Hadoop平臺下基于資源預測的Delay調度算法
2013-12-03 05:24:44魏曉輝付慶午李洪亮
吉林大學學報(理學版) 2013年1期
魏曉輝, 付慶午, 李洪亮
(吉林大學 計算機科學與技術學院, 長春 130012)
計算機網絡技術的高速發展和應用, 帶來了數據規模的爆炸式增長, 使大規模數據的處理和存儲成為目前高性能計算領域的研究熱點. 傳統的高性能計算系統多用于處理計算密集型作業, 并不適合解決數據密集型應用問題. Google提出的Mapreduce[1]計算模型和GFS[2]分布式存儲系統, 為海量數據處理和存儲需求提供了全新的方法. 近年來, Hadoop作為Mapreduce和GFS模型的開源實現, 得到了廣泛的應用和認可. Hadoop平臺是新一代的高性能計算和存儲平臺, 其系統結構有別于傳統的高性能計算系統[3-8]. Hadoop的系統結構具有將數據資源(HDFS)和計算資源(Mapreduce)整合的特點. 該特點使Hadoop集群資源調度過程遵循一個基本思想: 移動計算不移動數據----將計算任務派到包含要處理的數據計算節點, 即任務本地化計算(task locality). 任務調度作為Hadoop系統的重要組成部分, 直接影響作業的執行效率和機群資源利用率. 目前的Hadoop調度方法優化多基于提高Locality比例優化作業的執行效率, 從而提高系統作業吞吐量.
本文基于對機群整體計算資源合理分配的調度思想, 針對Hadoop集群數據資源和計算資源整合的特點, 提出一種資源可用性預測方法----基于資源預測的Delay調度算法(resource forecast delay scheduling, RFD). 基于該方法, RFD控制任務進行合理的等待, 提高了系統的整體作業執行效率和系統作業吞吐量. 實驗結果表明, 在Hadoop一般應用場景下, 本文提出的方法在保證任務Locality比例相近的前提下, 相比Fairshare算法[9], 平均作業執行效率提高了28.8%.
1 基于資源預測的Delay調度算法
1.1 算法思想及框架
Hadoop系統中作業的本地化計算比例(Locality)是影響作業執行效率和系統資源利用率的關鍵因素. 因此, 如何合理控制任務進行等待, 在保證系統Locality的同時, 合理分配資源是Hadoop調度程序要解決的關鍵問題. 本文提出一種基于資源預測的Delay調度算法(RFD). RFD算法以計算資源可用性為依據控制任務進行合理地等待, 提高作業的運行效率和系統的整體資源利用率.
數據的非本地化計算和作業等待過長都會導致機群整體計算資源浪費, FIFO和Fairshare算法都沒能很好地解決這個問題. Delay算法雖然能提高本地化運算比例, 但難以適應資源可用性動態變化. 因此, RFD調度器基于Delay思想, 針對資源實時可用性的預測進行合理地等待, 在數據非本地化計算和作業等待時間之間取得更好的平衡, 以提高機群整體利用效率.
RFD算法包含一個資源可用性預測模塊, 對各作業所需的資源可用性進行預測. 每個作業的資源需求不同和依賴的數據文件不同導致同一個資源對不同的作業可用性不同. 因此, RFD中使用作業的“可用資源期望”表達集群資源對作業的可用性. 圖1為RFD調度示意圖, job1的可用資源期望為2, 表示在未來一個調度周期中, 將到來的含有job1所需數據的節點請求數量為2. 在RFD算法進行資源分配前, 先根據歷史數據估計出作業隊列中各作業的資源期望值, 即可根據可用資源期望進行作業調度. 由圖1可見, job1的可用資源期望為2, job2的可用資源期望為3. 因此, 這兩個作業均可在本輪調度周期進行等待. 如果此時Tasktracker2有任務請求且該節點無job1要處理的數據塊, 則可以讓job1等待, 調度job2在該節點的本地化運算Map任務. 若job2也無本地化運行Map任務, 則繼續等待, 匹配下一個作業(如圖1中Tasktracker3的任務調度). 因此, RFD算法中任務等待是依據作業的資源可用性進行的, 這樣的等待不會影響作業的運行.
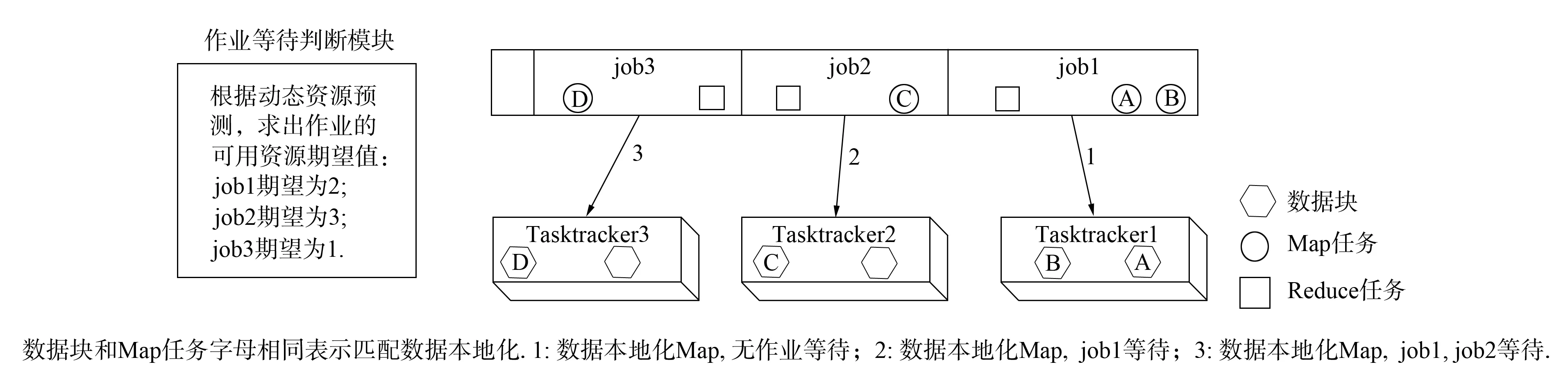
圖1 RFD調度示意圖Fig.1 Scheme of RFD scheduler
另一方面, 為了在通用環境下能夠高效運行, RFD調度器引入了FIFO簡單而高效的設計思路, 強調作業的先后優先級別. 在為計算資源匹配本地化計算任務時, 按作業提交順序進行匹配, 如圖2所示. 在Delay時機選擇方面, 本文遵循使總體效益損失最小的原則進行調度. 圖2為RFD調度器基本流程, 對于Tasktracker的任務請求, 為提高整體作業Locality計算比例, 先匹配該Tasktracker數據本地化計算的Map任務; 若匹配不成功, 為了整體作業合理等待, 則根據作業等待判斷模塊計算的可用資源期望決定是否等待.
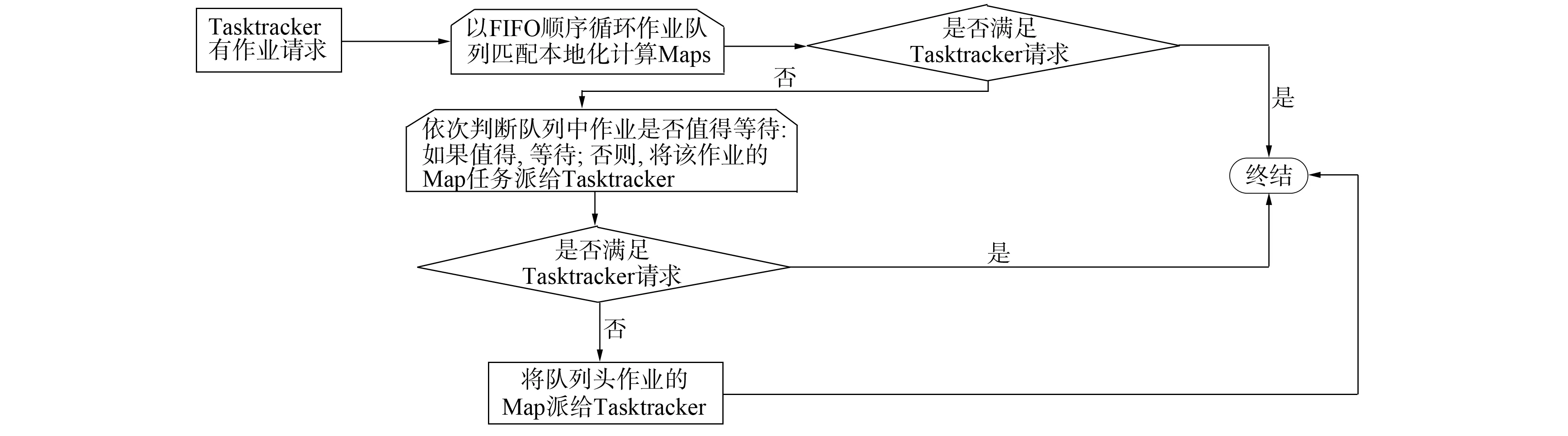
圖2 本文調度算法基本框架Fig.2 Scheduling algorithm basic framework
1.2 RFD調度算法
針對RFD調度算法的需要, 本文對Hadoop系統進行如下定義:j為jobj;N為機群中的總機器數;Mj為作業j未運行的Map task;Kj為Mj未處理數據分布的機器數;TT為數據塊在兩個計算節點間傳輸所需的時間;Pj為下一個“心跳”的源機器上有jobj未處理數據塊的概率:
Pj=Kj/N;
(1)
H為Jobtracker每秒鐘接收的“心跳”數:
H=N/3;
(2)
S為每個Tasktracker上可運行的Map任務數;t為作業平均完成時間;Ph為某個“心跳”有作業請求的概率:
Ph=3×S/t;
(3)
Ej為在未來TT時間內, Jobtracker接收的“心跳”中, 有作業請求, 且該“心跳”的源機器上有jobj未處理的數據塊的期望:
Ej=H×TT×Pj×Ph;Ej=(TT×N/3)×(kj/N)×(3×S/t)=TT×S×Kj/t.
(4)
期望Ej評判是否值得對作業j等待. 該期望值體現了一個數據塊傳輸的時間內能收到本地化作業請求的期望, 如果Ej≥1, 表明對于該作業, 等待是值得的.
在作業進行等待的同時, RFD算法需要考慮資源競爭問題. 對于當前調度的作業, 如果在未處理的數據塊機器上同樣含有在它之前作業未處理的數據塊, 則計算Ej時, 應考慮資源競爭的問題. 否則, 當計算該作業的Ej≥1時, 會出現與前面作業沖突, 前面的作業會占用與該作業有共同數據塊的機器作業請求, 導致Ej值虛高, 容易使該作業出現饑餓. 因此, 本文引入如下兩個變量:Rj為作業j與它前面作業的未處理數據塊在同一臺機器上的機器數; Prj為作業j與它前面作業會發生資源競爭的概率:
Prj=Rj/Kj;Ej=TT×S×Kj/t×Prj=TT×S×Rj/t.
(5)
RFD調度算法流程如下.
Begin
將作業調度隊列JobQueue按提交順序排列
assignedTasks=0; //標記已經派給Tasktracker的Map任務數
while(true)
If (assignedTasks==Tasktracker.請求作業數) then //滿足Tasktracker作業請求
break;
endif
For jobiin jobQueue do
If jobi有數據塊在發送“心跳”的機器上 then //Data-Local, 直接派作業
將jobi的數據本地化Map派到該機器上;
assignedTasks + +;
break;
endif
endfor
If (前面沒有找到合適的Map任務) then //下面引入等待機制
For jobiin jobQueue do
根據式(7)計算作業 jobi的期望值Ei;
If (Ei<1) then //如果Ei<1, 不值得等待, 分非本地化計算的Map任務
將jobi的數據非本地化Map派到該機器上;
assignedTasks + +;
break;
Else then
continue; //等待, 調度隊列中下一個作業
endif
endfor
If (前面沒有找到分配Map任務) then //前面沒有找到合適Map的任務
分配隊首作業非本地化Map任務;
assignedTasks + +;
endif
endwhile
End.
RFD調度算法吸收了FIFO和Delay-Scheduling算法的簡單高效特點, 避免了兩種算法的各自缺點, 提高了作業本地化計算Map任務的比例, 同時不會產生過度的等待, 有效地提高了機群整體的資源利用率. 通過分析可知, 第一個循環以FIFO的順序將隊列中作業于請求作業的Tasktracker進行數據本地化匹配. 循環結束, 若未匹配, 則該Tasktracker在當前的情況下不能分配到數據本地化計算的Map任務. 進入算法的Delay機制, 考慮作業是否應該等待; 基于對作業的可用計算資源預測, 對作業是否值得等待進行合理的評估. 上述兩次循環匹配都是基于整體計算資源的合理利用考慮. 如果還沒有分配到Map任務, 則將作業隊列隊首的Map任務分配給Tasktracker, 這種情況較少.
2 實驗結果和數據分析
2.1 實驗環境及結果
實驗機群由10臺Dell optiple x380 PC服務器構成(英特爾酷睿4核處理器, 2 Gb內存, 200 Gb硬盤), 采用100 M以太網絡相連, 實驗軟件采用Hadoop-0.21.0版本, 實驗所用數據為某網站訪問日志文件, 經過處理分成128 Mb~4 Gb不等10份樣本, 實驗用例是基于基本數據采樣處理的Mapreduce 作業, 用于統計訪問該網站的客戶端IP登陸次數.
本文對FIFO算法、 Fairshare算法和本文提出的RFD調度算法進行對比實驗. 為了反映真實的對比結果, 所用的實驗環境、 數據分布及作業完全一致. Fairshare調度器采用默認Delay時間設置. 針對10份不同的數據樣本, 每組測試6個作業. 在實驗過程中, 重點關注各實驗用例中作業的本地化計算任務數(比例)和作業的平均完成時間, 實驗結果列于表1和表2.
由RFD算法分析可知, 調度器是否對作業進行等待取決于對資源的預測期望值Ej; 若Ej≥1, 則作業等待; 否則, 將該作業非本地化計算的Map任務派出去. 可見, 系統計算期望值Ej的準確性將對作業是否等待產生決定性影響, 若該期望值不符合機群的實際運行情況, 將導致機群計算資源的浪費, 降低作業執行效率.
由于該期望值是對未來一段時間內(TT)Jobtracker能夠收到的包含某個作業未執行的Map任務要處理的數據塊的Tasktracker任務請求次數. 因此, 要將在某個時刻計算的所有作業的期望值都記錄下來, 對于某個作業, 記錄在未來時間TT內, Jobtracker收到任務請求的Tasktracker中, 包含有該作業未處理的數據塊的任務請求次數. 過了TT時刻開始輸出記錄每個作業真正收到的本地化計算Map任務請求; 實驗測試中, 在調度器中啟動一個統計線程, 該線程負責記錄每個收到的命中每個作業的本地化計算Map任務請求數, 定時輸出, 實驗結果列于表3.

表1 作業平均完成時間(s)

表2 數據本地化計算Map任務比例(%)
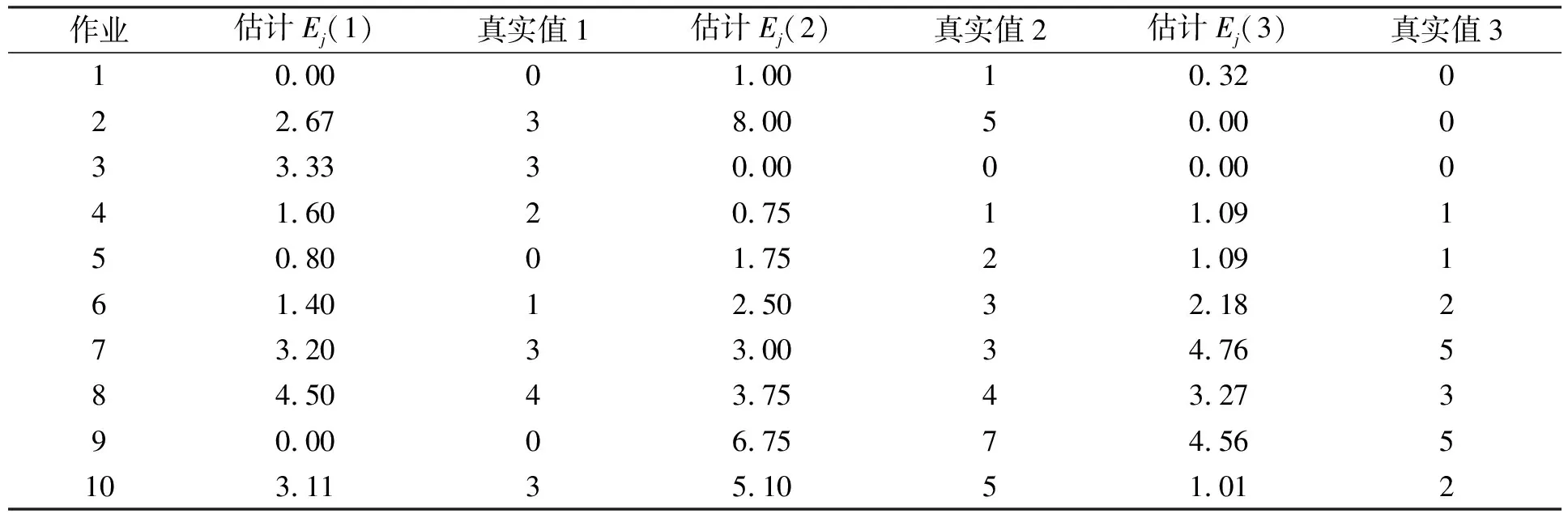
表3 資源預測準確性測試
由表3可見, 系統計算的資源預測期望值Ej與真實運行情況基本相同, 若將預測結果按四舍五入對應真實值, 預測準確度達90%以上, 表明本文基于資源預測的算法可行、 有效.
2.2 實驗結果分析
實驗結果可分為以下3種情況: 1) Map數為2, RFD調度器的本地化計算低于FIFO和Fairshare調度器, 作業運行時間高于后兩種調度器; 2) Map任務數為4和8, RFD調度器的數據本地化計算Map任務比例和執行時間都優于FIFO, 但不如Fairshare調度器; 3) Map任務數為16~64時, RFD調度器的本地化計算Map任務比例和作業運算時間優于FIFO, 本地化計算比例與Fairshare調度器相當, 但作業執行時間優于Fairshare調度器, 如圖3和圖4所示. 情況1)和2)屬于運行小作業的情況, Hadoop機群一般運行的作業都較大, 所以前兩種情況不常見; 情況3)運行的是中型和大型作業, 是Hadoop機群實際應用中經常出現的情況, 更具代表性.
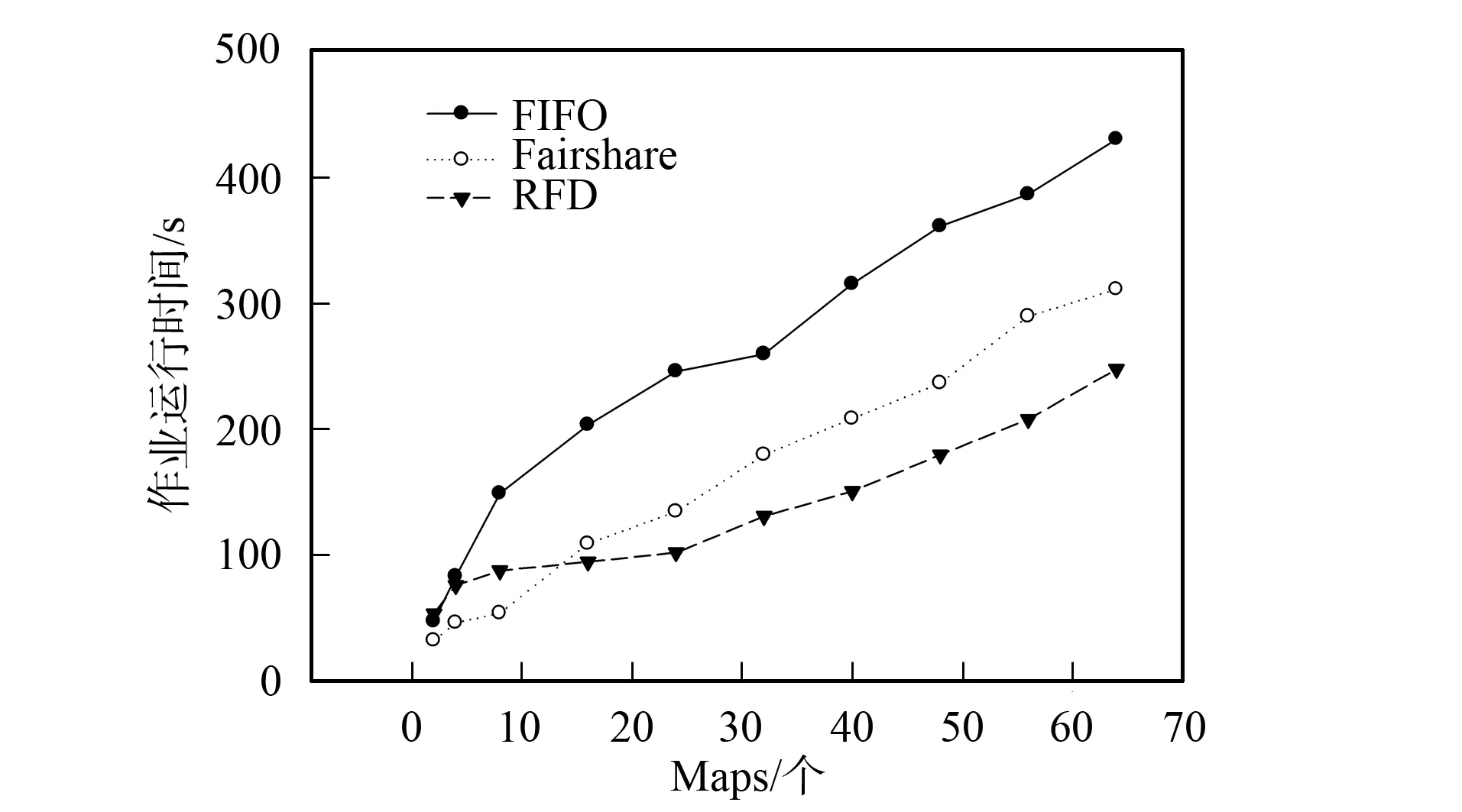
圖3 作業運行時間Fig.3 Jobs’ running time
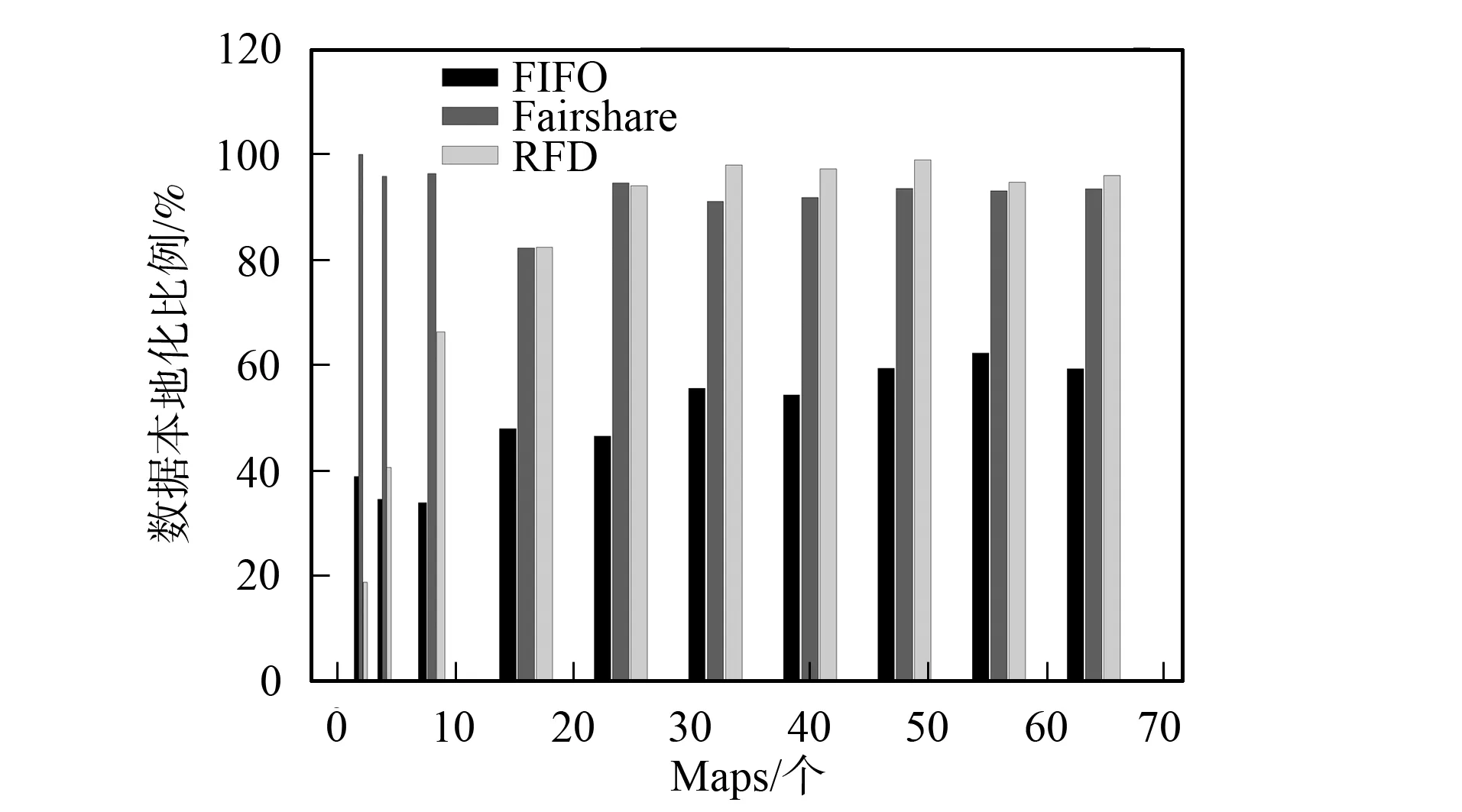
圖4 Map任務本地化計算(Locality)比例Fig.4 Percentages of locality computing Map tasks
當Hadoop運行作業, 分配非本地化計算的Map任務時, 傳輸數據塊和作業等待會導致作業運行時間增加; Delay算法是通過作業等待增加本地化計算Map任務數, 所以, 如何合理地等待是在這兩者取得平衡、 降低作業運行時間的關鍵.
由上述分析可知, RFD算法是否等待與作業未處理的數據塊分布機器數有關; Map任務數太少不會觸動等待機制. 分配一個非本地化計算Map任務給某個Tasktracker會影響其他作業的本地化計算任務分配到該Tasktracker(Tasktracker上分布著多個作業數據塊), 因此, Map任務較少時, RFD調度器會導致整體作業本地化計算Map任務比例低; Fairshare的等待時間是固定的4.5 s, 初始調度時, 調度器一定會收到一個Map本地化計算的作業請求(3 s就會收到Tasktracker一次“心跳”), 當Map任務數太少時, 本地化計算比例較高. FIFO調度器調度時只針對隊首作業, 不會受多個作業的數據塊分布在同一個計算節點的情況影響. 由圖3和圖4可見, 情況1)和2)中RFD調度器與Fairshare調度器相比, 在本地化計算任務比例低, 作業運行時間長; 但這兩項指標優于FIFO調度器.
隨著Map任務數增多, RFD調度器的等待機制被觸動, 本地化計算Map任務數開始增加. FIFO調度作業時只對隊首作業調度, 本地化計算Map任務數比例增長緩慢. 由圖4可見, Fairshare的等待時間固定, 所以本地化計算Map任務數比例變化不大.
情況3)中, RFD調度器的本地化Map任務數比例明顯上升(圖3), 作業運行時間低于Fairshare調度器, 這是由于Fairshare調度器等待時機不合理所致. 若某Tasktracker沒有一個作業的本地化計算數據會導致整個作業隊列都在等待, 因此作業運行時間較長; RFD調度器在以動態可用資源預測為等待基礎且以數據本地化調度優先, 等待時間較合理. 所以, 該情況下RFD調度器不僅本地化計算Map任務數比例較高, 且等待時間較合理, 作業運行時間也較少.
Hadoop的應用場景是處理大數據, 運行作業的Map任務數較多, 情況3)的出現概率遠大于情況1)和2). 實驗表明, RFD調度器在一般情況下比Fairshare和FIFO調度器的作業運行效率高, 且整體機群資源利用更合理. 根據Hadoop機群應用場景和本文的實驗結果可知, RFD在一般情況下, 本地化計算Map任務數比例與Fairshare調度器相近; 但作業平均運行時間低于Fairshare調度器的28.8%.
對比實驗表明, 本文提出的RFD算法與Fairshare算法相比, 一般情況下, 在保持系統高本地化作業執行比例(Locality)相近的同時, 優化了作業的整體執行效率(平均提高28%).
[1] Dean J, Ghemawat S. Mapreduce: Simplified Data Processing on Large Clusters [J]. ACM, 2008, 51: 107-113.
[2] Ghemawat S, Gobioff H, LEUNG Shun-tak. The Google File System [J]. ACM, 2003, 37: 29-43.
[3] Apache. The Oomepage of Hadop [EB/OL]. 2012-03-19. http://Hadoop.apache.org/.
[4] Shvachko K, KUANG Hai-rong, Radia S, et al. The Hadoop Distributed File System [J]. MSST, 2010, 1: 1-10.
[5] Amazon. The Homepage of s3 Distributed File System [EB/OL]. [2011-10-28]. http://aws.amazon.com/s3.
[6] Cloudstore. Cloudstore Distributed File System Website [EB/OL]. [2011-11-29]. http://kosmosfs.sourceforge.net/.
[7] GUO Dong, DU Yong, HU Liang. HDFS Based Cloud Data Backup System [J]. Journal of Jilin University: Science Edition, 2012, 50(1): 101-105. (郭東, 杜勇, 胡亮. 基于HDFS的云數據備份系統 [J]. 吉林大學學報: 理學版, 2012, 50(1): 101-105.)
[8] WEI Xiao-hui, Li Wilfred, XU Gao-chao, et al. Implementing Data Aware Scheduling on Gfarm by Using LSFTMScheduler Plugin [J]. Journal of Jilin University: Science Edition, 2005, 43(6): 763-767. (魏曉輝, Li Wilfred, 徐高潮, 等. 利用LSF調度程序的插件機制在Gfarm上實現Data aware調度 [J]. 吉林大學學報: 理學版, 2005, 43(6): 763-767.)
[9] Zaharia M, Borthakur D, Sarma J S, et al. Job Scheduling for Multi-user Mapreduce Clusters [J]. EECS Department, 2009, 55: 1-16.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
故事大王(2016年7期)2016-09-22 17:30:08
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
