大氣環境劇情生成技術研究
2012-11-30 04:57:50趙黎明許麗人
計算機工程與設計 2012年3期
蔡 軍,趙黎明,許麗人,許 瑞
(1.天津大學 管理學院,天津300072;2.北京應用氣象研究所,北京100029;3.中國科學院大氣物理研究所大氣邊界層物理和大氣化學國家重點實驗室,北京100029;4.北京航空航天大學 自動化科學與電氣工程學院,北京100191)
0 引 言
1995年10月,美國防部建模與仿真辦公室頒布了 “國防部建模與仿真主計劃 (MSMP)”,并將自然環境的及時和權威表示列為國防部建模與仿真發展的六大目標之一。為此,國防部組織實施大氣和空間自然環境建模與仿真計劃 (ASNE MSEA)。2000年,建模與仿真辦公室公布了“整體自然環境 (INE)計劃”,重點是提供自然環境的完整權威描述。這些計劃的實施推動了仿真公共基礎技術的迅速發展,如,動態大氣環境標準、環境數據表示與交換規范 (SEDRIS)、總環境庫 (MEL)、環境劇情生成 (ESG)、環境聯邦 (EnvironFed)等。其中,環境劇情生成技術是對用戶的特定環境信息需求做出及時回應,快速自動地生成滿足用戶需要的、且物理一致的大氣環境綜合劇情,并以標準規范的格式分發,以滿足用戶對特定區域、時間和環境條件下的仿真劇情的需求。當前,模擬訓練、仿真分析和作戰推演等對大氣環境劇情提出了不同的需求,而不同的仿真劇情通常需要不同的大氣環境狀態或條件,基于當今先進數據收集系統不斷擴充的數據量現狀,以及仿真領域對于大氣環境的集成和權威表達的需求,急需開展新的數據挖掘、管理和獲取技術[1]。本研究面向仿真應用,基于模糊邏輯搜索原理實現了大氣環境劇情生成技術。
1 劇情生成引擎框架
在大氣環境劇情生成技術中,劇情生成引擎為其核心內容,它主要包括模糊邏輯搜索模塊、劇情產品生成模塊和大氣環境劇情規則庫3部分,如圖1所示。
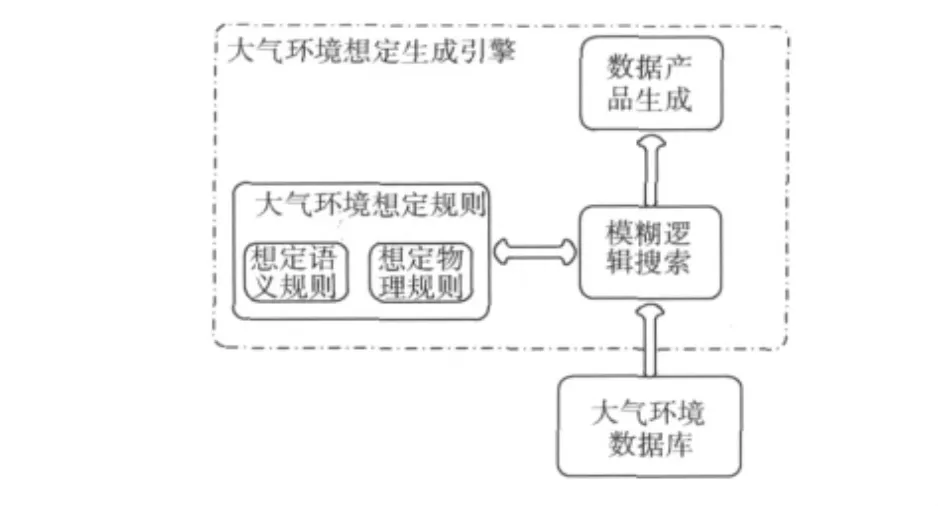
圖1 大氣環境劇情生成引擎框架
大氣環境數據庫為大氣環境劇情生成提供了底層數據源支持,是劇情生成進行的基礎。通過設計大氣環境數據表結構,可以存儲站點數據或格點數據。大氣環境數據庫雖然不歸入劇情生成引擎框架中,但卻是大氣環境劇情生成不可或缺的部分。內部數據越充分,劇情生成引擎搜索到用戶需求數據的可能性越大[2]。
模糊邏輯搜索模塊是整個引擎的核心,其功能是根據用戶提出的基于人類語言的搜索條件,從大氣環境數據庫中提取數據,利用模糊邏輯算法計算數據記錄的符合度并排序,得到候選事件列表供用戶選擇[3]。
大氣環境劇情規則庫由兩部分組成:劇情語義規則、劇情物理規則庫。分別為模糊邏輯搜索提供相應的語義規范和物理規則。
劇情產品生成模塊負責劇情數據的后處理。主要包括劇情數據集的表示、劇情數據的可視化、數據文件的生成等一系列的數據處理功能。
用戶進行劇情組織后,模糊邏輯搜索引擎對大氣環境數據庫中的數據進行搜索。大氣環境劇情規則庫對模糊邏輯搜索中的人類語言條件進行映射,支持模糊邏輯搜索。搜索到的數據集經過用戶選擇后進行數據產品的生成。由以上各部分協同工作,使大氣環境劇情生成引擎能夠支持自然語言對大氣環境條件和大氣環境信息描述;基于模糊邏輯的高效數據挖掘和挖掘結果評估;滿足物理一致性需求的大氣環境劇情組織。為用戶使用提供合理、準確、規范的大氣環境劇情產品[4]。
2 模糊邏輯搜索
大氣環境劇情生成技術為用戶提供了一種基于人類語言的劇情組織方法,使用戶可以用更為直觀的語言來設置搜索條件。但對于搜索引擎來說則需要在人類語言與計算機系統之間建立映射,這就涉及到模糊邏輯搜索。
2.1 模糊邏輯搜索原理
用帶有模糊限定算子 (例如:很,略,比較,非常等)的從人類語言提煉出來的語言變量 (例如:年輕,非常年輕等)或者模糊數 (例如,大約25,45左右等)來代替多值邏輯中命題的確切數字真值,就構成模糊語言邏輯,簡稱模糊邏輯。它為諸如人類語言變量一類的模糊信息的描述和處理提供了理論基礎。
在傳統型對象空間X中的一個集合A的隸屬關系可以用指標函數IA(.):X→ {0,1}來表示[5]。對象空間中的元素對于A的隸屬度非0則1。如圖2為段 [5,8]在實數空間R上的指標函數I[5,8]:R→ {0,1}。
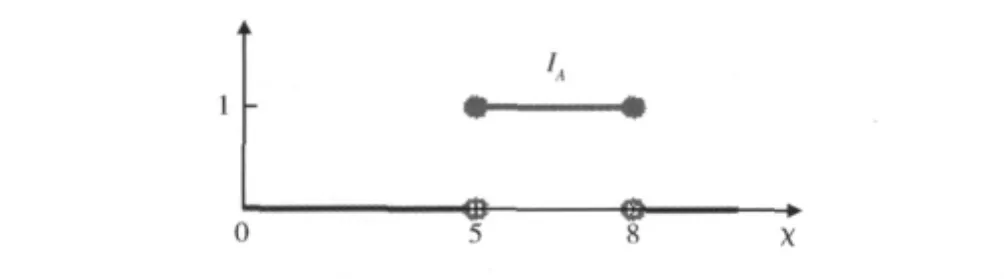
圖2 傳統集合 [5,8]的指標函數
對于人類語言來說,描述一個元素是否屬于某個區間時卻無法用明確的0和1來定義,此時就需要使用模糊集來定義。模糊集衡量元素對集合的隸屬度時指標函數值允許取在0、1之間。對象空間X中的一個模糊集合A通過隸屬度函數μA(.):X→ {0,1}來定義。X中的每一個元素對集合A的隸屬度都在0、1之間。如圖3所示為模糊集合[5,8]的隸屬度函數。
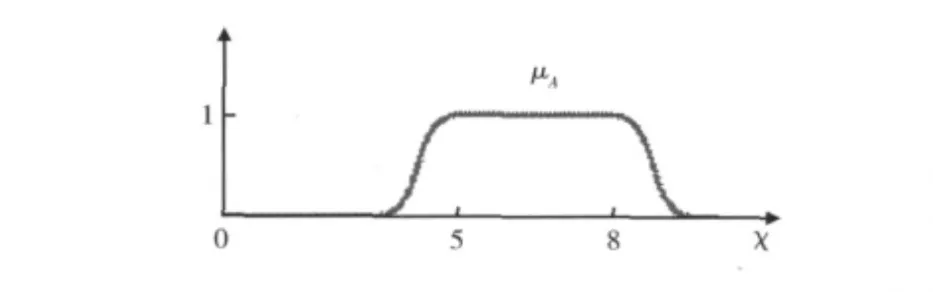
圖3 模糊集合 [5,8]的隸屬度函數
對二元模糊集合的隸屬度函數進行邏輯操作可以由普通二元集合的指標函數邏輯操作進行推廣[6]。如兩個一維模糊集合隸屬度函數μA(X),μB(X)進行與 (AND)操作后的隸屬度函數為min(μA,μB);或 (OR)操作后的隸屬度函數為 max(μA,μB);非 (NOT)操作后的隸屬度函數為示例如圖4所示。
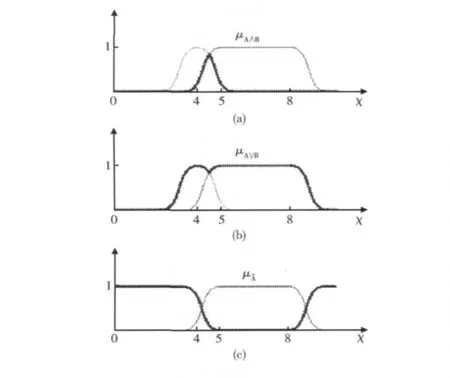
圖4 二元模糊集合的與、或、非操作
在大氣環境劇情中,使用人類語言去描述大氣屬性,比如溫度采用 “熱”、“冷”、“適中”等來區分。這樣的區間即可以用模糊集合來表示,它的隸屬度函數則根據氣象學的規范或是專家經驗來確定。本研究實例的隸屬度函數的確定使用generic bell方程[7]
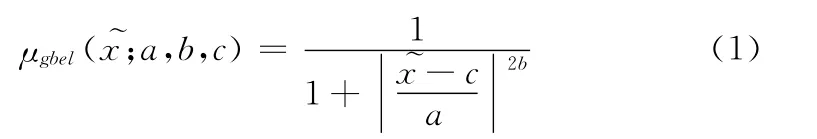
式中:——數據變量的范圍[0,1],a——半寬,b/2a——斜率,c—— “bell”的對稱中心。
以大氣環境中的溫度屬性為例,它的模糊集有 “寒冷”、“涼爽”、“適中”、“溫暖”、“酷熱”,它的隸屬度函數參數表如表1所示。
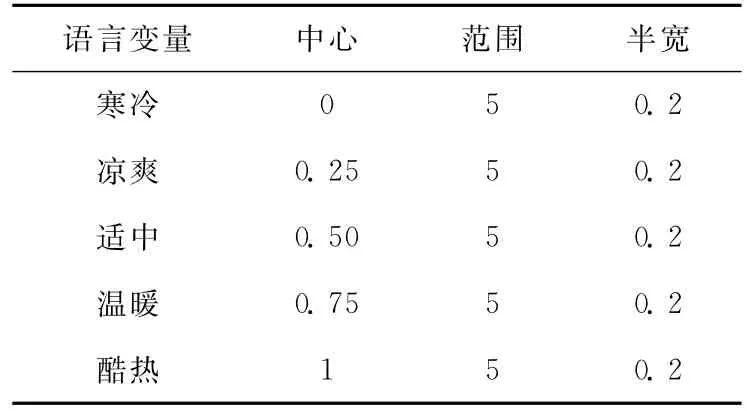
表1 溫度語言變量隸屬度參數
對不同的大氣環境屬性,根據專業知識進行分析設定相應參數,即可在模糊搜索中使用g-bell隸屬度函數對數據進行分析,確定數據對環境變量的隸屬程度。
2.2 模糊邏輯搜索機制
大氣環境劇情過程基于模糊邏輯搜索原理而實現,同時也對它的應用進行了拓展。用戶對劇情進行組織,確定需要進行搜索的大氣屬性。對于單點,它的每一種大氣屬性值相對于搜索條件都有一個介于0和1的隸屬度,也就是模糊搜索算法的判斷依據。單點在時間序列上的隸屬度采用平均算法
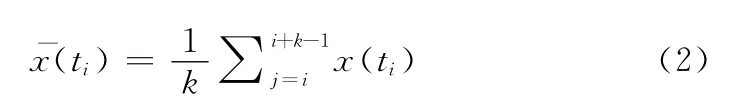
式中:ti=t0+iΔt。
對于時間固定,多點隸屬度的計算可采用同樣的算法進行計算。
以上3種基本情況的組合可以完成環境劇情中產生的所有隸屬度計算,模糊邏輯搜索即建立在此基礎上。
為提高模糊邏輯搜索效率,針對不同的搜索需求,數據集的劃分也采用不同的方法[8-9]。本研究在劇情組織中提供了 “固定空間區域搜索滿足時間劇情的時間段”和 “固定時間區域搜索滿足時間劇情的空間域”兩種搜索方式。因此對于數據段落的劃分主要在時間維上和空間經緯度兩個維度上進行分塊,搜索過程中對單塊數據逐一進行隸屬度計算。分塊的大小則取決于用戶對搜索區域的設置。
一般情況下,很難在大氣環境數據庫中搜索到完全符合用戶劇情設置的數據,仿真系統考慮到仿真的可信度也并非需要完全滿足設置的大氣數據。這也正是環境劇情使用基于人類語言的方式進行組織的主要原因。通過在模糊搜索過程中計算每個數據集的模糊隸屬度值。最后通過比較排序,提取符合度比較靠前的數據集,存入候選事件列表反饋給劇情用戶。用戶即可依據經驗判斷搜索到的數據集是否可用。
2.3 模糊邏輯搜索步驟
模糊邏輯的搜索步驟參考了數據挖掘的原理[10],如圖5所示。
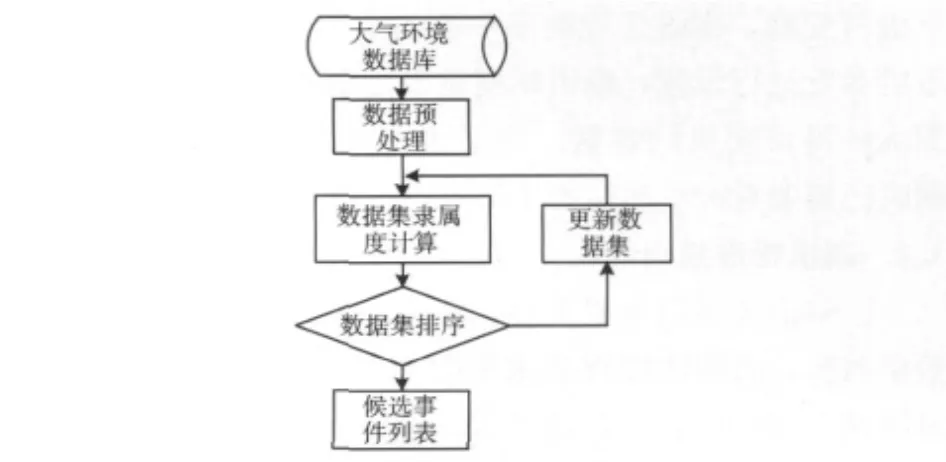
圖5 模糊邏輯搜索數據流程
數據預處理:根據用戶的劇情范圍設置,從大氣環境數據庫中查詢相應的數據。同時根據用戶的劇情條件設置對數據進行分塊操作,產生數據集用于進行模糊邏輯隸屬度計算。
數據集隸屬度計算:使用g-bell函數對數據集進行各項屬性隸屬度計算,再計算出整個數據集隸屬度。
數據集排序:對經過模糊邏輯運算的數據集進行隸屬度排序。更新候選事件列表。
更新數據集:在數據預處理過程中是根據用戶劇情設置對數據進行矩形劃分生成數據集的。但實際情況中有可能出現兩個數據集邊界區域的隸屬度很高,從兩個數據集分別的隸屬度上卻體現不出來。這里對經過排序的數據集進行分析,拋掉隸屬度為0的數據集。對隸屬度較高,同時有接觸的數據集進行重新劃分計算隸屬度,提高模糊邏輯搜索的準確性。
3 大氣環境劇情規則
模糊邏輯搜索的關鍵技術之一為隸屬度函數的確定,但人類語言變量針對不同的大氣環境屬性描述的也不盡相同,因此無法確定一個固定的隸屬度函數以適應所有的搜索情況。大氣環境劇情規則庫可以讓具有專業知識的管理員用戶對語言變量進行參數設置,使模糊邏輯搜索引擎動態的建立隸屬度函數。大氣環境劇情規則庫包括劇情語義規則庫和劇情物理規則庫[11]本文采用XML建立大氣環境劇情的規則庫,使想定生成引擎可以方便、快速的對劇情語義規則進行查詢[12]。
3.1 劇情語義規則
在劇情組織過程中,用戶設置一般是通過溫度 “涼爽”,南風 “弱”之類的人類語言組織起來的。模糊搜索引擎在執行搜索之前首先需要將這些人類語言轉換成數學描述語言才能進行下一步的工作。也即是需要一個規則集能夠將人類語言映射成隸屬度函數,這就是劇情語義規則庫。
根據模糊邏輯模型g-bell建立的隸屬度函數,需要每一個大氣屬性提供幾個關鍵參數,包括屬性上下限,以及每個屬性語言變量對應的對稱中心、半寬和斜度[13]。
以大氣環境溫度屬性為例,前文為溫度屬性定義了5個語言變量,在語義規則庫中就需要分別對這5個語言變量的參數進行設置,以供模糊邏輯查詢時進行映射。如表1即為各語言變量的參數。為了更好地進行模糊邏輯查詢,同時還需要對大氣屬性的上下限進行設置。
3.2 劇情物理規則
劇情語義規則主要是將人類具有模糊性的語言映射成數學語言,而劇情物理規則根據大氣環境自身的物理特性對劇情過程進行一定的約束,使劇情產生的數據更準確、可信。
大氣環境的物理規則分為兩類,一類是各物理屬性之間的相互約束關系,另一類是不同地域對物理屬性定義的偏差。對于第一類,主要是對用戶的劇情組織提供一定的約束與建議。諸如 “降雨量大”與 “氣壓高”很難同時發生,用戶在同時設置了這兩種情況時約束即產生作用,提醒用戶以減少不必要的查詢時間浪費。第二類主要產生于人們在不同地域對環境模糊量的定義上會產生偏差。比如處于熱帶的人對于溫度 “適中”的定義與處于溫帶的人對于同一個概念的定義肯定會有一定的差異。建立物理規則庫可以在模糊邏輯搜索過程中通過修正隸屬度函數來消減偏差。也可在劇情過程中不區別地理差異,以絕對的數值區間定義環境屬性變量。
4 劇情產品生成
大氣環境劇情生成的最終目的是為仿真用戶提供符合劇情組織的大氣環境數據。模糊邏輯搜索引擎通過對大氣環境數據庫進行搜索得到一系列的候選事件集并依照隸屬度進行排序。最后進行數據的后處理,即數據文件的生成和數據可視化。
4.1 劇情數據文件生成
當用戶在候選事件列表中選擇了數據集后,系統將數據集生成為用戶選擇的數據文件以供用戶在仿真系統中使用。為了以用戶需要的數據文件格式輸出,需要考慮不同數據格式的編碼問題。同時也需要對已有數據進行插值處理,以在數據庫數據量有限的情況下獲得更高分辨率的環境數據。在劇情生成引擎中的數據文件生成步驟如下:
(1)用戶選擇數據集,對數據范圍、分辨率、數據格式進行設置。
(2)從大氣環境數據庫中獲取對應范圍的數據。
(3)依照用戶的設置,對數據集進行裁剪和插值處理。
(4)針對用戶設定的數據格式對數據進行編碼輸出。
數據的裁剪主要依據用戶的設置對生成數據的范圍進行修改。由于數據資源的限制,搜索到的數據集分辨率一般無法滿足仿真系統對分辨率的需求。此時需要對數據進行插值處理,達到用戶需要的分辨率。為此,本文采用雙線性插值。
如圖6所示,已知A、B、C、D這4點的屬性值,為求P點的屬性值,首先在y方向上進行線性插值,求出Q、R的屬性值fQ、fR
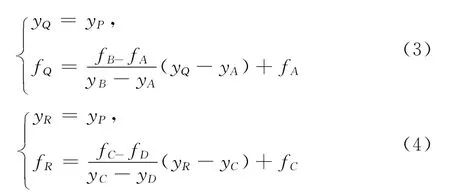
對Q、R在x方向上進行插值得到P點的屬性值fP
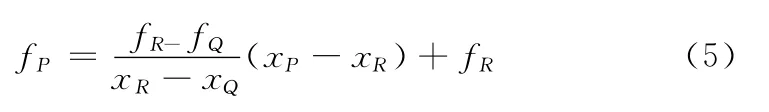
4.2 劇情數據可視化
模糊邏輯搜索對數據集進行隸屬度計算、排序生成候選事件集。用戶通過數據表無法直觀的判斷候選事件集中高隸屬度的數據在整體分布上是否滿足需求。為了給用戶提供一種通過經驗手段分析數據的途徑,需要對環境數據進行可視化處理[14]。
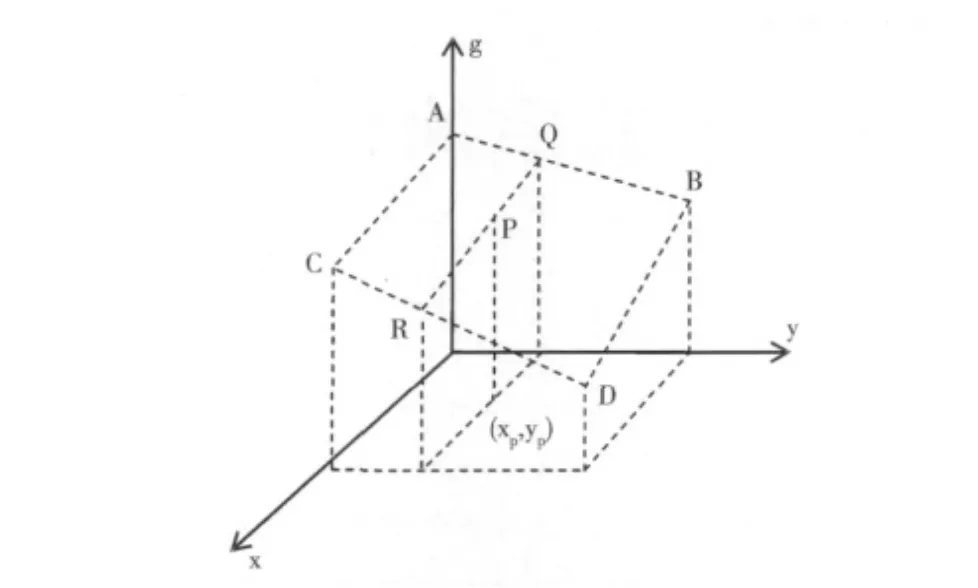
圖6 雙線性插值
GrADS(grid analysis and display system)是由COLA推出的全32位交互操作的大氣環境格點數據和站點數據的分析和顯示環境[15]。本文以某一時間段的全球格點氣象數據為基準數據庫,基于人類語言設定相應的想定劇情,通過設計的大氣環境想定生成引擎對數據庫中的數據進行搜索,產生數據集。并采用GrADS軟件進行數據集的可視化實現,生成數據的基本效果如圖7所示。
5 結束語
本研究設計提出了劇情生成引擎的邏輯框架,包括模糊邏輯搜索模塊、劇情產品生成模塊以及劇情規則庫,然后分別研究了3個模塊的實現原理和實現方法。針對模糊邏輯搜索這一核心模塊,從環境劇情的概念以及模糊集理論出發,提出了適用于大氣環境劇情的模糊搜索機制和搜索算法;對于大氣環境劇情規則,則以模糊邏輯搜索為目的,設計了劇情語義規范庫和物理規則庫,以XML文件組織和存儲規則庫,為劇情生成提供了語義參數和物理約束支持;而在劇情產品生成模塊中,對環境數據的可視化以及基于插值法的數據生成技術開展了研究,為仿真應用中的大氣環境劇情生成提供了途徑。最后通過實驗對大氣環境想定生成引擎進行了測試,得到了符合仿真用戶設定的大氣環境數據。
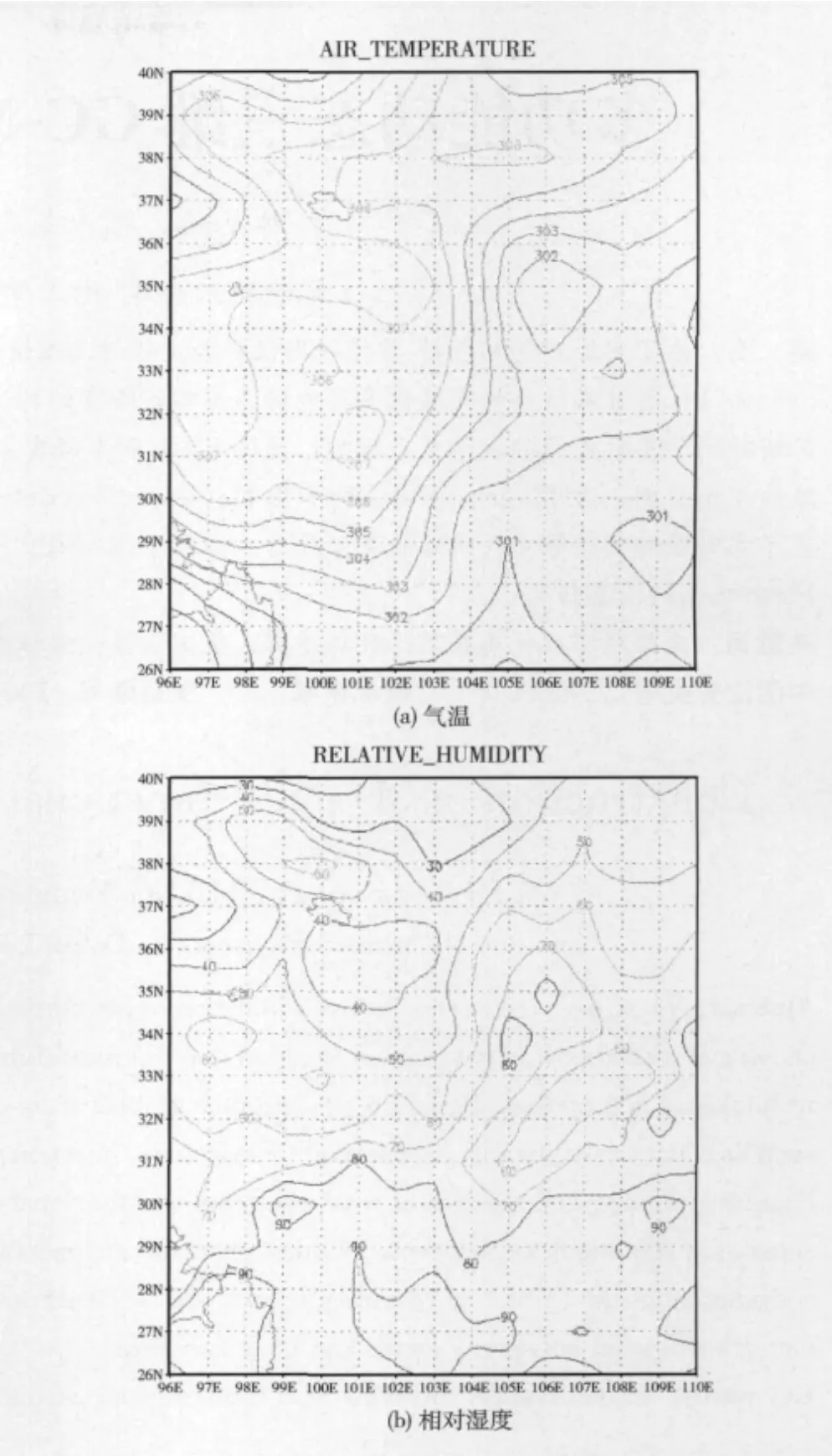
圖7 大氣溫度場與相對濕度等值線
[1]LIN Ju,ZHOU Baoshun,ZHANG Peng.Meteorological scenario generator oriented the simulation application [C].the 13th Conference on Control and Application,2008:5-10 (in Chinese).[林琚,周保順,張鵬.面向仿真應用的氣象想定生成系統 [C].控制與應用第十三屆學術年會,2008:5-10.]
[2]SUN Liqing,WANG Xingren.Research on development of synthetic natural environment database [J].Journal of System Simulation,2007,19 (16):3688-3692 (in Chinese).[孫麗卿,王行仁.綜合自然環境數據庫開發的研究 [J].系統仿真學報,2007,19 (16):3688-3692.]
[3]LI Ruixuan,WEN Kunmei,LU Zhengding,et al.An improved semantic search model based on hybrid fuzzy description logic [C].Proceedings of the Japan-China Joint Workshop on Frontier of Computer Science and Technology,2006:139-146.
[4]LIN Ju.Atmosphere environment scenario data generator and it’s application[D].Beijing:Beijing University of Aeronautics and Astronautics,2008(in Chinese).[林琚.大氣環境劇情數據生成系統及其仿真應用 [D].北京:北京航空航天大學,2008.]
[5]Mikhail N Zhizhin,Alexei Poyda,Dmitry Mishin,et al.Environmental scenario search engine(ESSE)–distributed,optimized,visible[EB/OL].http://esse.wdcb.ru/,2007.
[6]Zhizhin M,Kihn E,Lyutsarev V,et al.Environmental scenario search and visualization [C].Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems,2007:1-10.
[7]Son W,Jinhyoung Lee,Kim M S.Generic Bell inequalities for multipartite arbitrary dimensional systems [J].Physical Review Letters,2006,96 (6):060406.
[8]Adjei O,Chen L,Cheng H D,et al.A fuzzy search method for rough sets in data mining [C].Proceedings of IFSA/NAFIPS Conference,2001:980-985.
[9]Chen L.λ-connected approximations for rough sets [G].Lecture Notes in Computer Science 2457:Proceedings of the Third International Conference on Rough Sets and Current Trends in Computing,2002:572-577.
[10]YU Xiangxiang.Intruduction of data mining technology [J].Fujian Education of Information Technology,2005,1 (1):19-21(in Chinese).[于春香.數據挖掘技術簡介 [J].福建信息技術教育,2005,1 (1):19-21.]
[11]YANG Qing,CHEN Wei,WEN Bin.Fuzzy ontology model for semantic information query [J].Computer Engineering,2010,36 (8):188-190 (in Chinese).[楊青,陳薇,聞彬.面向語義信息查詢的模糊本體模型 [J].計算機工程,2010,36 (8):188-190.]
[12]DUAN Lixia.The XML data mining based on the fuzzy logic rules [J].Mind and Computation,2008,2 (1):21-26 (in Chinese).[段麗霞.基于模糊邏輯規則的XML數據挖掘[J].心智與計算,2008,2 (1):21-26.]
[13]ZHANG Peng,GONG Guang-hong.Atmosphere environment simulation scenario generator for distributed simulation system [J].Journal of System Simulation,2008,20 (19):5109-5112.
[14]ZHOU Yan.VGE and visualization of spatial data [J].Railway Investigation and Surveying,2004,30 (6):11-14 (in Chinese).[周艷.虛擬地理環境與空間數據可視化 [J].鐵道勘察,2004,30 (6):11-14.]
[15]ZHANG Li,SHEN Shuanghe,SUN Xiangming,et al.Processing of non-corresponding grid data from NCEP by using GRADS [J].Journal of Meteorological Research and Application,2009,30 (3):37-43 (in Chinese).[張麗,申雙和,孫向明,等.用GRADS處理NCEP資料中的非對應格點數據 [J].氣象研究與應用,2009,30 (3):37-43.]
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
開放教育研究(2020年2期)2020-03-31 01:54:14
Coco薇(2017年11期)2018-01-03 20:59:57
財經(2017年2期)2017-03-10 14:35:35
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
財經(2016年15期)2016-06-03 07:38:02
現代語文(2016年21期)2016-05-25 13:13:44
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
