基于用戶情境聚類的Web服務發現方法研究
2012-11-30 03:18:46楊岳明陳立潮謝斌紅潘理虎
計算機工程與設計 2012年4期
楊岳明,陳立潮,謝斌紅,潘理虎
(1.太原科技大學 計算機科學與技術學院,山西 太原030024;2.晉中師范高等專科學校 現代信息技術系,山西 晉中030600)
0 引 言
由于提供相同功能的Web服務越來越多,Web服務發現的研究重點逐漸由功能發現轉向了非功能發現,即在功能發現的基礎上,快速發現用戶適合度較高的Web服務。目前已有相關文獻在非功能性Web服務發現方面進行了描述。文獻 [1-3]對語義 Web服務集合進行了聚類預處理,有效縮小了服務查找范圍,從而提高了Web服務發現的效率。文獻 [4-5]借助邏輯推理功能,實現對情境/語境信息的相關推理,從而能夠自動地找到適宜用戶的服務。文獻 [6-14]利用本體為情境信息建模,服務發現主要采用本體映射和本體推理的方法。首先對直接感知到的用戶情境進行推理,得到與用戶相關的隱含的情境,然后將用戶隱含情境信息與服務描述模型直接匹配,從而發現對用戶合適的服務。文獻 [15]提出了使用倒排索引優化面向組合的語義服務發現方法,該方法利用倒排索引的優勢,極大地減少了搜索空間,從而能夠快速定位侯選服務。
通過對現有文獻進行分析,目前的Web服務發現方法存在以下不足:
(1)用戶信息利用率不高。在目前的Web服務發現方法中,當前用戶信息承擔了服務過濾的角色,在服務發現時,其推理關系僅是服務語義的擴展。這些方法沒有充分利用歷史用戶信息及其與當前用戶信息之間的關系進行服務發現,而與當前用戶有關的歷史用戶信息對服務發現具有重要的價值。
(2)沒有兼顧時間效率和用戶適合度。文獻 [1-3]對語義Web服務進行聚類的服務發現方法,雖然在一定程度上提高了Web服務發現的時間效率,但不能保證服務發現結果對用戶的適合度。文獻 [4-14]借助邏輯推理的服務發現方法,雖然提升了服務發現結果對用戶的適合度,但不能保證服務發現的時間效率。
針對以上不足,本文提出了一種基于用戶情境聚類的Web服務發現方法,該方法實現了相似情境用戶的聚類,并利用倒排索引快速得到了用戶適合度較高的Web服務。
1 基于用戶情境的本體建模
一般來講,用戶情境指的是用戶自身及所處的環境信息,它既有動態的信息,也有靜態的信息。為了充分利用用戶情境信息進行Web服務發現,需要對這些動態和靜態的信息進行刻畫。本體是共享概念的形式化的規范描述,為了刻畫用戶情境信息,本文采用本體來為用戶情境建模。
用戶情境本體要能盡量全面準確地描述用戶的情境信息,本文的用戶情境本體模型 (如圖1所示)包括用戶描述、環境和平臺3部分。
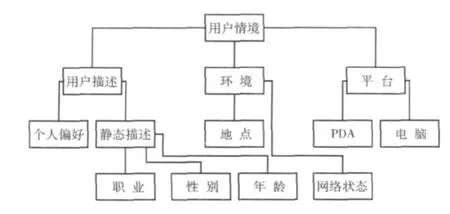
圖1 用戶情境本體
用戶情境形式化描述如下:
U (UserDiscription,Environment,Platform)
其中UserDiscription表示用戶描述,包括用戶靜態描述和個人偏好,即:
UserDiscription= (StaticDiscription,Preference)
而StaticDiscription又可以從職業、性別和年齡等方面來描述,即:
StaticDiscription= (Professional,Sex,Age)
Environment表示環境,包括地點和網絡狀態,即:
Environment= (Location,NetworkStatus)
Platform表示平臺,包括PDA和電腦,即:
Platform= (PDA,Computer)
2 基于用戶情境的聚類算法
聚類是數據挖掘領域的一個術語,它是指對一個對象集合進行不斷分類,從而最終形成若干個集合,同一集合中的對象相似度很大,不同集合中的對象相似度很小。通過對大量用戶情境信息及服務發現結果的分析,發現情境相似的用戶所使用的Web服務具有較大的相似性。基于該特點,在進行Web服務查找之前可以預先進行用戶的聚類,從而形成若干用戶類,使Web服務的查找局限于當前用戶所在類,這樣Web服務發現的效率就可以進一步提高。
在對用戶情境進行聚類處理中,本文借助BIRCH聚類算法得到了基于用戶情境的聚類思想,即初始時每一個對象都看成是一個單獨的新聚類,在接下來的迭代中,把那些類相似度大于閾值的類合并成一個新聚類,直到滿足某個條件為止,其中類相似度為兩個類中用戶情境相似度的最小值。基于用戶情境的相似度計算公式為:
SimUserContext=Sim (UserDis,UserDis)*W1+Sim (Env,Env)*W2+Sim (Platf,Platf)*W3
式中:W1——用戶描述權重,W2——環境權重,W3——平臺權重,W1+W2+W3=l。公式中涉及的本體概念間的相似度計算方法可以參閱文獻 [16-18],本文不在重復。
在上述基礎上,本文提出的基于用戶情境的聚類算法描述如下:
算法1:基于用戶情境的聚類算法
輸入:用戶情境信息
輸出:用戶類的集合
Begin
Get(UserContext);//獲取用戶情境信息及其權重
初始化新聚類U= {(U1), (U2),…, (Un)}及閾值N;
Do{
Val(Degree_SimCluster); //計算類相似度
將類相似度大于閾值N的聚類合并;
閾值N減少一個固定值;
}While(特定用戶所在類的對象個數小于某固定值K);//K值依據歷史用戶總數取值而定
Return (U);
End
3 服務發現算法
Web服務發現面臨的挑戰是如何快速發現用戶滿意度較高的服務,本文利用情境相似的用戶使用的Web服務具有較大相似性的特點,給出了一個基于用戶情境聚類的Web服務發現流程框架 (如圖2所示)。
為了實現圖2的服務發現流程框架,具體的服務發現算法描述如下:
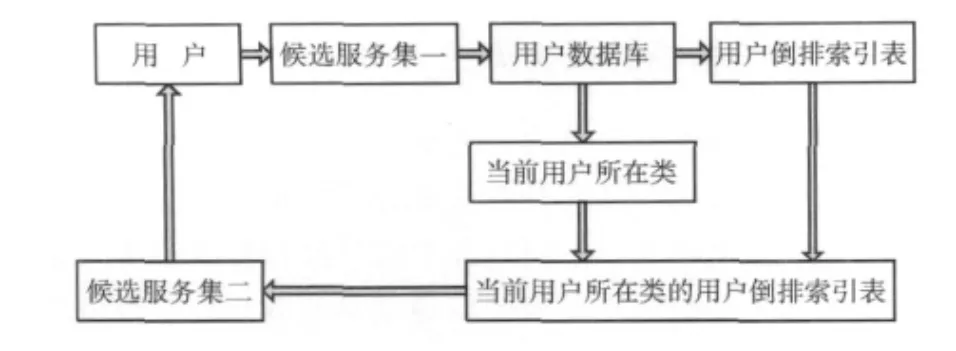
圖2 服務發現流程框架
算法2:基于用戶情境聚類的Web服務發現算法
輸入:用戶服務請求
輸出:滿足用戶個性化需求的服務集合
Begin
Request(User.need); //用戶提出服務請求
Function(All Web Service)==>C1= {S1,S2,…,Sn}; //進行Web服務功能發現得到侯選服務集一
Create(User_database);//創建用戶數據庫
C1.Si.history_user&&current_user==> User_database; //將當前用戶信息與侯選服務集一中所有服務的歷史用戶信息同時加入用戶數據庫中
Create(User_InvertedIndexList); //依據用戶數據庫創建用戶倒排索引表,包括用戶和服務及使用頻率
Cluster(User_database.UserContext); //對用戶數據庫,采用算法1對用戶進行聚類
Select (User_InvertedIndexList.CurrentUserClass);//篩選出當前用戶所在類的用戶倒排索引表
Add (Ui.Si.UseFrequency); //統計當前用戶所在類的所有服務的使用頻率
Sort(Si.UseFrequency)==>C2= {…,Si,…,};//按使用頻率降序排序,得到侯選服務集二
Return(C2); //將服務發現結果返回給用戶
End
4 實例分析
下面通過一個實例來說明如何利用本文方法進行服務發現。我們采用SQL Server 2005存儲200個Web服務,其中包括10個天氣預報Web服務。假設有一個山西晉中的用戶,他想使用一個Web服務來查詢天氣情況。
采用文獻 [1-3]的語義聚類 Web服務發現方法,服務發現結果僅局限于能夠快速發現10個天氣預報服務,即侯選服務集:(S1,S2,S3,S4,S5,S6,S7,S8,S9,S10)。
采用本文方法的服務發現過程如下:
步驟1:山西晉中的用戶提出查詢天氣情況的請求。
步驟2:進行天氣預報的Web服務發現,得到侯選服務集一:(S1,S2,S3,S4,S5,S6,S7,S8,S9,S10)。
步驟3:創建用戶數據庫,并將當前用戶情境信息與侯選服務集一中所有服務的歷史用戶情境信息同時加入用戶數據庫中 (如表1所示)。由于天氣預報服務提供者給出用戶位置信息是關鍵因素,因此為了減少用戶情境信息的復雜度,表1中用戶情境信息只列出了位置信息,其中Ui(i=1,…,10)代表歷史用戶,U代表當前用戶。

表1 用戶數據庫
步驟4:依據表1建立用戶倒排索引表 (如表2所示)。
步驟5:利用算法1,對表1中的用戶進行聚類 (設置K=3)。
初始化聚類:(U1) (U2) (U3) (U4) (U5) (U6)(U7)(U8)(U9)(U10)(U);
第一次聚類:(U1,U9)(U2,U5)(U3)(U4,U8)(U6)(U7,U)(U10);
第二次聚類:(U1,U9,U10)(U2,U5)(U3,U4,U8)(U6)(U7,U);
第 三次聚類:(U 1,U 9,U 1 0)(U 2,U 5,U 7,U)(U3,U4,U8)(U6)。
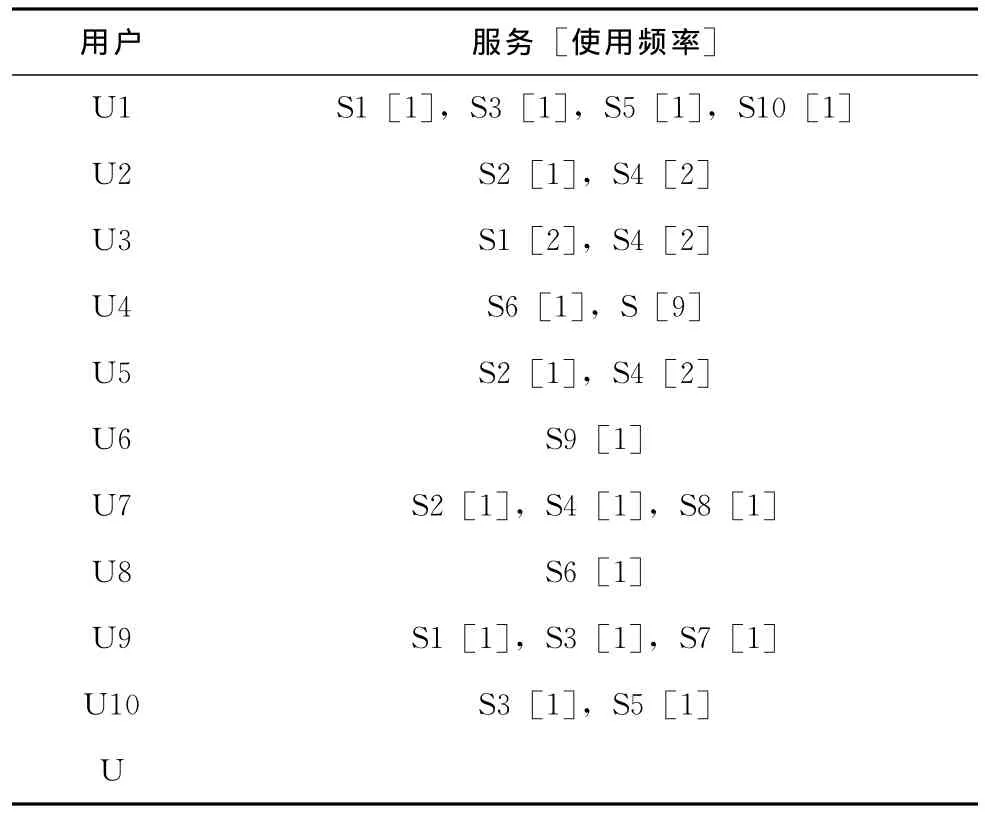
表2 用戶倒排索引表
步驟6:按當前用戶所在類進行篩選,得到當前用戶所在類的倒排索引表 (如表3所示)。

表3 當前用戶所在類的倒排索引表
步驟7:統計當前用戶所在類的所有服務的使用頻率:S2 [3],S4 [5],S8 [1]。
步驟8:按使用頻率降序排序,得到侯選服務集二:S4,S2,S8。
步驟9:將侯選服務集二返回給用戶。
最終,山西晉中的用戶可以優先使用S4,其次是S2。與文獻 [1-3]的方法相比,本文的方法有效提升了服務發現結果對用戶的適合度。
5 實驗分析
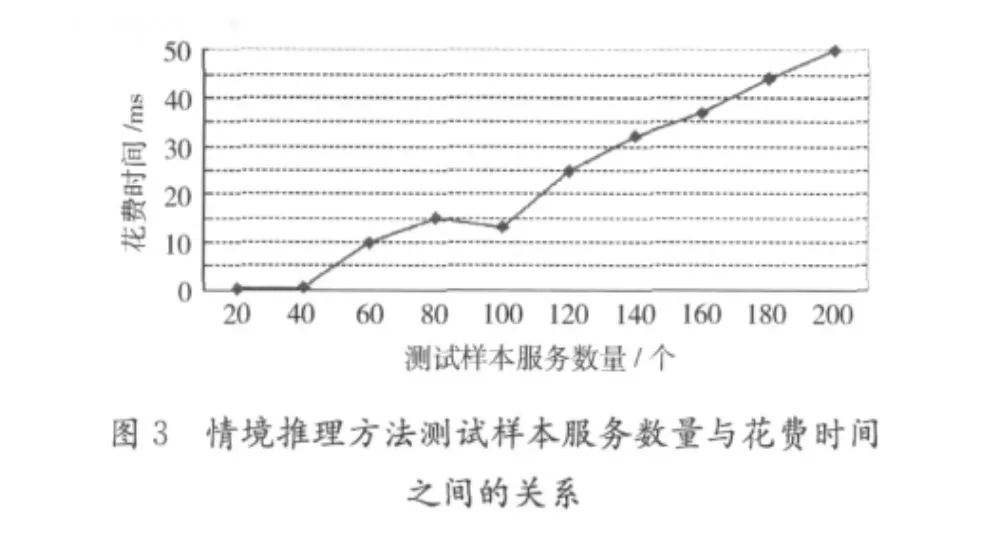
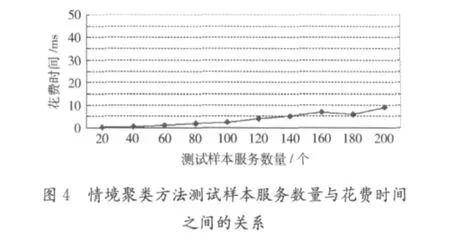
為了驗證本文方法在服務發現時間方面的優越性,將本文方法與文獻 [4]的情境推理方法進行比較,分別測試它們的花費時間。最初選取了20個服務作為測試樣本,然后每次遞增20個服務,共選取了10個樣本集。進行了10組實驗,記錄了每次實驗所花費的時間,分別得到了采用兩種方法的測試樣本服務數量與花費時間之間的關系,如圖3和圖4所示。
實驗結果表明,兩種服務發現方法所花費的時間都隨測試樣本服務數量的增加呈線性增長,而本文的方法在時間花費方面明顯優于文獻 [4]的情境推理方法。這說明本文的方法有效提升了服務發現的時間效率。
6 結束語
本文提出了一種基于用戶情境聚類的Web服務發現方法。該方法在功能發現的基礎上,構建了用戶情境本體模型,通過對情境相似的用戶進行聚類,將服務查找范圍局限于當前用戶所在的類,并利用倒排索引將該類中歷史使用頻率較高的Web服務提供給當前用戶。實例分析和實驗結果表明,使用該方法可以快速得到用戶適合度較高的Web服務。但是,本文的方法是基于用戶的角度進行了服務發現,沒有考慮服務本身的特性,在一定程度上影響了服務發現的效率。這將是我們下一步所要研究的問題。
[1]HE Chaobo,CHEN Qimai.Fast approach for semantic web service discovery [J].Computer Engineering and Design,2010,31 (12):2936-2939 (in Chinese). [賀超波,陳啟買.快速語義Web服務發現方法 [J].計算機工程與設計,2010,31 (12):2936-2939.]
[2]SUN Ping,JIANG Changjun. Using service clustering to facilitate process-oriented semantic web service discovery [J].Chinese Journal of Computers,2008,31 (8):1340-1353 (in Chinese).[孫萍,蔣昌俊.利用服務聚類優化面向過程模型的語義 Web服務發現 [J].計算機學報,2008,31 (8):1340-1353.]
[3]LIU Xingwei,YAO Shuhuai.A DHCS-based discovery mechanism of semantic web services [J].Computer Applications andSoftware,2007,24 (7):173-177 (in Chinese). [劉興偉,姚書懷.基于層次聚類的語義 Web服務發現算法 [J].計算機應用與軟件,2007,24 (7):173-177.]
[4]FENG Zaiwen,HE Keqing,LI Bing,et al.A method for semantic web service discovery based on context inference [J].Chinese Journal of Computers,2008,31 (8):1354-1363 (in Chinese).[馮在文,何克清,李兵,等.一種基于情境推理的語義Web服務發現方法 [J].計算機學報,2008,31 (8):1354-1363.]
[5]NIU Wenjia,CHANG Hang,WANG Xiaofeng,et al.Semantic web service discovery based on context and action reasoning[J].Pattern Recognition and Artificial Intelligence,2010,23(1):65-71 (in Chinese).[牛溫佳,常亮,王曉峰,等.基于語境和動作推理的語義 Web服務發現 [J].模式識別與人工智能,2010,23 (1):65-71.]
[6]JIN Zhi,LIU Lin.Web service retrieval:An approach based on context ontology [C].Chicago,USA:Proceedings of the 30th Annual International Computer Software and Applications Conference,2006:513-520.
[7]Aimrudee Jongtaveesataporn,Twittie Senivongse.A context type model for context_aware discovery of web services [C].The Third IASTED International Conference on Advances in Computer Science and Technology.Anaheim,CA,USA:ACTA Press,2007:96-101.
[8]YANG Stephen J H,ZHANG Jia,CHEN Irene Y L.A JESS-enabled context elicitation system for providing context-aware web services [J].Expert Systems with Applications,2008,34 (4):2254-2266.
[9]Christos Doulkeridis,Nikos Loutas,Michalis Vazirgiannis.A system architecture for context-aware service discovery [J].Electronic Notes in Theoretical Computer Science,2006,146(1):101-116.
[10]HAN Weili,SHI Xingdong,CHEN Ronghua.Process-context aware matchmaking for web service composition [J].Journal of Network and Computer Applications,2008,31(4):559-576.
[11]HONG Jongyi,Suh Euiho,KIM Junyoung,et al.Contextaware system for proactive personalized service based on context history [J].Expert Systems with Applications,2009,36 (4):7448-7457.
[12]Alessandra Toninelli,Antonio Corradi,Rebecca Montanari.Semantic-based discovery to support mobile context-aware service access [J].Computer Communications,2008,31(5):935-949.
[13]LI Li,LIU Dongxi,Athman Bouguettaya.Semantic based aspectoriented programming for context-aware web service composition[J].Information Systems,2011,36 (3):551-564.
[14]Christos Doulkeridis,Michalis Vazirgiannis.CASD:Management of a context-aware service directory [J].Pervasive and Mobile Computing,2008,4 (5):737-754.
[15]KUANG Li,DENG Shuiguang,LI Ying,et al.Using inverted indexing to facilitate composition-oriented semantic service discovery [J].Journal of Software,2007,18 (8):1911-1921(in Chinese). [鄺礫,鄧水光,李瑩,等.使用倒排索引優化面向組合的語義服務發現 [J].軟件學報,2007,18 (8):1911-1921.]
[16]WANG Gang,QIU Yuhui.Study on text clustering based on ontology and similarity [J].Application Research of Computers,2010,27 (7):2494-2497 (in Chinese).[王剛,邱玉輝.基于本體及相似度的文本聚類研究 [J].計算機應用研究,2010,27 (7):2494-2497.]
[17]XU Dezhi,WANG Huaimin.Concept semantic similarity research based on ontology [J].Computer Engineering and Applications,2007,43 (8):154-156 (in Chinese). [徐德智,王懷民.基于本體的概念間語義相似度計算方法研究 [J].計算機工程與應用,2007,43 (8):154-156.]
[18]ZHANG Gongjie,ZHAO Xiangjun,CHEN Kejian.Ontology oriented semantic similarity calculation and application in retrieval[J].Computer Engineering and Applications,2010,46 (29):131-133 (in Chinese).[張功杰,趙向軍,陳克建.面向本體的語義相似度計算及在檢索中的應用 [J].計算機工程與應用,2010,46 (29):131-133.]
猜你喜歡
福建中學數學(2023年5期)2024-01-25 17:41:36
中學生數理化·中考版(2022年10期)2022-11-10 09:37:46
開放教育研究(2020年2期)2020-03-31 01:54:14
護士進修雜志(2017年3期)2017-02-14 07:19:35
商用汽車(2016年11期)2016-12-19 01:20:16
小學生作文(中高年級適用)(2016年3期)2016-11-11 06:30:23
商用汽車(2016年6期)2016-06-29 09:18:54
現代語文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
