文本分類中基于綜合度量的特征選擇方法
2013-12-03 03:19:12楊杰明劉元寧曲朝陽(yáng)劉志穎
吉林大學(xué)學(xué)報(bào)(理學(xué)版) 2013年5期
楊杰明,劉元寧,曲朝陽(yáng),劉志穎
(1.東北電力大學(xué) 信息工程學(xué)院,吉林 吉林 132012;2.吉林大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,長(zhǎng)春 130012)
隨著IT應(yīng)用的不斷增長(zhǎng),人工管理文本數(shù)字信息已成為一項(xiàng)不可能完成的任務(wù).自動(dòng)文本分類技術(shù)是處理海量文本信息的有效方法,近年來(lái)已在許多領(lǐng)域得到廣泛應(yīng)用.目前,已有很多成熟算法應(yīng)用于文本分類中,如Bayes分類器、支持向量機(jī)、決策樹(shù)、K-近鄰方法等.然而,文本分類中最大的特點(diǎn)是高維性,即使是一個(gè)并不太大的語(yǔ)料集,它的維度也能達(dá)到上萬(wàn)維甚至十幾萬(wàn)維.在機(jī)器學(xué)習(xí)過(guò)程中,高維度會(huì)帶來(lái)兩方面的問(wèn)題:1) 在高維環(huán)境中,大部分成熟算法不能得到高效的應(yīng)用;2) 在高維環(huán)境中訓(xùn)練分類器時(shí),不可避免地會(huì)產(chǎn)生過(guò)擬合現(xiàn)象[1].因此,降維成為文本分類中的一個(gè)重要研究方向.目前,降維主要有兩種實(shí)現(xiàn)方式,即特征選擇和特征提取.特征提取是在原有特征的基礎(chǔ)上,通過(guò)組合、轉(zhuǎn)換生成一組全新特征集合的技術(shù),如特征項(xiàng)聚類、隱含語(yǔ)義索引[2]和獨(dú)立分量分析[3]等.特征提取方式能捕獲特征間的語(yǔ)義關(guān)系,但表示文本的特征不易理解、計(jì)算成本較高.特征選擇算法是根據(jù)某種特征度量函數(shù),衡量一個(gè)特征在分類中所起作用的重要度,并按重要度排序,然后根據(jù)排序結(jié)果從原有的特征集合中選擇重要度最高的少數(shù)特征組成一個(gè)特征子集,最終實(shí)現(xiàn)文本的表示和分類器的訓(xùn)練.特征選擇算法運(yùn)算效率高、實(shí)現(xiàn)方便快捷,是當(dāng)前文本分類中最常使用的降維方法[4-5].目前已有很多特征選擇方法應(yīng)用在文本分類的降維過(guò)程中,如文檔頻率(DF)、信息增益(IG)、卡方檢驗(yàn)(CHI)[6-7]、正交質(zhì)心(OCFS)[8]和特征質(zhì)心(FCFS)特征選擇算法[9]等.
本文提出一種新的特征選擇算法,該算法從兩方面綜合度量一個(gè)特征對(duì)于分類的重要性,并在20-Newgroups,Reuters和WebKB這3個(gè)數(shù)據(jù)集上與文檔頻率、信息增益、卡方檢驗(yàn)、正交質(zhì)心和FCFS特征選擇算法進(jìn)行了對(duì)比.實(shí)驗(yàn)結(jié)果表明,該算法能有效提高文本分類性能.
1 問(wèn)題描述及相關(guān)技術(shù)
1.1 問(wèn)題描述
預(yù)先給定一個(gè)整數(shù)K,在盡可能保證文本分類性能不受影響的前提下,特征選擇算法從原始的特征集合T中選擇一個(gè)子集T′(|T′|?|T|).Yang等[6]指出最佳的特征選擇算法和合適的特征子集數(shù)量不但不損害分類器的性能,反而能提高分類效果.目前,應(yīng)用在文本分類中的特征選擇方法可分為3類,即嵌入式特征選擇(embed)、融合式特征選擇(wrapper)和過(guò)濾式特征選擇(filtering).嵌入式的特征選擇方法是將特征選擇的過(guò)程直接嵌入到分類器的學(xué)習(xí)過(guò)程中,而融合特征選擇方法是利用某個(gè)分類器學(xué)習(xí)算法作為特征的評(píng)價(jià)標(biāo)準(zhǔn)去選擇特征子集,再利用該特征子集訓(xùn)練分類器.過(guò)濾式特征選擇方法先利用一個(gè)獨(dú)立的評(píng)價(jià)函數(shù)去度量一個(gè)特征對(duì)分類的重要程度,然后根據(jù)度量值對(duì)所有的特征進(jìn)行排序,最后選擇K個(gè)度量值最高的特征構(gòu)成特征子集.由于易于操作、計(jì)算成本低、分類效果好等特點(diǎn),因此過(guò)濾式特征選擇方法應(yīng)用廣泛.本文提出的算法也是過(guò)濾式特征選擇方法.
1.2 相關(guān)技術(shù)
1.2.1 文檔頻率 文檔頻率是一個(gè)簡(jiǎn)單而有效的特征選擇算法,它計(jì)算包含某個(gè)特征的文檔數(shù)量.主要思想是如果一個(gè)特征出現(xiàn)在很少的文本中,則該特征對(duì)分類沒(méi)有用,甚至可能降低分類性能,所以該特征選擇算法保留那些具有高文檔頻率的特征.該算法可表示為
DF(tk,ci)=P(tk|ci).
1.2.2 信息增益 信息增益是機(jī)器學(xué)習(xí)領(lǐng)域常用的算法.如果一個(gè)特征的信息增益值越大,則表明該特征對(duì)分類越有用.特征tk相對(duì)于類別ci的信息增益可表示為
1.2.3 卡方檢驗(yàn) 卡方檢驗(yàn)是數(shù)理統(tǒng)計(jì)學(xué)中用于度量?jī)蓚€(gè)變量獨(dú)立性的方法.在文本分類中,卡方檢驗(yàn)被用于確定特征tk與類別ci的獨(dú)立性程度.如果χ2(tk,ci)=0,則表示特征tk和類別ci是相互獨(dú)立的,即特征tk對(duì)類別ci不具有任何代表性;反之,卡方檢驗(yàn)值越大,該特征對(duì)分類越有用.卡方檢驗(yàn)公式定義為
1.2.4 正交質(zhì)心 正交質(zhì)心先計(jì)算一個(gè)特征在每個(gè)類別和在整個(gè)訓(xùn)練集中的質(zhì)心,然后根據(jù)每個(gè)類質(zhì)心與整個(gè)訓(xùn)練集質(zhì)心計(jì)算出該特征的分值.特征的分值越大,該特征包含越多的分類信息.一個(gè)特征的正交質(zhì)心公式定義為
1.2.5 FCFS特征選擇算法 FCFS算法先計(jì)算特征tk出現(xiàn)在所有類別中的質(zhì)心tck,然后將特征tk在類別ci中的特征頻率與tck的偏差作為該特征度量,值越大則越具有類別代表性.FCFS算法可描述為
FCFS(tk,ci)=tf(tk,ci)-tf(tk)/|C|.
2 算法設(shè)計(jì)
目前,大多數(shù)特征選擇算法都是在特征×類別矩陣的基礎(chǔ)上進(jìn)行的.在特征×類別矩陣中,行表示出現(xiàn)在訓(xùn)練集中的每個(gè)特征,列表示預(yù)定義的類別,矩陣中的元素表示某個(gè)特征出現(xiàn)在某一類別中的特征頻率,見(jiàn)表1.
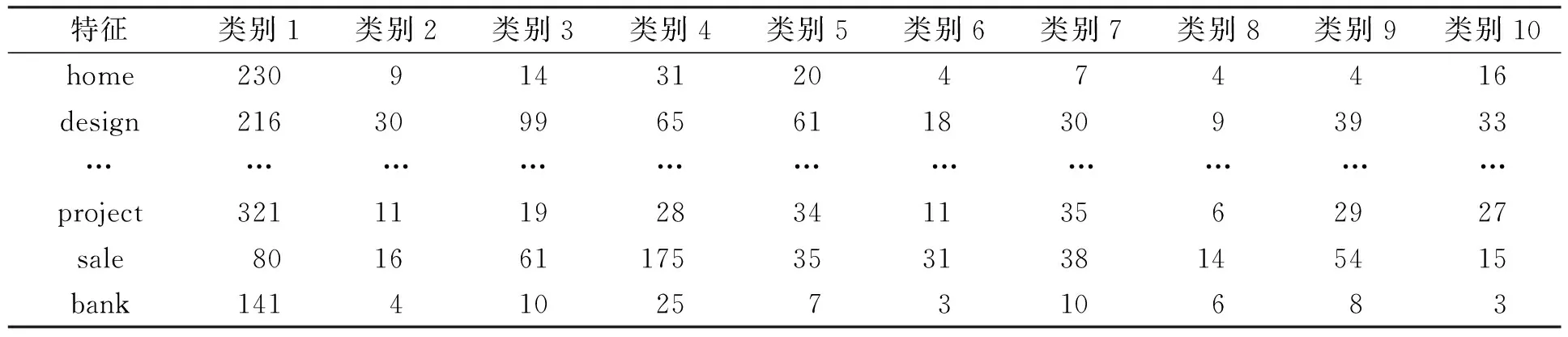
表1 特征×類別矩陣Table 1 Feature×category matrix
2.1 算法思想
FCFS算法根據(jù)一個(gè)特征在不同類別中出現(xiàn)的特征頻率計(jì)算該特征在不同類別中的質(zhì)心,然后計(jì)算該特征在某一類別中偏離該質(zhì)心的距離.如果特征tk在類別ci中偏離質(zhì)心的距離最大,則表明該特征tk擁有最多的類別ci信息.FCFS算法即為通過(guò)一個(gè)特征偏離類別質(zhì)心的程度度量該特征在某一類別中相對(duì)于在其他類別中的重要程度.
正交質(zhì)心特征選擇算法首先計(jì)算所有特征在整個(gè)訓(xùn)練集中的質(zhì)心及在每個(gè)類別中的質(zhì)心,然后利用每個(gè)類別的質(zhì)心和整個(gè)訓(xùn)練集質(zhì)心計(jì)算出所有特征對(duì)分類的重要程度.正交執(zhí)行特征選擇算法主要是計(jì)算類別內(nèi)部一個(gè)特征相對(duì)其他特征對(duì)分類的重要程度.
事實(shí)上,FCFS算法只關(guān)注了一個(gè)特征出現(xiàn)在某一類別中相對(duì)于出現(xiàn)在其他類別中的重要程度,而正交質(zhì)心算法只考慮了某一類別中一個(gè)特征相對(duì)于其他特征的重要程度.上述兩種算法都只分別考慮了特征×類別矩陣中的一方面,即FCFS算法只關(guān)注特征×類別矩陣的行,而正交質(zhì)心只關(guān)注特征×類別矩陣的列.如表1中的特征,按照FCFS算法特征project包含類別1的信息最多,而從正交質(zhì)心算法的角度看則是特征design最能代表類別1.基于上述原因,本文提出一種新的特征選擇算法,該算法彌補(bǔ)了上述兩種算法的不足,同時(shí)考慮特征×類別矩陣的行和列,綜合度量一個(gè)特征對(duì)分類的重要程度.
2.2 算法描述
輸入:V,D,K.其中:V表示特征×類別矩陣,包含T個(gè)特征,C個(gè)類別,矩陣中元素tf(i,j),1≤i≤T,1≤j≤C,表示第i個(gè)特征在第j類別中的特征頻率;D表示類別中文本數(shù)量向量{d1,d2,…,dj},1≤j≤C,dj表示第j個(gè)類別中的文本數(shù)量;K表示要選擇的特征數(shù)量.
輸出:特征子集Vs.
算法如下:
1) 計(jì)算整個(gè)訓(xùn)練集中的特征質(zhì)心向量,M={m1,m2,…,mi},其中mi表示第i個(gè)特征的質(zhì)心,
3) for每個(gè)特征ti∈V;
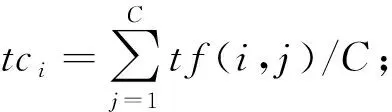
4) for每個(gè)類別ci∈C
計(jì)算特征ti在類別cj中相對(duì)于類間質(zhì)心tci的偏移量,cp(i,j)=tf(i,j)-tci;
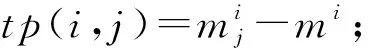
計(jì)算特征ti的總體重要性,ICFS(i,j)=tp(i,j)*cp(i,j);
end
end
5) 按照ICFS(i,j)對(duì)所有的特征進(jìn)行排序;
6) 選擇ICFS(i,j)值最高的K個(gè)特征構(gòu)成一個(gè)新的特征集合Vs.
3 實(shí)驗(yàn)環(huán)境與結(jié)果
3.1 數(shù)據(jù)集
為了驗(yàn)證算法的有效性,本文在3個(gè)不同的數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)驗(yàn)證.其中,20-Newgroups是文本分類中常采用的語(yǔ)料集,共包含19 997個(gè)文本,且所有的文本被平均劃分到20個(gè)不同的類別中;Reuters-21578語(yǔ)料集中共包含21 578個(gè)路透社新聞報(bào)道,所有的新聞報(bào)道被不均勻的劃分到135個(gè)類別中,本文采用文本數(shù)量最多的10個(gè)類別;WebKB語(yǔ)料集中包含4個(gè)不同大學(xué)網(wǎng)站的網(wǎng)頁(yè)集合,8 282個(gè)網(wǎng)頁(yè)被劃分到7個(gè)不同的類別中.本文采用“course”,“faculty”,“project”和“student”4個(gè)類別作為訓(xùn)練集.
3.2 分類器
在實(shí)驗(yàn)過(guò)程中,本文使用兩個(gè)不同的分類器.其中,Bayes分類器是建立在出現(xiàn)于一個(gè)文本中的特征與其他特征無(wú)關(guān)的假設(shè)基礎(chǔ)上的分類算法.目前,Bayes分類器有兩種常用模型: 多項(xiàng)式模型和多元Bernoulli模型[10].本文采用多項(xiàng)式模型.支持向量機(jī)是一個(gè)高效的文本分類器.本文采用libsvm工具包[11],并選擇缺省參數(shù)和線性核.
3.3 評(píng)價(jià)準(zhǔn)則
采用Micro-F1和準(zhǔn)確率[12-14]度量本文提出特征選擇算法的性能:
其中:P表示查準(zhǔn)率;R表示查全率;TP表示正確劃分為正類的數(shù)量;TN表示正確劃分為負(fù)類的數(shù)量;FP表示錯(cuò)誤劃分為正類的數(shù)量;FN表示錯(cuò)誤劃分為負(fù)類的數(shù)量.
3.4 實(shí)驗(yàn)結(jié)果
3.4.1 Micro-F1性能比較 表2~表4分別列出了6個(gè)不同特征選擇算法應(yīng)用在20-Newgroups,Reuters-21578和WebKB語(yǔ)料集上時(shí),Bayes分類器和支持向量機(jī)分類器的Micro-F1性能比較結(jié)果.由表2可見(jiàn),當(dāng)ICFS特征選擇算法應(yīng)用在20-Newgroups語(yǔ)料集時(shí),Bayes和支持向量機(jī)的分類性能優(yōu)于信息增益、文檔頻率和正交質(zhì)心,次于卡方檢驗(yàn)和FCFS算法.由表3可見(jiàn),當(dāng)ICFS算法應(yīng)用在Reuters-21578語(yǔ)料集上時(shí),Bayes和支持向量機(jī)分類器的性能均優(yōu)于其他5個(gè)特征選擇算法.由表4可見(jiàn),ICFS算法應(yīng)用在WebKB語(yǔ)料集上時(shí),分類器的性能優(yōu)于其他特征選擇算法,特別是采用支持向量機(jī)分類器時(shí).
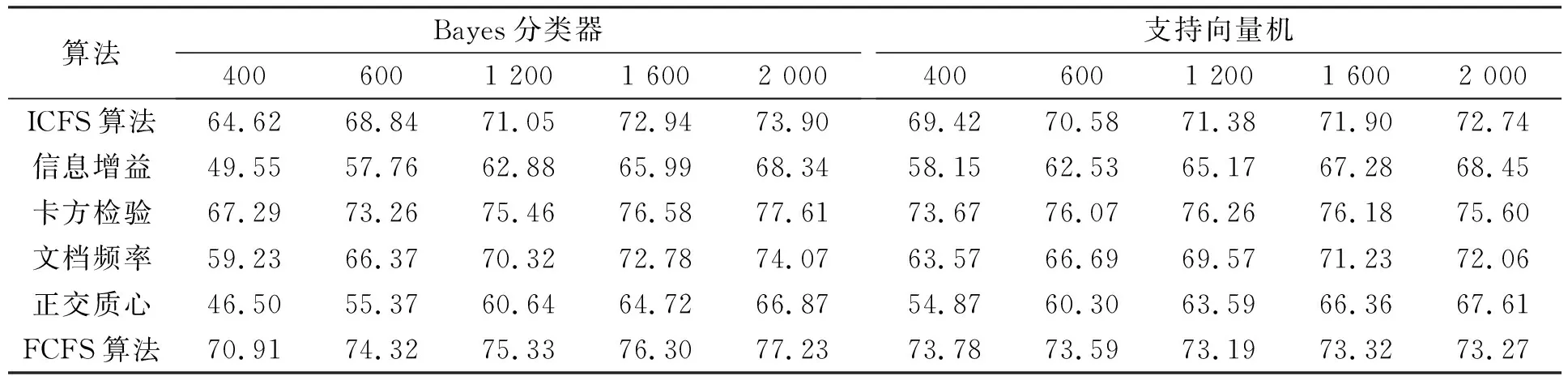
表2 6種不同特征選擇算法應(yīng)用在20-Newgroups語(yǔ)料集時(shí)Bayes分類器和支持向量機(jī)分類器的Micro-F1性能比較Table 2 Micro-F1 measure result by Na?ve Bayes and SVM classifiers for 6 feature selection algorithms on 20-Newsgroups
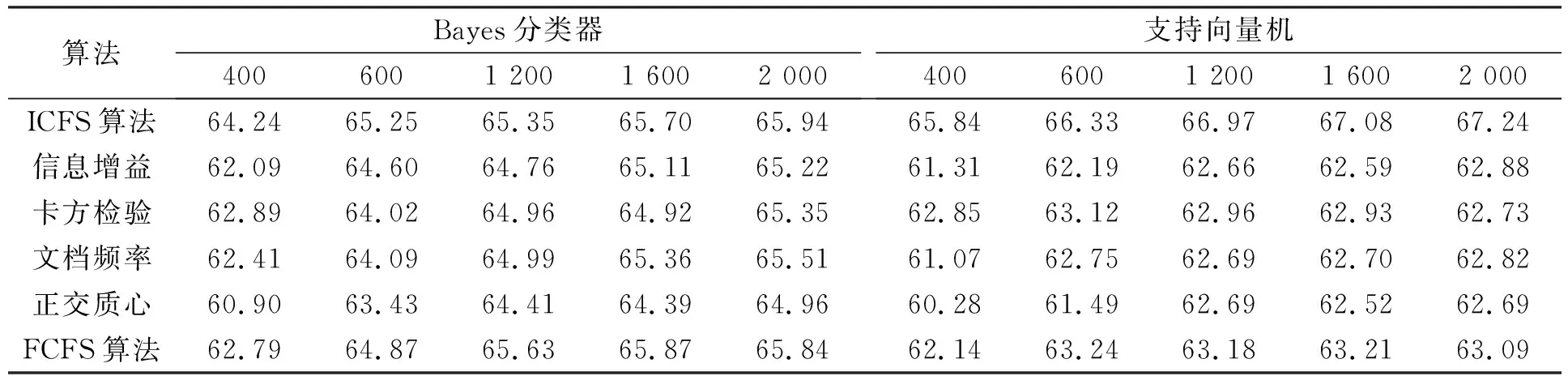
表3 6種不同特征選擇算法應(yīng)用在Reuters-21578語(yǔ)料集時(shí)Bayes分類器和支持向量機(jī)分類器的Micro-F1性能比較Table 3 Micro-F1 measure result by Na?ve Bayes and SVM classifiers for 6 feature selection algorithms on Reuters-21578
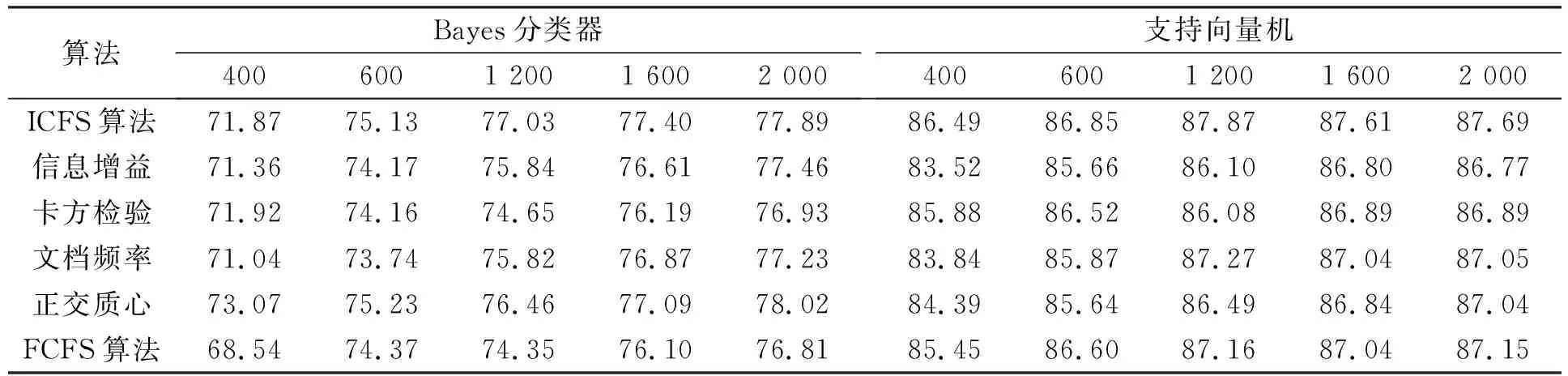
表4 6種不同特征選擇算法應(yīng)用在WebKB語(yǔ)料集時(shí)Bayes分類器和支持向量機(jī)分類器的Micro-F1性能比較Table 4 Micro-F1 measure result using Na?ve Bayes and SVM classifiers for 6 feature selection algorithms on WebKB
3.4.2 分類準(zhǔn)確率性能比較 圖1~圖6為6種特征選擇算法應(yīng)用在3個(gè)不同語(yǔ)料集上時(shí)Bayes和支持向量機(jī)分類器的分類準(zhǔn)確率性能曲線.由圖1和圖2可見(jiàn),應(yīng)用ICFS特征選擇算法時(shí)的Bayes分類器和支持向量機(jī)分類器的準(zhǔn)確率曲線高于信息增益、文檔頻率和正交質(zhì)心算法,而低于卡方檢驗(yàn)和FCFS算法.由圖3可見(jiàn),ICFS算法應(yīng)用在Retuers-21578語(yǔ)料集上時(shí),Bayes分類器的準(zhǔn)確率曲線除了當(dāng)特征數(shù)量為800~1 600時(shí)僅次于FCFS外,高于其他特征選擇算法,特別是當(dāng)特征數(shù)量較少時(shí),性能的增加較明顯.由圖4可見(jiàn),應(yīng)用ICFS算法時(shí),支持向量機(jī)分類器的分類準(zhǔn)確率遠(yuǎn)高于其他特征選擇算法,性能增加的幅度最高達(dá)到了1.6%.由圖5可見(jiàn),ICFS算法應(yīng)用在WebKB語(yǔ)料集上時(shí),Bayes分類器的分類準(zhǔn)確率曲線整體上高于其他特征選擇算法,但性能增加的幅度不大,低于0.6%.由圖6可見(jiàn),ICFS算法與支持向量機(jī)分類器配合應(yīng)用在WebKB語(yǔ)料集上時(shí),分類準(zhǔn)確率遠(yuǎn)高于其他特征選擇算法.
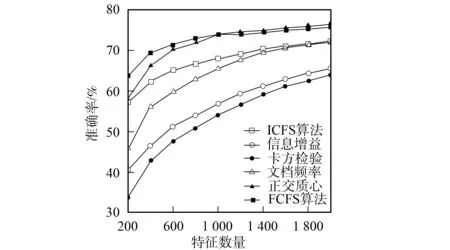
圖1 6個(gè)特征選擇算法應(yīng)用在20-Newgroups 語(yǔ)料集時(shí)Bayes分類器的準(zhǔn)確率曲線 Fig.1 Accuracy performance curves of Na?ve Bayes combined with 6 feature selection algorithm on 20-Newsgroups
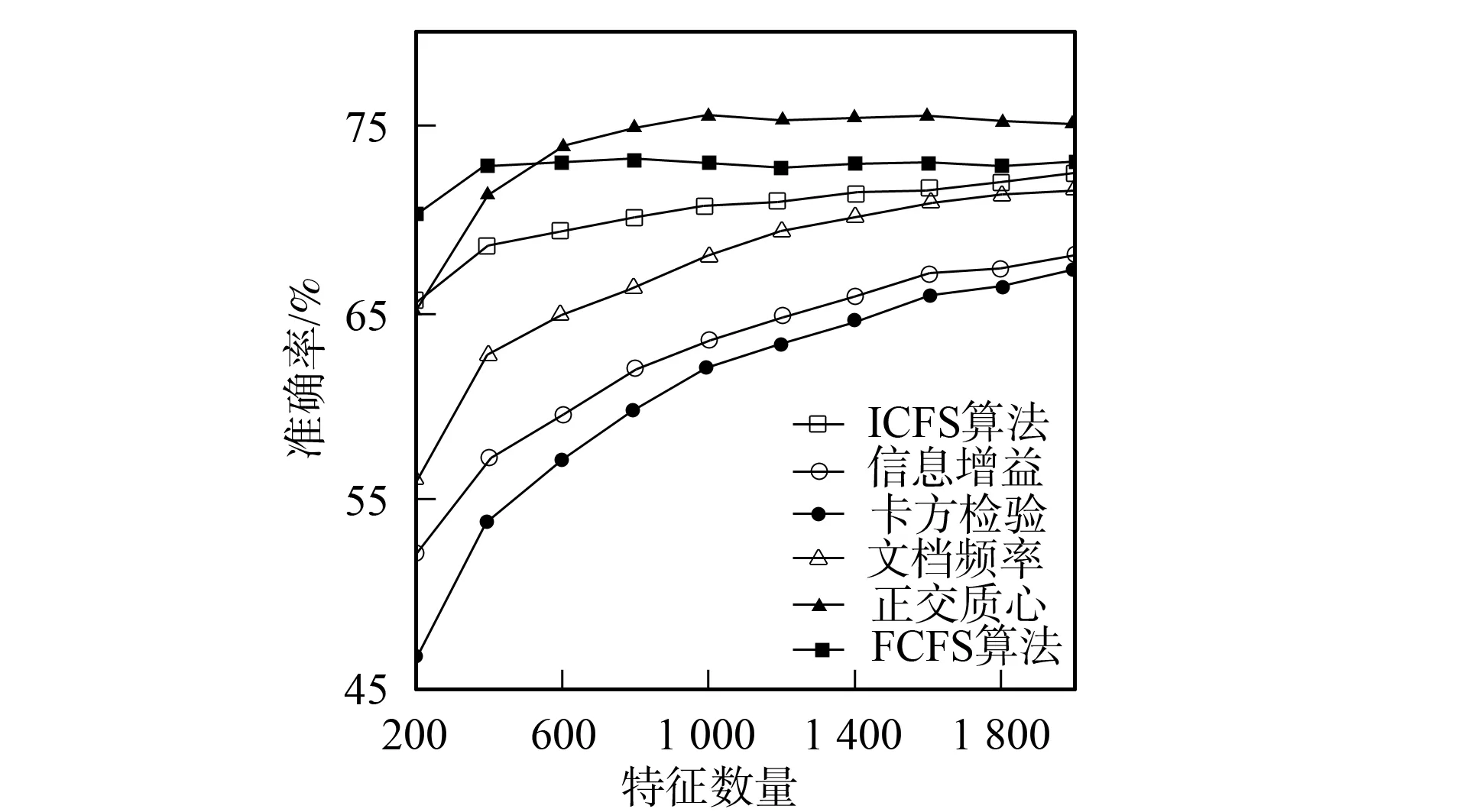
圖2 6個(gè)特征選擇算法應(yīng)用在20-Newgroups語(yǔ)料 集時(shí)支持向量機(jī)分類器的準(zhǔn)確率曲線 Fig.2 Accuracy performance curves of SVM combined with 6 feature selection algorithm on 20-newsgroups
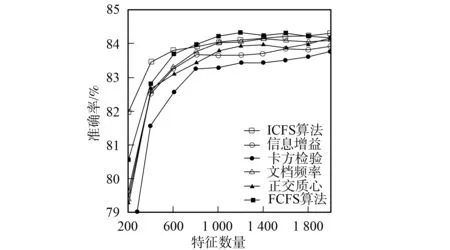
圖3 6個(gè)特征選擇算法應(yīng)用在Reuters-21578語(yǔ)料 集時(shí)Bayes分類器的準(zhǔn)確率曲線 Fig.3 Accuracy performance curves of Na?ve Bayes combined with 6 feature selection algorithm on Reuters-21578
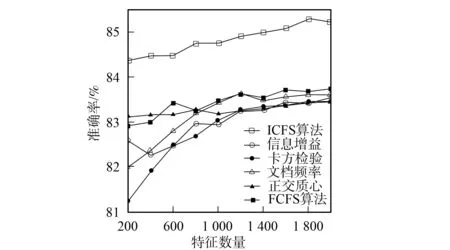
圖4 6個(gè)特征選擇算法應(yīng)用在Reuters-21578語(yǔ)料 集上時(shí)的支持向量機(jī)分類器的準(zhǔn)確率曲線 Fig.4 Accuracy performance curves of SVM combined with 6 feature selection algorithm on Reuters-21578
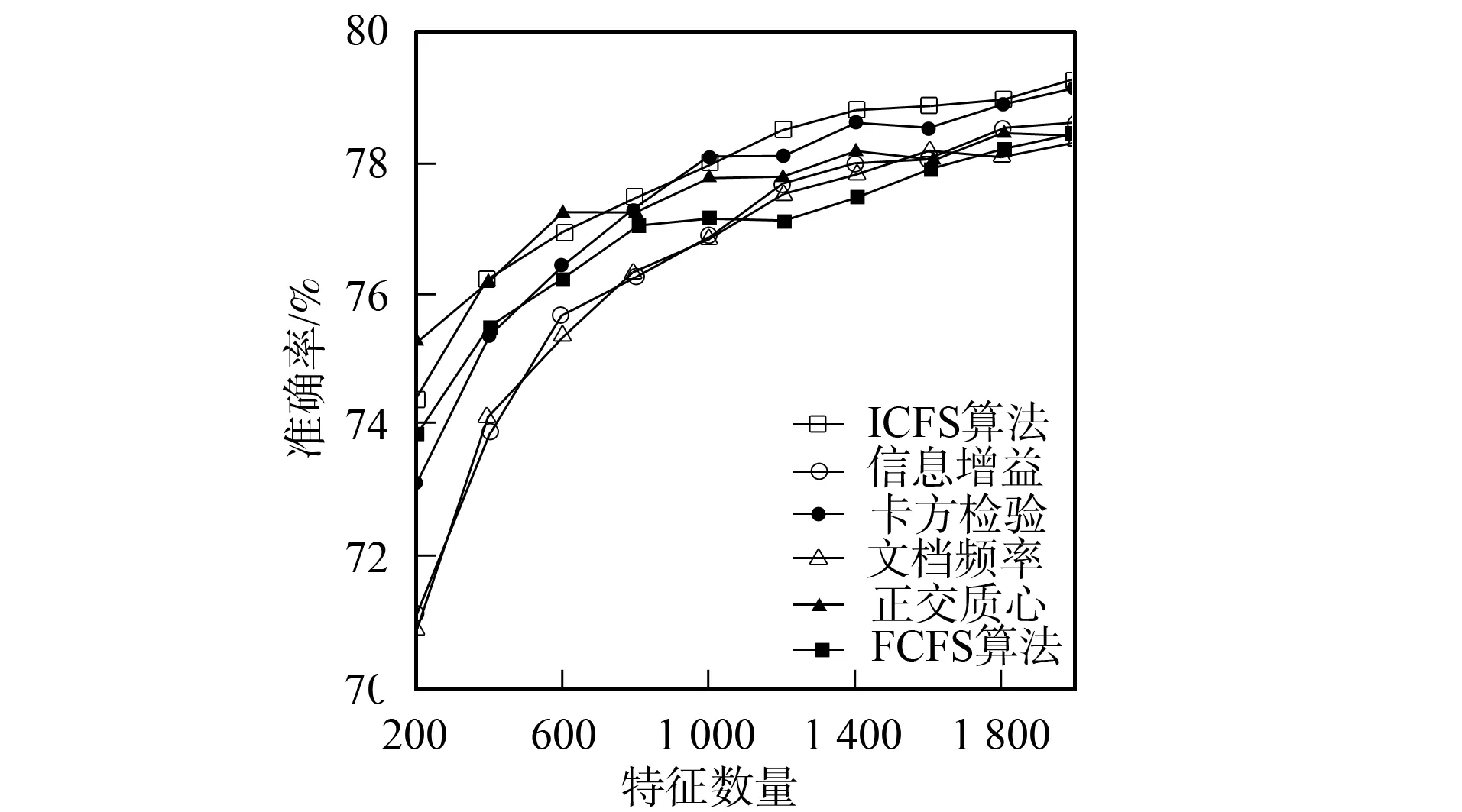
圖5 6個(gè)特征選擇算法應(yīng)用在WebKB語(yǔ)料 集上時(shí)Bayes分類器的準(zhǔn)確率曲線Fig.5 Accuracy performance curves of Na?ve Bayes combined with 6 feature selection algorithm on WebKB
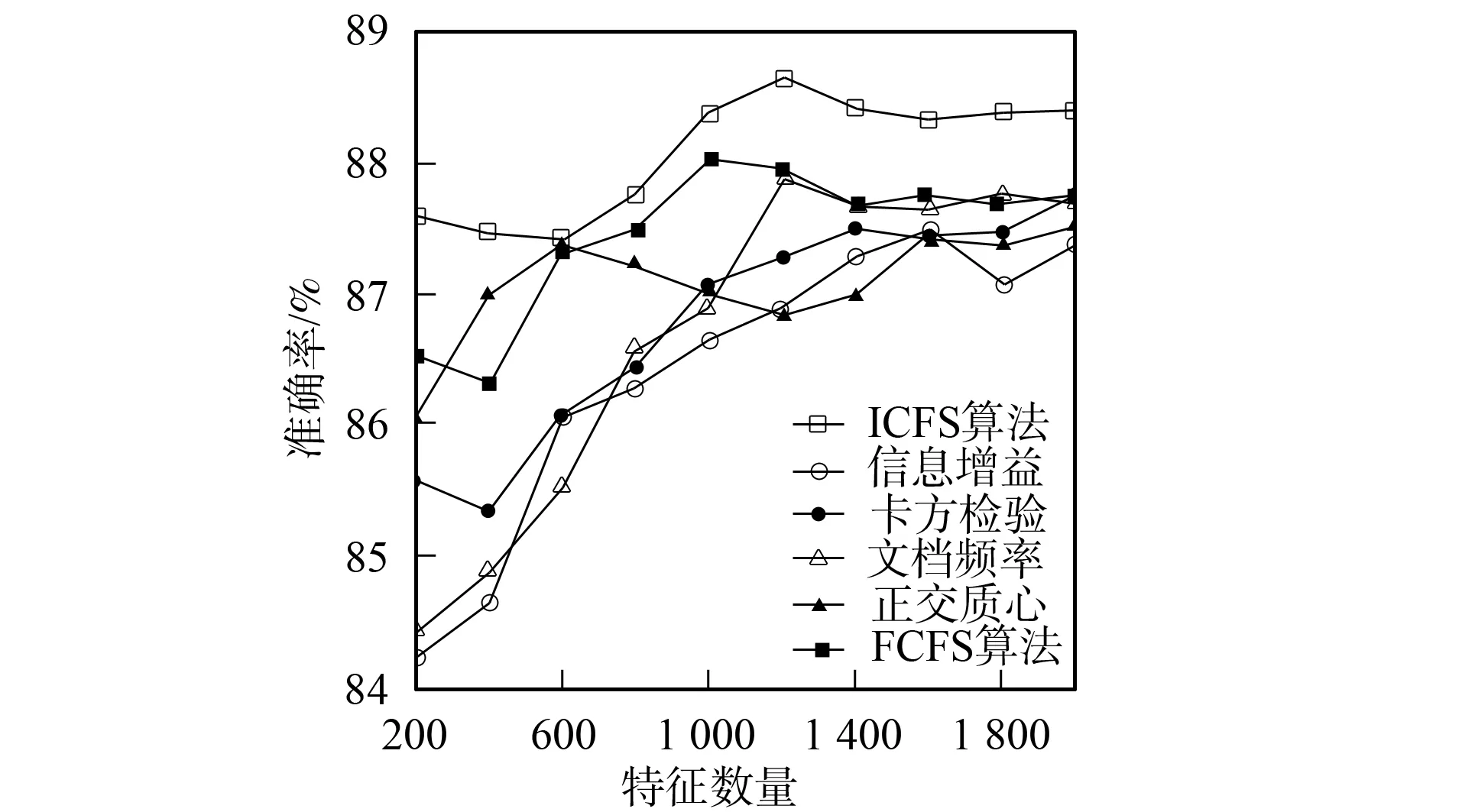
圖6 6個(gè)特征選擇算法應(yīng)用在WebKB語(yǔ)料集 上時(shí)支持向量機(jī)分類器的準(zhǔn)確率曲線 Fig.6 Accuracy performance curves of SVM combined with 6 feature selection algorithm on WebKB
由實(shí)驗(yàn)結(jié)果可見(jiàn),本文提出的新的特征選擇算法在20-Newgroups語(yǔ)料集上并未獲得最優(yōu)效果.主要是因?yàn)?0-Newgroups語(yǔ)料集是一個(gè)平衡的語(yǔ)料集,而Reuters-21578和WebKB語(yǔ)料集都存在不同程度的不平衡性問(wèn)題,所以本文提出的特征選擇算法在不平衡的環(huán)境下能較好地發(fā)揮作用.
綜上所述,本文提出的特征選擇算法由兩方面綜合地度量了一個(gè)特征對(duì)分類的重要程度.實(shí)驗(yàn)結(jié)果表明,該特征選擇算法能有效提高分類器的分類性能,特別在不平衡數(shù)據(jù)集上能產(chǎn)生較大幅度的性能提升.
[1] Sebastiani F.Machine Learning in Automated Text Categorization [J].ACM Computing Surveys,2002,34(1): 1-47.
[2] Deerwester S,Dumail S T,Furnas G W,et al.Indexing by Latent Semantic Analysis [J].Journal of the American Society of Information Science,1990,41(6): 391-407.
[3] TANG Lei,LIU Huan.Bias Analysis in Text Classification for Highly Skewed Data [C]//Proceedings of the 5th IEEE International Conference on Data Mining (ICDM-05).Washington: IEEE Computer Society,2005: 781-784.
[4] YANG Jie-ming,LIU Yuan-ning,LIU Zhen,et al.A New Feature Selection Algorithm Based on Binomial Hypothesis Testing for Spam Filtering [J].Knowledge-Based Systems,2011,24(6): 904-914.
[5] YANG Jie-ming,LIU Yuan-ning,ZHU Xiao-dong,et al.A New Feature Selection Based on Comprehensive Measurement Both in Inter-Category and Intra-Category for Text Categorization [J].Information Processing and Management,2012,48(4): 741-754.
[6] YANG Yi-ming,Pedersen J O.A Comparative Study on Feature Selection in Text Categorization [C]//Proceedings of the 14th International Conference on Machine Learning.San Francisco: Morgan Kaufmann Publishers Inc,1997: 412-420.
[7] Ogura H,Amano H,Kondo M.Feature Selection with a Measure of Deviations from Poisson in Text Categorization [J].Expert Systems with Applications: An International Journal,2009,36(3): 6826-6832.
[8] YAN Jun,LIU Ning,ZHANG Ben-yu,et al.OCFS: Optimal Orthogonal Centroid Feature Selection for Text Categorization [C]//Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York: ACM Press,2005: 122-129.
[9] YANG Jie-ming,LIU Zhi-ying.A Feature Selection Based on Deviation from Feature Centroid for Text Categorization [C]//Proceedings of the Intelligent Control and Information Processing (ICICIP).Piscataway: IEEE Press,2011: 180-184.
[10] McCallum A,Nigam K.A Comparison of Event Models for Na?ve Bayes Text Classification [C]//AAAI-98 Workshop on Learning for Text Categorization.[S.l.]: AAAI Press,1998.
[11] Chang C C,Lin C J.LIBSVM: A Library for Support Vector Machines [EB/OL].2011-09-03.http://www.csie.ntu.edu.tw/~cjlin/libsvm.
[12] Forman G.An Extensive Empirical Study of Feature Selection Metrics for Text Classification [J].Journal of Machine Learning Research,2003,3: 1289-1305.
[13] WANG Gang,LIU Yuan-ning,ZHANG Xiao-xu,et al.Novel Spam Filtering Method Based on Fuzzy Adaptive Particle Swarm Optimization [J].Journal of Jilin University: Engineering and Technology Edition,2011,41(3): 716-720.(王剛,劉元寧,張曉旭,等.基于模糊自適應(yīng)粒子群的垃圾郵件過(guò)濾新方法 [J].吉林大學(xué)學(xué)報(bào): 工學(xué)版,2011,41(3): 716-720.)
[14] LIU Jie,JIN Di,DU Hui-jun,et al.New Hybrid Feature Selection Method RRK [J].Journal of Jilin University: Engineering and Technology Edition,2009,39(2): 419-423.(劉杰,金弟,杜惠君,等.一種新的混合特征選擇方法RRK [J].吉林大學(xué)學(xué)報(bào): 工學(xué)版,2009,39(2): 419-423.)
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
