商業銀行信用風險評估實證分析及方法比較
2013-07-23 01:37:40李君藝張宇華
網絡安全技術與應用 2013年3期
李君藝 張宇華
1東莞職業技術學院計算機工程系 廣東 523808 2廣東工業大學計算機學院 廣東 510006
0 引言
我國的金融風險主要表現為信用風險,我國商業銀行信用風險管理已由傳統經驗判斷時期逐步發展到現代信用風險模型化階段。隨著管理信息系統的廣泛使用和電子商務的深入發展,我國商業銀行大都擁有大量客戶數據,而面對海量數據,傳統的信用風險管理方法逐漸無法負荷。數據挖掘技術的出現,為解決海量數據下的信用風險管理問題提供了新的思路和方法。數據挖掘是以人工智能為基礎的數據分析技術,是從大量的、不完全的、有噪聲、模糊的、隨機的數據中,提煉隱含其中的、具有潛在作用的信息和知識的過程。數據挖掘可以為商業銀行信用風險提供諸多分析方法,本文對三種常用的數據挖掘方法——多元判別分析、聚類分析和貝葉斯網絡模型進行實證研究,通過結果分析,比較三者作為信用風險評估方法的優劣。
1 商業銀行信用風險評估指標
信用風險評估方法的驗證數據選用某商業銀行的數據,選擇已成功申請房貸的 6000條個人客戶數據為研究對象,其中5000條數據作為訓練樣本,1000條數據作為結果驗證。LEVEL表示信用風險等級,劃分為 High(H)、Middle(M)、Low(L)三個等級,各等級在樣本數據中大致均勻分布。LEVEL作為響應變量或目標變量,其余的變量為客戶信用指標集,反應客戶的各項屬性,即特征屬性變量,如表1所示。
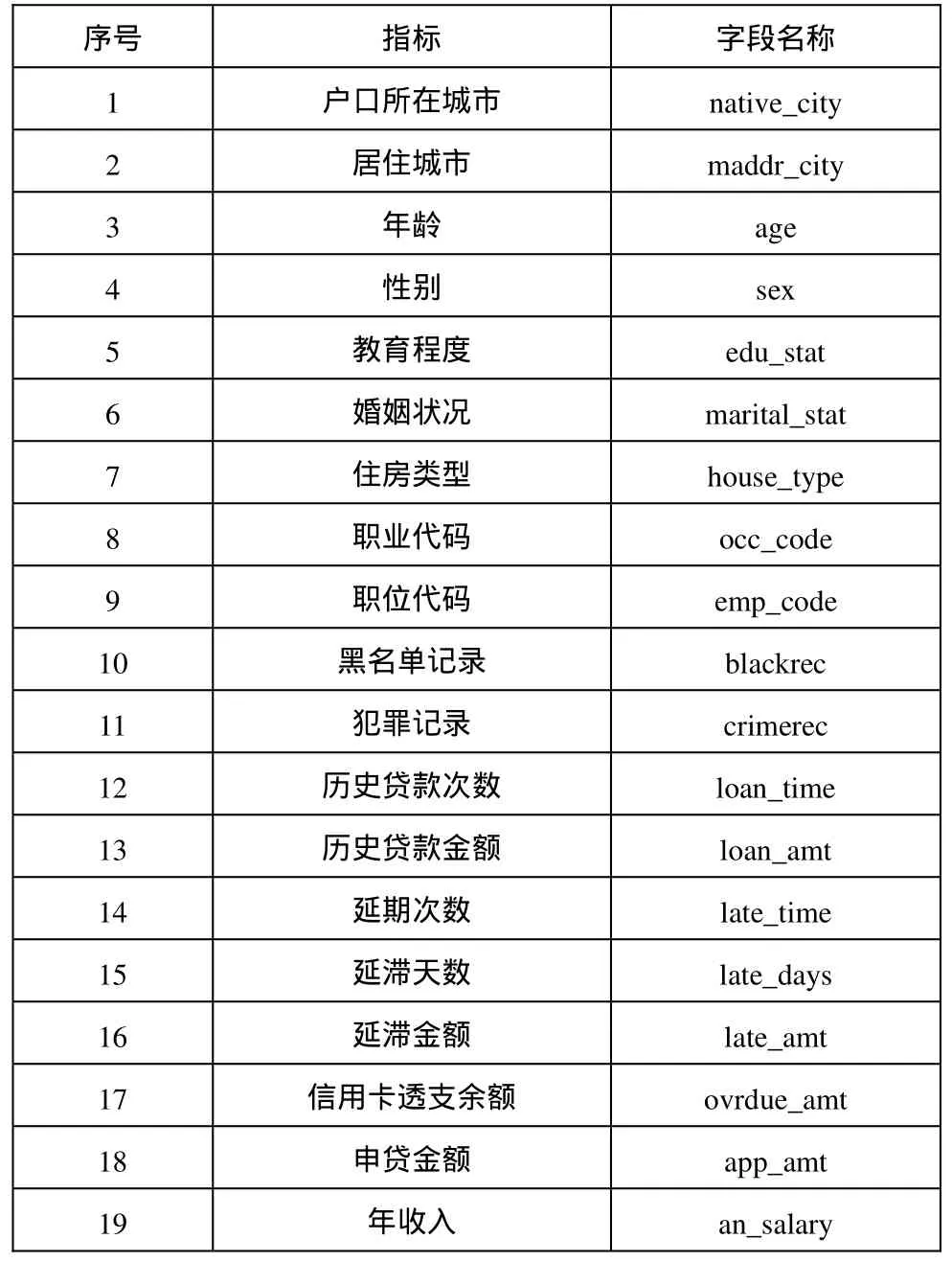
表1 屬性指標列表
以上數據以SAS數據集的形式儲存于ODS數據層,訓練數據統一存放于數據集studydata,驗證數據存放于數據集newdata。
信用風險評估方法的實現功能是:在給定的風險等級分類體系下,根據分析客戶的以上特征屬性變量,自動確定客戶的信用風險等級類別LEVEL。我們將通過對三種不同的分析方法進行驗證,比較三種方法在信用風險評估分析中的性能及準確度。
2 實證分析
2.1 多元判別分析
判別分析是根據表明研究對象特征的變量值判別樣品所屬類型的一種分類方法。根據樣本的已知分類及所測得的數據,篩選出最能表明研究對象特征的變量,并根據這些變量和已知類別,建立使誤判率最小的判別函數。在風險評估算法中,可把風險等級作為分類變量,各個指標屬性作為數值變量,從已知分類數據中訓練出判別函數,用于客戶風險等級的分類預測。
我們利用SAS系統軟件中的STEPDISC、DISCRIM過程對信用風險評估指標進行判別分析。過程如下:
(1)指標篩選
首先,利用STEPDISC過程對指標進行篩選,選出對判別分析結果相關性較大的指標。proc stepdisc data=studydata method=sw;class X20;var X1-X19;run;
STEPDISC過程逐步選出F值最大,即對判別效果貢獻最大的變量,選入模型,最后選出Pr>F小于判據0.15的變量。結果在19個變量中選擇了X3,X5,X10,X14,X18,X19共6個變量。
(2)判別分析過程
評估指標的變量既有離散型變量也有連續型變量,數據的分布不能確定,我們須采用SAS中的DISCRIM過程。下面我們將以 studydata作為訓練樣本,在前面已經過STEPDISC的變量篩選,現在我們基于 studydata對新樣本newdata進行風險等級分類。
proc discrim data=newdata testdata=studydata testout=result list;
class x20;
var x3 x5 x10 x14 x18 x19;
run;
Studydata中的風險等級分類共有H、M、L三級,即X20有三種取值。運行過程是首先得出三個級別的線性判別函數的系數和常數項,用回代法將newdata每個觀測的變量代入三個判別函數,哪個函數值大,觀測就屬于哪一類。這里我們使用了 LIST選項,使分類結果自動列出,并顯視各觀測分到每一類的后驗概率,最后結果是觀測被分到后驗概率最大的那一項(圖1)。
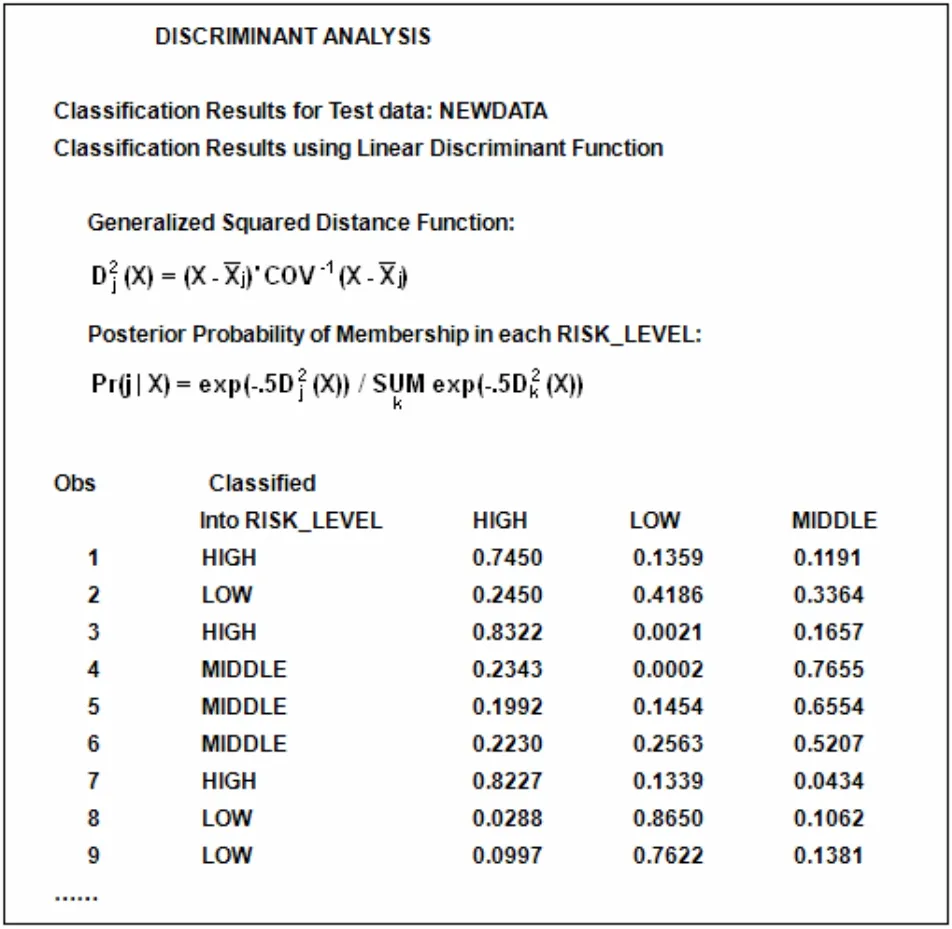
圖1 PROC DISCRIM部分運行結果
我們把DISCRIM過程的分類結果與銀行內部的實際風險評級結果相比,分類正確的數據為776條,準確率達到77%以上。然后我們嘗試把studydata樣本提高為8000條數據時,newdata的分類準確率提升為80.6%。
2.2 聚類分析
聚類分析和判別分析有相似的作用,都是起到分類的作用。但是,判別分析是已知分類然后總結出判別規則,是一種有指導的學習;而聚類分析則是有了一批樣本,不知道它們的分類,甚至連分成幾類也不知道,希望用某種方法把觀測進行合理的分類,使得同一類的觀測比較接近,不同類的觀測相差較多,這是無指導的學習。因聚類分析適合于分析樣本量少的數據,下面我們只從newdata中選取100條數據作分析。
SAS中的聚類分析過程有 11種分類方法(METHOD),下面我們采用最短距離法(METHOD=SINGLE),即通過計算兩類觀測間最近一對的距離,得出分類結果。
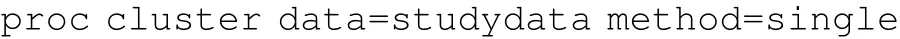

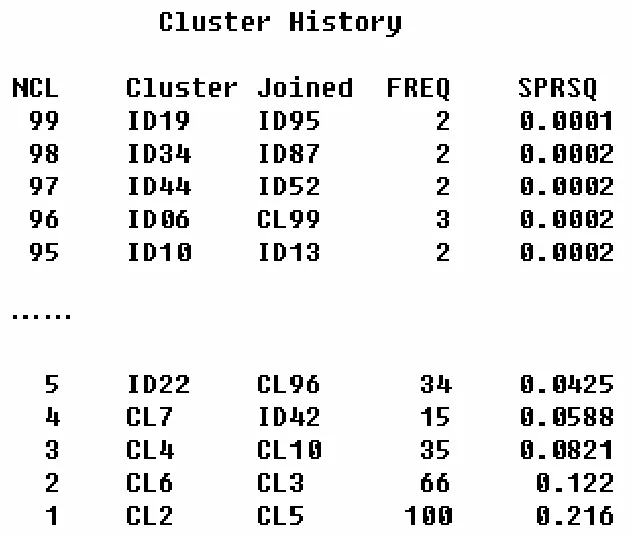
圖2 PROC CLUSTER運行結果
如圖2所示,Cluster History中的變量依次表示分類的類數、原分類、每步合并入的類、此步類中的觀測數、R平方。系統聚類法首先將所有樣本觀測各獨自視為1類,然后逐步合并至只有1類。然后,我們設信用等級分類數ncl為3,接下來,可以用proc tree和proc means進一步完善后續工作。

最后,根據數據集result可以得到將100個客戶分為3類,再結合對各類客戶的定性評分,可以把信用風險定為高,中,低三個級別。與實際評級結果相比,運算結果準確的條數達 74條,準確率為 74%。聚類分析只能應用于數據量較少的樣本,并且只能對樣本進行分類,無法具體確定每一類的風險級別。確定每個分類的風險級別需要結合因子分析或人為定性分析。
2.3 貝葉斯網絡模型
貝葉斯網絡的構建可以通過學習和人工構建兩種方式進行。人工構建通過專家經驗手工構造,學習則是通過數據分析獲得,即利用機器學習的方法分析數據來獲得貝葉斯網絡。在訓練樣本充分的情況下,可以從數據中訓練出貝葉斯網絡模型。貝葉斯網絡模型的構建過程包括網絡結構學習和參數學習,步驟如下:
(1)各個指標作為節點,運用K2算法對studydata樣本進行訓練,尋找CH評分高的貝葉斯網絡模型,確定節點間的關系,生成貝葉斯網絡結構表。
(2)利用最大似然估計算法進行參數學習,確定節點的概率分配,為每個節點各生成一個條件概率表。
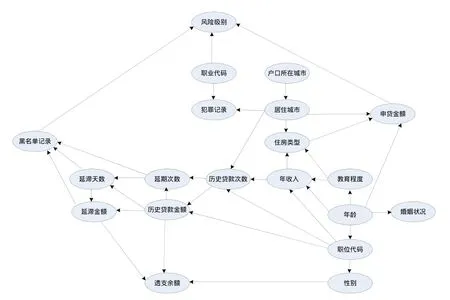
圖3 信用風險評估貝葉斯網絡模型
通過以上步驟構建的貝葉斯網絡模型結構如圖3所示。現對模型進行驗證。把從前面參數學習取得的 20個條件概率表,建立20個數據集,依次命名為T1,T2,…,T20。把網絡結構表建立一個獨立的數據集,命名為 network。SAS算法將對客戶數據(newdata)逐條處理,過程如下:
(1)讀取客戶數據,初始化運算公式:
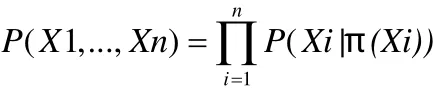
(2)搜索表Network,獲取屬性變量Xi(i=1,2,…,19)的父節點;
(3)搜索表Ti(i=1,2,…,19),獲得該子節點與父節點的聯合條件概率,將其加入運算公式;
(4)搜索表 T20,把 3個風險等級下的條件概率分別加入運算公式,得出客戶在3個風險等級(H,M,L)的概率結果,最后確定把客戶分到概率最高的一個等級。
驗證過程是通過輸入客戶的數據(newdata),得出客戶在3個信用風險級別(H,M,L)的概率,最后確定客戶屬于概率最大的一個級別。算法流程見圖4。
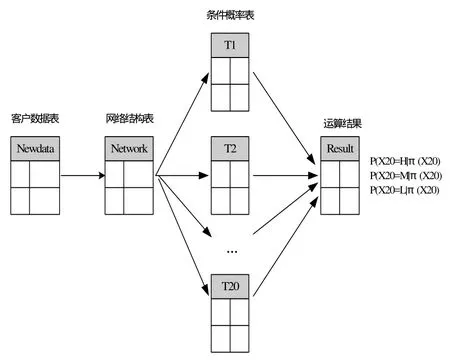
圖4 貝葉斯網絡驗證算法流程圖
根據以上過程,我們使用newdata樣本的1000條數據進行結果驗證。把模型的分類結果與銀行內部的實際風險評級結果相比,分類正確的數據為886條,準確率達到88.6%。
3 結論
從表2的結果看,三種分析方法相比,對于中、低風險級別的客戶數據,貝葉斯網絡方法的準確率優于判別分析和聚類分析;對于高風險級別的客戶數據,貝葉斯網絡的準確率與其它兩種方法基本持平。貝葉斯網絡模型在判斷高風險客戶上沒有明顯的優勢,大約是因為高風險客戶的指標屬性集近似吻合條件獨立的假定。但是,對于中、低風險的客戶而言,其影響還款能力的各方面因素大多是相關的,貝葉斯網絡模型在解決條件依賴方面有明顯優勢。總體來看,貝葉斯網絡模型的總體準確率高于判別分析和聚類分析。貝葉斯網絡能運用所有的屬性指標并明確確定每個指標的依賴關系和條件概率,判別分析則只選取相關性較高的指標進行概率估算,因此貝葉斯網絡的精確度顯然要高于判別分析;與聚類分析相比,貝葉斯網絡是基于對大量歷史數據進行學習而獲得的,并能用于分析數據規模較大的樣本,而聚類分析能應用于數據量較少的樣本,并且只能對樣本進行分類,無法具體確定每一類的風險級別,在這一點上,貝葉斯網絡模型明顯優于聚類分析。
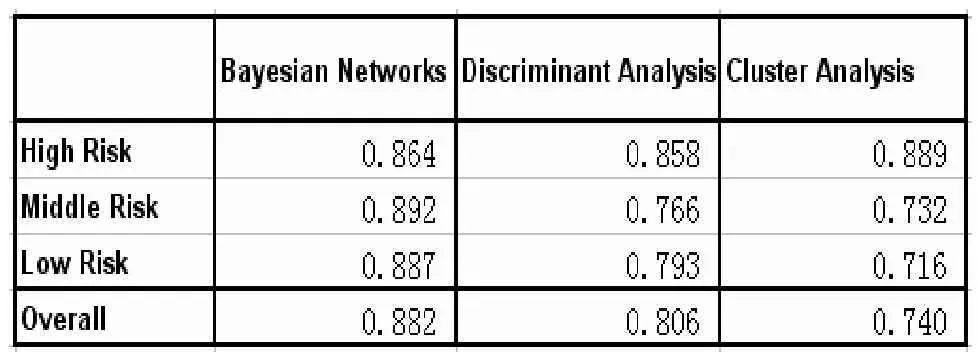
表2 三種方法正確率對照表
[1]張連文,郭海鵬.貝葉斯網引論[M].科學出版社.2006.
[2]譚浩強.SAS/PC統計分析軟件使用技術[M].國防工業出版社.1996.
[3]李君藝,梁智城.SAS判別分析在商業銀行信用風險評估中的應用[J].計算機安全.2011.
[4]薄純林,王宗軍.基于貝葉斯網絡的商業銀行操作風險管理[J].金融理論與實踐.2008.
[5]汪辦興.我國商業銀行信用風險模型的國際比較與改進.當代經濟科學[J].2007.
[6]Jiawei Han,Micheline Kamber.數據挖掘概念與技術[M].機械工業出版社.2008.
[7]General J.Financial analysis using Bayesian networks[J].Applied Sochastic Modelsin Bussiness and Industry.2001.17(1):57-67.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
