基于高維特征非線性篩選的HLA-A*0201限制性CTL 表位預測
2013-09-21 09:00:18袁哲明代志軍王志明
物理化學學報 2013年9期
關鍵詞:模型
韓 娜 袁哲明 陳 淵 代志軍 王志明
(湖南農業大學,湖南省作物種質創新與資源利用重點實驗室,湖南省植物病蟲害生物學及防控重點實驗室,長沙410128)
1 引言
細胞毒性T淋巴細胞(CTL)作為免疫細胞T細胞家族的重要成員,在惡性腫瘤治療中起了關鍵作用.1其中,與主要組織相容性復合物(MHC-I)結合的抗原短肽即CTL表位(epitopes),對CTL特異性殺傷效應起決定作用,被廣泛應用于多肽疫苗設計.因實驗方法鑒定CTL表位效率較低,CTL表位測定成為此類多肽疫苗設計開發的瓶頸,發展基于計算機算法的高精度CTL表位快速鑒定意義重大.
多肽空間結構與功能本質上由其一級結構(氨基酸序列)決定,高級結構很難測定而一級結構簡便易得.已有研究結果表明,處于結合狀態抗原肽立體結構受HLA-A*0201影響較小,決定抗原肽與HLA-A*0201結合強弱關鍵在于抗原肽殘基與附近HLA-A*0201殘基作用大小;受體HLA-A*0201可認為不變,故抗原肽序列各位點殘基差異導致它們間親和活性不同.2因此,多肽定量序效模型(QSAM)研究在研發肽類新藥特別是抗原肽疫苗方面具廣泛應用前景.多肽QSAM建模的兩個重要內容是回歸模型選擇和其一級結構表征.在回歸模型選擇方面,常用的多元線性回歸、偏最小二乘回歸、神經網絡等存在諸多弊端;3?6而基于結構風險最小的支持向量回歸(SVR)較好地解決了小樣本、非線性、過擬合、維數災難和局部極小等問題,模型的外部預測能力優異.4因此本研究選用SVR為基本建模工具.在多肽一級結構表征方面,主要有基于氨基酸性質主成分分析的氨基酸描述子和直接基于氨基酸性質的氨基酸描述子兩類.前者如Z標度,7,8每一主成分(描述子)是相應氨基酸多種物化性質的線性加權,雖綜合性、代表性較好,但實現的是初始描述子的線性壓縮與去冗余,難以反映初始描述子與多肽活性間的復雜非線性關系,且模型解釋困難.后者如殘基側鏈全向表面積-電荷指數(ISA-ECI),9雖描述子物化意義明確、解釋性較好,但每個氨基酸殘基僅由ISA和ECI兩個參數表征顯然不夠全面.氨基酸指數數據庫(http://www.genome.jp/aaindex/)中的531個特征是氨基酸物理化學性質的較全面總結,理論上可直接作為描述子用于肽、蛋白質結構表征,但由此衍生的問題是特征維數巨增,且無關、冗余特征影響模型精度.從m個特征中選取最優特征子集理論上有2m種可能,在m較大時無法窮舉;多數現有啟發式特征選擇方法存在易陷入局部最優的缺陷;10以逐步線性回歸篩選獲得的特征應用于SVR等非線性建模,在理論上和實踐上均缺乏證據支持.6
鑒此,本文以氨基酸的531個物理化學性質直接表征多肽序列,集成基于SVR發展的二元矩陣重排過濾器、多輪末尾淘汰非線性精細篩選方法以及SVR非線性解釋性體系,運用于CTL表位鑒定,建立了精度高、解釋性強的QSAM模型,并基于該模型對1.28×109條(其中2個位置被固定)虛擬9肽進行預測,獲得了244880條預測活性高于8.77(現有最高實測值)的9肽,其中最高活性值達到9.707.結果報道如下.
2 數據與方法
2.1 數據來源
152條HLA-A*0201限制性CTL表位9肽序列與親和活性pIC50引自文獻,11其中多肽序列GLYSSTVPV出現兩次但活性值不同,本文予以去除.為便于比較,參照文獻11劃分訓練集(101個樣本)和測試集(49個樣本).pIC50為IC50的負對數,IC50(單位為nmol·L?1)為采用不同濃度的待測肽與0.5 nmol·L?1的放射性標記的HBVc18227(FLPSDYEPSV)T細胞表位肽(對照肽)與HLA-A*0201的復合物在溫室下共孵育2 h,測定待測肽序列將對照肽/HLA-A*0201的復合物中50%的對照肽置換下來的濃度.
2.2 多肽序列表征
每條多肽序列上的每個氨基酸殘基由氨基酸指數數據庫中的531個描述子表征(命名為AA531),依次串聯排列.每條9肽含4779個初始描述子.
2.3 二元矩陣重排過濾器
假定初始訓練集由n維列向量Y和n行m列矩陣X組成,本文中Y為親和活性值pIC50,X為初始描述子.首先有條件隨機產生k行m列取值為0或1的矩陣M(限制條件為每列0與1的個數均衡),k可根據m值的大小和每輪篩選所耗費時間適當取值,本文k初始值為500,并每輪以步長50遞減,下限為200.其次,矩陣M的每行以0(剔除)和1(保留)對應取出X的列,產生k個子集(i=1,2,...,k),所有子集分別與Y組成k個數據集,各個數據集基于SVR經交叉測試(如未特別說明,本文交叉測試次數均為5次,核函數固定為徑向基核,核函數參數經自動尋優給出)獲得k個均方誤差MSE,并與M組合成新的數據集D.最后,判斷各特征是否保留時,先將M對應列各元素值取反得M′,與k個MSE組合后作為測試集,D作為訓練集,預測得到k個MSE',按照M和M′第一列以0和1值對k個MSE和k個MSE'進行 分類,對得到的k個MSE0和k個MSE1取均值和除.12,13對保留的m1個特征對應原始數據集取出相應則保留該特征,反之剔列作為新的特征集X1,與Y組合成粗篩后的數據集D1,用于后續多輪末尾淘汰.
2.4 多輪末尾淘汰非線性精細篩選
基于SVR計算數據集D1的交叉測試MSE0.在第一輪篩選時,特征集X1(xij∈X1,i=1,...,n;j=1,...,m1)逐次刪除第p列得到m1個特征子集X2(xij∈X2,i=1,...,n;j=1,...,p?1,p+1,...,m1),交叉測試得到向量MSEj(j=1,...,m1),若min(MSEj)≤MSE0,則剔除相應特征,反之篩選結束.6,12新特征子集X2(xij∈X2,i=1,...,n;j=1,2,...,m1?1),與Y組合得到D2進入下一輪,直到沒有變量剔除為止.
2.5 SVR非線性解釋性體系
2.5.1 SVR模型非線性回歸顯著性檢驗
常用評估SVR模型優劣的MSE等指標,在不同數據集間不具可比性,且無法給出定性判斷.這里引入F統計量:14

回歸平方和:

剩余離差平方和:

其中,n為樣本個數,m′為保留因子個數,yi、yi分別為第i個樣本真值和估計值,yˉ為所有樣本真值的均值,F自由度為 (m′,n?m′?1).當F > Fα(m′,n?m′?1),則表明SVR模型在α水平上非線性回歸顯著.
2.5.2 單因子重要性分析
因子越重要,則因變量Y隨其大小變化越明顯.將xj固定為零水平(平均值),其它因子值不變作為測試集代入所建最優SVR模型,據預測值計算得到代表了x對j回歸平方和的貢獻.14由于非線性SVR模型中,離均差平方和SSy≠Q+U,因此本文利用矯正后的U′=U/(U+Q)×SSy和Q′=Q/(U+Q)×SSy,Q和U規格化到SSy=Q′+U′并計算xj固定下的Fj值:
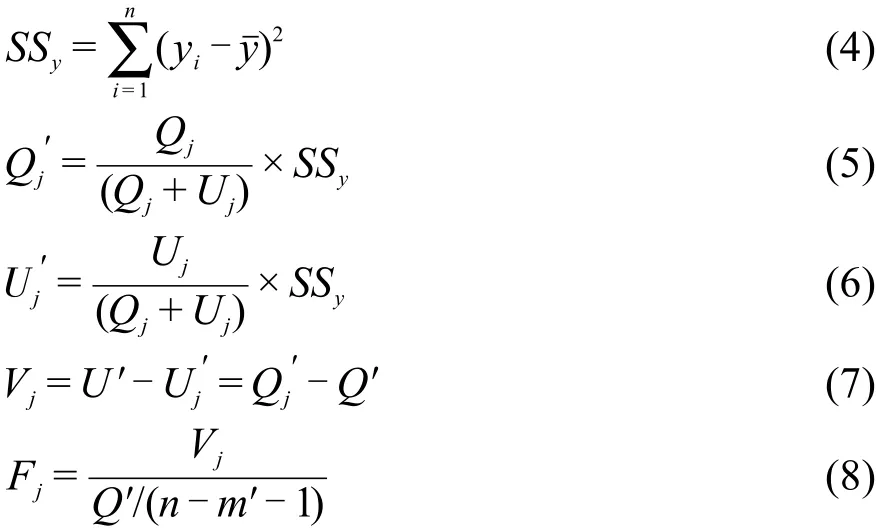
其中,y′i分別為固定 xj的第 i個樣本估計值,Fj的自由度ν1和ν2分別為1和n?m′?1.
2.5.3 單因子效應分析
為了解隨著單個因子xj的變動,因變量Y的變化趨勢,采用基于SVR的非線性單因子效應分析.14先將除xj外其他因子固定為其均值,并令xj在固定取值區間(通常為xj的極差)內按一定步長取多個水平,代入所建最優SVR模型獲得預測值y,各因子規格化后作x?y效應圖.
二元矩陣重排過濾器粗篩、多輪末尾淘汰精細篩和SVR非線性解釋性體系以自編Matlab程序通過調用Libsvm 3.1軟件包15實現并經驗證通過.核函數固定為徑向基核,核函數各參數基于gridregression.py搜索自動獲取.
2.6 模型評價
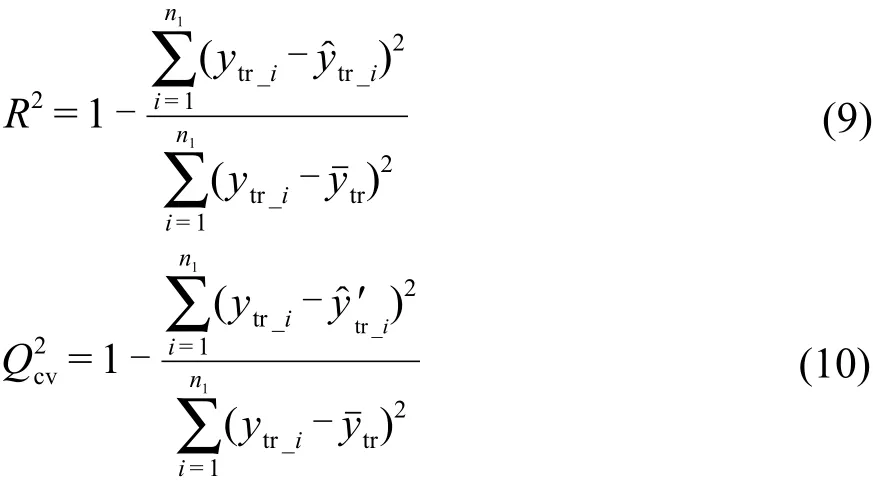
訓練集擬合精度及交叉驗證精度采用決定系數R2和表示:16,17其中,ytr_i和ytr_i分別為訓練集樣本真值和擬合值,yˉtr為訓練集樣本真值的均值,y'tr_i為訓練集交叉驗證預測值,n1為訓練集樣本個數.
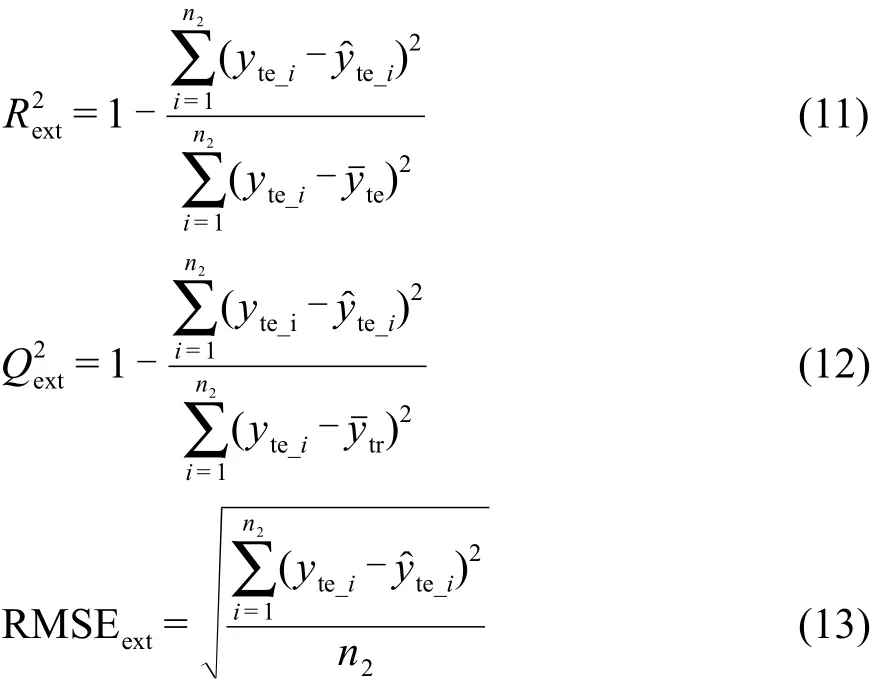
其中,yte_i和yte_i分別為測試集樣本真值和預測值,yˉte為測試集樣本真值的均值,n2為測試集樣本個數.
3 結果與討論
3.1 模型檢驗
訓練集初始描述子個數為4779,基于SVR的交叉驗證,MSE為0.359;經二元重排過濾器(BMSF)粗篩后,描述子個數降為27,交叉驗證MSE降為0.215;進一步以多輪末尾淘汰法非線性精細篩選,得18個保留描述子,交叉驗證MSE降至0.201.基于18個保留描述子,以訓練集構建最優SVR模型,150條HLA-A*0201表位肽序列及其生物活性值、訓練集擬合值、測試集預測值見表1;其擬合、留一法交叉驗證決定系數R2、分別為0.957、0.708;獨立預測決定系數及均方根誤差、RMSEext分別為0.818、0.366,明顯優于現有文獻報道結(表2).圖1和圖2進一步直觀展示了訓練集擬合和測試集預測的優異結果.
3.2 模型解釋
對表1全部150個樣本基于18個保留描述子建立SVR模型,F(=151.032)>F0.01(18,131)(=2.075),表明非線性回歸極顯著.18個保留描述子單因子重要性分析結果見表3,均達極顯著(F0.01(1,131)=6.832).18個保留描述子的單因子效應分析結果見圖3.
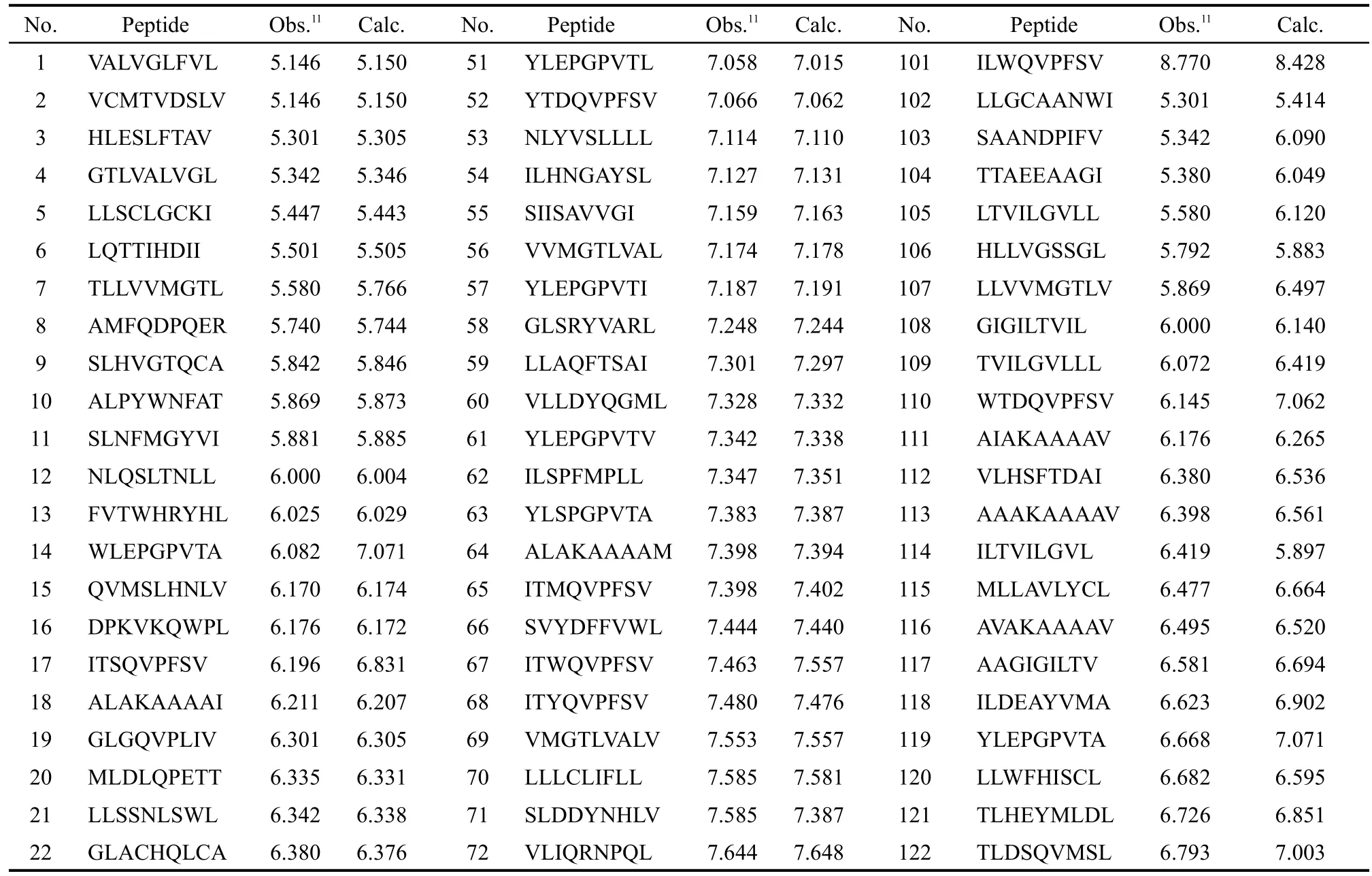
表1 CTL表位的氨基酸序列與親和性(pIC50)的實驗值與預測值Table 1 CTLepitopes sequences with observed and predicted values(pIC50)of binding affinity
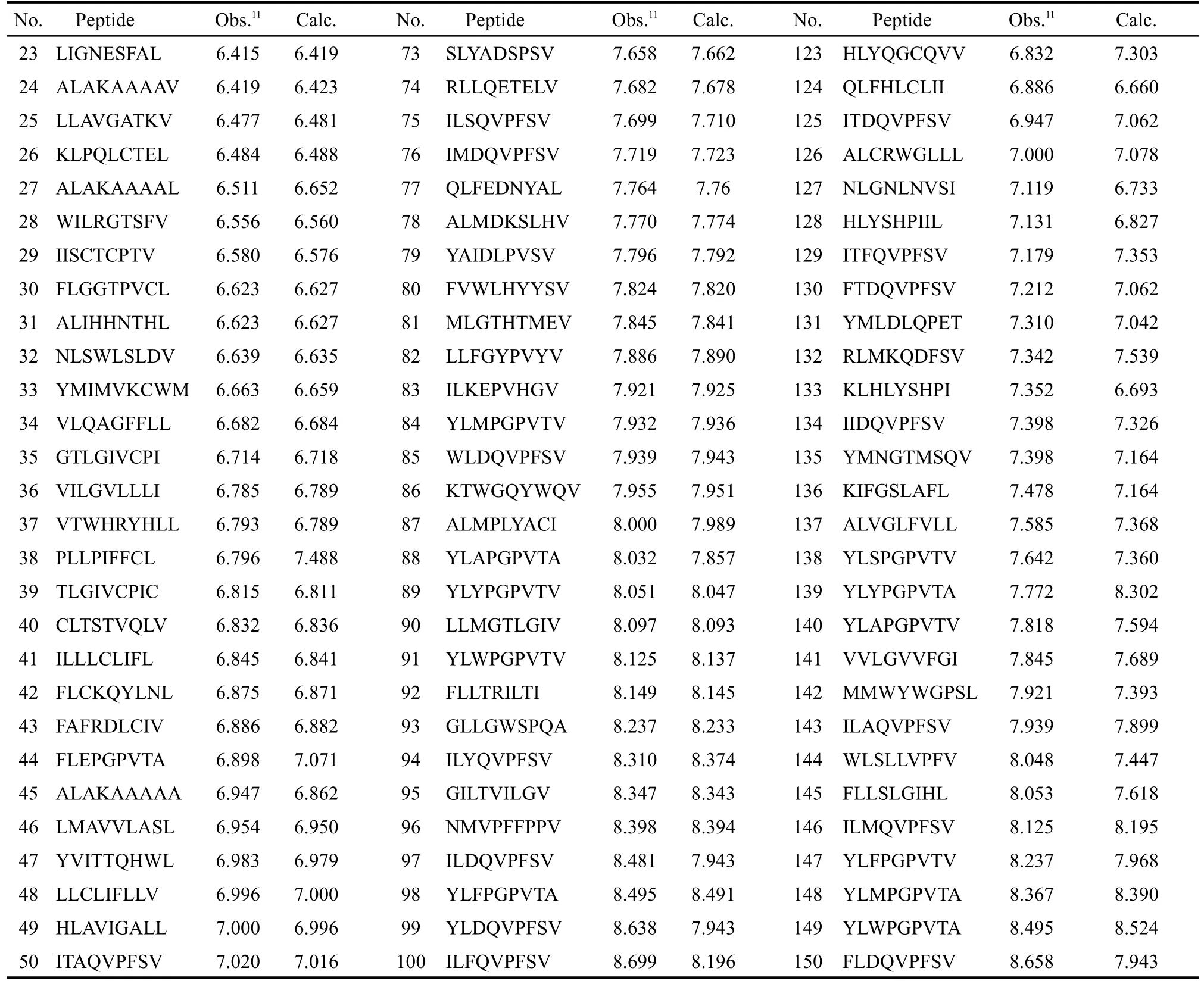
continued Table 1
3.3 高活性肽分子設計
由前所述,基于表1全部150個樣本、18個保留描述子建立的SVR模型可以信賴,現依該模型進一步進行高活性表位肽預測與分子設計.9肽全組合預測集生成如下:因1位和5位為非重要殘基,且實測150個9肽中活性最高表位肽為ILWQVPFSV(pIC50=8.77),可固定1位殘基為I,5位殘基為V;其余7個位置殘基(7因素)每個位置由20種天然氨基酸依次取代(20水平),共產生207=1.28×109條虛擬9肽.預測結果表明,預測值大于8.77的9肽有244880條,最高預測值為9.707.預測值最高的前10條9肽見表4,可供進一步實驗驗證.
對預測值大于9.3的3276條虛擬9肽,逐位統計氨基酸出現頻次,結果見圖4(其中1位殘基固定為I,5位殘基固定為V),各位置上字母越突出,則表示該氨基酸在該位置出現頻次越高.
3.4 各位置氨基酸殘基與親和活性的關系
結合表3、圖3和圖4,逐位殘基(除第1位和第5位非重要殘基外)對表位肽活性影響分析如下.
Position 2(P2):多肽親和性與該位殘基多肽環信息測度、24STERIMOL最大側鏈寬度值、25?6窗口位置卷曲螺旋權重值26等氨基酸空間性質有較大關聯(表3),且與多肽環信息測度呈顯著正相關,與STERIMOL最大側鏈寬度值呈負相關(圖3).該位殘基對抗原肽與MHC分子結合起重要作用,通常被認為是“錨點”.11頻次統計分析顯示,P2位為Val、Ala、Glu、Leu、Ile、Met等6種殘基有助于提高表位肽活性(圖4),與結合基序法認為該位Ile、Met和Val是初級錨點的結論相近.27本文結果支持P2位為關鍵殘基位點的現有認知,但解釋不同,以往研究認為多肽親和性與P2位殘基的疏水性和電性有關,本文認為主要與P2位殘基的空間性質有關.
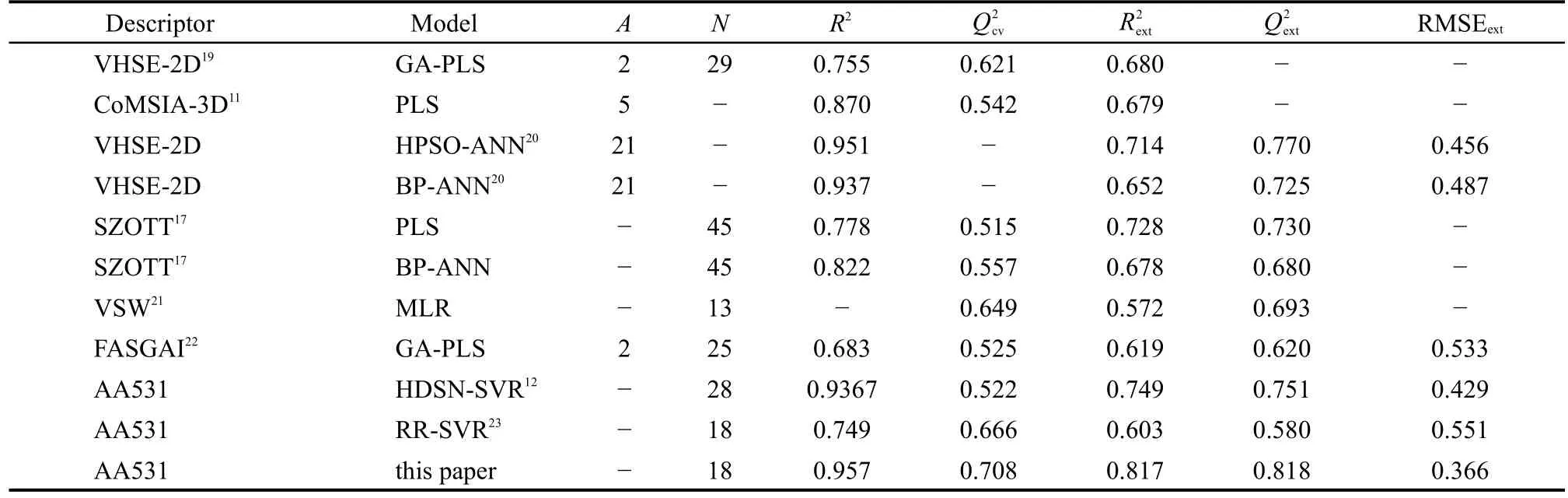
表2 CTL表位的QSAR/QSAM模型比較Table 2 Comparison between QSAR/QSAM models of CTLepitopes
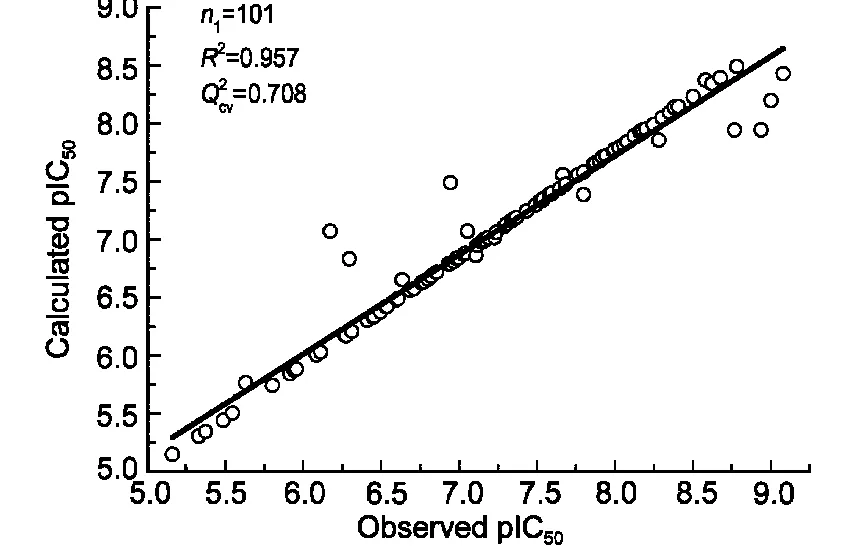
圖1 訓練集樣本活性的實驗值與回歸值Fig.1 Observed values vs predicted values of binding affinity of training samples
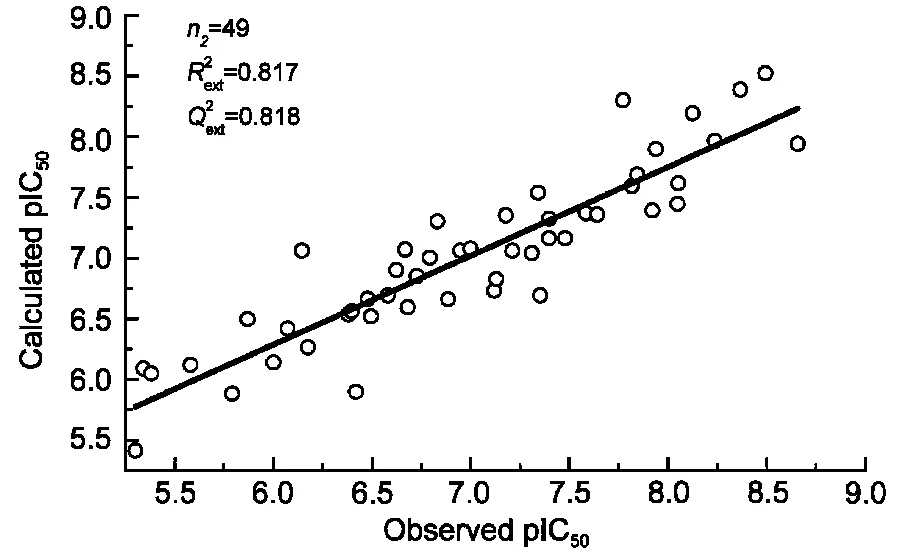
圖2 測試集樣本活性的實驗值與回歸值Fig.2 Observed values vs predicted values of binding affinity of testing samples
Position 3(P3):多肽親和性與該位殘基的β-蛋白標準疏水值、28改進Kyte-Doolittle疏水值29等氨基酸疏水性質有較大關聯(表3),且與前者呈正相關關系(圖3);頻次統計顯示該位可出現14種殘基,其中Trp、Tyr、Phe三種殘基合計頻率超過80%(圖4),與Doytchinova等11該位殘基側鏈為芳香烴的疏水性氨基酸Trp、Tyr、Phe有利于提高親和活性的觀點一致.
Position 4(P4):多肽親和性與該位殘基的圖形形狀指數(反映氨基酸空間性質的綜合指標)、25主成分IV(反映氨基酸多種性質的綜合指標)、30側鏈交互作用參數(反映氨基酸側鏈間范德華力作用大小的指標)31和平均彈性指數(穩定性指標)32等四個性質有較大關聯(表3),且與前兩者呈負相關,與后兩者呈正相關(圖3).該位殘基被認為是標志鏈,主要功能是被T細胞表面抗原受體(T cell receptor,TCR)識別.33頻次統計顯示該位可出現7種殘基,其中Pro、Gly、Glu三種殘基合計頻率超過87%(圖4),與宋哲等33認為4位的Gly對親和活性貢獻最大以及Kirksey等34認為4位Glu能有效提高親和活性并易于被T細胞識別的觀點吻合.
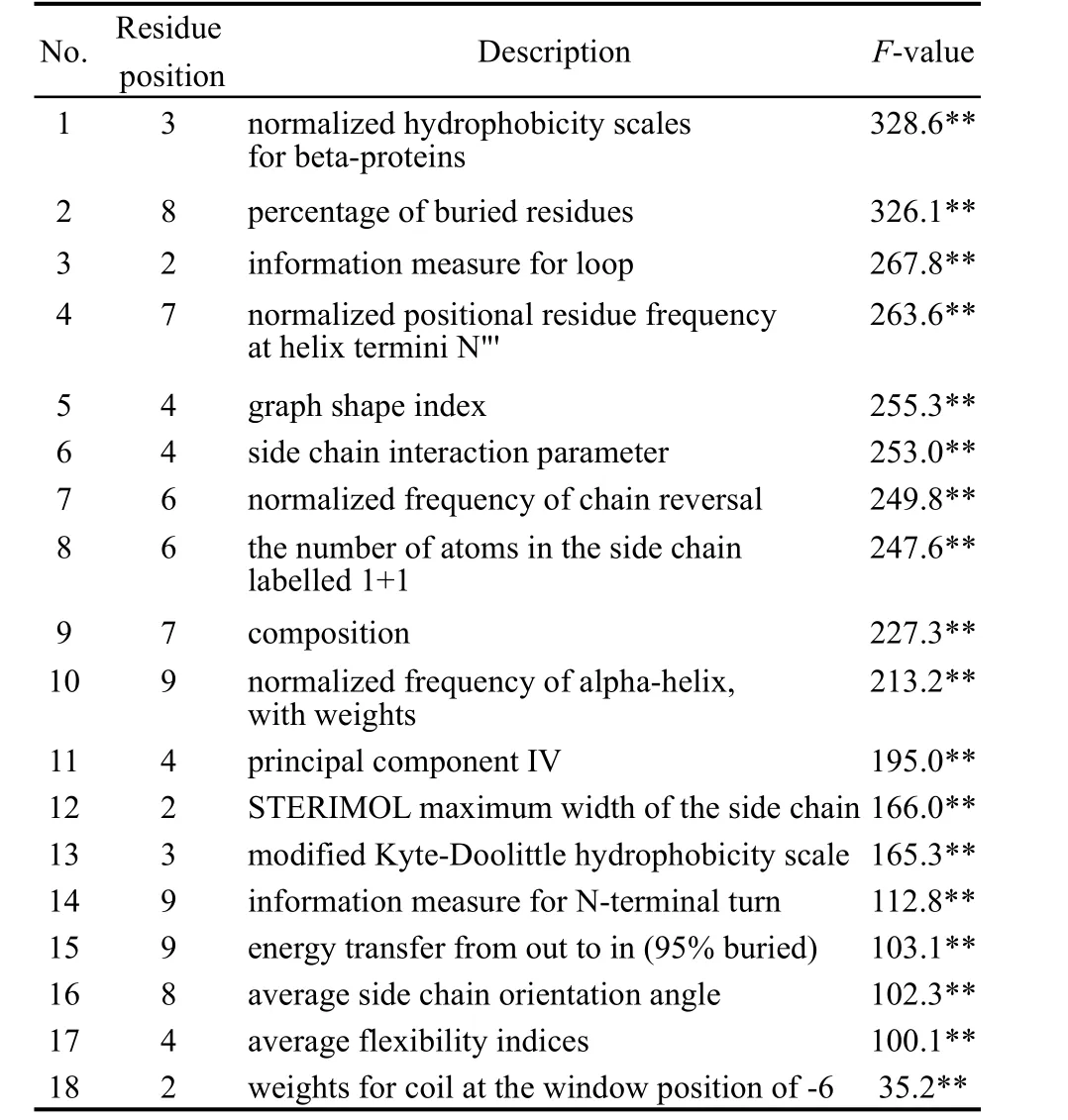
表3 QSAM模型中CTL表位的保留描述子Table 3 Reserved descriptors of CTLepitopes in QSAM model
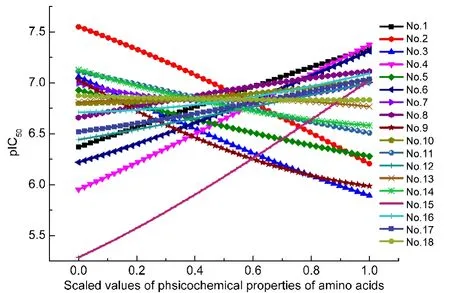
圖3 CTL表位18個保留描述子單因子效應x?y折線圖Fig.3 x?y line chart of the single-factor effects for 18 selected descriptors of CTLepitopes
Position 6(P6):多肽親和性與該位殘基的反轉鏈標準頻率、35側鏈1+1標記位原子數36關聯較大(表3),且與前者呈開口向上拋物線變化,與后者正相關(圖3).頻次統計顯示該位可出現除Ala外的19種殘基且較為分散(圖4).綜合判斷,該位殘基對活性影響較弱.
Position 7(P7):多肽親和性與該位殘基的螺旋N"'端殘基標準化頻率、37側鏈原子組成38關聯較大(表3),且與前者正相關明顯,與后者負相關明顯(圖3).頻次統計顯示,該位殘基為 Pro、Met、Phe、Tyr、Ala可提高親和活性(圖4),與宋哲等33認為7位的Thr、Pro、Phe對親和活性貢獻較大,Doytchinova等11認為7位易接受Ala、Val、Pro的觀點接近.
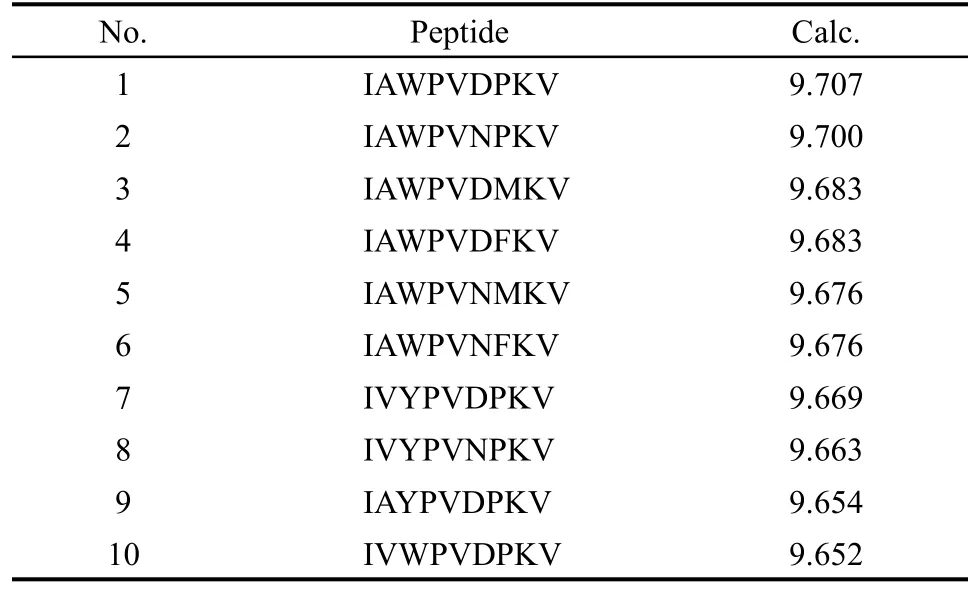
表4 預測活性值(pIC50)最高的10條多肽序列Table 4 Ten sequences with the highest predicted values(pIC50)of binding affinity
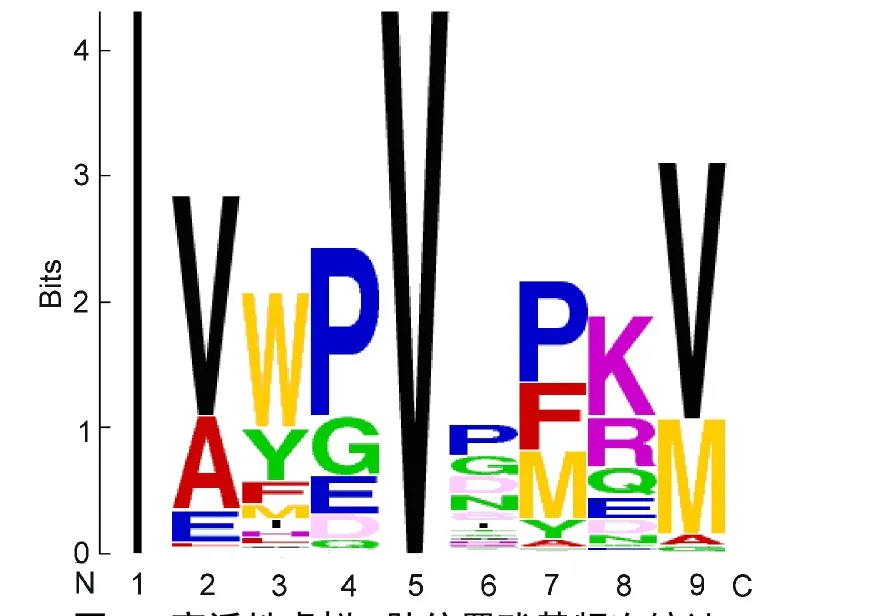
圖4 高活性虛擬9肽位置殘基頻次統計Fig.4 Frequency statistic of amino acids at each position among the high-activity virtual 9 peptide
Position 8(P8):多肽親和性與該位殘基的隱蔽殘基百分比、39平均側鏈存在角度40關聯較大(表3),且與前者呈負相關,與后者呈正相關(圖3),頻次統計顯示該位殘基為Lys、Arg、Gln、Glu可提高親和活性(圖4).P8位殘基與P4位殘基同被認為是標志鏈.33
Position 9(P9):多肽親和性與該位殘基的α螺旋標準加權頻率、4195%自由能自外向內轉移參數、42N-末端轉角信息測度24有較大關聯(表3),且與前兩者正相關明顯,與后者呈負相關(圖3).該位殘基一般認為也是“錨點”.11頻次統計顯示該位殘基為Val、Met、Gly、Ala、Leu等5種殘基可提高親和活性(圖4),與宋哲等33認為9位的Val、Met對親和活性貢獻最大,Doytchinova等11認為9位易于容納Ala、Val的觀點較一致,支持P9位為關鍵殘基位點的現有認知.
3.5 模型局限性
本文所建QSAM模型仍存在進一步改進之處.一是150條實測多肽很難代表209條9肽所產生的多種結構狀態.由于不少相似序列結構基本相同,簡單地增加實測多肽條數不僅耗時費力,也并不足以能完全解決這一問題.對類似9因素20水平這樣復雜的多因素多水平實驗設計與優化問題,本實驗室曾發展了基于均勻設計(UD)與SVR的實驗設計與分析新方法UD-SVR,并在多個動物營養、微生物發酵配方優化中得到成功應用.43?45因此,首先采用系列UD設計獲得樣本容量依次倍增的虛擬9肽集n1、n2、…、nj,模建每一條9肽構象,計數每一9肽集中結構狀態數s1、s2、…、sj,對n?s作圖,可大致估計s趨近飽和(si)時的最小虛擬9肽集ni(si<ni),從ni中挑出約si條結構狀態非冗余的9肽序列,真實合成并實測其親和活性,構建初始數據集,可能是解決這一問題的有效途徑.二是本文僅基于序列的分子描述符而未涉及更為重要的基于結構的分子描述符.雖然T細胞表位是線性表位,46但B細胞表位主要為構象表位,47絕大多數的多肽活性與空間構象有關,基于序列的模型應用受限,基于結構的方法理論上更直觀、更準確.48?51基于結構分子描述符,經高維特征非線性篩選建立更普適的高精度多肽QSAR模型是未來進一步研究的方向.
4 結論
將氨基酸指數數據庫中的531個物理化學性質直接表征表位肽序列,經非線性特征篩選后建立SVR模型,獲得了保留特征較少、預測精度較高的QSAM模型;通過對全組合虛擬9肽的預測,得到了多條預測親和活性高于已知表位肽的9肽,可供實驗驗證;結合非線性解釋性體系與高活性虛擬肽頻次統計分析,進一步較全面闡明了特定位置殘基對多肽親和性的影響規律,為高活性多肽疫苗分子設計提供了切實指導.
致謝: 美國克萊姆森大學羅峰博士修改、潤色英文摘要,謹致謝忱.
(1) Zhu,B.;Lin,Z.H.;Chen,Z.T.;Wu,Y.T.Immunological Journal 2005,21(3),177. [朱 波,林治華,陳正堂,吳玉堂.免疫學雜志,2005,21(3),177.]
(2) Zhou,P.;Li,Z.L.;Tian,F.F.;Zhang,M.J.Chin.Sci.Bull.2006,51(11),1259.[周 鵬,李志良,田菲菲,張夢軍.科學通報,2006,51(11),1259.]
(3) Charkraborty,K.;Mehrotra,K.;Mohan,C.;Ranka,S.Neural Networks 1992,5(6),961.doi:10.1016/S0893-6080(05)80092-9
(4) Vapnik,V.The Nature of Statistical Learning Theory,2nd ed.;Springer:New York,1995;pp 5?78.
(5)Wang,H.W.;Wu,Z.B.;Meng,J.Partial Least-Squares Regression-Linear and Nonlinear Methods,1st ed.;National Defence Industry Press:Beijing,2006;pp 34?54.[王惠文,吳載斌,孟 潔.偏最小二乘回歸的線性與非線性方法.北京:國防工業出版社,2006:34?54.]
(6) Yuan,Z.M.;Tan,X.S.Acta Agronomica Sinica 2010,36(7),1176.
(7) Hellberg,S.;Sj?str?m,M.;Skagerberg,B.;Wold,S.J.Med.Chem.1987,30(7),1126.doi:10.1021/jm00390a003
(8) Hellberg,S.;Eriksson,L.;Jonsson,J.;Lindgren,F.;Sj?str?m,M.;Skagerberg,B.;Wold,S.;Andrews,P.Int.J.Pept.Protein Res.1991,37(5),414.
(9) Elizabeth,R.C.;William,J.I.J.Med.Chem.1995,38(14),2705.doi:10.1021/jm00014a022
(10) Golub,T.R.;Slonim,D.K.;Tamayo,P.;Huard,C.;Gaasenbeek,M.;Mesirov,J.P.;Coller,H.;Loh,M.L.;Downing,J.R.;Caligiuri,M.A.;Bloomfield,C.D.;Lander,E.S.Science 1999,286(5439),531.doi:10.1126/science.286.5439.531
(11) Doytchinova,I.A.;Darren,R.F.J.Med.Chem.2001,44(22),3572.doi:10.1021/jm010021j
(12) Zhou,W.;Dai,Z.J.;Chen,Y.;Wang,H.Y.;Yuan,Z.M.Int.J.Mol.Sci.2012,13(1),1161.
(13)Zhang,H.Y.;Wang,H.Y.;Dai,Z.J.;Chen,M.S.;Yuan,Z.M.BMC Bioinformatics 2012,13(1),298.doi:10.1186/1471-2105-13-298
(14)Tan,X.S.;Wang,Z.M.;Tan,S.Q.;Yuan,Z.M.;Xiong,X.Y.Journal of System Simulation 2009,21(24),7795. [譚顯勝,王志明,譚泗橋,袁哲明,熊興耀.系統仿真學報,2009,21(24),7795.]
(15) Chang,C.C.;Lin,C.J.ACM TIST 2011,2(3),1.
(16)Yang,S.B.;Xia,Z.N.;Shu,M.;Mei,H.;Lü,F.L.;Zhang,M.;Wu,Y.Q.;Li,Z.L.Chem.J.Chin.Univ.2008,29(11),2213.[楊善彬,夏之寧,舒 茂,梅 虎,呂鳳林,張 梅,吳玉乾,李志良.高等學校化學學報,2008,29(11),2213.]
(17) Liang,G.Z.;Mao,S.;Li,S.S.J.Chin.Chem.Soc.2008,55(5),1178.
(18)Tropsha,A.;Paola,G.;Gombar,V.K.QSAR Comb.Sci.2003,22(1),69.
(19) Mei,H.;Zhou,Y.;Liao,Z.H.;Li,Z.L.Acta Chimica Sinica 2006,64(9),949.[梅 虎,周 原,廖志華,李志良.化學學報,2006,64(9),949.]
(20) Ren,Y.R.Computers and Applied Chemistry 2011,28(6),734.[任彥榮.計算機應用與化學,2011,28(6),734.]
(21) Chen,T.The Application of 3D Amino Acids Descriptors to the Quantitative Structure?Activity Relationship Study of Peptides.Ph.D.Dissertation,Shanxi University,Shanxi,2011.[陳 婷.三維氨基酸描述子在肽類定量構效關系研究中的應用[D].山西:山西大學,2011.]
(22) Liang,G.Z.Construction of Representation Techniques and Investigation on Structure?Activity Relationship for Biological Sequences.Ph.D.Dissertation,Chongqing University,Chongqing,2007.[梁桂兆.生物序列表征體系構建及結構與功能關系研究[D].重慶:重慶大學,2007.]
(23)Wang,Z.M.;Han,N.;Yuan,Z.M.;Wu,Z.H.Acta Phys.-Chim Sin.2013,29(3),498.[王志明,韓 娜,袁哲明,伍朝華.物理化學學報,2013,29(3),498.]doi:10.3866/PKU.WHXB201301042
(24) Robson,B.;Suzuki,E.Am.J.Mol.Biol.1976,107(3),327.
(25) Fauchère,J.L.U.C.;Charton,M.;Lemont,B.K.;Verloop,A.;Pliska,V.Int.J.Pept.Protein Res.1988,32(4),269.
(26) Qian,N.;Sejnowski,T.J.Mol.Biol.1988,202(4),865.doi:10.1016/0022-2836(88)90564-5
(27) Falk,K.;R?tzschke,O.;Stevanovié,S.;Jung,G.;Rammensee,H.G.Nature 1991,351(23),290.
(28) Hilda,C.;Marta,B.;Mauricio,C.;Felipe,G.Protein Eng.1992,5(5),373.doi:10.1093/protein/5.5.373
(29) Jureti?a,D.;Zuci?b,D.;Luc?i?c,B.;Trinajsti?c,N.Computers Chem.1998,22(4),279.doi:10.1016/S0097-8485(97)00070-3
(30) Sneath,P.H.A.J.Theoret.Biol.1966,12(2),157.doi:10.1016/0022-5193(66)90112-3
(31) Krigbaum,W.R.;Komoriya,A.BBA-Protein Struct.M.1979,576(1),204.doi:10.1016/0005-2795(79)90498-7
(32) Vihinen,M.;Torkkila,E.;Riikonen,P.Proteins:Structure,Function,and Genetics 1994,19(2),141.
(33) Song,Z.;Liu,T.;Liu,W.;Zhu,M.H.;Wang,X.G.Acta Phys.-Chim.Sin.2007,23(2),198.[宋 哲,劉 濤,劉 偉,朱鳴華,王曉鋼.物理化學學報,2007,23(2),198.]doi:10.1016/S1872-1508(07)60016-3
(34) Kirksey,T.J.;Pogue-Caley,R.R.;Frelinger,J.A.;Collins,E.J.J.Biol.Chem.1999,254(52),33726.
(35) Tanaka,S.;Scheraga,H.A.Macromolecules 1977,10(2),291.doi:10.1021/ma60056a015
(36) Charton,M.;Barbara,I.C.J.Theor.Biol.1983,102(1),121.doi:10.1016/0022-5193(83)90265-5
(37) Aurora,R.;Rose,G.D.Protein Sci.1998,7(1),21.
(38) Grantham,R.Science 1974,185(4154),862.doi:10.1126/science.185.4154.862
(39) Janin,J.;Chothia,C.Biochemistry 1978,17(15),2943.doi:10.1021/bi00608a001
(40) Meirovitch,H.;Scheraga,H.A.Macromolecules 1980,13(6),1406.doi:10.1021/ma60078a014
(41) Levitt,M.Biochemistry 1978,17(20),4277.doi:10.1021/bi00613a026
(42) Radzicka,A.;Wolfenden,R.Biochemistry 1988,27(5),1664.doi:10.1021/bi00405a042
(43)Yuan,Z.M.;Zuo,B.;Tan,S.Q.;Tan,X.S.;Xiong,X.Y.Chin.J.Process Eng.2009,9(1),148.[袁哲明,左 斌,譚泗橋,譚顯勝,熊興耀.過程工程學報,2009,9(1),148.]
(44) Li,J.;Tan,X.S.;Tan,S.Q.;Yuan,Z.M.;Xiong,X.Y.Acta Entomologica Sinica 2010,53(4),420.[李 俊,譚顯勝,譚泗橋,袁哲明,熊興耀.昆蟲學報,2010,53(4),420.]
(45) Zhou,S.H.;Li,J.;Yao,R.X.;Zhang,X.;Yuan,Z.M.Acta Entomologica Sinica 2012,55(1),124.[周世豪,李 俊,姚潤賢,張 星,袁哲明.昆蟲學報,2012,55(1),124.]
(46)Yasser,E.L.M.;Dobbs,D.;Honavar,V.PLoS One 2008,3(9),e3268
(47) Zhang,W.;Xiong,Y.;Zhao,M.;Zou,H.;Ye,X.H.;Liu,J.BMC Bioinformatics 2011,12(1),341.doi:10.1186/1471-2105-12-341
(48) Shen,M.Y.;Zhou,S.Y.;Li,Y.Y.;Pan,P.C.;Zhang,L.L.;Hou,T.J.Mol.Biosys 2013,9(3),361.doi:10.1039/c2mb25408e
(49) Hou,T.J.;Li,N.;Li,Y.Y.;Wang,W.J.Proteome Res.2012,11(5),2982.doi:10.1021/pr3000688
(50) Zhang,C.Q.;Hou,T.J.;Li,Y.Y.Curr.Comput.-Aided Drug Des.2013,9(1),60.
(51)Yan,Y.;Li,Y.;Zhang,S.;Ai,C.J.Mol.Graph.Model.2011,29(5),747.doi:10.1016/j.jmgm.2010.12.008
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
