支持向量機在視頻運動目標分析中的應用
2013-12-03 05:24:44邢吉生尚祖飛浦鐵成牛國成于哲舟
吉林大學學報(理學版) 2013年1期
邢吉生, 楊 禮, 尚祖飛, 浦鐵成, 牛國成, 于哲舟
(1. 北華大學 電氣信息工程學院, 吉林 吉林 132021;2. 中國科學院 長春光學精密機械與物理研究所光學系統先進制造技術重點實驗室, 長春 130033; 3. 黑龍江大學 電子工程學院, 哈爾濱 150080; 4. 吉林大學 計算機科學與技術學院, 長春 130012)
視頻監控系統模擬人的視覺系統, 對感興趣的目標進行特征提取, 并模擬人的大腦分析系統對目標進行分析和識別. 在模擬大腦分析系統時要求計算機不但能根據事先設定的閾值做出判斷, 同時還具備學習的功能, 只有這樣才能實現真正意義上的計算機智能化[1-2]. 本文基于結構風險最小化的支持向量機模式識別方法對視頻中運動目標進行分析, 模擬了人的學習和分析過程, 以達到對運動目標最終做出快速而準確識別的目的.
1 預備知識
先模擬人眼對感興趣的目標進行提取, 且選取穩定而又能反映物體本質的特征, 用適當的方式表達, 以進行分類識別. 提取特征的準確度直接影響最后的判定結果.
1.1 運動目標提取
所謂感興趣的目標主要針對運動物體, 這樣可去除絕大部分背景, 簡化支持向量機的訓練難度, 從而保證較高的檢測率、 較低的誤測率及較快的速度. 但并非所有的運動物體都是感興趣的目標, 如晃動的樹葉和飄揚的旗幟, 同時, 變化的天氣和光線也是重要因素.
本文采用混合Gauss模型的背景建模算法[3-4], 該方法對背景的自適應性較高, 在時空效率適中的情況下能提供較精確的背景模型, 再利用背景減除法即可分割出運動物體.
1.2 運動目標預處理
由于噪聲及前景空洞的影響, 因此得到的二值化前景圖像并不理想, 可利用形態學方法解決, 主要包括腐蝕和膨脹兩個基本運算[5-6]. 本文選用3×3和5×5的矩形模板, 通過調節腐蝕膨脹的模板類型、 使用順序及使用次數, 達到最好的效果. 本文設定連通區域閾值, 小于該閾值的不列為前景運動目標, 利用該方法不僅能過濾掉過小運動目標, 還能消除噪點. 在預處理過程中, 將數據中冗余部分去掉的同時降低了數據的維數, 從而減少建立學習模型的訓練時間.
1.3 時間一致性約束
在進行運動目標檢測時,會遇到目標遮擋及沒有完全進入場景的情況, 此時進行分類通常無法得到準確結果. 時間一致性約束[7]可理解為分類不僅依靠某一時刻的信息, 還要考慮在一段時間內運動物體的變化情況, 即記錄在一段時間內不同時刻測量的運動目標, 經過多次假設分類, 統計所有分類信息得到最后結果. 同時, 利用時間一致性約束還能分辨出輕微運動的背景, 如搖晃的樹枝, 即通過計算運動物體持續出現的時間, 若小于設定的閾值即視為背景擾亂.
1.4 支持向量機
支持向量機(SVM)是一種基于結構風險最小化原理的有監督統計學習方法, 明顯改善了泛化性能差、 容易出現過學習與欠學習等問題[8]. SVM是很好的分類器, 基于小樣本學習理論, 并能體現異類樣本的差異, 因此在各領域應用廣泛. SVM由線性可分情況下的最優分類面發展而來, 其基本思想可用兩類現行可分情況說明. 對于平面上的兩類可分樣本, 機器學習的任務是找到這樣一條直線, 不僅能把兩類樣本分開, 并且保證分類間隔最大. 所謂分類間隔是指從這條直線到兩類樣本中最近樣本的距離之和, 而這些最近距離樣本即為支持向量機.
復雜的分類問題可以先通過非線性映射將輸入空間變換到一個高維空間, 然后在該高維空間中獲得最優分類面. 本文引入非線性映射φ,Rd→H把數據從輸入空間Rd映射到更高維的心空間H, 數據在H上線性可分.Rd上的樣本集{(xi,yi),i=1,2,…,N}映射得到H, 從而得到新樣本集{(φ(xi),yi),i=1,2,…,N}, 然后在H上建立最優分類面. 根據Lagrange方法及Cover定理, 可得超平面決策函數:
(1)
它對于原空間Rd是非線性的. 由此引進核函數K(x,y)=φ(x)·φ(y), 從而只需在Rd上計算K(x,y)即可, 最終的判別式為
(2)
不同的核函數將導致不同的支持向量機算法, 目前主要有多項式、 徑向基函數和S型函數3種核函數. 核函數的選擇關系到最后分類識別的準確性, 但目前最優核函數的選擇仍未完全解決. 懲罰因子C的選擇同樣重要, 它的取值直接影響訓練分類的準確性和推廣性. 本文選擇徑向基函數作為核函數構造支持向量機模型.
2 特征抽取及實驗流程
2.1 運動目標特征提取
本文從單幀圖片和連續幀兩方面進行特征提取. 對單張圖片常用形狀、 紋理、 顏色等低層特征[9], 而對象的顏色和紋理等特征不蘊含對象的類別信息, 不適用于分類識別, 所以本文主要考慮形狀特征. 而對于連續圖片提取特征, 要使用跟蹤算法確定研究目標, 從而得到其運動中一些特性的變化情況. 本文主要從以下6個特征入手:
1) 高寬比R1=H/W, 其中H和W分別表示輪廓外接矩形的長與寬.R1能很好地描述輪廓的大概外形特征, 不隨目標的大小而改變. 一般認為HWR大于1時判定為人, 小于等于1時判定為車輛.
2) 占空比R2=S/SS, 其中:S表示運動目標區域面積;SS表示外界最小矩形面積. 考慮到目標的多角度問題,SS沒有直接使用1)中的H×W, 使占空比更準確.
3)R3=(10S1/H)/W, 其中S1為運動目標區域1/10處區域的面積. 10S1/H表示目標區域1/10處的平均寬度, 用于調節局部過寬的情況. 實驗表明, 人頭部寬度和身體寬度的比值與車頂寬度和車身寬度比例有明顯差別.R3是在車型識別中的重要特征.
4)R4=Lmax/Lmin, 其中:Lmax表示質心到輪廓邊緣最大值;Lmin表示質心到輪廓邊緣最小值.
5) 運動速度R5, 即為質心單位時間內移動的像素距離. 質心的橫坐標是對象區域所有像素點橫坐標的平均值, 質心的縱坐標是對象區域所有像素點縱坐標的平均值. 通過質心可確定運動目標的位置,R5可判定目標的運動快慢.
6) 對象大小的變化速度R6=(Areak+1-Areak)-(Areak-Areak-1), 其中Areak表示第k幀目標區域的面積. 對于行駛的車輛, 由于外形具有穩定不變性, 所以R6趨于0; 而人在行走時伴隨形變, 所以R6值在正負間變化.
2.2 基于支持向量機的運動目標分析
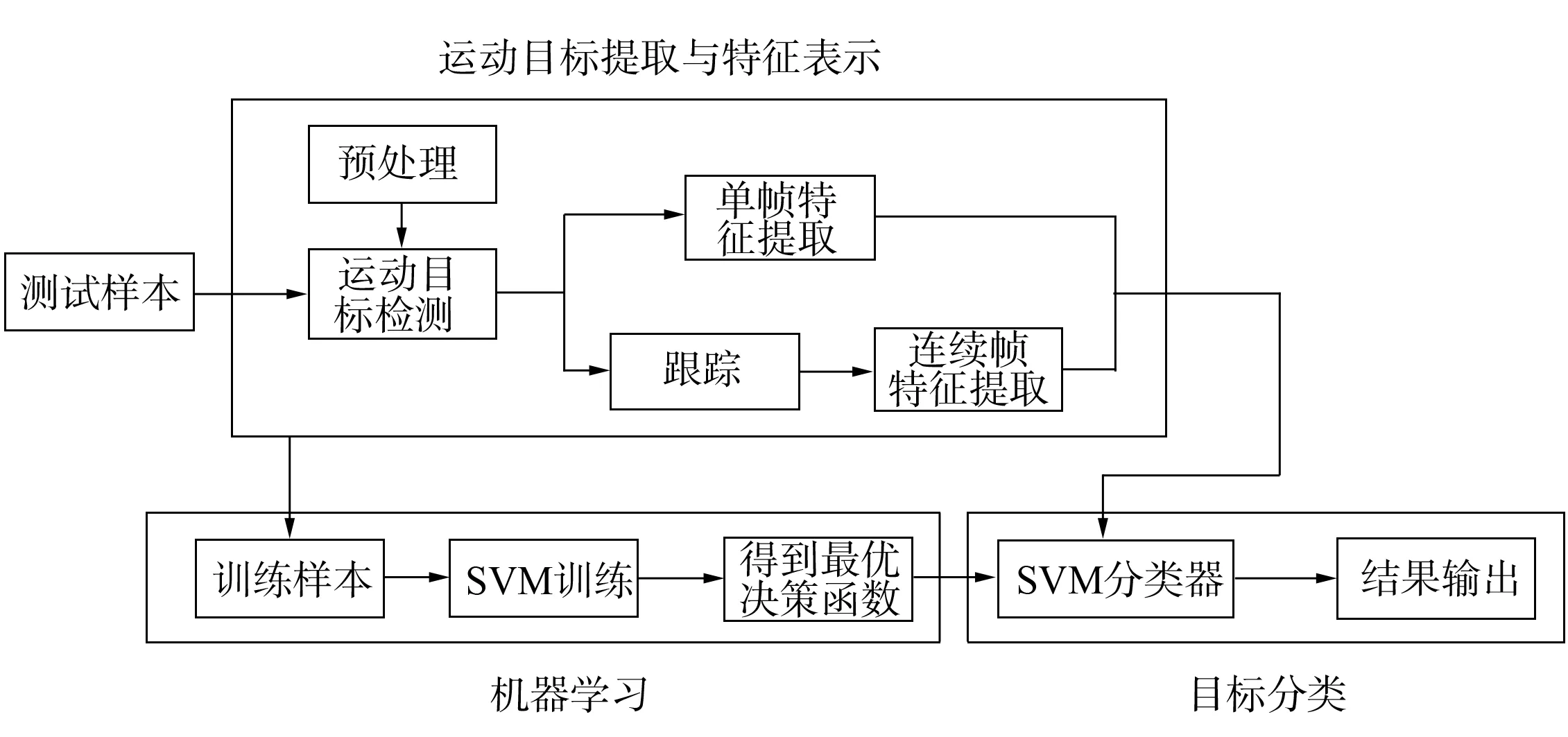
圖1 基于支持向量機的運動目標分類原理Fig.1 Support vector machine based moving target classification
基于支持向量機的運動目標分類原理如圖1所示. 由圖1可見, 在基于支持向量機的運動目標分析中可大致分為3個步驟: 運動目標提取與特征表示、 機器學習及做出最后的類別判定. 在運動目標提取與特征表示中, 通過使用混合Gauss模型進行背景更新, 先利用背景差減法提取運動目標, 再分別針對單幀和連續幀的運動目標提取特征向量(R1,R2,R3,R4,R5,R6); 在機器學習中, 用一組事先標記過的訓練集訓練支持向量機, 得到最優決策函數. 為了減小樣本集的規模, 采用自舉方式可以使樣本更具代表性, 從而提高分類器的訓練速度及分類的正確率; 最后利用訓練好的支持向量機對測試集進行運動目標的分類識別.
3 實驗結果與分析
實驗主要針對靜止單攝像機在普通戶外場景下目標多角度、 姿態多變化且含少量影子的運動目標, 使用訓練軟件Libsvm對其進行分類[10]. 為免去手工標注提高工作效率, 從14組視頻中抽取1 399張只含有單人或單車的圖片作為訓練樣本, 其中車輛圖片542張, 行人圖片857張. 本文選擇徑向基函數作為核函數, 并采用交叉驗證方法選擇懲罰因子C和核函數的參數g, 其值分別為14.928 52和6.062 87. 先利用這兩個最佳參數對選取的訓練樣本集進行訓練, 得到支持向量機模型, 再應用此支持向量機模型對選取的418張測試樣本進行類別判定. 測試正確率達到98.086 1%, 其中行人測試正確率為99.586 8%, 車輛測試正確率為96.022 7%. 圖2為原始圖像及其分類結果. 由圖2可見, 由于光線及前景顏色接近背景顏色等外界因素, 會出現運動目標輪廓變形的問題, 從而影響特征向量的提取而影響分類結果的正確率.

圖2 原始圖像(A),(B),(C)和分類結果(D),(E),(F)Fig.2 Original images (A),(B),(C) and classification results (D),(E),(F)
綜上可見, 本文提出的支持向量機在視頻運動目標分析中的應用, 能對車輛和行人作出較準確的分類. 在此基礎上可增加相應的特征向量, 對運動目標作出進一步的判斷, 如運動速度、 停留時間、 車型判斷及人行為分析理解等, 為智能監控的實現奠定基礎.
[1] Baidu. On 2010, Chinese Security Video Surveillance Equipment Industry Development Strategy and Competitive Strategy Analysis Report [R/OL]. [2011-11-30]. http://wenku.baidu.com/view/ebf2971ca300a6c30c229f9e.html.
[2] Ekpar F. A Framework for Intelligent Video Surveillance [C]//Proceedings of the IEEE 8th International Conference on Computer and Information Technology Workshops. Sydeny: IEEE, 2008: 421-426.
[3] Stauffer C, Grimson W E L. Adaptive Background Mixture Models for Real-Time Tracking [C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Fort Collins: IEEE, 1999: 2246-2252.
[4] Stauffer C, Grimson W E L. Learning Patterns of Activity Using Real-Time Tracking [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(8): 747-757.
[5] Pratt W K. 數字圖像處理 [M]. 李虹, 肖春虹, 李穎華, 等譯. 北京: 機械工業出版社, 2010: 428-430.
[6] Shapiro L G, Stockman G C. 計算機視覺 [M]. 趙清杰, 錢芳, 蔡利棟, 譯. 北京: 機械工業出版社, 2005.
[7] Lipton A, Fujiyoshi H, Patti R. Moving Target Classification and Tracking from Real-Time Video [C]//Proceedings of IEEE Workshop on Applications of Computer Vision. Princeton, NJ: IEEE, 1998: 8-14.
[8] Cortes C, Vapnik V. Support Vector Networks [J]. Machine Learning, 1995, 20: 273-297.
[9] YU Lin-sen, ZHANG Tian-wen, ZHANG Kai-yue, et al. Review of Indexing Methods for Image Retrieval [J]. Journal of Chinese Computer Systems, 2007, 28(2): 356-360. (于林森, 張天文, 張凱月, 等. 圖像檢索中的相似性判別及索引方法綜述 [J]. 小型微型計算機系統, 2007, 28(2): 356-360.)
[10] Chang C C, Lin C J. LIBSVM-A Library for Support Vector Machines [EB/OL]. [2011-10-14]. http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
