基于X86 平臺的ARM 指令集模擬器的設計
2013-10-21 00:54:06賈少波
電子設計工程 2013年12期
賈少波
(西安財經(jīng)學院 信息與教育技術中心,陜西 西安 710061)
如今,仿真技術和虛擬技術被廣泛應用各個領域,特別在嵌入式系統(tǒng)的開發(fā)過程中,由于在不同應用領域中,嵌入式開發(fā)要求的硬件體系差別很大,用軟件進行系統(tǒng)仿真或虛擬硬件非常必要。軟件仿真的重點是微控制器的仿真,而對微控制器的仿真重點又在指令仿真上,因此本文給出一種基于解釋型仿真策略的指令仿真器的實現(xiàn)。指令集仿真器(Instruction Set Simulator,ISS)是用來在宿主機仿真另一種目標機上程序運行過程的軟件工具。它通過仿真每條指令在目標處理器上的執(zhí)行效果來仿真目標機程序,是目標處理器的軟件仿真器。在嵌入式軟硬件的并行開發(fā)中,指令仿真器是必不可少的工具之一,在目標機可用之前,通過它就可以完成軟件的仿真調(diào)試,真正做到了軟硬件的并行開發(fā)。
1 ARM 體系架構及指令集模擬技術
1.1 ARM 體系架構
到目前為止,ARM 微處理器以其體積小、低功耗、低成本、高性能、指令執(zhí)行速度快、尋址方式靈活簡單、執(zhí)行效率高、指令長度固定等優(yōu)點幾乎已經(jīng)深入到各個領域。ARM處理器實現(xiàn)加載/存儲(load/store)體系結構,是典型的RISC處理器。只有加載和存儲指令可以訪問存儲器。數(shù)據(jù)處理指令支隊寄存器的內(nèi)容進行操作,傳統(tǒng)的CISC(Complex Instruction Set Computer,復雜指令集計算機)技術的指令集隨著計算機的發(fā)展引入了各種各樣的復雜指令,已經(jīng)不堪重負。圖1 描述了ARM 微處理器的體系架構。
1.2 指令集模擬技術
1.2.1 指令集模擬解釋型模擬技術
解釋型模擬器的模擬流程是參照硬件環(huán)境中的指令執(zhí)行,并不進行任何執(zhí)行信息的服用,故執(zhí)行起來性能不高,愛目前主流配置的主機上的運行性能能一般從幾十到幾百個KIPS(Kilo-Instructions Per-Second)。由于解釋型模擬器實現(xiàn)較為簡單,同時能夠提供足夠的模擬精度以及靈活性,但解釋型模擬器的模擬性能低下,故在對于模擬性能沒有特別高的要求下,采用這種模擬技術是非常優(yōu)越的。目前絕大部分商用的模擬器是解釋型模擬器。這類模擬器的典型代表是Simple Scalar。
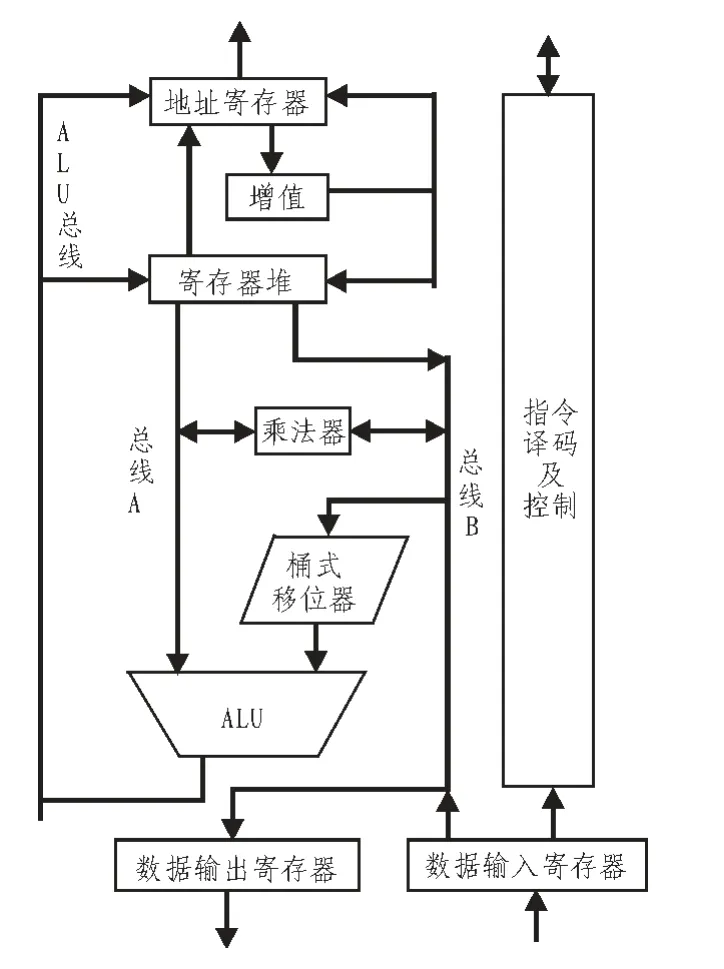
圖1 ARM 微處理器體系架構圖Fig.1 ARM microprocessor architecture diagram
1.2.2 指令集模擬器動態(tài)翻譯模擬技術
動態(tài)翻譯模擬是在解釋型模擬技術基礎上的一種優(yōu)化,由于使用了緩存技術盡可能大的復用已解析的信息,提高了模擬的效率。模擬器的工作流程是:模擬一條指令,先核對這條指令是否存在于緩沖頁,如果是,則調(diào)用存儲中已有的解碼結果,實現(xiàn)模擬;如果沒有,則翻譯該指令并將結果緩存頁中備用,同時按照解釋型模擬的模式,繼續(xù)進行。由于啟動模擬編譯器的系統(tǒng)開銷較大,為了提高性能,每次啟動模擬編譯器完成若干條指令的翻譯,為了處理方便,每次編譯的指令數(shù)是固定的,稱為一個“翻譯頁”。在動態(tài)翻譯模擬技術中,翻譯和模擬的過程耦合度較低,可以分配給不同的線程完成,或結合多核技術,將代碼的執(zhí)行工作分配給幾個CPU 同時來執(zhí)行,來提高模擬速度。目前采用動態(tài)翻譯技術的應用的較好的模擬器有Intel IA-32 Execution Layer 等[1]。
2 ARM 指令集模擬器的設計
2.1 ARM 指令集模擬器系統(tǒng)總體框架設計
本模擬器的主要功能是模擬ARM 處理器對指令集的處理能力,當把內(nèi)容為ARM 指令的二進制BIN 文件輸入時,可以模擬在真實ARM 處理器上的運行效果。由圖2 指令集模擬器的總體架構圖可以看出一個應用程序在運行的時候和指令集模擬器之間的關系。一個應用程序在經(jīng)過ARM 交叉編譯器編譯生成基于ARM 指令集的二進制可執(zhí)行文件,可執(zhí)行文件進入ARM 指令集模擬器內(nèi)核被解釋執(zhí)行,最后得到運行后的結果。
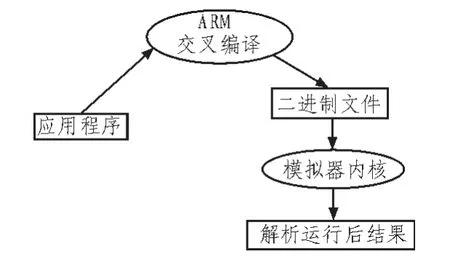
圖2 指令集模擬器總體架構圖Fig.2 Architecture instruction set simulator
其中模擬器內(nèi)核是整個模擬器的核心部分,也是本文將要重點設計和實現(xiàn)的部分。它主要包含一下功能:對可執(zhí)行文件的加載,執(zhí)行取指令、指令譯碼、指令模擬執(zhí)行的三級流水和解析結果的展示。在模擬器內(nèi)核設計部分,模擬指令執(zhí)行的過程是內(nèi)核的核心部分,在本模擬器設計中,借鑒CPU模型中的指令流水設計內(nèi)核翻譯程序的取指、譯碼和指令執(zhí)行3個過程。圖3 描述了指令集模擬器內(nèi)核的總體架構。如圖所示,整個內(nèi)核包含程序加載模塊、指令譯碼模塊、取指模塊、指令調(diào)度與模擬模塊、寄存器模擬模塊和數(shù)據(jù)存儲模塊。在此模擬器中,存儲模塊不做實現(xiàn),調(diào)用gdb 中的相應模塊[2-3]。
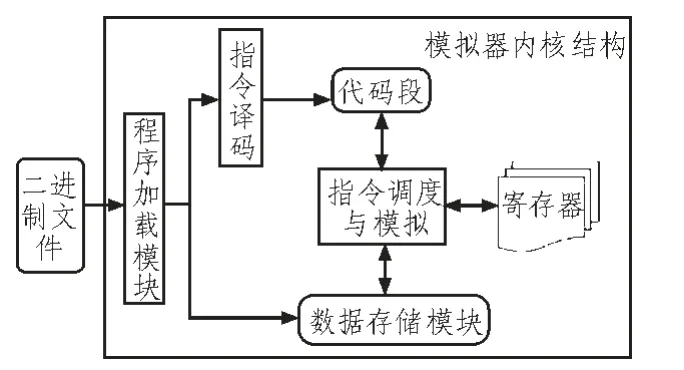
圖3 指令集模擬器內(nèi)核總體架構圖Fig.3 Instruction set simulator kernel architecture diagram
2.2 ARM 指令集模擬器的流程設計
本模擬器是按照解釋型模擬器的模擬策略設計的。解釋型指令集模擬器基本上是以軟件實現(xiàn)的虛擬機,它以解釋的形式在宿主機上執(zhí)行加載的目標代碼,它的主體是一個具有3 步過程的循環(huán)體,分別對應取指令、指令譯碼、指令執(zhí)行3步操作。因此本ARM 指令集模擬器的核心流程就是加載程序,之后進入讀取指令、指令譯碼和指令執(zhí)行的循環(huán)體中,當所有目標代碼都執(zhí)行之后結束并顯示運行結果。整個流程如圖4 指令模擬器的工作流程所示。
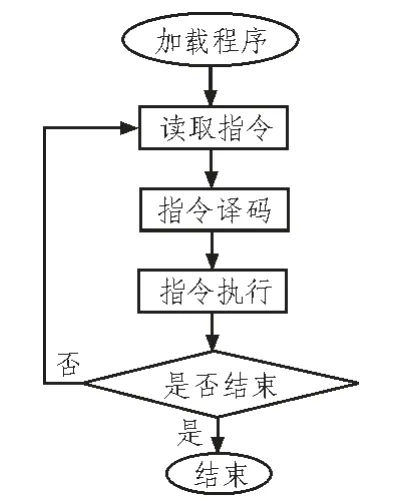
圖4 指令集模擬器工作流程圖Fig.4 Instruction set simulators work flow chart
2.3 ARM 指令集模擬器的主要功能模塊設計
2.3.1 指令譯碼模塊
指令譯碼模塊的功能就是根據(jù)ARM 指令集編碼,將要執(zhí)行的二進制指令譯碼成操作碼、操作數(shù)、條件碼等指令模擬需要的信息。指令集模擬器的每一模擬步模擬一條指令的取指令、譯碼、執(zhí)行等各個階段,因此指令集模擬器中的指令譯碼與實際ARM 處理器的譯碼并不是完全對應,同時也不會影響模擬的正確性。
在指令譯碼模塊中,本文采用分類的思想,將指令集按照一定的規(guī)律進行分類解析,逐步解析,找到最終指令所對應的解析函數(shù)。這樣做的目的是為了減少判斷指令時的條件判斷次數(shù),采用分治的思想提高指令譯碼的效率[2]。不過要想對指令譯碼效率有顯著性的提高,還是要采用改進型的工作流程,主要原因是在指令譯碼的過程中,會出現(xiàn)大量的重復譯碼,所以改進型的工作流程中提出的指令緩存技術會很好的提高譯碼效率,減少重復的譯碼工作[4]。
2.3.2 指令模擬與調(diào)度模塊
指令模擬與調(diào)度功能模塊是指令集模擬器的核心部分,也是實現(xiàn)代碼量最大的部分,主要包括與虛擬指令集定義對應的一系列指令模擬函數(shù)、指令執(zhí)行控制函數(shù)、指令翻譯調(diào)度函數(shù)、中斷處理函數(shù)以及一些公用函數(shù)。指令執(zhí)行控制函數(shù)負責控制整個模擬過程,反匯編結果文件加載完畢后,程序就進入核心部分的模擬循環(huán);指令翻譯調(diào)度函數(shù)負責將目標指令轉(zhuǎn)化為虛擬指令形式,然后指令模擬函數(shù)按照相應指令的功能定義完成指令的模擬,模擬結果是修改存儲器、寄存器值;公用函數(shù)主要包括尋址方式判別、指令操作數(shù)分析、指令條件碼判別、移位操作、ALU 操作以及寄存器訪問等。
指令模擬與調(diào)度的循環(huán)過程如下:
1)取指令
該模擬器的輸入是二進制可執(zhí)行文件,因此取指令時,根據(jù)PC 值取得的當前的指令,進行譯碼。
2)翻譯
調(diào)用指令翻譯函數(shù)獲得虛擬指令。
3)調(diào)度
根據(jù)指令類型,調(diào)用相應的指令模擬函數(shù)。
4)執(zhí)行
指令模擬函數(shù)對指令進行模擬。
5)中斷檢測與調(diào)度
為了對中斷系統(tǒng)進行模擬,本文定義了對應于FIQ、IRQ 的標志變量,可以改變他們來模擬外部中斷輸入,每條指令模擬結束后,必須檢測上述兩個標志,如果檢測到中斷發(fā)生,則調(diào)用相應的異常進入函數(shù),PC 被設定為中斷服務程序入口地址。
6)更新PC 值
如果本次循環(huán)沒有發(fā)生指令跳轉(zhuǎn)、加載PC 及中斷,PC 順序移向下一條指令。
2.4 ARM 指令集模擬器的內(nèi)核設計
模擬器內(nèi)核結構如圖5 所示。
2.4.1 內(nèi)核解碼模塊設計
指令模擬器內(nèi)核中的解碼模塊包括取指令模型和指令轉(zhuǎn)換模型兩部分內(nèi)容,取指令模型介紹了內(nèi)核程序如何從加載的目標代碼中取出逐條指令,指令轉(zhuǎn)換模型介紹了取出的逐條指令是如何轉(zhuǎn)換成中間語言指令來實現(xiàn)的。
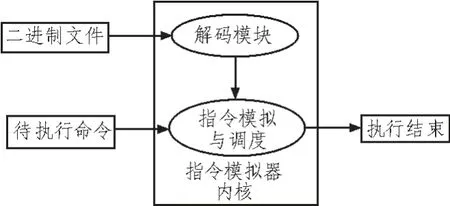
圖5 模擬器內(nèi)核結構圖Fig.5 Simulator kernel structure
1)取指令模型
本文設計的模擬器中取指令模型結構如圖6 所示,包括指令計數(shù)器、指令格式解析器、指令格式解析器、取指令邏輯控制器和指令地址更新邏輯。指令計數(shù)器是處理器都會有的一個寄存器。不同的處理器有不同的表現(xiàn)形式。
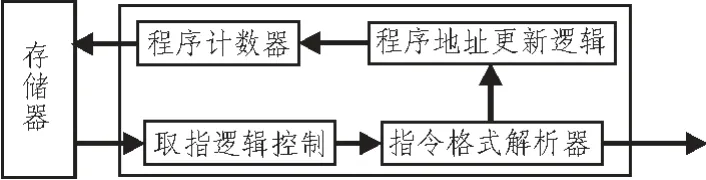
圖6 取指令模型圖Fig.6 Fetch model diagram
2)指令的轉(zhuǎn)換模型
指令譯碼就是根據(jù)ARM 指令集編碼,將要執(zhí)行的指令譯成操作碼、操作數(shù)、條件碼等指令仿真需要的信息。譯碼的重點在于獲取不同尋址方式下的操作數(shù),通過分析指令字助記符和指令碼,可以很方便地得到不同尋址方式的操作數(shù)[3]。由于本文設計的指令集虛擬模擬ARM 的指令集,所以加入指令轉(zhuǎn)換模型,指令轉(zhuǎn)換是將一條目標機器指令轉(zhuǎn)換為一條或幾條中間可執(zhí)行指令集的過程。轉(zhuǎn)換工作由指令轉(zhuǎn)換器完成。其工作模型如圖7 所示,一條源指令經(jīng)過指令譯碼模塊翻譯,生成一系列的中間語言隊列,在本模擬器中,中間語言就是能在X86 平臺上運行的匯編語言。
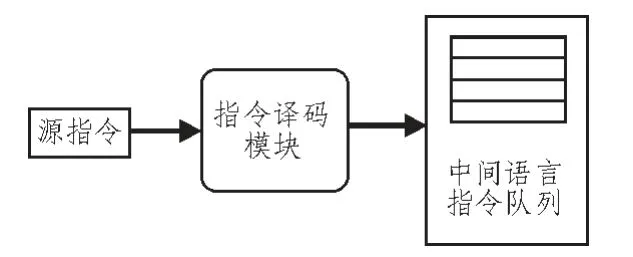
圖7 指令譯碼模型Fig.7 Instruction decoding model
2.4.2 內(nèi)核指令模擬與調(diào)度模塊
指令調(diào)度就是把指令字與完成相應操作的功能函數(shù)對應起來,使得仿真時取到該指令后能知道該調(diào)用哪個執(zhí)行過程。本文是基于傳統(tǒng)的解釋型仿真策略,其主體是一個大的switch 結構,并使用case 語句。這種設計模型會影響模擬速度,由于case 語句的種類非常多,所以在今后的工作中,這里將會是一個重點的研究對象,可以采用hash 結構、壓縮算法或者指令緩存來提高指令譯碼的執(zhí)行效率,這也將會是模擬器的整體執(zhí)行效率得到一個很大的提高。
指令模擬執(zhí)行模塊把指令分類處理并采用數(shù)據(jù)獲取和數(shù)據(jù)操作相分離的方法,使得執(zhí)行函數(shù)更具有通用性,當新的指令系統(tǒng)添加時,只需要添加相應的尋址方式和原系統(tǒng)中沒有的指令執(zhí)行過程,就能完成添加指令集的操作,提高了系統(tǒng)設計的可擴展性[5-6]。
3 結束語
本文是針對嵌入式開發(fā)現(xiàn)階段的主要存在的問題,即傳統(tǒng)低下的開發(fā)效率和當下對較短市場開發(fā)周期的要求之間的矛盾,提出了ARM 指令集模擬器的設計和實現(xiàn)方法。以及對指令集模擬技術的介紹和掌握。目前,與嵌入式系統(tǒng)相關的軟件開發(fā)復雜度越來越高,因此指令集模擬器的發(fā)展前景十分樂觀。
[1]張帆.ARM指令集仿真器的設計與實現(xiàn)[D].武漢:湖北工業(yè)大學,2008.
[2]LV Ming-song,DENG Qing-xu,GUAN Nan,et al.ARMISS:an instruction set simulator for the ARM architecture[D].Institute of Computer Software and Theory,Northeastrn University,2008.
[3]姜旭鋒.SmartSimular:基于虛擬指令集的嵌入式系統(tǒng)模擬器[D].杭州:浙江大學,2006.
[4]趙軍.通用指令集描述語言的設計和實現(xiàn)[D].杭州:浙江大學,2006.
[5]周立功.ARM嵌入式系統(tǒng)基礎教程[M].北京:北京航空航天大學出版社,2005.
[6]羅蕾.嵌入式實時操作系統(tǒng)及應用開發(fā)[M].北京:北京航空航天大學出版社,2005.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
藝術啟蒙(2018年7期)2018-08-23 09:14:18
鐵道通信信號(2018年2期)2018-04-18 12:18:23
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
電鍍與環(huán)保(2016年3期)2017-01-20 08:15:32
單片機與嵌入式系統(tǒng)應用(2014年9期)2014-03-11 15:35:13
自動化博覽(2014年4期)2014-02-28 22:31:15
