ASON網絡的路由方案設計及仿真
2013-11-05 06:43:18高書強李海濤
電子測試 2013年5期
高書強 李海濤
(鄭州大學信息工程學院,河南鄭州 450052)
1 仿真軟件的介紹
在此次仿真中,我們選用OPNET Modeler進行仿真。下面就對這個軟件做一些簡要的介紹。
1.1 概述
Modeler提供了一個協議開發和器件、網絡模型的開發環境,可以進行高效、準確的仿真。為網絡優化、降低成本、縮短投放市場的時間等提供了方便。我把Modeler開發分為三種:一是上層開發,利用內部已有模型搭建符合要求的網絡,通過配置外部屬性改變網絡特性,通過設置不同的統計量,了解網絡各個方面性能。二是底層開發,通過編程的方式,利用Modeler內部機制,開發出靈活性更強的模型。三是二者結合,既利用內部模型函數又自己編制程序,這可以省去很大的工作量,減短開發周期。
1.2 Modeler仿真的層次結構
Modeler仿真以project為單位,一般一個project完成一項仿真任務。而一個Project是一系列網絡實例(scenario)的集合,而每一個實例研究網絡設計的一個方面,如不同的scenario可能是采用的協議不同、統計方向不同、拓撲不同等等。一個Project 至少有一個scenario。
Modeler仿真,是一個分層構建的過程,從底往上,像蓋房子一 樣。Link、 packet、Ici,etc.—process—node—network。一個可以有一個或幾個network 。
2 ASON節點模塊的設計
在這里,由于ASON的節點主要由3個模塊來構成,所以主要由ASON的RC(路由模塊),CC(信令模塊)和LRM(鏈路資源管理)所構成。具體連接圖沿用ASON仿真組上一次的設計,在這里面要能夠提供業務發生器的部分,以在節點的外部接口可以直接設置業務的屬性,以便以后不同網絡狀況的的輸出比較。
這里lrm資源管理、自動資源發現、故障定位和恢復,CC分發信令來實現控制平面對傳送面的控制信息,他們和RC模塊構成了對ASON控制平面的作用的執行,而在仿真中由于要依賴IP網組建ASON的控制平面,信令和LSA要通過IP網絡傳輸,這里的ip_encap和ip模塊就是完成數據包的封裝和IP傳送功能,CPU的作用是主要是協調各個模塊,分配仿真資源。
2.1 仿真所用的拓撲介紹
為保證仿真的真實性,此次仿真所用的是NSFNET,共有16個節點,研究對象的粒度為波長極。下圖為NSFNET拓撲結構,這次仿真主要采用的是靜態拓撲輸入。
2.2 仿真統計如圖所示
仿真時間為1小時,計算歷時6分56秒,仿真事件9152462件,平均每秒21963件,仿真結束未發生錯誤。
仿真中的完成一次Flooding所傳送控制信息的平均開銷(AOF)如下圖:
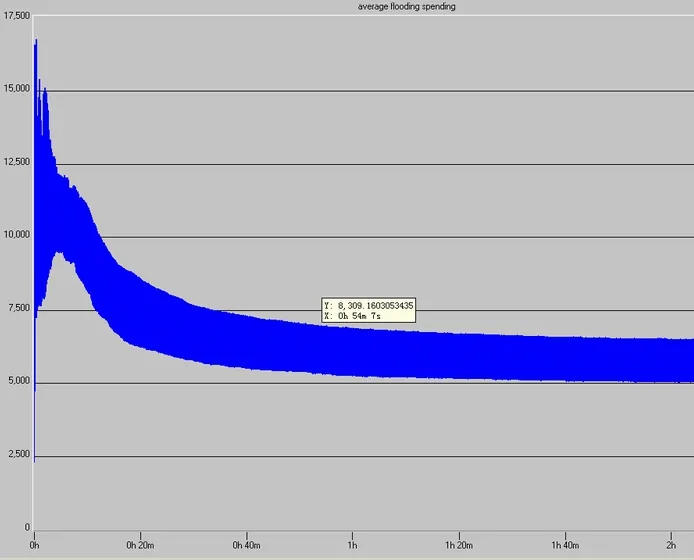
從上圖可以看出,在仿真開始的約10分鐘,flooding的開銷很大,每次 1Mbit,過后慢慢趨于平靜,約沒次平均5500bit,造成這種的原因應該是在仿真開始之初的一段時間里,各個節點的網絡狀況和初始化還沒有完全穩定下來,所以造成那在這段時間里由于網絡各節點之間的拓撲未同步,并且此時真正的業務還沒有完全建立起來,網絡中有大量的控制面的信息需要交互,這就造成了LSA的收發的成功率,于是節點RC就需要重復發送LSA以確保所有節點之間的鏈路狀態的同步,從而造成了此時的每次flooding的開銷比較大,一旦網絡狀況穩定下來以后,業務開始建立,此時的控制平面的改變較少,并僅僅在鏈路狀況改變的情況下才flooding其相應的LSA,控制平面需要的帶寬較少,比較不容易引起擁塞,從而flooding的開銷會比較穩定。
完成一次Flooding的平均時間(ATF)的顯示圖表如下:
為了比較方便,我們把flooding的平均時間設定為本地變量,這里我們將選取4個節點來輸出結果分析:
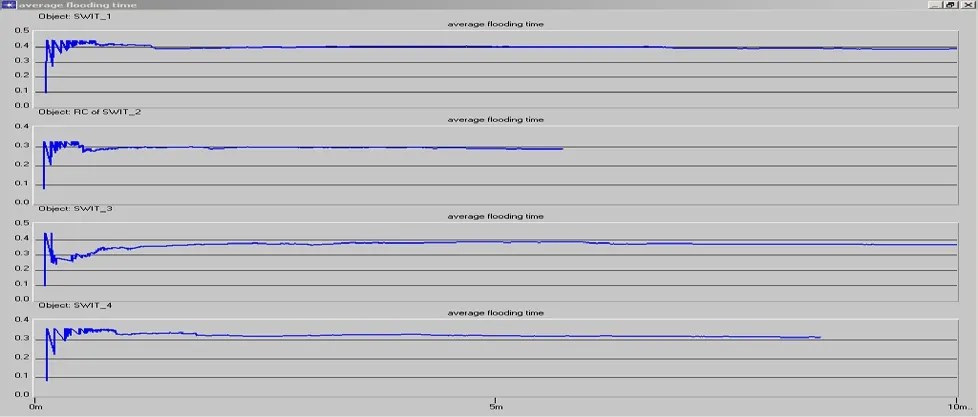
這里我們可以看出,由于在網絡中所處的位置不同,在結果中每次flooding所需要的時間也不盡相同,當還是大致的都在0.3秒到0.5秒之間的一個值收斂,這里也出現了在仿真開始之初的不穩定情況,和上面的關于flooding的開銷的分析相似,還有一點要注意的是在仿真中仿真的時間是1小時,但是在這里有些節點的存在flooding的時間卻只有10分鐘左右,這個原因有幾種可能:
1.前面已經講過,由于在ASON控制平面中,仿真的時間較短,可能在信令系統接收到業務的請求并建立業務以后,業務的持續時間比較長,就可能引起在業務建立以后的較長一段時間里沒有新的業務。
2.在此,由于RWA算法還未成功移植,在這里就表明鏈路的狀態沒有發生變化,所以就沒有LSA信息的分發。
3.程序故障,可能是RC,CC,LRM模塊之間的交流存在一些問題。
4.網絡資源的配置問題。
仿真時間也為1小時,計算歷時10分31秒,仿真事件6735658件,平均每秒10661件,仿真結束未發生錯誤。在這里,業務量大約是上次仿真的一半,其結果如下:
仿真中的完成一次Flooding所傳送控制信息的平均開銷(AOF)如下圖:
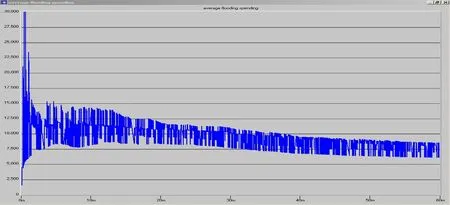
在比較中,我們可以看出,在業務量比較小的情況下,平均網絡收斂的時間變短,平均每次flooding的開銷也在7500bit/次。說明當網絡比較穩定的情況下,每次flooding的開銷大致相等。在業務量比較小的時候,鏈路的變化也比較少,平均每段時間內所產生的鏈路狀態改變也比較少,所以產生的LSA也相對較少。
完成一次Flooding的平均時間(ATF)的顯示圖表如下:
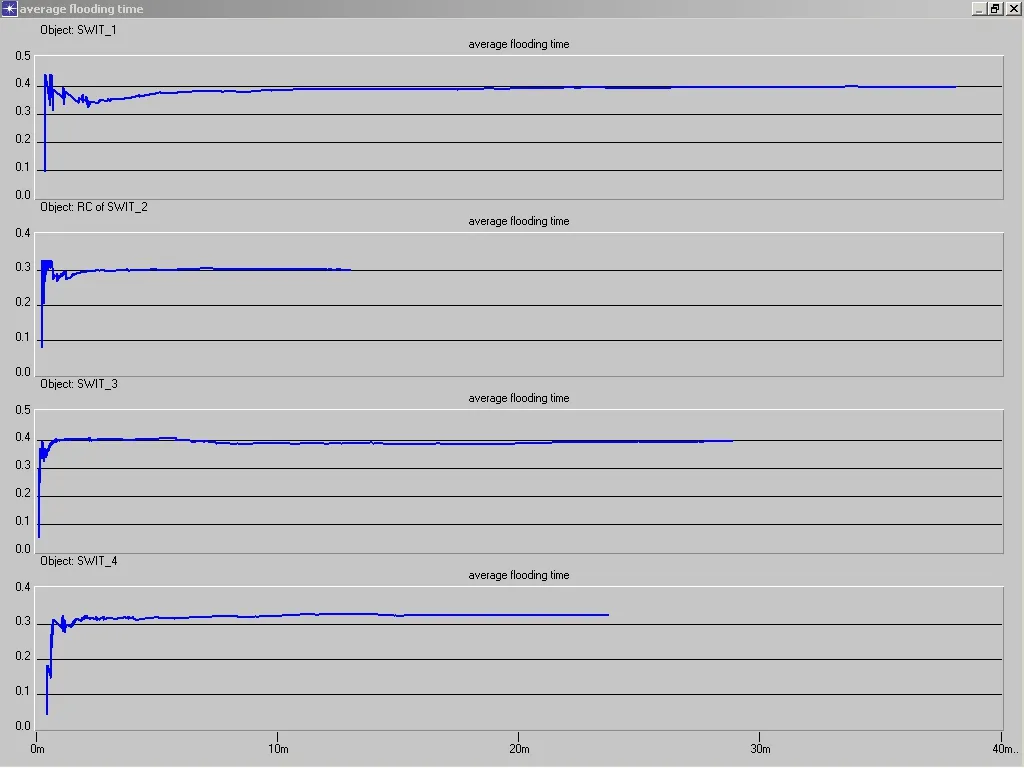
這次我們的設置中,每個節點發生的業務強度也不一樣,在圖中我們可以看出,業務量最大的節點3中,大概在10幾秒以后就不再有要flooding的廣播數據包產生,我們可以并且可以看出他flooding的時間要比別的節點好,說明它在網絡中的位置比較好,所屬鏈路的鏈路狀況比較好,這在也第一次的仿真結果比較中我們可以看出,平均每次flooding所需要的時間大致相當,這說明了基本上平均每次flooding所需要的時間是與控制平面的拓撲有關系。在這次的仿真結果中我們看得出,節點有鏈路狀態變化的時間雖然也沒有到完全仿真時間,但是比起是一次來說已經提高很多,并且業務量最大的節點三也是最先產生鏈路狀態無變化(這里的變化值得是相對的變化,比如說所用信道帶寬占總帶寬的權值),就是說明在上次分析的原因中,所講的第二中情況,即網絡的帶寬在業務發起的一段時間后會達到一個相對大的值,這個時候相對所占帶寬的權值就沒有變化,造成了一段時間后就沒有新的鏈路狀態相對變化。當然這里也不能完全排除其他的情況,所以還是需要進一步的比較分析,說明。并且在不同的業務發生強度,業務持續時間,業務量的情況下做相應的比較分析。
此次仿真還未解決的問題:
1.在仿真中對于過期的LSA確認(所需確認的LSA鏈路狀態已經重新改變,所屬sequence number也已經更新),在本次的仿真中所做的處理是直接釋放,這些信息還是否需要保存仍然需要繼續研究。
2.在本次中,所用的路由算法應采用RWA算法,但是由于項目組的原因并未實現,仍然沿用老的鏈路權值計算方法。
3.在于CC的交流中,CC模塊也是所用的老的模塊,新的資源預留的模塊還未完成,沒有辦法比較在資源預留情況下所用算法的優劣。由于采用的老的算法在給CC顯式路由時以查算好路由表的方法,在OPNET仿真中,其返回時間約為0,所以沒法統計平均的路由計算時間。
[1] B. Wu, A.D. Kshemkalyani. Objective-optimal algorithms for long-term Web prefetching. IEEE Transactions on Computers, 2006, 55(1):2-17
[2] X. Chen, X. Zhang. A popularity-based prediction model for Web prefetching. Computer. 2003,36(3):63-70
[3] Lei Shi, Yingjie Han, Xiaoguang Ding, Lin Wei,Zhimin Gu, An SPN based Integrated Model for Web Prefetching and Caching, Journal of Computer Science and Technology, 2006, 21(4): 482-489
