趣對不同資源在時效量化的影響,導致無論在推薦效果和推薦穩定性方面,均比N-CFRM表現更差.
從F-CFRM的實驗結果上看,采取遺忘曲線能夠較好的擬合資源時效隨時間變化情況,表現為推薦平均效果較N-CFRM有所提高,但其忽略了資源時效量化存在多階段遺忘過程的特征.在用戶興趣發生變化時,F-CFRM的推薦效果會出現較大波動,即推薦過程不可控現象.
基于上述分析:FC-CFRM能夠采取合理的歷史信息時效量化模型,跟蹤用戶興趣變化,動態調整資源歷史評價信息的時效遺忘速率,提供穩定且質量較高的推薦效果.
4 結束語
針對歷史評價時效特征,提出一種用遺忘曲線協同過濾推薦模型.實驗結果表明,與其他推薦模型相比,模型能夠合理揭示遺忘速率隨用戶興趣的變化規律并提供穩定且質量較高的推薦效果.
現有推薦系統將用戶評價作為衡量資源效用的唯一標準,缺乏對環境等其他因素的考慮.當推薦對象為具體網絡資源時,環境等因素往往更能夠反映資源實際運行狀態.在后續研究中,擬將時效量化與多屬性評價相結合,設計具有時效特征的多屬性協同過濾推薦系統.
[1]許海玲,吳瀟,李曉東,等.互聯網推薦系統比較研究[J].軟件學報,2009,20(2):350-356.XU Hailing,WU Xiao,LI Xiaodong,et al.Comparison study of internet recommendation system [J].Journal of Software,2009,20(2):350-356.
[2]董麗,刑春曉,王克宏.基于不同數據集的協同過濾算法評測[J].清華大學學報:自然科學,2009,49(4):590-594.DONG Li,XING Chunxiao,WANG Kehong.Based on different data sets of evaluating collaborative filtering algorithms[J].Journal of Tsinghua University,2009,49(4):590-594.
[3]FOLDBERG D,NICHLOSD,OKIB M,et al.Using collaborative filtering to weave an information tapestry[J].Communications of ACM,1992,35(12):61-70.
[4]KONSTAN J A,MILLER B N,MALTZ D,et al.Grouplens:applying collaborative filtering to usenet news[J].Communications of the ACM,1997,40(3):77-87.
[5]PARK S,PENNOCK D.Applying collaborative filtering techniques to movie search for better ranking and browsing[C]//Proceedings of the 13th Association for Computing Machinery Special Interest Group on Knowledge Discovery in Data.San Jose,California,USA,2007:550-559.
[6]孫超.基于Agent的推薦技術的研究與應用[D].大連:大連海事大學,2009:35-37.SUN Chao.Research and application of recommendation technologies based on agent[D].Dalian:Dalian Maritime University,2009:35-37.
[7]KOYCHEV I,SCHWAB I.Adaptation to drifting user’s interests[C]//Proceedings of ECML 2000 Workshop:Machine Learning in New Information Age.Barcelona,Spain,2000:39-46.
[8]KUKAR M,LJUBLJANA S.Drifting concepts as hidden factors in clinical studies[C]//Artificial Intelligence in Medicine 9th Conference on Artificial Intelligence in Medicine in Europe(AIME 2003).Protaras,Cyprus,2003:355-364.
[9]YIDing,XUE Li.Time weight collaborative filter[C]//Proceedings of the 14th ACM International Conference on Information and Knowledge Management CIKM’05.Bremen,German,2005:485-492.
[10]KATAKISG,TSOUMAKAS,VLAHAVAS I.An ensemble of classifiers for coping with recurring contexts in data streams[C]//Proceedings of the Conference on ECAI 2008:18th European Conference on Artificial Intelligence.Patras,Greece,2008:763-764.
[11]HERMANN E.Memory:a contribution to experimental psychology[EB/OL].[2011-12-09].http://psy.ed.asu.edu/~ classics/Ebbinghaus/index.htm.
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中老年保健(2021年12期)2021-11-30 02:58:01
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
中華詩詞(2018年11期)2018-03-26 06:41:34
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
Coco薇(2016年8期)2016-10-09 02:11:50
商用汽車(2016年6期)2016-06-29 09:18:54
