基于增加最優(yōu)優(yōu)先搜索多樣性的研究
2013-09-10 01:17:24李偉生
計算機工程與設(shè)計 2013年9期
李偉生,代 飛
(重慶郵電大學(xué) 計算機科學(xué)與技術(shù)學(xué)院,重慶400065)
0 引 言
智能規(guī)劃是尋找一個有效動作序列,將某個現(xiàn)實問題從一個已知的初始狀態(tài)轉(zhuǎn)換成滿足特定條件的目標(biāo)狀態(tài)的過程,這種有效動作序列稱為規(guī)劃解。目前解決規(guī)劃問題主要有3種方法:第一種是規(guī)劃圖方法;第二種方法是約束可滿足方法;第三種方法是啟發(fā)式搜索方法,用啟發(fā)式函數(shù)產(chǎn)生規(guī)劃實例的估價,用該估價來指導(dǎo)規(guī)劃在狀態(tài)空間中的搜索。在以上3種方法中,以啟發(fā)式搜索的效率最好,并且可以結(jié)合其它方法。所以現(xiàn)今大多數(shù)的規(guī)劃器都采用了啟發(fā)式搜索技術(shù),它通過將規(guī)劃問題轉(zhuǎn)化為狀態(tài)空間上的路徑來搜索規(guī)劃解。規(guī)劃大賽中表現(xiàn)較好的規(guī)劃器如:Fast-Downward[1]、LAMA[2]等都采用了啟發(fā)式搜索策略。盡管,最優(yōu)優(yōu)先是一個相對有效的啟發(fā)式搜索策略。但當(dāng)啟發(fā)式函數(shù)對狀態(tài)節(jié)點估計有誤時,最優(yōu)優(yōu)先搜索的效率將會降低。比如啟發(fā)式函數(shù)將一些無利狀態(tài)節(jié)點的啟發(fā)式值估計為最小,然后,最優(yōu)優(yōu)先算法就會先去擴展這些無利的狀態(tài)節(jié)點,以至于搜索到的規(guī)劃解質(zhì)量不高。還有一種情況是在搜索狀態(tài)節(jié)點過程中會產(chǎn)生一種狀態(tài)節(jié)點啟發(fā)式值不再減少的高原現(xiàn)象[3-4],如果還是單一依賴啟發(fā)式函數(shù)估計的最優(yōu)狀態(tài)節(jié)點進(jìn)行搜索,不采用別的方法避免這種高原狀態(tài)的話,會導(dǎo)致規(guī)劃代價較大。
本文以主流的規(guī)劃器LAMA[2]為研究對象。深入分析了最優(yōu)優(yōu)先搜索策略的優(yōu)缺點,提出了一種增加狀態(tài)節(jié)點選擇多樣性的方法,通過對不同路徑執(zhí)行盡量多的搜索,能夠避免由于啟發(fā)式函數(shù)地估計錯誤和高原狀態(tài)而導(dǎo)致搜索到的規(guī)劃解的最優(yōu)度不高的問題。
1 相關(guān)的啟發(fā)式搜索策略
隨時修復(fù) A* (anytime repairing A*)[5]。它在搜索到一個規(guī)劃解時,利用此次規(guī)劃解的代價進(jìn)行剪枝,力求得到代價更小的解。在Anytime Repairing A*迭代搜索中,上次搜索成功后產(chǎn)生的節(jié)狀態(tài)節(jié)點繼續(xù)保留為下次使用。但在這里就存在一個問題,由于啟發(fā)式函數(shù)的估計并不準(zhǔn)確,如果不清空,當(dāng)上次搜索到一個質(zhì)量較差的規(guī)劃解時,下次搜索規(guī)劃解時會受到上次搜索時所產(chǎn)生的狀態(tài)節(jié)點的影響,不利于改善規(guī)劃質(zhì)量[6]。
KBFS (K-best-first-search)[7]。KBFS是最優(yōu)優(yōu)先搜索和廣度優(yōu)先搜索[8]的結(jié)合。KBFS選擇節(jié)點擴展時,先從開列表中選擇K (K>1)個最優(yōu)狀體節(jié)點擴展,然后才產(chǎn)生后繼狀態(tài)節(jié)點。該算法通過延遲檢測后繼狀態(tài)節(jié)點的啟發(fā)式信息,來增加搜索的多樣性。參數(shù)K用于增加狀態(tài)節(jié)點選擇的范圍,K越大,搜索中擴展的狀態(tài)節(jié)點越多,就能在狀態(tài)空間中搜索到不同的路徑,進(jìn)而選擇最優(yōu)路徑。KBFS能夠在一定程度上避免由于啟發(fā)式函數(shù)估計錯誤而導(dǎo)致的高原狀態(tài)和局部最優(yōu)先現(xiàn)象。但是,如果它所選擇的這K個狀態(tài)節(jié)點被錯誤的估計為有利狀態(tài)節(jié)點的話,就會導(dǎo)致搜索到的規(guī)劃解最有度不高。可以通過增加K值來避免這種情況,但是隨著K值變大,KBFS的搜索類似于廣度優(yōu)先搜索,無法利用啟發(fā)式信息指導(dǎo)搜索,導(dǎo)致整個搜索過程效率低下。
自由走步 (random-walk)策略[9-10]。它采用了一種探測策略,在一定的搜索步長范圍內(nèi),隨機擴展一些狀態(tài)節(jié)點,從而在一定程度上避免了單一依賴啟發(fā)式函數(shù)指導(dǎo)搜索導(dǎo)致的問題,增加了選擇的多樣性。但是這種方法有一個問題,它會忽略已搜索到的狀態(tài)空間,使得相同的狀態(tài)節(jié)點在不同的路徑上被重復(fù)估計。
2 BBFS (better-best-first-search)算法
2.1 最好優(yōu)先搜索存在的問題
圖1中英文字母代表狀態(tài)節(jié)點,括號中的數(shù)字代表每個狀態(tài)節(jié)點的啟發(fā)式值,大寫字母G代表目標(biāo)狀態(tài)節(jié)點,實線代表搜索中的路徑,括號中的數(shù)字代表狀態(tài)節(jié)點的啟發(fā)式值。如圖1所示,如果采用最優(yōu)優(yōu)先搜索策略,最開始擴展?fàn)顟B(tài)節(jié)點B,然后,產(chǎn)生其后繼狀態(tài)節(jié)點,由于其后繼狀態(tài)節(jié)點的啟發(fā)式值都比較小,所以會不斷的擴展這些啟發(fā)式值最小的狀態(tài)節(jié)點,但這些后繼狀態(tài)節(jié)點并不是在目標(biāo)路徑上。如果,不單一地依賴最優(yōu)狀態(tài)節(jié)點,考慮更多的次優(yōu)狀態(tài)節(jié)點,那么在搜索過程中就有可能避免由于過度啟發(fā)式函數(shù)指導(dǎo)搜索而導(dǎo)致的局部最優(yōu)和高原狀態(tài)。
如圖1所示,通過增加狀態(tài)節(jié)點選擇的多樣性,能夠找 {A,C,J,O,T,G},{A,D,K,P,G},{A,E,G}這幾個質(zhì)量較高的規(guī)劃解。
2.2 算法基本思想
通過對最優(yōu)優(yōu)先搜索策略中存在問題的分析。我們可以從兩方面來改善搜索策略:①將最優(yōu)優(yōu)先搜索中的開列表細(xì)化為多個包含不同啟發(fā)式信息的列表,然后通過一定的概率來選擇細(xì)化后的開列表,進(jìn)而增加鏈表選擇的多樣;②每次選擇多個狀態(tài)節(jié)點進(jìn)行擴展,而不僅僅只選擇最優(yōu)狀態(tài)節(jié)點進(jìn)行擴展。

圖1 局部最優(yōu)和高原狀態(tài)
相對于KBFS(K),本算法不僅僅選擇單個列表中最優(yōu)的K個狀態(tài)節(jié)點,而是在多個列表中選擇狀態(tài)節(jié)點,BBFS能夠有更大的可能來選擇那些被錯誤估計為無利狀態(tài)的節(jié)點。相對于自由走步,BBFS會將已經(jīng)擴展的狀態(tài)節(jié)點保存在關(guān)列表中,所以它可以有效地使用已經(jīng)搜索到的狀態(tài)空間。比如,當(dāng)擴展的狀態(tài)節(jié)點在多條不同的搜索路徑上時,就可以直接利用以前的啟發(fā)式值,而不再重復(fù)計算。BBFS是一個完備的算法。換句話說,就是在給定的時間和內(nèi)存限制下,當(dāng)存在規(guī)劃解的時候,他可以返回一個規(guī)劃解,當(dāng)無法找到規(guī)劃解時,它可以正確的退出。
2.3 算法實現(xiàn)步驟
算法1和算法2給出了BBFS的偽代碼。算法1用于狀態(tài)節(jié)點的擴展;算法2用于獲取狀態(tài)節(jié)點。BBFS整個算法的流程比較簡單:從包含不同啟發(fā)式信息的開列表中選擇多個狀態(tài)節(jié)點進(jìn)行擴展后,再生成這些擴展?fàn)顟B(tài)節(jié)點的后繼節(jié)點,直到找到規(guī)劃解或者發(fā)現(xiàn)規(guī)劃解不存在為止。BBFS旨在一定的范圍內(nèi)增加狀態(tài)節(jié)點的多樣性,而不是通過完全丟棄啟發(fā)式信息來增加狀態(tài)空間搜索的多樣性,所以BBFS每次擴展的狀態(tài)節(jié)點數(shù)即K值設(shè)置為5,這里的K值設(shè)定為5并不是必須的,在內(nèi)存可以的情況下,K值可以適當(dāng)設(shè)置大一點,比如K=10。BBFS通過一個關(guān)列表保存所有已經(jīng)擴展的狀態(tài)節(jié)點,從而使得這些狀態(tài)節(jié)點再次被擴展時,不再重新估計它們的啟發(fā)式值,避免了自由走步的問題。當(dāng)K個狀態(tài)節(jié)點被擴展后,它們所產(chǎn)生的后繼狀態(tài)節(jié)點將放入包含不同啟發(fā)式信息的開列表中。
算法1 Better-Best-First-Search


算法2get the K nodes from all of the open_lists

算法1中,將初始狀態(tài)節(jié)點放入任意的一個開列表中,然后進(jìn)行擴展 (第1行)。全局變量gpselectsum用于表示所有開列表優(yōu)先級的總和,gpselectopen_list1用于表示包含F(xiàn)F啟發(fā)式信息開列表的優(yōu)先級,gpselectopen_list2用于表示包含路標(biāo)啟發(fā)式信息開列表的優(yōu)先級 (第4行~第6行)。開列表可以根據(jù)不同的規(guī)劃器包含的啟發(fā)式信息類型而設(shè)置,由于LAMA包含了FF和路標(biāo)啟發(fā)式信息,所以這里的開列表設(shè)置了兩個:open_list1,open_list2。如果被擴展的狀態(tài)節(jié)點是目標(biāo)狀態(tài)節(jié)點則返回規(guī)劃解 (第12行~第14行)。每次擴展一個狀態(tài)節(jié)點,如果該狀態(tài)節(jié)點在open_list1被發(fā)現(xiàn)且其啟發(fā)式值比以前狀態(tài)節(jié)點的啟發(fā)式值小,則提高包含該狀態(tài)節(jié)點列表的優(yōu)先級,以期發(fā)現(xiàn)更多的有利狀態(tài)節(jié)點,并修改gpselectsum的值 (第17行~第19行)。如果該狀態(tài)節(jié)點在open_list2被搜索到且其啟發(fā)式值以前發(fā)現(xiàn)的啟發(fā)式值小,則提高包含該有利狀態(tài)節(jié)點列表的優(yōu)先級,并修改gpselectsum的值 (第21行~第23行)。如果所有的開列表都搜索完成,還是沒有搜索到規(guī)劃解則返回失敗信息。(第27行)。
算法2中,每從一個開列表中獲取一個狀態(tài)節(jié)點就降低該列表的優(yōu)先級 (第7行)。主要是為了防止算法1中過度的增加單個列表的優(yōu)先級,使得搜索多次在同一個列表中選擇狀態(tài)節(jié)點,不利于增加節(jié)點選擇的多樣性。同時,當(dāng)在某個開列表出現(xiàn)了高原現(xiàn)象之后,通過減少該列表的優(yōu)先級,選擇另外的開列表,可以在一定程度避免這種高原狀態(tài)。
參數(shù)Y (Y>1)主要用于控制在不同開列表中狀態(tài)節(jié)點被選中的可能性。BFS通常將所有產(chǎn)生的狀態(tài)節(jié)點放在單個開列表中,然后再選擇啟發(fā)式值最小的狀態(tài)節(jié)點進(jìn)行擴展。BBFS通過將包含不同啟發(fā)式信息的節(jié)點進(jìn)行分類,歸納在多個開列表中。然后,每次擴展和獲取狀態(tài)節(jié)點時,就更新這些開列表的優(yōu)先級,每個開列表以最高概率YP1/P2被選中,其中P1=gpselectopen_list1,P2=gpselectopen_list2。
如果BFS選中了一個無利狀態(tài)節(jié)點,該無利狀態(tài)節(jié)點的后繼節(jié)點有一個較小的啟發(fā)式值,它將會繼續(xù)擴展該無利狀態(tài)節(jié)點的后繼,使得搜索的方向出現(xiàn)偏差。但是,當(dāng)BBFS選中一個無利狀態(tài)節(jié)點,即使該狀態(tài)節(jié)點的后繼的啟發(fā)式值較小,它也不會立即擴展該狀態(tài)節(jié)點的后繼,而是選擇另外的非該狀態(tài)節(jié)點的后繼狀態(tài)節(jié)點,進(jìn)行擴展。這樣就在一定程度上避免了搜索陷入局部最優(yōu)的問題。
3 實驗結(jié)果分析
本文選取了問題規(guī)模較大的openstacks、nomystery規(guī)劃域進(jìn)行實驗驗證,其中每個規(guī)劃域里面包含20個問題。這些規(guī)劃問題全部來自2011國際規(guī)劃大賽。實驗環(huán)境是在單核處理器2.80Ghz AMD Athlon (tm)II X2 2400,內(nèi)存2GB,Ubuntn-10.10 (Linux kernel 2.6.35-22-generic),編譯器為g++4.4.5的環(huán)境下進(jìn)行地測試。設(shè)定規(guī)劃超時限為規(guī)劃大賽規(guī)定的30分鐘 (1800s)。在LAMA中采用了兩種啟發(fā)式搜索算法,一種是最優(yōu)優(yōu)先,另一種的加權(quán)A*,兩種算法的搜索的基本流程差不多,差別在于啟發(fā)式函數(shù)的代價計算方式不同。所以BBFS可以很好的與加權(quán)A*結(jié)合。此次實驗也將BBFS加入到加權(quán)A*中。如圖2所示,在狀態(tài)空間較大的openstack領(lǐng)域,本文通過增加LAMA中狀態(tài)節(jié)點選擇的多樣性,減少搜索對于啟發(fā)式函數(shù)的依賴,縮短了規(guī)劃解長度,DLAMA (Diversity-LAMA)表示在LAMA中采用了BBFS算法增加搜索中的多樣性。這說明本方法在一定程度上避免了搜索中的局部最優(yōu)和高原狀態(tài),改善了規(guī)劃解的質(zhì)量。

圖2 DLAMA和LAMA規(guī)劃長度和規(guī)劃待代價對比,x軸代表規(guī)劃問題的編號
表1和表2列出的是本文方法和LAMA對規(guī)劃大賽中openstack和normstery領(lǐng)域?qū)嶒灥囊?guī)劃代價和規(guī)劃步長。如表1所示,在大規(guī)模規(guī)劃領(lǐng)域openstack中,雖然前3個規(guī)劃問題DLAMA搜索到的規(guī)劃代價比LAMA的高,但是其規(guī)劃步長較比LAMA短,說明其在一定程度上避免了搜索中高原狀態(tài)的出現(xiàn),減少了規(guī)劃步長。在后17個規(guī)劃問題中,本方法搜索到的規(guī)劃解在代價開銷和規(guī)劃步長方面都比LAMA好,主要原因在于:隨著問題規(guī)模的逐步擴大,啟發(fā)式函數(shù)對狀態(tài)節(jié)點的估計變得越來越不準(zhǔn)確,LAMA單一依賴啟發(fā)函數(shù)進(jìn)行搜索就會出現(xiàn)偏差,本方法通過增加狀態(tài)節(jié)點選擇的多樣性,在一定程度上降低搜索對啟發(fā)式函數(shù)的依賴,使得在搜索目標(biāo)狀態(tài)過程中能過糾正啟發(fā)函數(shù)估計錯誤而導(dǎo)致的問題。由表2可知,在normstery領(lǐng)域中,LAMA的平均規(guī)劃代價和規(guī)劃步長為29.9,本方法的平均規(guī)劃代價開銷和規(guī)劃長度為25.2。從上面的實驗結(jié)果可以看出,本文提出的方法改善了規(guī)劃解的質(zhì)量。
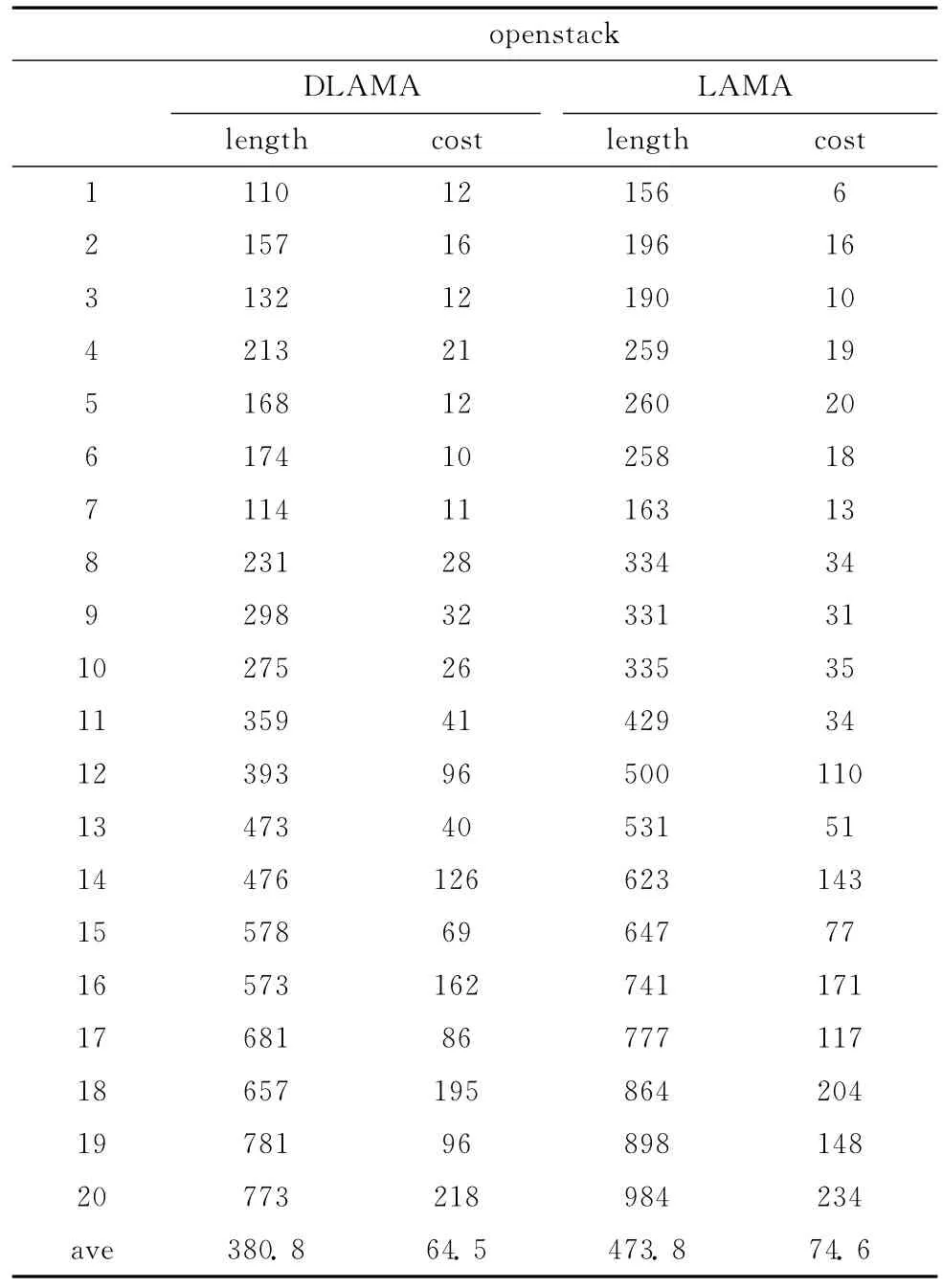
表1 openstack領(lǐng)域規(guī)劃長度和規(guī)劃代價比較

表2 normstery領(lǐng)域規(guī)劃長度和規(guī)劃代價比較
4 結(jié)束語
本文通過分析最優(yōu)優(yōu)先搜索策略單一依賴啟發(fā)式函數(shù)指導(dǎo)搜索而導(dǎo)致的問題。提出了增加開列表多樣性和狀態(tài)節(jié)點選擇多樣性的方法,減少搜索對啟發(fā)式函數(shù)的依賴,進(jìn)而避免由于啟發(fā)式函數(shù)估計錯誤而導(dǎo)致的局部最優(yōu)和高原狀態(tài)。該方法立足于在搜索過程中發(fā)現(xiàn)更多的路徑,使得搜索不單一地選擇估計的最優(yōu)路徑方向進(jìn)行搜索,從而實現(xiàn)對規(guī)劃質(zhì)量的改善。實驗結(jié)果表明,該方法是可行的。
然而,現(xiàn)實規(guī)劃問題多種多樣,本文所提出的方法只是在一定范圍內(nèi)增加了狀態(tài)節(jié)點選擇的多樣性,隨著更多復(fù)雜規(guī)劃問題的出現(xiàn),本方法在增加多樣性方面也就有了進(jìn)一步擴展的空間。可以在開列表選擇方式中加入相關(guān)的啟發(fā)式值參數(shù),然后將參數(shù)Y的指數(shù)換成啟發(fā)式值和各個開列表優(yōu)先級的一個加權(quán),通過這樣來進(jìn)一步增加搜索中選擇的多樣性,這是一個值得研究的方向。
[1]Helmert M.The fast downward planning system [J].Journal of Artificial Intelligence Research,2006,26 (1):191-246.
[2]Richter S,Westphal M.The LAMA planner:Guiding costbased anytime planning with landmarks [J].Journal of Artificial Intelligence Research,2010,39 (1):127-77.
[3]Lu Q,Xu Y,Huang R,et al.The roamer planner randomwalk assisted best-first search [C]//Proc International Plan-ning Competition,2011:73-76.
[4]Benton J,Talamadupula K,Eyerich P,et al.G-value plateaus:A challenge for planning[C]//Proceedings of the International Conference on Automated Planning and Scheduling,2010:259-262.
[5]Eric A Hansen,Zhou Rong.Anytime heuristic search [J].Journal of Artificial Intelligence Research,2007,28 (1):267-297.
[6]Richter S,Thayer J T,Ruml W.The joy of forgetting:Faster anytime search via restarting [C]//Proceedings of the Twentieth International Conference on Automated Planning and Scheduling,2010:137-144.
[7]Carlos Linares,Daniel Borrajo.Adding diversity to classical heuristic planning [C]//Proceedings of the Third Annual Symposium on Combinatorial Search,2010:73-80.
[8]Zhou R,Hansen E A.Breadth-first heuristic search [J].Artificial Intelligence,2006,170 (4-5):385-408.
[9]Nakhost H,Müller M.Monte-Carlo explorationfor deterministic planning [C]//Proceedings of the Twenty-First International Joint Conference on Artificial Intelligence,2009:1766-1771.
[10]Maxim Likhachev,Anthony Stentz.R*search [C]//Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence,2008:344-350.
猜你喜歡
公民與法治(2020年11期)2020-07-25 02:02:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
領(lǐng)導(dǎo)決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛(wèi)生(2016年2期)2016-11-12 13:22:16
華東科技(2016年10期)2016-11-11 06:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
中國工程咨詢(2016年4期)2016-02-14 07:28:28
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
