基于Web的DCI垂直搜索引擎的研究與設計
2013-07-03 00:45:10吳潔明冀單單韓云輝
計算機工程與設計 2013年4期
吳潔明,冀單單,韓云輝
(北方工業大學 信息工程學院,北京 100144)
0 引 言
在互聯網飛速發展的今天,互聯網上的信息更是浩如煙海,據互聯網數據中心于2010年的一則報道,2010年底全球數字信息總量將達到1.2ZB,預計到2020年這個數字將達到3.5ZB,其增長速度超過摩爾定律[1]。針對海量的數字信息,如何快速準確的獲得有用的信息成為研究的重點。基于國際數字出版領域認可度較高的資源定位解析方案是美國出版者協會于1988年制定的數字對象唯一標識符DOI(Digital Object Identifier)標準,中國版權保護中心在深入研究國際現有的版權保護技術、相關的法規和標準后,結合數字資源出版服務領域的發展趨勢,提出了數字作品版權唯一標識符(DCI),用于解決數字作品產業鏈中各個參與者的利益分享、技術創新和高效的維權機制[2]。目前,國內對于DCI的研究處于初級階段,本文就是圍繞這一問題,在Lucene開源技術、數據采集、信息抽取和索引搜索等基礎上,設計實現用于解決互聯網上海量DCI數據的垂直搜索引擎。
1 搜索引擎相關概述
1.1 垂直搜索引擎
根據數據收錄范圍不同,將搜索引擎分為通用搜索引擎和垂直搜索引擎。最常見的通用搜索引擎有:百度、Google和搜狗等。垂直搜索引擎是針對某些特定領域的專業搜索引擎,是搜索引擎的細分和延伸,是對某種專業信息的整合,是針對某一特定領域、某一特定人群或某一特定需求,提供有一定價值的信息和搜索服務,準確搜索出用戶所需要的信息。垂直搜索引擎的特點就是“專、精、深”,且具有行業色彩[3]。由于垂直搜索引擎側重自己獨有專業信息的搜索,可以專注于自己的特長和核心技術,采用更有效的信息采集策略,保證信息技術的及時更新。因此在專業信息方面,垂直搜索引擎比通用搜索引擎有很明顯的優勢,常見的垂直搜索引擎有:汽車垂直搜索引擎、旅游垂直搜索引擎等。
1.2 Heritrix概述
Heritrix是用Java語言開發的開源網絡爬蟲框架,采取深度遍歷網站的資源數據,將資源數據采集保存到本地,分析采集到的每一個有效的URL 地址,并提交HTTP 請求,從而獲得相應的結果,最后生成本地文件和日志信息。Heritrix在抓取過程中可以用來獲取完整的、精確的站點內容的復制,將抓取的內容保存到本地而不做任何修改,數據采集結構如圖1所示,Heritrix的優點在于它的可擴展性和靈活性。
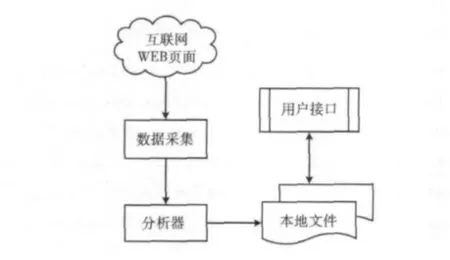
圖1 數據采集結構
1.3 Lucene概述
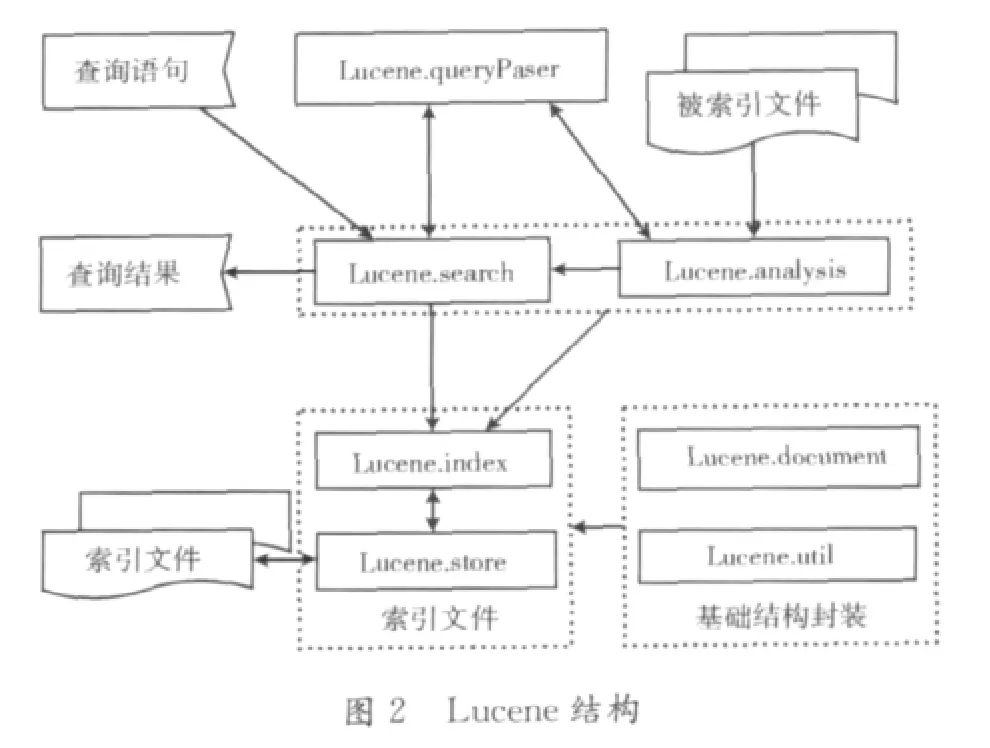
Lucene是跨平臺的用Java語言開發的一個開放源碼的全文檢索工具包。Lucene最初由Doug Cutting編寫,目的是為軟件開發人員提供簡單易用的應用程序接口,通過重載Searcher類、Analyzer類以及增加爬蟲系統等對象實現一個完整的搜索引擎系統[4]。關于Lucene的項目主要有:郵件列表管理系統Eyebrows中的檢索和歸檔、基于Web的論壇系統Jive和Eclipse的全文檢索部分等。Lucene的有點主要有:索引文件獨立于應用系統,采用倒排索引技術建立索引文件,提供豐富強大的API接口,如提供布爾查詢、模糊查詢和分組查詢等,其結構如圖2所示。
2 搜索引擎設計
2.1 DCI搜索引擎結構
基于Web的DCI垂直搜索引擎結構如圖3所示,采用的技術主要包括:數據采集、網頁信息抽取、索引器、檢索器等。
如圖3所示,DCI搜索引擎核心模塊包括:數據采集、網頁信息抽取、索引器和檢索器等。
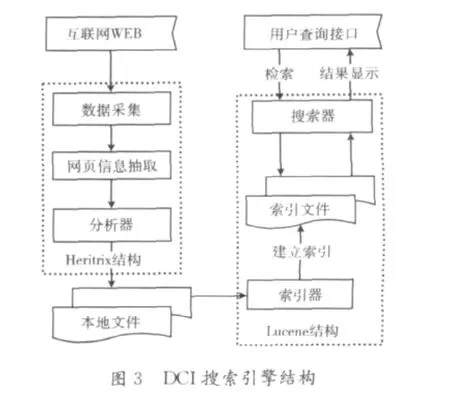
(1)數據采集:采用網絡爬蟲技術進行數據的采集,采用廣度優先算法,采集處理URL鏈接,采集完的數據保存在本地文件中;
(2)網頁信息抽取:遍歷所爬取到本地的網頁文件,先進行HTML文件的標記進行規范化處理,再讀取樹節點的純文本信息。
(3)索引器:將文本信息進行分詞處理,并采用倒排索引技術建立索引,并將生成的索引文件保存到本地;
(4)檢索器:對于用戶輸入的查詢關鍵詞在索引文件中進行檢索,將檢索結果按照排序算法返回給用戶。
2.2 Hits算法及數據采集
Hits 算 法(hyperlink-induced topic search )是由Kleinberg提出的基于超鏈接關系分析的網頁排名算法。提供了用于對網頁質量進行評估的兩種類型:權威型(authority)和目錄型(hub)。權威型網頁是指對于特定的搜索時,網頁提供最好的相關信息。目錄型網頁是指提供很多指向其他權威型網頁的超鏈接。Hits算法適用于處理頁面數量較少的情況,如網頁數量在幾萬以內是,速度較快,其針對的只是特定查詢主題的互聯網子圖,沒有考慮網頁的內容,當一個頁面里出現多個主題時會處理主題漂移現象。Hits算法的改進可以基于內容和超鏈接的分析相結合的主題相關度上分析處理,如對URL地址信息、錨文本信息、祖先網頁信息(網頁鏈接分析和內容分析)、頁面的深度(網頁超鏈接)等做為權重信息。
本文的數據采集采用的是基于廣度優先的數據采集過程,具體描述如下:
(1)在線程池中,選擇一個預定的URL;
(2)從選擇的URL 網址獲取文件內容;
(3)分析、歸檔下載到的內容,如果包函想要找的文字信息,則寫入磁盤鏡像目錄;
(4)從分析到的內容里面根據策略選擇URL,加入預定隊列;
(5)標記已經處理過的URL,己經處理過的URL 則不再處理;
(6)從第(1)步繼續進行,直到所有的URL 處理結束,抓取工作結束。
數據采集處理器鏈處理流程如圖4所示。
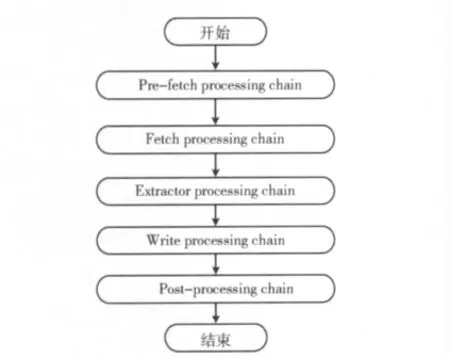
圖4 數據采集處理器鏈
(1)預取鏈:做準備工作,對抓取時的一些先決條件的判斷;
(2)提取鏈:獲得資源,解析網絡傳輸協議;
(3)抽取鏈:用于解析當前獲取的服務器返回的內容;(4)寫鏈:用于將抓取到的信息寫入磁盤;
(5)提交鏈:將解析出來的URL 有條件地加入到待處理隊列中。
2.3 網頁信息抽取
從內容上一個網頁一般包括導航信息、正文信息、廣告信息、版權信息和相關鏈接等,如果直接對整個網頁保存并建立索引,會降低檢索結果的精確度,為了使網頁的信息盡可能全面準確,本文先對網頁的所有部分的文本進行全部抽取,然后重點分析處理正文信息。網頁信息包括結構化和非結構化的信息,因此需要對其進行預處理,將其轉化為數據結構清晰、語義明確的格式。本文采用一種基于統計方法的信息抽取,這種方法適應于網頁中的正文信息放在table中,采用如下兩步:

(1)網頁規范化處理。根據網頁中規范的HTML 標記,可以把網頁表示成一棵樹型結構,網頁規范化處理主要內容如下:網頁中“<”和“>”只能用于表示標記,其他非標記的地方出現“<”和“>”時,全部用<和&gt替換;對所有的標記都保證其開始和結束相互配對出現;將標記中的屬性值放在一對引號中,如<a href="www.ncut.edu.cn"></a>的形式;多個標記之間不能交叉嵌套[5]。
(2)獲取節點信息。經過規范化處理的網頁,就可以表示成一個樹型結構,從屬性結果中獲取包含正文信息的節點。找到HTML 文檔中包含所有的table節點,遍歷每個節點并去除標記,得到不含有任何標記的純文本,并將得到的純文本信息保存在本地磁盤中,網頁文本信息抽取流程圖如圖5所示。
2.4 倒排索引
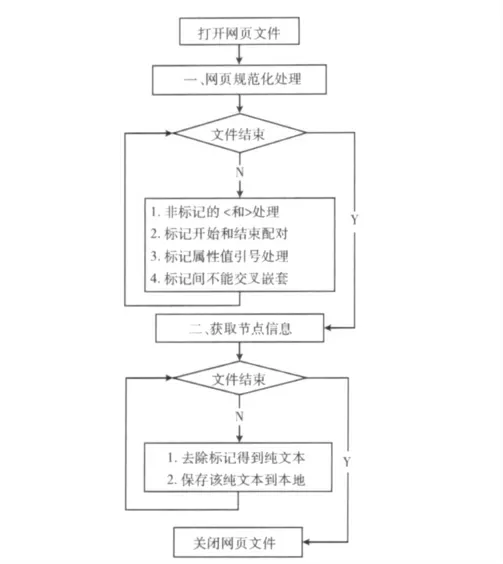
圖5 網頁信息抽取流程
在Lucene倒排索引中,項(Term)是最小的索引單位,它直接代表了一個關鍵詞以及其在文件中的出現位置和出現次數等信息,若干的項組成域(Field),域是一個關聯的元組,域是由一個域名和一個域值組成,若干的域組成文檔(Document),文檔是提取了某個文件中的所有信息之后的結果,若干的文檔組成段(Segment),內存中的段數量達到指定數量時將會合并成一個段,若干段組成子索引(Index),子索引可以組合為索引,也可以合并為一個新的包含了所有合并項的內部元素的子索引。在Lucene中采用段索引的生成方式,合并閾值影響著內存與硬盤中索引文件的個數。每添加一個Document將生成一段索引被內存持有,當段索引的個數超過合并閾值時,就會通過merge(合并)的過程將一段索引合并為段索引[6]。
例如有文本1和文本2:
文本1:research and design of vertical search engine.
文本2:research and implement of search engine.
首先對文本1和文本2提取關鍵詞,按照一般索引得到結果如表1所示,按照Lucene倒排索引得到結果如表2所示。由表1和表2可知,一般索引關鍵詞數量隨著文本內容成線性關系增長,而倒排索引當出現相同關鍵詞時,只需要修改相應記錄信息,節省索引文件的存儲空間并提高檢索效率[7]。Lucene建立索引文件過程中,對于表2中的關鍵詞,在文本中出現位置和次數,分別保存在如詞典文件,位置文件和頻率文件中。其中詞典文件中有指向位置和頻率文件的指針。
2.5 建立索引
將分詞后的DCI數據采用倒排索引技術建立索引可分為如下4步:
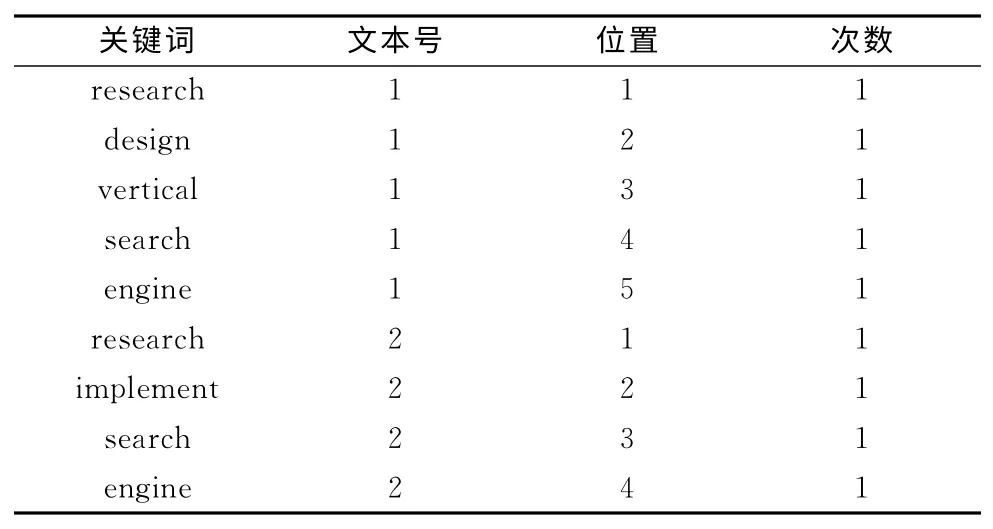
表1 一般索引
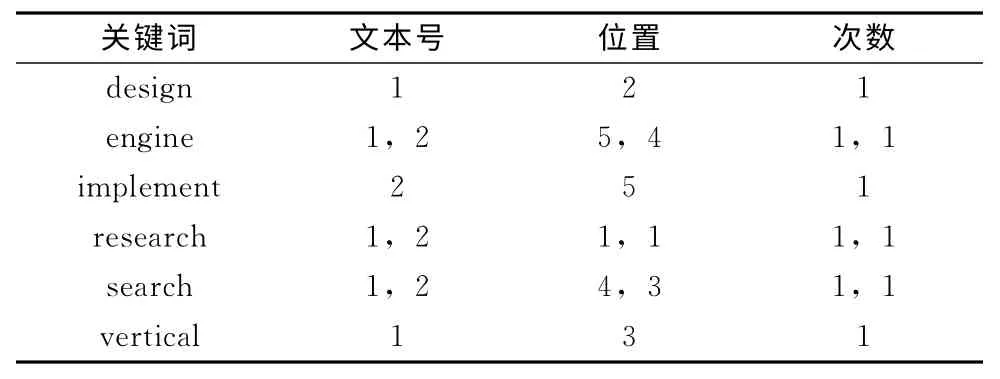
表2 倒排索引
(1)從數據庫中獲取DCI數據,針對一條數據進行解析,取出每個字段和值,按照數據庫字段對應Lucene域的方式生成Field對象;
(2)將生成的Field添加到Document中生成Document對象;
(3)通過IndexWriter類的addDocument方法建立索引,在建立索引時,Lucene會對數據進行分析處理;
(4)直到沒有要更新的數據,則索引創建完成并關閉索引器。當大量數據建索引時,在向磁盤寫入索引文件時會出現瓶頸,在Lucene內存中有一塊緩沖區來解決此問題。

2.6 搜索模塊
檢索模塊的系統結構如圖6所示,主要進行以下處理:關鍵詞預處理、同義詞擴展、查詢優化和Lucene索引檢索等[8]。首先,查詢預處理模塊對查詢請求進行篩選和過濾并分割出關鍵詞,去除沒有意義的字符,如“的”,“哈”,“哎”等干擾字符,將查詢請求處理成最原始的,最便于查詢處理的狀態;接著,對關鍵詞進行同義詞查詢擴展,通常用戶給定的查詢請求常被解析成獨立的實詞,從語義詞庫中獲取相應的同義詞組,比如關鍵詞:價格,可以擴展成:價值、售價等,這樣可以在更廣泛的概念上檢索出與用戶請求相關的信息;然后,將關鍵詞分派給查詢優化模塊進行邏輯關系分析,將搜索詞傳遞給搜索引擎模塊;最后,結合Lucene搜索提供的API實現搜索。
Lucene提供實現搜索API包括:QueryParser將用戶輸入的查詢關鍵詞分析處理后,生成查詢Query對象;IndexSearcher對Query對象進行搜索后結果返回在Hits集里;Lucene的相關度排序算法將搜索結果排序顯示給用戶。
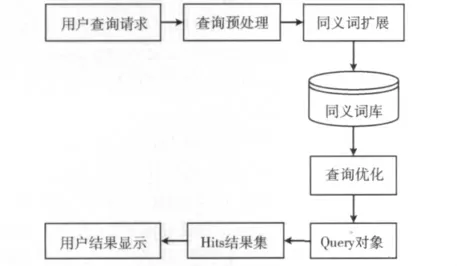
圖6 檢索模塊結構

2.7 相關度排序算法及改進
在使用關鍵詞查詢的時候,一般會得到大量符合條件的結果,用戶一般只會關注結果排在前面的幾頁,因此對于搜索結果排序變得尤其重要,本文是基于Lucene的垂直搜索引擎,Lucene 是結合了布爾模型和向量空間模型,Lucene原始的排序公式如下
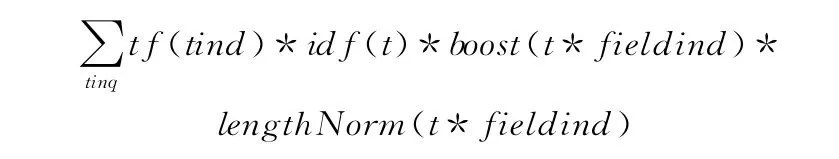
通過這個評分公式得到的是原始分數,但是由Hits結果集返回的關于某文檔的評分卻不是其原始得分,而是當評分最高得分的文檔如果超過了1.0,那么將所有評分都會以這個此評分為標準進行計算,因此所有Hits對象的得分都只能小于或等于1.0[9]。Lucene排序公式主要考慮了檢索詞的詞頻、反轉文檔概率和文檔長度,但是忽略了檢索詞之間關聯關系,本文提出如下改進算法[10]。

3 實驗結果與分析
基于本文的理論分析,本文系統實現是用Java語言編寫,搜索界面用JSP頁面顯示,索引文件采用Lucene的本地文件,相應的硬件環境是:Intel Core Due CPU i5 2.5GHz和2GB內存;軟件環境是:JDK1.6、Tomcat6.0、Myeclipse6.5和WinowsXP等。基于25萬條DCI數據建立索引,并提供相應的檢索服務,并以下兩方面對DCI搜索引擎實驗分析:
(1)基于Web的DCI垂直搜索引擎與傳統的基于數據庫的搜索引擎的比較如表3所示。由表3可知,該搜索引擎在數據源、分詞算法、索引和查詢分析等都比傳統的搜索引擎有很大的改進和提高。
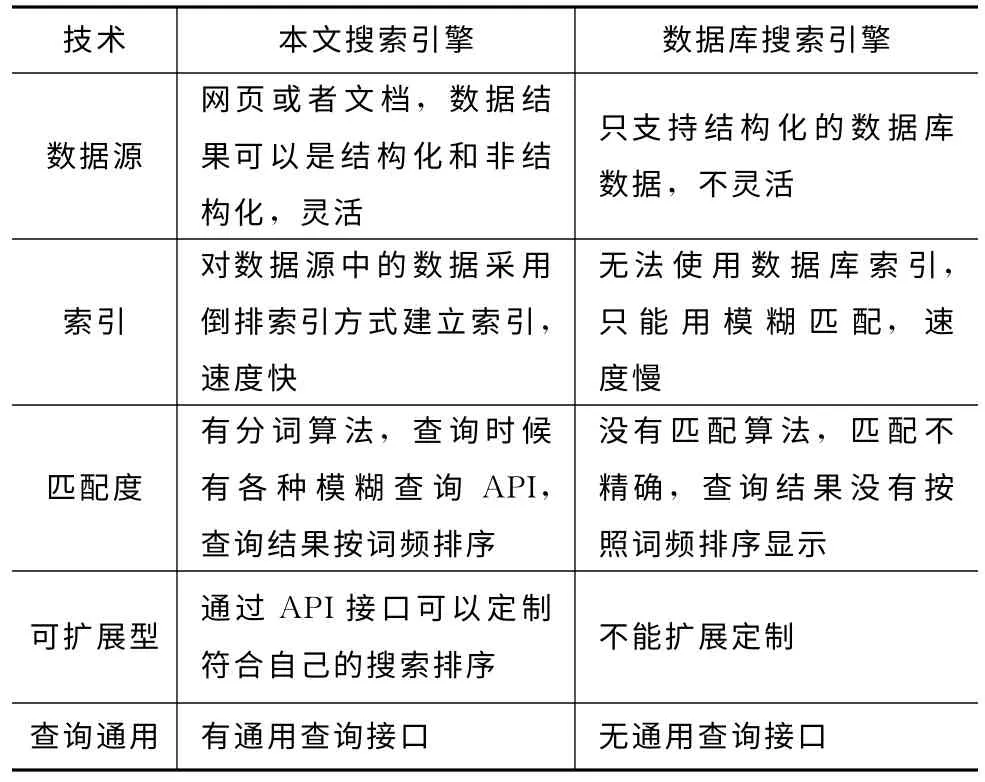
表3 搜索引擎比較表
(2)在網頁信息抽取方面,實驗選擇一下四個網站進行抽取,如表4所示,本文的抽取方法表現了較好的準確率,基本在95%左右。
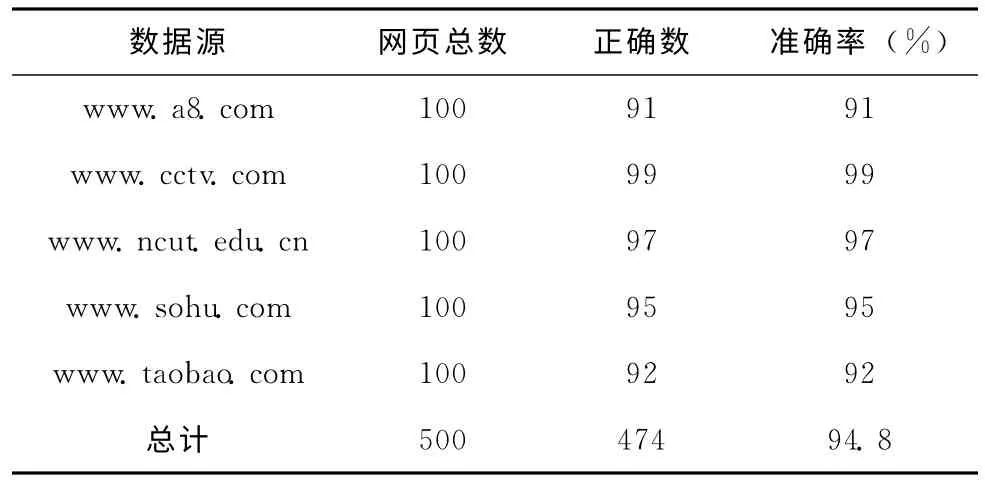
表4 網頁信息抽取結果
(3)在索引器搜索方面,基于25萬條DCI數據進行搜索,如表5所示,本搜索引擎確實實現了DCI數據的快速搜索功能,關鍵詞檢索響應時間全部在100ms之內完成。
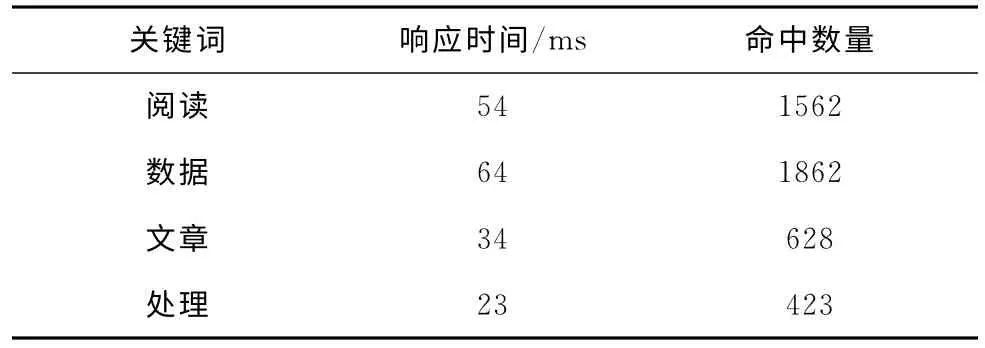
表5 關鍵詞檢索響應結果
4 結束語
垂直搜索引擎以其更準確、更有效的檢索而越來越受到用戶的重視,在深入學習研究Lucene和Heritrix等開源技術之后,本文先對DCI搜索引擎的整體結構進行了分析,接著對各個功能技術進行了分析與設計。在網頁信息抽取方面本文提出的基于統計的抽取技術,在很大程度上提高的抽取的準確度,還提出分析了Lucene的相關度排序算法并對其進行改進,最終設計了DCI垂直搜索引擎,并且實現DCI海量數據的快速準確搜索。同時,本系統還有一些有待改進的地方,比如以后可以進一步研究分布式技術來提高搜索效率等。
[1]LI Xuelian.IDC:in 2020the total amount of the explosion of digital information will reach 35ZB[EB/OL].[2010-05-10].http://tech.hexun.com/2010-05-10/123653027.html(in Chinese).[李雪蓮.IDC:數字信息大爆炸2020年總量將達35ZB[EB/OL].[2010-05-10].http://tech.hexun.com/2010-05-10/123653027.html.]
[2]Huelmarc.DCI baidu baike[EB/OL].[2011-12-02].http://baike.baidu.com/view/1733861.htm(in Chinese).[Huelmarc.DCI百度百科[EB/OL].[2011-12-02].http://baike.baidu.com/view/1733861.htm.]
[3]FU Qiang.Lucene research and implementation on the vertical search engine application to university library books[J].Journal of Taiyuan Normal University,2011,10(4):103-107(in Chinese).[付強.基于Lucene的高效圖書垂直搜索引擎的研究與實現[J].太原師范學院學報,2011,10(4):103-107.]
[4]CUI Xiaobo.SOA overview[EB/OL].[2006-01-05].http://blog.csdn.net/byfq/article/details/2411442(in Chinese).[崔曉波.SOA 概 覽[EB/OL].[2006-01-05].http://blog.csdn.net/byfq/article/details/2411442.]
[5]SUN Chengjie,GUAN Yi.A statistical approach for content extraction from web page[J].Journal of Chinese Information Processing,2004,18(5):17-22(in Chinese).[孫承杰,關毅.基于統計的網頁正文信息抽取方法的研究[J].中文信息學報,2004,18(5):17-22.]
[6]QIU Zhe,FU Taotao.Developing its own search engine--Lucene 2.0+Heritrix[M].Beijing:People’s Posts and Telecommunications Press,2007(in Chinese).[邱哲,符滔滔.開發自己的搜索引擎—Lucene 2.0+Heritrix[M].北京:人民郵電出版社,2007.]
[7]ZHAO Ke,LU Peng,LI Yongqiang.Design and implementation of search engine based on Lucene[J].Computer Engineering,2011,37(16):39-41(in Chinese).[趙珂,逯鵬,李永強.基于Lucene的搜索引擎的設計與實現[J].計算機工程,2011,37(16):39-41.]
[8]JIANG Yifeng,WANG Hua,ZHANG Yuhong,et al.Design and implementation of semantic search engine based on Lucene[J].Computer Engineering and Design,2008,29(20):5336-5341(in Chinese).[蔣一峰,王華,張玉紅,等.基于Lucene的語義檢索系統的設計和實現[J].計算機工程與設計,2008,29(20):5336-5341.]
[9]Otis Gospodnetic,Erik Hatcher.Lucene IN ACTION[M].TAN Hong,transl.Beijing:Publishing House of Electronics Industry,2007(in Chinese).[Otis Gospodnetic,Erik Hatcher.Lucene IN ACTION 中文版[M].譚鴻,譯.北京:電子工業出版社,2007.]
[10]WANG huan,SUN Zhirui.Research of semantic retrieval system based on domain-ontology and Lucene[J].Journal of Computer Application,2010,30(6):1555-1660(in Chinese).[王歡,孫瑞志.基于領域本體和Lucene的語義檢索系統研究[J].計算機應用,2010,30(6):1555-1660.]
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年12期)2015-11-10 05:13:38
中外會展(2014年4期)2014-11-27 07:46:46
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
語文知識(2014年1期)2014-02-28 21:59:13
計算機應用文摘(2009年17期)2009-04-29 00:44:03
