基于情境上下文的智能虛擬裝配動作預測模型
2013-07-03 00:44:56曹兆元劉惠義楊戰軍
計算機工程與設計 2013年4期
曹兆元,劉惠義,楊戰軍,2,鄭 源
(1.河海大學 計算機與信息學院,江蘇 南京 210098;2.中國人民解放軍92995部隊,山東 青島266100;3.河海大學 能源與電氣學院,江蘇 南京 210098)
0 引 言
虛擬裝配是虛擬現實技術在制造業的典型應用[1]。然而,現有虛擬裝配系統普遍缺乏對復雜情境的分析能力,難以根據上下文準確預測用戶的意圖,導致系統智能性低下,用戶認知負荷較重。
目前,智能虛擬裝配已成為一個研究熱點,科研人員開展了深入的研究。文獻[2]將感知機制引入到虛擬裝配,給出了虛擬交互的感知模式和感知算法;文獻[3-5]將語義引入虛擬裝配,實現了裝配工程語義的虛擬表示,并通過語義的推理和識別來捕捉裝配過程中用戶的操作意圖;文獻[6]提出建立虛擬裝配環境約束信息模型的方法,引入了約束元素包圍盒的概念,將約束元素包圍盒的相交測試作為裝配意圖捕捉算法的入口;文獻[7]給出了一種面向虛擬裝配的框架數據模型,將過程性知識封裝到過程框架中,將零件模型中的工程信息封裝到特征框架中,將框架實例對象與產品層、顯示層中的數據對象一起構成框架數據模型。然而,這些方法都只是從零件配合和操作真實性的角度對交互進行完善,沒有充分運用情境上下文信息,用戶的認知負荷依然較重。文獻[8-9]將情境上下文引入了虛擬裝配,給出了基于本體的情境感知體系結構框架,對智能裝配的情境信息本體建模及其感知機制進行了較為深入的研究,但模型中基于本體的裝配語義推理顯得比較抽象和復雜。
本文提出一種基于情境上下文的智能虛擬裝配動作預測模型。該模型運用了情境上下文信息,有效降低了用戶的認知負荷;通過實例進行用戶動作意圖預測,簡化了推理過程的復雜性;并結合水輪發電機組的轉輪體裝配實例,給出了模型的實現框架。最后通過實驗驗證了模型的正確性。
1 虛擬裝配中的情境上下文
情境上下文(Context)為智能虛擬裝配提供信息支持,包括三類上下文:環境上下文(Environment Context,EC)、任務上下文(Task Context,TC)和用戶上下文(User Context,UC),形式化表示為
Context=〈EC,TC,UC〉
EC涉及虛擬裝配仿真的領域(domain),界面上可顯示的零部件(presentation)以及交互設備(device)等,形式化描述為
EC=〈domain,presentation,device〉
TC包括系統所要完成的裝配任務(task),任務中涉及的零部件(parts)以及一系列的原子動作(包括動作的類型(type)、名稱(name)和描述(description)),形式化定義為
TC=〈task,parts,type,name,description〉
UC用于刻畫正在進行虛擬裝配的用戶,形式化表示為
UC=〈user〉,user∈UserSet
UserSet為所有使用本系統的用戶集合。
Context中,EC中的裝配領域知識為TC 定義虛擬裝配的任務以及任務中的一系列裝配動作提供了依據;TC 中裝配動作的定義是UC 中記錄用戶經驗的基礎。三者關系如圖1所示。

圖1 EC、TC、UC之間的關系
根據Context的定義,基于情境上下文的智能虛擬裝配動作預測模型(An Intelligent Action Prediction Model of Virtual Assembly Based on Context Awareness,IAPMVACA)的組成元素包括:環境模型(Environment Model,EM)、任務模型(Task Model,TM)、用 戶模型(User Model,UM),形式化定義為
IAPMVACA=〈EM,TM,UM〉
EM 描述了系統中的零部件實體對象(Entity)、對象之間的裝配關系(Assembly Relationship,ARS)、界面上的可視零部件(Visual Components,VCP)以及系統所使用的交互設備(Device),形式化表示為
EM=〈{Entity},{ARS},{VCP},{Device}〉
TM 描述了虛擬裝配所能完成的任務編號(TaskID)和名稱(TaskName)以及具體的交互過程({Action}),形式化描述為

式中:ActionID——動作編號,ActionName——動作名稱,ObjectID——動作作用零部件的編號,Time——動作發生的時間,Description——動作的描述。例如平移(Translate)操作時,Description=〈start,end〉,start表示起始位置,end 表示終點位置;旋轉(Rotate)操作時,Description=〈axis,direction,angle〉,axis表示旋轉所繞的軸線,direction表示旋轉的方向,有順時針和逆時針兩種,angle表示旋轉的角度。
UM 描述了用戶編號(UserID)和角色(Role)以及用戶經驗(Experience),形式化定義為

2 用戶動作意圖預測算法
基于情境上下文的動作預測重點就是通過研究用戶經驗,發現裝配過程中存在的動作模式,再結合當前的情境上下文對將來的動作進行預測。參照文獻[10]中基于經驗感知的自適應用戶界面的動作預測方法,給出基于情境上下文的智能虛擬裝配動作預測方法,分為3個步驟:①構建動作模式;②動作預測;③決策與反饋。
2.1 構建動作模式
構建動作模式的總體思想如下:在完成一個裝配任務的情況下,針對一個動作序列,如果是第一次出現則作為預動作模式,再次出現后就作為動作模式添加到模式庫。假設某個零部件正在執行當前裝配任務的最后一個動作a,定義零部件已經執行過的動作集合為C,新動作的集合為E,則算法過程如下:
(1)若a∈E,則執行(2);否則,若a∈C,則執行(6),否則執行(3)。
(2)從用戶經驗中取出以a為結束項的動作序列作為預動作模式Spre,將a從E 中取出,轉向(5)。
(3)將當前以a為結束項的動作序列與Spre進行比較,其中相同的動作部分即為以a為結束項的動作模式S。
(4)把S 加入到模式庫中,若a瓟C,將a加入到C 中。
(5)繼續執行下一個裝配任務,轉向(1)。
(6)對于以a為結束項的用戶經驗動作序列,如果在模式庫中存在與它局部匹配的動作模式,則產生一個新的動作模式S,轉向(4);否則,該動作序列中存在一個新的動作模式,轉向(2)。
2.2 動作預測
假設需要動作預測的零部件的動作模式最大長度為L,則算法步驟如下:
(1)取長度l=1的動作序列S,將模式庫中所有的動作模式與S 比較,找出所有匹配序列的下一個動作,得到初始預測集C={〈Ci,i〉|i∈[1,l]}。
(2)若l>L,轉向(4),否則轉向(3)。
(3)令l=l+1,將當前的動作序列反向向前讀取一個動作,則當前動作序列達到新的長度l,依次從C 中取出預測Ci,加到當前動作序列之后,產生了新的長度為l+1的動作序列Si,查找模式庫,如果存在i∈[1,l],則更新C的序列長度,轉(2)。
(4)令Clong=Ci作為最終的預測候選。
2.3 決策與反饋
若最終有多個預測候選,則需要決策器進行決策。可以統計每個預測候選在所有成功用戶經驗中的發生概率,由概率的大小來決定執行哪個預測。
假設當前共有成功用戶經驗N 條,某個預測候選共執行過n次,則發生概率
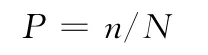
將所有預測候選按P 由大到小排列,選擇P 最大的動作推薦給系統。如果最終沒有預測推薦,則首先用戶手動完成此次裝配任務,再通過評價器反饋回來,提醒系統進行模式庫的更新。
3 裝配應用實例
以軸流式水輪發電機組的轉輪體(組織結構如圖2所示,裝配關系如圖3所示)裝配為例,假設矩形框中的零部件已參與過裝配,形成了部件2(unit2),下面將進行活塞(piston)的裝配。按照裝配工藝,是將unit2裝配到piston上。
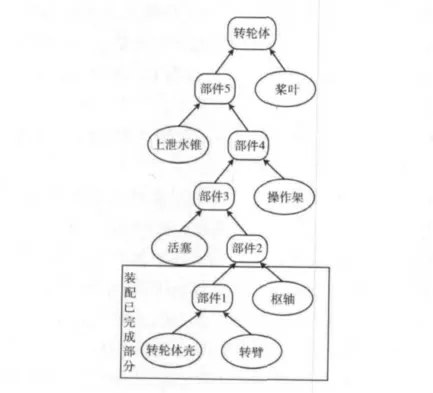
圖2 轉輪體組織結構
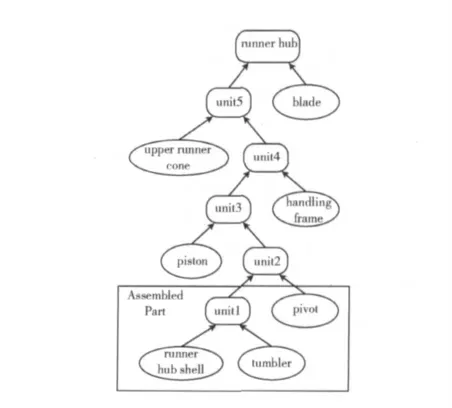
圖3 轉輪體裝配關系
3.1 獲取情境上下文
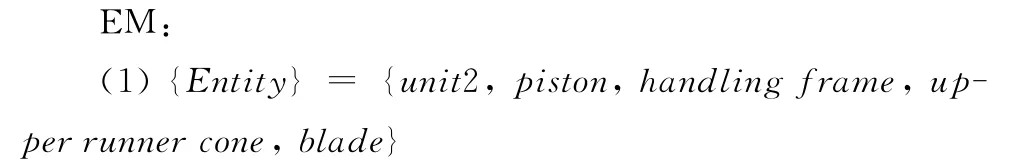
(2){ARS}通過XML(Extensible Markup Language)文檔定義如下:

(3){VCP}主要根據系統需要,在界面中設置零部件為隱藏/顯示。可以在定義零部件屬性時設置一個visible變量,visible=0表示隱藏;visible=1表示顯示。
(4)本系統為桌面式虛擬裝配系統,{Device}={keyboard,mouse,computer}。

UM:UserID=1,Role=student,該模型重點是記錄用戶經驗,由系統在使用過程中自動完成。
3.2 用戶動作意圖推理
假設系統通過對用戶經驗的挖掘,發現裝配活塞有如下三種動作模式:

假設前11次裝配活塞全部成功,在第12次進行裝配時,動作的發生順序是Select、Translate,則排除Mode1,預測結果有Rotate和Translate 兩種。根據成功用戶經驗統計,前11次的第3步操作中,Rotate出現4次,Translate出現2次,PRotate=4/11,PTranslate=2/11,PRotate>PTranslate,則最后系統反饋的就是Mode2中的Rotate操作。
3.3 模型實現框架
基于文獻[9]中本體情境感知框架的情境感知層、情境服務層和情境應用層的分層思想,參照文獻[10]中自適應用戶界面數據層、模型層、自適應層和用戶界面層的四層體系架構,通過對體系架構層次和推理引擎部分的改進,給出基于情境上下文的智能虛擬裝配動作預測模型的實現框架,如圖4所示。
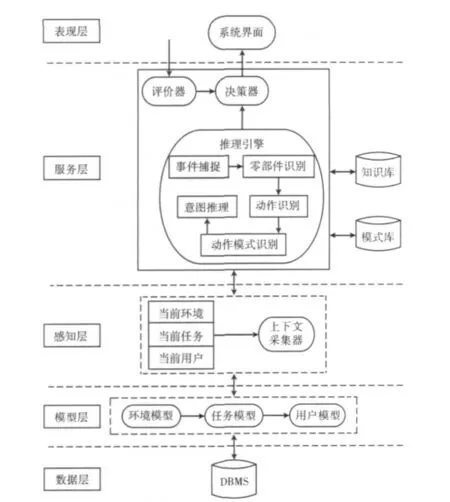
圖4 IAPMVACA 實現框架
該框架一共分為5層:底層為數據層,中間層為模型層、感知層、服務層,上層為表現層。
數據層中以數據庫表格保存著任務模型、用戶模型的數據信息以及整個智能裝配系統所涉及的零部件的屬性信息。模型層描述了系統進行動作預測所需要的信息集合,分為環境模型、任務模型和用戶模型三部分。感知層主要負責情境上下文的采集,作為用戶動作意圖推理的基礎。服務層由知識庫、模式庫以及推理模塊和決策模塊組成,知識庫以XML文檔保存著裝配關系;模式庫是系統數據庫的一部分,保存從用戶經驗中挖掘出得用戶動作模式;推理引擎通過系統事件消息處理機制捕捉事件,對相關零部件進行識別,進一步識別出當前正在進行的動作,將識別結果傳入動作模式識別模塊,再結合知識庫和模式庫對動作意圖進行推理;決策器基于傳入的預測候選,結合用戶經驗進行決策。表現層的系統界面上呈現最終的結果。
框架以通信的方式實現各層之間的關聯:感知層獲得的消息通過消息事件引擎轉換成用戶經驗,并為系統提供情境上下文。推理引擎模塊通過不間斷的分析用戶經驗和當前情境上下文,再依據知識庫以及模式庫中的內容,為系統提供智能虛擬裝配的動作預測功能。總之,服務層通過連續不斷的與上下各層進行通信,實現了智能虛擬裝配的動作預測功能。
4 實驗與分析
基于模型的實現框架,通過3DMax 三維建模,采用Visual Studio 2005開發工具和OpenSceneGraph渲染引擎,利用SQL Server 2000數據庫以及XML 技術開發了一個軸流式水輪發電機組轉輪體裝配的原型系統。其中某次裝配活塞的過程如圖5所示。
初始場景(a)中,unit2 處于(0,0,0)位置,piston處于(100,100,0)位置;(b)中用戶手動選中unit2,將其平移到(0,0,62);(c)中令unit2沿x軸順時針旋轉180度,根據3.2中的分析,此時系統已經推斷出unit2將執行Mode2,于是自動先平移至(100,100,62),再平移至(100,100,6),成功實現活塞的裝配,如(d)、(e)所示。圖5證明了用戶意圖推理的合理性,進而驗證了基于情境上下文的智能虛擬裝配動作預測模型的正確性。
5 結束語
本文將情境上下文的理論應用到虛擬裝配中,建立了基于情境上下文的智能虛擬裝配動作預測模型,結合實例分析,給出了模型的實現框架。實驗結果表明,該模型能夠準確預測用戶的動作意圖,實時調整零部件的動作以自動完成裝配。
相較于前人所做的工作,本文的創新如下:①記錄了虛擬裝配中的情境上下文,為智能虛擬裝配奠定了基礎;②進行基于實例的裝配動作預測,使推理更加直觀、清晰;③給出了動作預測模型的實現框架,為應用提供了方便。進一步的工作將從任務模型中獨立出交互模型,將環境模型細化成領域模型和表示模型,使模型層中的層次更豐富。

圖5 裝配活塞的過程
[1]XIA Pingjun,CHEN Peng,LANG Yuedong,et al.Study on virtual assembly technology:A survey[J].Journal of System Simulation,2009,21(8):2267-2272(in Chinese).[夏平均,陳朋,郎躍東,等.虛擬裝配技術的研究綜述[J].系統仿真學報,2009,21(8):2267-2272.]
[2]CHENG Cheng.Research on construction of mating perception in virtual assembly[J].Journal of Computer Research and Development,2002,39(10):1331-1336(inChinese).[程成.虛擬裝配中面貼合感知構造研究[J].計算機研究與發展,2002,39(10):1331-1336.]
[3]WANG Hui,XIANG Dong,DUAN Guanghong,et al.Assembly planning based on semantic modeling approach[J].Computers in Industry,2007,58(3):227-239.
[4]CHENG Cheng,XU Zhenling,LI Yan.Semantic space construction for virtual assembly[C]//International Conference on Computer Science and Software Engineering.Washington DC:IEEE Computer Society,2008:1110-1113.
[5]XIA Zhixiang,ZHU Hongmin,WU Dianliang,et al.Reasoning method based on semantics for virtual assembly operation[J].Computer Integrated Manufacturing Systems,2009,15(8):1606-1613(in Chinese).[夏之祥,朱洪敏,武殿梁,等.虛擬裝配操作中基于語義的推理方法研究[J].計算機集成制造系統,2009,15(8):1606-1613.]
[6]ZHANG Dan,ZUO Dunwen,JIAO Guangming,et al.Constraint modeling and assembly intention capturing technology for virtual assembly[J].Computer Integrated Manufacturing Systems,2010,18(6):1208-1214(in Chinese).[張丹,左敦穩,焦光明,等.面向虛擬裝配的約束建模與裝配意圖捕捉技術[J].計算機集成制造系統,2010,18(6):1208-1214.]
[7]WU Changsheng,WANG Daiyong,DAI Yingming,et al.Data model of virtual assembly based on framework theory[J].Journal of System Simulation,2011,23(10):2163-2168(in Chinese).[吳昌盛,汪代勇,代英明,等.面向虛擬裝配的框架數據模型研究[J].系統仿真學報,2011,23(10):2163-2168.]
[8]LI Tiemeng,HOU Wenjun,PAN Hao.Put context-aware in virtual assembly:A study of ontology-based architecture and an arithmetic[C]//The 4th International Conference on Pervasive Computing and Applications.Taiwan:Tamkang University,2009:503-506.
[9]HOU Wenjun.Study on intelligent virtual assembly system and the related key technologies based on context-aware[D].Beijing:Beijing University of Posts and Telecommunications,2010(in Chinese).[侯文君.基于情境感知的智能虛擬裝配系統若干關鍵技術研究[D].北京:北京郵電大學,2010.]
[10]FAN Yinting,TENG Dongxing,YANG Haiyan,et al.An adaptive user interface model based on experience awareness[J].Chinese Journal of Computers,2011,31(11):2211-2223(in Chinese).[樊銀亭,滕東興,楊海燕,等.基于經驗感知的自適應用戶界面模型[J].計算機學報,2011,31(11):2211-2223.]
猜你喜歡
福建中學數學(2023年5期)2024-01-25 17:41:36
中學生數理化·中考版(2022年10期)2022-11-10 09:37:46
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
護士進修雜志(2017年3期)2017-02-14 07:19:35
