結合查詢相關性的關鍵詞查詢排序方法
2013-09-10 01:17:12楊書新徐慧琴
計算機工程與設計 2013年9期
楊書新,徐慧琴,譚 偉
(江西理工大學 信息工程學院,江西 贛州341000)
0 引 言
關系數據庫關鍵詞查詢旨在為用戶提供類搜索引擎的方法實現基于關鍵詞的數據庫內容查詢,它不要求用戶熟悉復雜的結構化查詢語言 (如SQL,SPARQL等)和底層數據庫模式的知識。關系數據庫關鍵詞查詢枚舉所有查詢結果的方法主要由兩部分組成:根據用戶給定的關鍵詞集合Q,產生一系列候選結果集合;對候選結果集進行相關度降序排序。一個優秀的關鍵詞查詢系統必需滿足以下三點要求:①查詢效率高;②能枚舉所有與查詢相關的結果;③一個滿足用戶需求的相關性評分函數。然而,要很好的滿足以上三點要求依然存在很大的挑戰,因此,關系數據庫關鍵詞查詢方法的研究依然是數據庫研究領域的一個重點。
文中針對要求③中的排序問題研究如何有效的對結果進行排序,目前已有的排序方法通常考慮的影響因素比較單一,因此,文中提出結合結果樹結構權重和關鍵詞與包含關鍵詞元組之間的相關性對結果進行排序的方法。在基于結構權重的排序方法基礎上引入相關性權重,可以使排列在前面的結果樹不僅結構緊湊而且與查詢條件高度相關。
1 相關工作
目前,已有的研究通常將關系數據庫關鍵詞查詢轉換為對圖的查詢,基于圖關鍵詞查詢的結果排序主要有兩種:基于圖結構權重的方法和基于IR式排序的方法。
文獻 [1-2]采用路徑代價來衡量結果的質量,當所有關鍵詞節點到中心節點的總路徑權重越小,查詢到的結果樹就越緊湊,結果質量也就越高。
不同于以上采用基于圖結構權重的排序方法,文獻[3-4]采用IR式排序方法,為結果中的每個元組附一個IR分值,結果樹的IR分值取結果樹中所有元組IR分值的平均值。F.Liu等人在文獻 [3]中對KQORD和傳統的IR排序方法進行分析,將一種結合了規范化因子的IR評分方法應用于結果排序中。在IR式結果排序的基礎上,Y.Luo等人在文獻 [4]的排序方法中引入虛擬文檔模型的概念,計算查詢結果與關鍵詞的相關度。
文獻 [5-7]為了完整表達關鍵詞之間的語義關系,受Steiner樹的啟發提出了Steiner圖問題。
由上述可知,很多研究在結果排序方面考慮的元素比較單一,因此,在接下來的篇幅中,文中將在查詢結果的呈現方面聯合基于圖結構權重和基于IR式排序方法的優點,提出一種新的排序方法,采用結合結果樹的結構權重和查詢相關性的方法對結果進行排序。
2 數據模型
許多領域中的大量數據 (例如生物網絡,社會網絡等)都可以建模成圖的結構。基于圖數據結構的關系數據庫關鍵詞查詢方法可以根據用戶給定的一組查詢關鍵詞Q產生由核心節點 (所有關鍵詞節點所能到達的節點),信息節點(關鍵詞節點),路徑節點和相關邊構成的一系列子樹作為查詢結果。查詢結果必須滿足如下兩個約束:①完全性約束:結果中必須包含用戶給定的所有關鍵詞;②非冗余性約束:當結果子樹的子樹依然包含所有的關鍵詞,或者一個結果包含于另一個查詢結果時,都屬于冗余結果,必須進行剪枝。
現有方法中的數據模型主要可分為兩大類:模式圖和數據圖。在模式圖中,節點對應數據庫中的關系表,邊對應表與表之間的主外碼引用關系;在數據圖中,節點表示關系表中元組記錄,邊表示元組與元組之間的主外碼關系。數據圖可表示非結構化數據,半結構化數據和結構化數據。由于數據圖廣泛的應用性,基于數據圖的關鍵詞查詢方法備受關注,基于數據圖的查詢系統有BANKS-Ⅰ,BANK-Ⅱ,EASE[5]等。
定義1 數據圖:假設G=(V,E)是關系數據庫對應的數據圖,G表示一個有向帶權圖,V為圖中節點集合,E為圖中邊的集合,數據庫中的每條元組記錄看作是圖中的節點,如果存在表中任意兩個元組ti,tj存在主外碼引用關系,則有 <ti,tj>∈E或 <tj,ti>∈E。
關系數據庫關鍵詞查詢中,給定一組查詢條件Q=(q1,q2,…qn),系統找到包含關鍵詞的信息碎片 (包含關鍵詞的元組記錄),合理的組織這些信息碎片,構成非冗余的結果組Steiner樹,一個查詢條件通常會產生大量結果,隨機排列結果顯然不符合用戶的需求,因此,定義一個相關性評分函數很有必要,使結果集按照某種特定的順序呈現在客戶端,將用戶感興趣的結果靠前排列。
3 結果排序方法
到目前為止,一些基于最小Steiner樹問題以及它的變型通常只考慮邊的權重而忽視了節點權重或者考慮了節點權重也只是假設它們的權重是相等的,但實際上,包含關鍵詞節點和關鍵詞可達節點的重要性并不是等同的,因此,在本節中,結果樹評分函數將結合結構權重和節點的相關性權重。
3.1 基于結構的權重計算
根據權威度的定義,當一個參與者有許多的鏈入鏈接時,它就是權威的。對于數據圖而言,一個節點的入度越大,它的權威度就越高。因此,用節點權威度可以很理想的表示節點的權重,式 (1)給出單個節點的權重計算公式,用平均節點權重表示結果樹的節點權重,如式 (2)所示
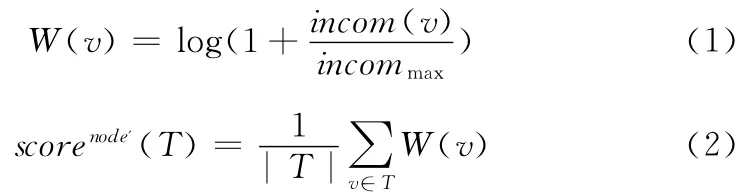
式中:incom(v)——節點v的入度,incommax——數據圖中的節點最大入度,|T|——結果子樹中的節點個數。
以往的一些研究對有向圖G的正反向邊的權值并未給予區分,這顯然不符合實際應用,文中在對數據進行預處理時,為正向邊和反向邊設定不同的權值,如式 (3)所示,正向邊設權值為1,式 (4)給出結果樹中邊權重分量的計算方法,邊權重越小,結果樹分數越大,采用log函數求邊權重和可以有效減小結果樹評分函數中邊權重部分的變化幅度,其中Wmin(e)為圖中最小邊權重
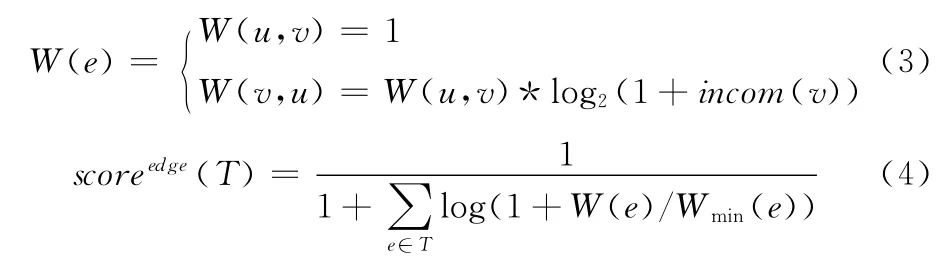
3.2 基于相關性的權重計算
(1)關鍵詞重要性分析
TF-IDF作為一種用于資訊探勘和資訊檢索的常用加權技術,可用于評估一個詞對于一個文件集 (語料庫)中一個文件的重要程度。一個詞的重要性與它在文件中出現的次數成正比,但同時與它在語料庫中出現的頻率成反比。
采用基于TF-IDF的方法計算關鍵詞的重要性[8],元組與給定的查詢關鍵詞的相關性與輸入的關鍵詞集合緊密聯系,因此該值是動態的,隨著給定的關鍵詞變化而變化。
文中將每個元組單元建模成一個虛擬文檔d,式 (5)給出求文檔d中關鍵詞qi的重要性標準化公式
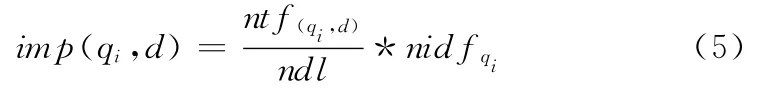
ntf(qi,d)(標準詞頻),ndl(標準文檔長度)和nidfqi(標準逆文檔頻率)[8]3個因子的計算公式如下
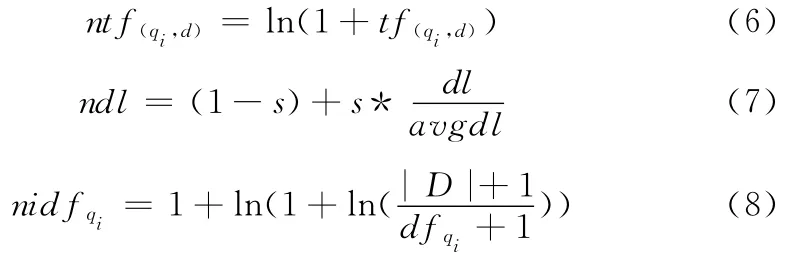
其中,tf(qi,d)為詞頻,表示關鍵詞qi在文檔 (元組)d中出現的次數,一個詞在文檔中出現得越頻繁,重要性越大。dl表示文檔長度,即元組中包含術語的個數,dl的出現可以有效降低長文本中關鍵詞qi的重要性。avgdl表示文檔的平均長度,s為0~1的平滑參數,通常取值為0.2。idfqi為逆文檔頻率,用文檔頻率的倒數表示,文檔頻率為包含某特定關鍵詞的文檔在總的文檔集中出現次數,式 (8)給出了逆文檔頻率的標準化計算公式,D為文檔d的集合,|D|表示總的文檔數量,|dfqi|為包含關鍵詞qi的元組數量。這里文檔進行了分類,針對DBLP數據集而言,文檔有author和paper兩個類,如果關鍵詞qi屬于anthor類,那么|D|就為author元組的數量,否則就為paper元組的數量。
以圖1中的數據子圖為例,當查詢條件Q= {Keyword,Relational}時,包含關鍵詞的節點為p1,p2和p3,下面分別給出這3個節點與查詢條件相關性的計算過程。
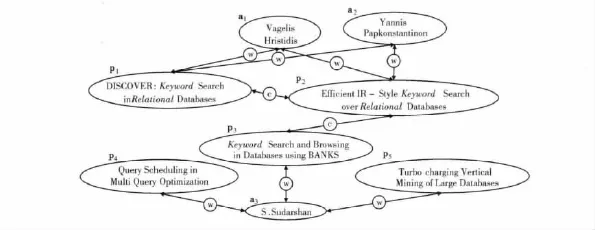
圖1 數據圖子樣
詞頻tf(qi,d)見表1。
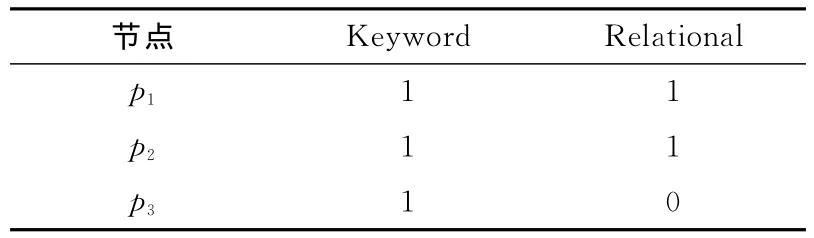
表1 詞頻tf(qi,d)
逆文檔頻率idfqi見表2。
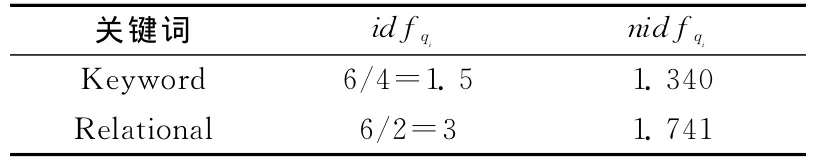
表2 逆文檔頻率idfqi
標準文檔長度ndl見表3。
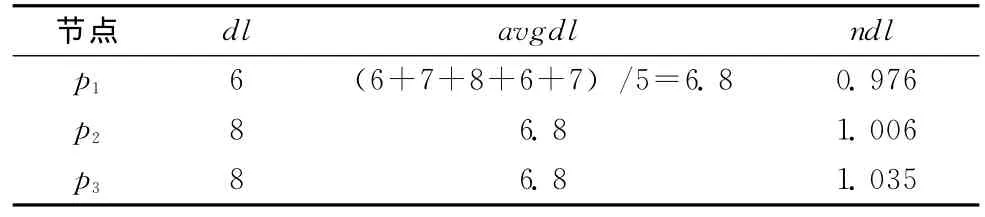
表3 標準文檔長度ndl
節點與查詢條件的相關性分數見表4。
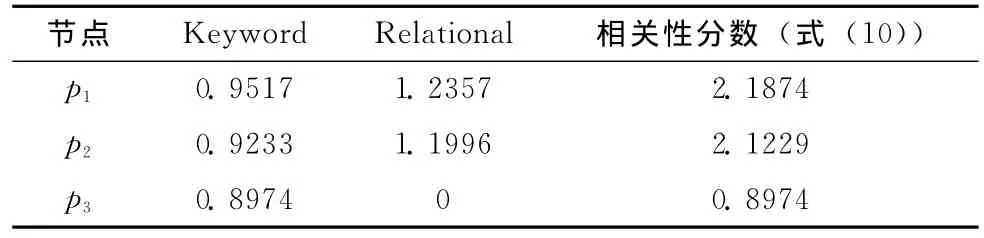
表4 節點與查詢條件的相關性分數
(2)節點與關鍵詞相關性分析
為了描述元組與關鍵詞的相關性,用RE(t,Q)表示元組t與查詢條件Q的相關度,式 (9)分別給出包含關鍵詞和不包含關鍵詞的元組相關度計算方法,當元組不包含關鍵詞時,相關度值為0

其中,包含給定關鍵詞元組的相關性計算如式 (10)所示。假設t是關系數據庫中基本數據表中的元組,對于DBLP數據集來講,它們是來自表Author和Pape
式 (11)為基于節點相關性的權重分量計算方法
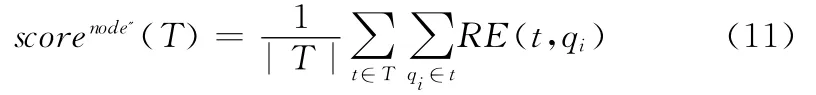
3.3 線性結合
下式給出結果樹的相關性評分函數計算公式,其中0<λ,β<1,通常λ取值0.2,分數越高,表明結果與查詢相關性就越大,越符合用戶查詢要求。
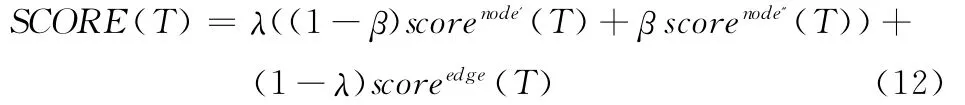
在實際應用中,關鍵詞表示的語義可能不同,例如關鍵詞 “于丹”,它可以是一個作者名,也可是一本書名中的術語。為了提高查詢靈活性,確定關鍵詞所屬類型,可將關鍵詞表示成 “作者:于丹”,說明查詢的關鍵詞類型為作者。關鍵詞類型的設置對于不熟悉系統的用戶來說會存在一定偏差,作者可能被描述成作家,寫書人等,系統應結合這種情況將這一類描述智能統一成作者。雖然該種表示方式包含兩個術語,但由于冒號前面用于標注關鍵詞類型,因而冒號前后做一個關鍵詞看待,只有當元組與關鍵詞內容和類型屬性完全匹配的時候,相關度的值為一個非零實數。
當輸入查詢關鍵詞時,只找到包含關鍵詞的元組遠不能滿足用戶的信息需求,表5定義了幾種針對DBLP數據集設置查詢條件的方式供用戶選擇。<#style>表示附加條件,#后面標注的是要查找的信息類型,只有當輸入的關鍵詞出現在同一個元組中時才考慮該附加條件。

表5 查詢條件的設置
4 實 驗
4.1 實驗環境
為了驗證文中提出的結果評分函數的有效性,做了一系列的實驗數據分析,本次實驗開發環境為Myeclipse+jdk1.6+tomcat6.0,基于postgreSQL數據庫用java語言實現功能,為了避免查詢過程中出現內存溢出的問題,在Myeclipse平臺下設置java虛擬機參數為 “-Xms256MXmx512M”,實驗設備為一臺內存為2G,CPU為酷睿雙核2.1GHz,操作系統為 Windows XP的PC機。
4.2 實驗結果
4.2.1 查詢結果的產生
查詢結果的獲取采用圖遍歷和位標記的方法,首先根據用戶輸入的關鍵詞找到包含關鍵詞的節點并采用n位二進制數對其進行位標記 (n值為關鍵詞個數),其它不包含關鍵詞節點的位標記值初始化為0,然后對圖遍歷并更新節點位標記值,遍歷過的節點位標記值更新為其可達關鍵詞節點的位標記值求或運算后的值,當節點的位標記值為所有關鍵詞節點位標記的或運算結果時,則稱該節點為能連接所有關鍵詞節點的中心節點,由中心節點,關鍵詞節點和它們之間的路徑便能得到一個結果組stenier樹。圖2為結果獲取的一個簡單實例。
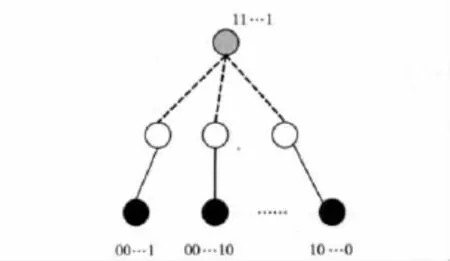
圖2 查詢結果樹的獲取
圖2中黑色節點為關鍵詞節點,灰色節點為可達所有關鍵詞節點的中心節點,虛線為節點之間的路徑。
4.2.2 實驗結果及分析
系統以文獻索引數據庫DBLP (digital bibliography &library project)作為實驗數據集對評分函數進行評估。實驗采用標準的IR評價指標 MRR (mean reciprocal rank),RR定義為1/rbest,即把最符合查詢條件的答案在被評價系統給出結果中的排序取倒數作為它的準確度,MRR則為多次求得RR的平均值。為了說明文中提出的結果評估函數(search EValution,SEV)的有效性,將在結果評分函數中參數值的估計和結果查準率兩個方面進行實驗。
(1)參數值的估算
評分函數中參數λ取值為0.2,該值參考經典的BANKS系統中的值,設置參數β值分別為0,0.002,0.004,0.006,0.008和0.01進行實驗,實驗每次輸入兩個關鍵詞,使用系統進行查詢操作并記錄最符合查詢條件的結果排序序號,對應不同的參數β,進行20組實驗,分別在系統查詢到的結果集中找到與輸入關鍵詞最相關的結果和它所排在的位置,通過最佳結果排序序號的倒數計算得到MRR值,實驗結果如圖3所示,從實驗結果可以看出,β最好的取值在0.002~0.006之間,因此,為了方便實驗數據的比較,后期將β參數值設為0.005。
(2)結果查準率
SEV評分函數的有效性采用信息檢索領域的查準率(precision)來評估,計算方法如下
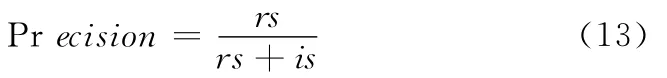
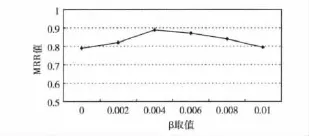
圖3 參數β取值0~0.01時的查詢結果MRR值
式中:rs (relevant results)——查詢到的與關鍵詞相關的結果數,is(irrelevant results)——查詢到的與關鍵詞不相關的結果數。
參數λ為0.2,β為0.005,當輸入關鍵詞個數分別為1,2和3時,計算top-k個查詢結果的查準率,實驗結果如圖4所示。

圖4 top-k結果查準率
實驗結果表明,當輸入關鍵詞個數為1時,輸出的top-k個結果幾乎都是與查詢相關的結果,當輸入多個關鍵詞時,輸出的結果有高度相似和冗余情況,使得結果查準率略微下降。
運行實驗系統,當輸入關鍵詞為2,3,4和5時,分別進行20次查詢,并求得平均查準率,將求得的平均查準率和SPARK[4],BLINKS[9]方法的平均查準率進行比較,SPARK和BLINKS方法的查準率參考文獻 [10]。比較結果如圖5所示,實驗結果表明文中所提方法的平均查準率比SPARK和BLINKS有所提高。
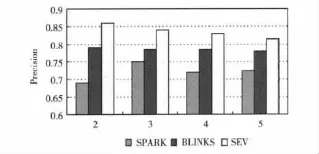
圖5 查詢結果在DBLP數據集中的平均查準率
5 結束語
SEV排序方法不僅考慮結果的結構權重,而且結合了查詢相關性的元組IR式權重,當元組同時包含多個關鍵詞時,元組權重明顯增加,相關的結果排序越靠前。該方法相比于BANKS系統中的排序方法,在輸入若干個查詢關鍵詞并且其中的兩個或兩個以上的關鍵詞出現在同一個元組的情況下,文中提出的方法能更有效的對結果進行排序。由于關鍵詞的選取對于用戶來說有一定的難度,因此,關鍵詞查詢過程的研究還有一定的空間,今后的工作將從查詢重寫和查詢提示方面開展。
[1]Wang Meirong,Jiang Lijun,Zhang Liru,et al.Exact top-k keyword search on graph databases [C]//Taichung,Taiwan:SAC,2011:985-986.
[2]Ding Bolin,Jeffrey Xu Yu,Wang Shan,et al.Finding top-k min-cost connected trees in databases [C]//Istanbul:Data Engineering,2007:836-845.
[3]Liu F,Yu C,Meng W.Effective keyword search in relational databases[C]//Chicago,Illinois,USA:The ACM SIGMOD International Conference on Manament of Data,2006:563-574.
[4]Luo Y,Lin X,Wang W.SPARK:Top-k keyword query in relational databases [C]//Cancun:ICDE,2007:115-126.
[5]Li G,Ooi B C,Feng J.EASE:An effective 3-in-1keyword search method for unstructured,semi-structured and structured data [C]//New York,NY,USA:SIGMOD,2008:903-914.
[6]Kasneci G,Ramanath M,Sozio M.STAR:Steiner-tree approximation in relationship graphs [C]//Shanghai,China:ICDE,2009:868-879.
[7]Günter Ladwig,Thanh Tran.Index structures and top-k join algorithms for native keyword search databases [C]//New York,NY,USA:ACM,2011:1505-1514.
[8]WANG Jiayi,YANG Luming,XIE Dong,et al.Ranking strategy of keyword search over relational databases [J].Computer Engineering and Design,2008,29 (10):2566-2569 (in Chinese).[王佳宜,楊路明,謝東,等.基于關系數據庫的關鍵詞查找排序策略 [J].計算機工程與設計,2008,29(10):2566-2569.]
[9]He H,Wang H,Yang J.BLINKS:Ranked keyword searches on graphs [C]//New York,NY,USA:Proceedings of the ACM SIGMOD International Conference on Management of Data,2007:305-316.
[10]Feng Jianhua,Guoliang L,Wang Jianyong.Finding top-k answers in keyword search over relational databases using tuple units [J].Knowledge and Data Engineering,2011,23(12):1781-1794.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
