基于云計(jì)算的移動(dòng)互聯(lián)網(wǎng)大數(shù)據(jù)用戶行為分析引擎設(shè)計(jì)*
2013-08-10 03:42:04陶彩霞謝曉軍郭利榮
電信科學(xué) 2013年3期
陶彩霞,謝曉軍,陳 康,郭利榮,劉 春
(中國(guó)電信股份有限公司廣東研究院 廣州 510630)
1 引言
從2010年開(kāi)始,國(guó)內(nèi)移動(dòng)互聯(lián)網(wǎng)進(jìn)入快速發(fā)展階段,領(lǐng)先的電信運(yùn)營(yíng)商開(kāi)始布局移動(dòng)互聯(lián)網(wǎng),同時(shí),互聯(lián)網(wǎng)公司全面介入,終端廠商也基于應(yīng)用商店模式快速加入移動(dòng)互聯(lián)網(wǎng)領(lǐng)域。根據(jù)艾瑞咨詢發(fā)布的數(shù)據(jù),全球移動(dòng)互聯(lián)網(wǎng)用戶數(shù)正呈爆發(fā)式增長(zhǎng),2014年全球移動(dòng)互聯(lián)網(wǎng)用戶數(shù)有望達(dá)到14億。然而在數(shù)據(jù)流量快速增長(zhǎng)的同時(shí),電信運(yùn)營(yíng)商卻出現(xiàn)數(shù)據(jù)業(yè)務(wù)收入增速放緩的困境,面臨被管道化的威脅。為應(yīng)對(duì)移動(dòng)互聯(lián)網(wǎng)帶來(lái)的挑戰(zhàn),中國(guó)電信提出了從話務(wù)量經(jīng)營(yíng)轉(zhuǎn)向流量經(jīng)營(yíng)的戰(zhàn)略目標(biāo),從傳統(tǒng)的注重用戶規(guī)模轉(zhuǎn)變?yōu)樽⒅亓髁堪l(fā)展。運(yùn)營(yíng)商擁有龐大的用戶,同時(shí)具有對(duì)終端及用戶上網(wǎng)通道的掌控能力,使得在用戶行為分析方面具有很好的數(shù)據(jù)基礎(chǔ),深入分析用戶流量行為特征和規(guī)律,發(fā)現(xiàn)用戶潛在流量使用需求,是提升流量規(guī)模和價(jià)值、提高流量經(jīng)營(yíng)水平的有效手段。
然而隨著移動(dòng)互聯(lián)網(wǎng)的迅速發(fā)展,用戶行為分析面臨著新的挑戰(zhàn):一是移動(dòng)互聯(lián)網(wǎng)新業(yè)務(wù)、新產(chǎn)品“短、平、快”的特征,要求運(yùn)營(yíng)商支持快速變化的營(yíng)銷活動(dòng);二是隨著移動(dòng)互聯(lián)網(wǎng)業(yè)務(wù)及終端、傳感器技術(shù)發(fā)展帶來(lái)的數(shù)據(jù)量的急劇膨脹,需要分析和處理的數(shù)據(jù)規(guī)模從GB級(jí)邁向TB級(jí)甚至PB級(jí)。傳統(tǒng)的數(shù)據(jù)分析架構(gòu)已經(jīng)不能適應(yīng)這種海量數(shù)據(jù)處理和快速、深度挖掘的需求,迫切需要引入大規(guī)模并行處理技術(shù)和分布式架構(gòu),構(gòu)建基于云計(jì)算的移動(dòng)互聯(lián)網(wǎng)用戶行為分析引擎系統(tǒng),以應(yīng)對(duì)移動(dòng)互聯(lián)網(wǎng)大數(shù)據(jù)時(shí)代的挑戰(zhàn)。
2 基于云計(jì)算的系統(tǒng)總體設(shè)計(jì)方案
2.1 系統(tǒng)總體技術(shù)架構(gòu)
本文設(shè)計(jì)的移動(dòng)互聯(lián)網(wǎng)用戶行為分析引擎通過(guò)云計(jì)算技術(shù)實(shí)現(xiàn)分布式并發(fā)的大規(guī)模計(jì)算能力,構(gòu)建移動(dòng)互聯(lián)網(wǎng)端到端的大數(shù)據(jù)挖掘分析系統(tǒng),實(shí)現(xiàn)對(duì)DPI和應(yīng)用平臺(tái)用戶上網(wǎng)行為的偏好分析,提供個(gè)性化推薦服務(wù),打通從數(shù)據(jù)采集、分析到服務(wù)提供、營(yíng)銷執(zhí)行的全過(guò)程。
系統(tǒng)通過(guò)FTP服務(wù)器獲取數(shù)據(jù),在接口層采用分布式計(jì)算與批量處理相結(jié)合的方式,將大數(shù)據(jù)存入Hbase數(shù)據(jù)庫(kù)中,支持海量數(shù)據(jù)和非結(jié)構(gòu)化數(shù)據(jù)的存儲(chǔ),數(shù)據(jù)入庫(kù)之后利用Hive進(jìn)行整合層和匯總層的ETL處理,再基于MapReduce計(jì)算框架設(shè)計(jì)大數(shù)據(jù)分析模型,最后通過(guò)Hive數(shù)據(jù)庫(kù)將結(jié)果導(dǎo)入前端展現(xiàn)數(shù)據(jù)庫(kù)。在數(shù)據(jù)處理層,利用Hbase、Hive的優(yōu)勢(shì)進(jìn)行海量數(shù)據(jù)的存儲(chǔ)和處理,考慮到前端展現(xiàn)要求的靈活性,采用關(guān)系型數(shù)據(jù)庫(kù)MySQL作為前端展現(xiàn)。系統(tǒng)總體技術(shù)架構(gòu)如圖1所示。
2.2 系統(tǒng)總體拓?fù)浜凸δ芊植?/h3>
系統(tǒng)的總體拓?fù)淙鐖D2所示,系統(tǒng)由一臺(tái)服務(wù)器作為Hadoop平臺(tái)和Hbase的主節(jié)點(diǎn)服務(wù)器,其他服務(wù)器為Hadoop平臺(tái)和Hbase的從節(jié)點(diǎn)服務(wù)器,從節(jié)點(diǎn)服務(wù)器的數(shù)量可根據(jù)系統(tǒng)處理需求動(dòng)態(tài)擴(kuò)展。主節(jié)點(diǎn)服務(wù)器主要負(fù)責(zé)從節(jié)點(diǎn)服務(wù)器任務(wù)和流量的分配,并對(duì)從節(jié)點(diǎn)服務(wù)器的執(zhí)行狀態(tài)進(jìn)行監(jiān)控,多臺(tái)從節(jié)點(diǎn)服務(wù)器在主節(jié)點(diǎn)服務(wù)器的控制下執(zhí)行具體的任務(wù)。
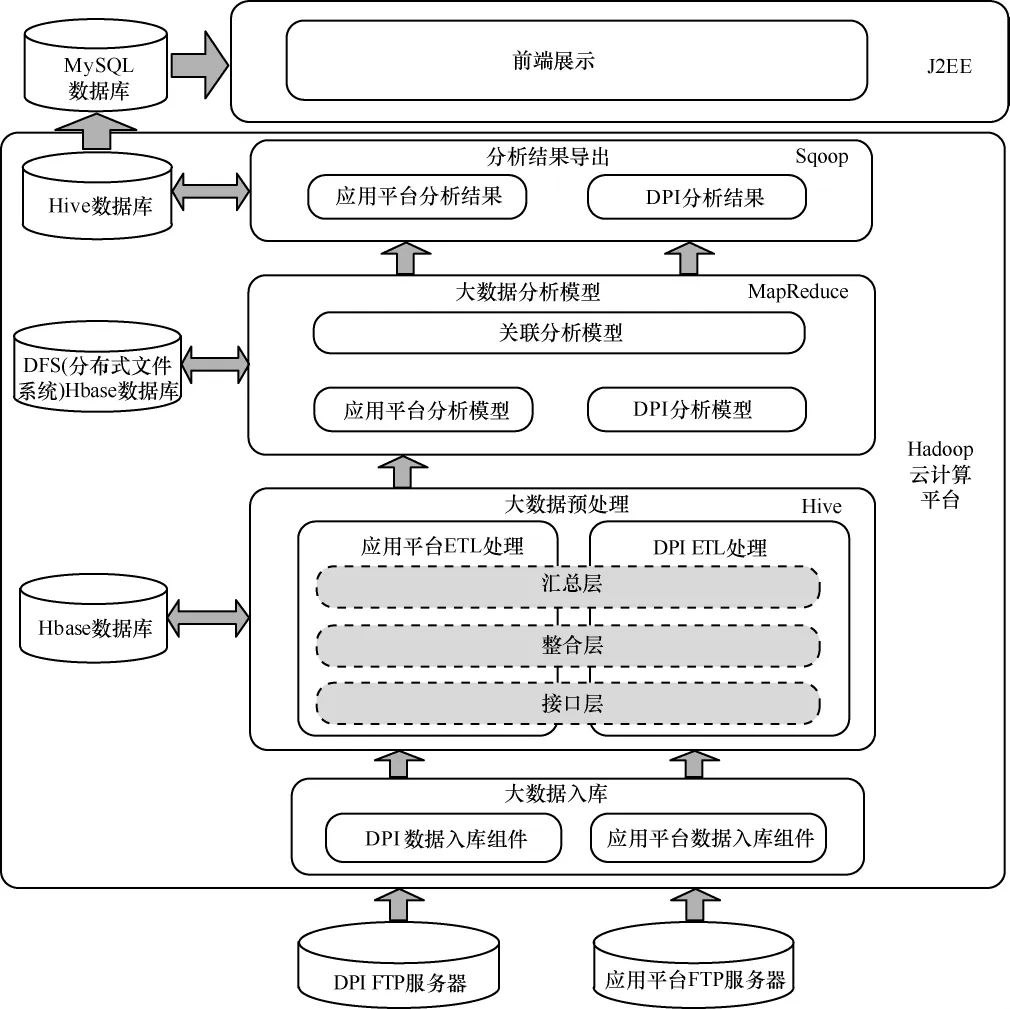
圖1 基于云計(jì)算的移動(dòng)互聯(lián)網(wǎng)大數(shù)據(jù)用戶行為分析引擎總體技術(shù)架構(gòu)

圖2 系統(tǒng)總體拓?fù)?/p>
主節(jié)點(diǎn)服務(wù)器的軟件功能架構(gòu)如圖3所示,各模塊具體介紹如下。
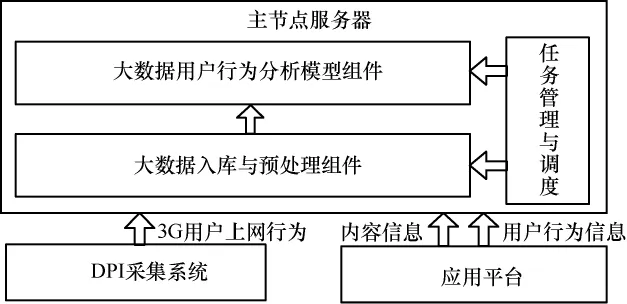
圖3 主節(jié)點(diǎn)服務(wù)器功能架構(gòu)
(1)任務(wù)管理與調(diào)度模塊
集中式的任務(wù)調(diào)度控制臺(tái),提供任務(wù)的創(chuàng)建、調(diào)整和刪除等功能,通過(guò)業(yè)務(wù)類型選擇、執(zhí)行周期設(shè)置等,定義應(yīng)用的處理邏輯;自動(dòng)控制數(shù)據(jù)抽取、數(shù)據(jù)整理到數(shù)據(jù)建模、模型運(yùn)行、結(jié)果輸出等過(guò)程,根據(jù)任務(wù)設(shè)置的激活處理?xiàng)l件,自動(dòng)加載任務(wù)運(yùn)行,系統(tǒng)提供任務(wù)的暫停、恢復(fù)以及優(yōu)先級(jí)管理功能。
(2)大數(shù)據(jù)入庫(kù)與預(yù)處理組件
將DPI用戶的上網(wǎng)行為、應(yīng)用平臺(tái)的用戶行為和內(nèi)容信息等大數(shù)據(jù),及時(shí)導(dǎo)入用戶行為分析引擎系統(tǒng),作為數(shù)據(jù)分析和模型挖掘的數(shù)據(jù)源。
(3)大數(shù)據(jù)用戶行為分析模型組件
基于匯聚到系統(tǒng)中的海量移動(dòng)互聯(lián)網(wǎng)用戶行為數(shù)據(jù),利用MapReduce計(jì)算框架構(gòu)建用戶行為分析模型資源池,快速分析用戶的偏好、社會(huì)關(guān)系信息,且支持多類業(yè)務(wù)實(shí)現(xiàn)精準(zhǔn)的內(nèi)容推薦。
從節(jié)點(diǎn)服務(wù)器的軟件結(jié)構(gòu)與主節(jié)點(diǎn)服務(wù)器基本相同,區(qū)別主要在于從節(jié)點(diǎn)服務(wù)器不需要部署任務(wù)管理和調(diào)度模塊。
3 大數(shù)據(jù)入庫(kù)組件設(shè)計(jì)
移動(dòng)互聯(lián)網(wǎng)用戶行為分析引擎的數(shù)據(jù)來(lái)源主要有兩類:應(yīng)用平臺(tái)數(shù)據(jù)和DPI數(shù)據(jù)。兩類數(shù)據(jù)源的特點(diǎn)不同:應(yīng)用平臺(tái)的數(shù)據(jù)主要集中在一個(gè)訪問(wèn)行為表上,每天一個(gè)文件,每個(gè)文件的大小為GB級(jí);而DPI數(shù)據(jù)的特點(diǎn)是大量的小文件,每個(gè)文件大小在10 MB以內(nèi),但文件來(lái)源頻率快,一般2 min就有好幾個(gè)文件,一個(gè)省份累計(jì)1天的數(shù)據(jù)量可達(dá)1 TB。
針對(duì)上述不同的數(shù)據(jù)源特點(diǎn),系統(tǒng)采用不同的技術(shù)方案,具體介紹如下。
(1)應(yīng)用平臺(tái)數(shù)據(jù)入庫(kù)
由于Hadoop通常使用的TextInputFormat類,在map中讀取到的是文件的一行記錄。因此,系統(tǒng)使用N LineInputFormat類實(shí)現(xiàn)在MapReduce中的批量入庫(kù)。通過(guò)使用N LineInputFormat類,每個(gè)分片有N行記錄,通過(guò)參數(shù)的配置,每次可讀取文件的N行記錄,那么可以在map中直接執(zhí)行批量入庫(kù)的操作,效率相對(duì)較高。
(2)DPI數(shù)據(jù)入庫(kù)
由于DPI的行為數(shù)據(jù)是大量來(lái)源頻率很快的小文件,在Hadoop平臺(tái)下處理小文件采取的措施通常如下。
· 利用SequenceFiles將小文件打包上傳,可從源頭避免小文件產(chǎn)生,但無(wú)論是Hadoop shell還是MapReduce,都不能進(jìn)行靈活讀取。
·使用HAR將HDFS中的小文件打包歸檔 (從HDFS),可減少既有 HDFS中的小文件數(shù)量,但HAR文件讀取性能差。
·Hadoop append可直接追加數(shù)據(jù)到相同文件中,但每個(gè)小文件的大小不同,同時(shí)考慮每天的DPI日志有峰值和低谷,對(duì)文件數(shù)量的控制和處理來(lái)說(shuō)有一定的麻煩。
· Flume、FlumeNG、Scribe,可通過(guò)中間層匯聚數(shù)據(jù)的辦法減少小文件數(shù)量,但FlumeNG和Scribe都不能很好地傳輸壓縮文件。
通過(guò)以上分析可以看到,上述4種方式均存在一定的缺點(diǎn),因此針對(duì)DPI數(shù)據(jù)的特征,采用Hadoop平臺(tái)的CombineFileInputFormat類方式,即通過(guò)繼承CombineFile InputFormat,實(shí)現(xiàn) CreateRecordReader,同時(shí)設(shè)置數(shù)據(jù)分片的大小,通過(guò)這種方式實(shí)現(xiàn)DPI大數(shù)據(jù)的入庫(kù)。
4 大數(shù)據(jù)用戶行為分析模型組件設(shè)計(jì)
大數(shù)據(jù)用戶行為分析模型組件提供多個(gè)在Hadoop分布式平臺(tái)上運(yùn)行的分析模型,其功能結(jié)構(gòu)及其與其他組件的關(guān)系如圖4所示。
2006年,隨著“三湖三河”污染治理工程的提出,巢湖流域受到了廣泛關(guān)注。巢湖流域以巢湖為中心,匯集了大小河流33條,是安徽省人口較集中的地區(qū)之一。近30年來(lái),巢湖流域的經(jīng)濟(jì)發(fā)展加快,城鎮(zhèn)化程度越來(lái)越高。現(xiàn)今巢湖流域的國(guó)內(nèi)生產(chǎn)總值已約占全省的三分之一,其產(chǎn)業(yè)結(jié)構(gòu)特點(diǎn)突出,以第一二產(chǎn)業(yè)為主,第三產(chǎn)業(yè)比例較低。隨著城鎮(zhèn)化和經(jīng)濟(jì)發(fā)展的加速,巢湖流域的生態(tài)問(wèn)題和人地矛盾愈發(fā)尖銳。
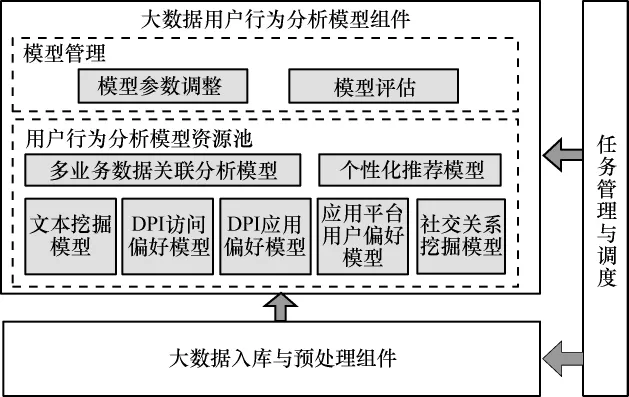
圖4 大數(shù)據(jù)用戶行為分析模型組件
本組件主要由以下幾個(gè)模塊組成。
· 模型參數(shù)調(diào)整:提供對(duì)模型算法中的變量設(shè)定、參數(shù)調(diào)整、樣本空間規(guī)模設(shè)置等功能。
· 模型評(píng)估:提供創(chuàng)建模型校驗(yàn)任務(wù),將實(shí)際數(shù)據(jù)與模型計(jì)算結(jié)果進(jìn)行比對(duì),輸出模型校驗(yàn)指標(biāo),進(jìn)行模型校驗(yàn)和模型有效性評(píng)價(jià)。
· 多業(yè)務(wù)數(shù)據(jù)關(guān)聯(lián)分析模型:對(duì)用戶的互聯(lián)網(wǎng)行為和愛(ài)游戲業(yè)務(wù)平臺(tái)的行為進(jìn)行關(guān)聯(lián)分析,判斷DPI用戶上網(wǎng)行為偏好與在應(yīng)用平臺(tái)上的行為偏好是否存在關(guān)聯(lián)關(guān)系,采用關(guān)聯(lián)算法找出其中存在的規(guī)則,并將規(guī)則固化到系統(tǒng)中,從而有助于交叉營(yíng)銷。
· 個(gè)性化推薦模型:以協(xié)同過(guò)濾技術(shù)和內(nèi)容推薦技術(shù)為主,采用混合推薦技術(shù),綜合考慮來(lái)自產(chǎn)品內(nèi)容和用戶兩個(gè)維度的影響,按照綜合相似度向用戶推薦相應(yīng)的信息,實(shí)現(xiàn)用戶動(dòng)態(tài)推薦算法。
· 文本挖掘模型:對(duì)文本內(nèi)容(如網(wǎng)頁(yè))通過(guò)預(yù)處理去除噪聲(如網(wǎng)頁(yè)導(dǎo)航欄、頁(yè)首、頁(yè)尾、廣告等不相關(guān)內(nèi)容),提取出文本主體部分,根據(jù)文本(網(wǎng)頁(yè))分類標(biāo)準(zhǔn)構(gòu)造標(biāo)注語(yǔ)料庫(kù),通過(guò)分類訓(xùn)練算法進(jìn)行模型訓(xùn)練和機(jī)器學(xué)習(xí),建立文本(網(wǎng)頁(yè))人工智能分類模型。
·DPI訪問(wèn)偏好模型:基于網(wǎng)頁(yè)內(nèi)容分類,通過(guò)用戶訪問(wèn)網(wǎng)頁(yè)分析,計(jì)算用戶Web訪問(wèn)興趣偏好。
·DPI應(yīng)用偏好模型:基于DPI采集數(shù)據(jù),通過(guò)應(yīng)用知識(shí)庫(kù)識(shí)別應(yīng)用,計(jì)算用戶應(yīng)用興趣偏好。
· 應(yīng)用平臺(tái)用戶偏好模型:依據(jù)用戶在應(yīng)用平臺(tái)上的各種操作行為,找出用戶對(duì)應(yīng)用平臺(tái)各種內(nèi)容的偏好規(guī)律。
· 社交關(guān)系挖掘模型:社交關(guān)系挖掘包括用戶社交圖譜和興趣圖譜的構(gòu)建。社交圖譜通過(guò)用戶的位置軌跡進(jìn)行挖掘分析,建立用戶之間的好友等社交關(guān)系;興趣圖譜基于用戶偏好模型,計(jì)算用戶偏好的相似度,得到與用戶興趣最相近的鄰居集合,建立用戶之間的相同興趣愛(ài)好關(guān)系。
以上模型的建模過(guò)程中很多用到了MapReduce計(jì)算框架。在MapReduce計(jì)算框架中,每個(gè)MapReduce作業(yè)主要分為兩個(gè)階段:map階段和reduce階段,分別用map函數(shù)和reduce函數(shù)實(shí)現(xiàn)。map函數(shù)對(duì)一個(gè)
(1)job1:計(jì)算用戶對(duì)內(nèi)容的偏好度
map函數(shù):從Hbase中讀取用戶行為數(shù)據(jù),組合相關(guān)的數(shù)據(jù)。key為用戶ID,value為用戶瀏覽過(guò)的內(nèi)容信息(如游戲、視頻等)。
reduce函數(shù):獲取每個(gè)用戶所有的行為信息,計(jì)算用戶對(duì)內(nèi)容的偏好度。key為用戶ID+內(nèi)容ID,value為內(nèi)容偏好度。
(2)job2:計(jì)算用戶對(duì)內(nèi)容屬性的偏好度
map函數(shù):讀取內(nèi)容偏好度信息傳給reduce函數(shù)。key為用戶ID,value為內(nèi)容ID+內(nèi)容偏好度。
reduce函數(shù):計(jì)算每個(gè)用戶的內(nèi)容屬性偏好度。
(3)job3:計(jì)算基于內(nèi)容的推薦列表
map函數(shù):獲取用戶內(nèi)容屬性偏好度和用戶內(nèi)容偏好度,key為用戶ID,value為屬性偏好度+內(nèi)容偏好度。
reduce函數(shù):計(jì)算推薦列表。
通過(guò)這種方式,系統(tǒng)把數(shù)據(jù)密集型的大數(shù)據(jù)用戶行為分析模型運(yùn)算任務(wù)分配到各個(gè)計(jì)算節(jié)點(diǎn)分布式運(yùn)行,從而大大提高模型運(yùn)算性能。
5 系統(tǒng)測(cè)試與結(jié)果分析
為了驗(yàn)證本文提出的基于云計(jì)算的移動(dòng)互聯(lián)網(wǎng)大數(shù)據(jù)用戶行為分析引擎設(shè)計(jì)方案,在實(shí)驗(yàn)室用PC服務(wù)器搭建了4個(gè)節(jié)點(diǎn)的Hadoop分布式平臺(tái),其中一個(gè)為主節(jié)點(diǎn),3個(gè)為從節(jié)點(diǎn),以大數(shù)據(jù)入庫(kù)為測(cè)試場(chǎng)景,與單機(jī)運(yùn)行環(huán)境進(jìn)行對(duì)比,測(cè)試了5組不同數(shù)據(jù)規(guī)模情況下的系統(tǒng)運(yùn)算時(shí)間,測(cè)試結(jié)果如圖5所示。
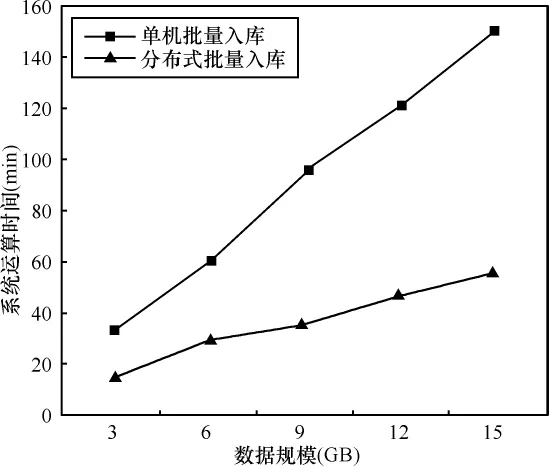
圖5 單機(jī)與分布式批量入庫(kù)測(cè)試性能對(duì)比
從測(cè)試結(jié)果可以看出,單機(jī)批量入庫(kù)方式的性能很低,對(duì)于 3 GB、6 GB、9 GB、12 GB、15 GB 的 5組數(shù)據(jù)規(guī)模,其系統(tǒng)運(yùn)算時(shí)間分別為 32 min、60 min、95 min、121 min、151 min,系統(tǒng)運(yùn)算時(shí)間隨著數(shù)據(jù)量的增長(zhǎng)幾乎呈線性增長(zhǎng),對(duì)于海量的大數(shù)據(jù)來(lái)說(shuō),很難在合理的時(shí)間內(nèi)快速完成數(shù)據(jù)的入庫(kù)操作;而采用云計(jì)算分布式批量入庫(kù)方式,系統(tǒng)處理時(shí)間大大縮短,對(duì)于3 GB、6 GB、9 GB、12 GB、15 GB 的5組數(shù)據(jù)規(guī)模來(lái)說(shuō),系統(tǒng)運(yùn)算時(shí)間分別為14 min、29 min、35 min、47 min、55 min。從兩種方式的測(cè)試結(jié)果對(duì)比可以看出,隨著數(shù)據(jù)規(guī)模的增大,云計(jì)算分布式批量入庫(kù)方式與單機(jī)批量入庫(kù)方式的處理時(shí)間差距越大,優(yōu)勢(shì)越明顯。
6 結(jié)束語(yǔ)
本文針對(duì)移動(dòng)互聯(lián)網(wǎng)大數(shù)據(jù)時(shí)代給運(yùn)營(yíng)商帶來(lái)的挑戰(zhàn),提出了一種基于云計(jì)算的移動(dòng)互聯(lián)網(wǎng)大數(shù)據(jù)用戶行為分析引擎設(shè)計(jì)方案。通過(guò)實(shí)驗(yàn)驗(yàn)證,該方案能有效地應(yīng)對(duì)移動(dòng)互聯(lián)網(wǎng)新業(yè)務(wù)、新產(chǎn)品“短、平、快”的特征和數(shù)據(jù)規(guī)模急劇膨脹等問(wèn)題,能夠在有效的時(shí)間內(nèi)完成大數(shù)據(jù)處理和分析任務(wù)。
1 陳康,鄭緯民.云計(jì)算:系統(tǒng)實(shí)例與研究現(xiàn)狀.軟件學(xué)報(bào),2009,20(5)
2 馮銘,王保進(jìn),蔡建宇.基于云計(jì)算的可重構(gòu)移動(dòng)互聯(lián)網(wǎng)用戶行為分析系統(tǒng)的設(shè)計(jì).計(jì)算機(jī)科學(xué),2011(8)
3 Anand Rajaraman,Jeffrey David Ullman.Mining of Massive Datasets.Cambridge University Press,2011
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科學(xué)大眾(2022年11期)2022-06-21 09:20:52
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
商用汽車(chē)(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
臺(tái)聲(2016年2期)2016-09-16 01:06:53
商用汽車(chē)(2016年6期)2016-06-29 09:18:54
商用汽車(chē)(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
