一種基于人工和機器學習相結合的教學網絡資源分類方法
2013-12-29 00:00:00許琦
中國信息技術教育 2013年12期

摘要:本文探討了教學網絡資源的分類方法,對如何應用人工與機器學習相結合的方法建立類別特征模型進行了研究。簡述了K最臨近分類法的基本思想。提出在領域專家的幫助下,采用人工的方法選取類別特征項,建立類別特征模型;在小樣本集環境下,采用機器學習的方法訓練類別特征項權重。并給出了教學網絡資源和類別特征模型匹配程度的計算方法。通過實驗,對所提出的分類方法的可行性和有效性進行了驗證。
關鍵詞:資源分類;K最臨近分類法;類別特征模型;機器學習
● 引言
為了實現教學網絡資源效用的最大化,必須對這些資源進行有效的組織管理。分類是教學網絡資源組織管理的重要方法。由于教學網絡資源多維性、動態性、交互性的特點,使得教學網絡資源分類體系缺少邏輯性和規范化,不能揭示資源之間的邏輯關系,主要體現在以下幾方面[1]:①類別設置缺少規律性。教學網絡資源分類中,其類別設置往往同時采取多個標準,每個標準在使用時又并不完整,有時甚至列出不同等級的類別,使得類別的設置顯得很混亂,缺乏邏輯性和規律性,從而影響用戶查找信息的效率。②類名不規范。有些類別有多個名稱,其歸屬也很隨意,不利于用戶的檢索。③類別沒有注釋或提示,用戶不能直接找到所需類別,必須逐級翻尋。
因此,有必要建立一個規范的分類體系,來組織管理教學網絡資源。
● K最臨近分類法概述
現有的分類方法主要包括以下幾種:K最臨近分類、決策樹歸納法、貝葉斯分類法、遺傳分類法等,各種方法分別適合不同的數據模型。[2]
K最臨近分類法(K Nearest Neighbor,KNN)是基于類比學習的方法。其基本思想是:類別樣本用n維數值屬性描述,每個樣本表示為n維空間的一個向量,這樣所有的類別樣本都存放在n維模型空間中,給定一個待分類資源,K最臨近分類法搜索模型空間,找出最接近待分類資源的k個類別樣本,待分類資源就被分配到k個最臨近樣本的最公共的類中。當k=1時,待分類資源被指定到模型空間中與之最臨近的類別樣本的類中。該方法的優點是容易實現和訓練快速,并且該方法的啟發性搜索是簡單的。同時也存在一些缺點,首先如果將所有的類別樣本都存起來,分類器就變得笨重并且反應變慢。其次,對于高維向量的資源,對分類起主要作用的維數遠遠低于資源本身的維數,相當多維對于資源分類意義不大甚至成為噪聲數據,這將增加分類的時間和空間復雜度。
● 分類方法
本文對K最臨近分類法做簡約化處理,取k=1,并對類別特征模型構建和分類算法做出如下改進。
1.類別特征模型構建
K最臨近分類法是通過搜索與待分類資源最臨近的(相似度最大)k個類別樣本來分類的,因此分類的準確程度很大程度上取決于類別特征項選取的合理性和分類算法的科學性。相關學者提出了許多選取類別特征項的方法:有的提出了基于CHI概率統計選取類別特征項的方法[3];有的提出了基于互信息差值選取類別特征項的方法[4];有的提出了基于正交質心算法選取類別特征項的方法。[5]這些方法的基本思想是為類別選擇一定數量51a2dd7ace0c6cd667456bd3b3d5ad4381220ed961ee6136af9f979b70812323的樣本,按一定的算法從樣本集中訓練得到類別特征項,建立類別特征模型,本質上是基于機器學習的方法。這些方法是從一定數量的樣本出發,而不是從類別層次出發來考慮類別特征項的重要性和價值的,因此訓練得到的類別特征項的權威性和合理性無法驗證。本文考慮將人工和機器學習結合起來構建類別特征模型。具體步驟如下:
(1)在領域專家的幫助下,采用人工的方法選取類別特征項。
在領域專家的幫助下,綜合考慮重要性、代表性、權威性、合理性等因素,人工選取類別特征項。考慮到不同的特征項對類別的貢獻是不一樣的,因此把類別特征項分為三部分:一級核心特征項、二級核心特征項和外圍特征項。其中,外圍特征項具有一定的類別特征信息,但不豐富;二級核心特征項含有比較豐富的類別特征信息;一級核心特征項含有最豐富的類別特征信息。通常情況下,外圍特征項占大部分,而一級、二級核心特征項只占其中的小部分。類別特征項以關鍵詞來表示,如下所示:
其中,Cj表示類別j,CjF、CjS和CjN分別表示類別j的一級核心特征、二級核心特征和外圍特征,kjFx、kjSy和kjNz分別表示類別j的第x個一級核心特征項、第y個二級核心特征項和第z個外圍特征項,l、n、m分別是一級核心特征、二級核心特征和外圍特征中特征項的個數,λf和λs分別是一級核心特征項和二級核心特征項的權重,由第二個步驟訓練得到。公式(2)則表示CjF、CjS和CjN互不包容。
(2)在小樣本集環境下,采用機器學習的方法訓練類別特征項權重。
設訓練集包含num個樣本,Tr={D1,D2,…,Dnum},權重向量λ=[λf, λs]T,最優權重向量為λbest=[λfbest, λsbest]T,權重增量(訓練步長)λa=[λa1, λa2]T,訓練集人工標定類別向量Vt=[t1,t2,…,tnum]T,訓練集分類結果向量Va=[a1,a2,…,anum]T,預測誤差為Eo,最小誤差為Emin,分類誤差為E,計算公式如下:
為了得到最優的λf和λs,在小樣本集環境下,訓練方法如下:[6]
(a)初始化: λ=[1, 1]T, λa=[1, 0.5]T, λbest=[1, 1]T, Eo=1, Emin=1, times=0;
(b)while (E o>0.05 or times<100)
(c) times++;
(d) Va=Class(Tr, λ); //調用分類函數對訓練集進行分類
(e) 按公式(3)計算分類誤差E;
(f) if (E< E o) λ=λ+λa;
(g) else λ=λ-0.5λa;
(h) End if
(i) Eo =E;
(j) if (Eo < Emin) {Emin =E; λbest =λ;}
(k) End if
(l) End while
訓練結束之后,λbest=[λfbest, λsbest]T就是得到的最優核心特征項權重。
2.分類算法
分類算法是計算待分類資源與類別的匹配程度(相似度),將待分類資源分配給與之最匹配的類別。那么資源分類則轉換為計算待分類資源與類別特征模型的相似度問題。待分類資源Di與類別特征模型Cj相似度計算公式如下:
相似度包括三部分:待分類資源與一級核心特征的相似度、待分類資源與二級核心特征的相似度以及待分類資源與外圍核心特征的相似度。
三者計算方法類似,因此這里只討論計算待分類資源與一級核心特征的相似度。
相似度計算公式如下:
該公式在計算Di與CjF兩個向量的余弦相似度的基礎上,引入特征權重λf以表征一級核心特征、二級核心特征和外圍特征不同的重要程度。
● 實驗驗證
1.實驗方法
為了檢驗所提出的分類方法的有效性,筆者以中國職業教育信息資源網(http://www.tvet.org.cn/)為實驗數據源,通過實驗進行驗證。從該網站的遠程教育、數字校園、精品教材、院校改革等欄目中下載了3213個樣本,以保證各欄目樣本分類正確。然后下載其他非欄目樣本400個,摻入欄目樣本中。實驗原始數據如下:遠程教育欄目489個樣本,數字校園欄目1203個樣本,精品教材欄目429個樣本,院校改革欄目237個樣本,名優設備欄目188個樣本,產業升級欄目31個樣本,企業創新欄目217個樣本,國際合作欄目52個樣本,國家戰略欄目94個樣本,地方行動欄目273個樣本,其他非欄目樣本400個。
2.性能評價指標
為了評價分類方法的性能,分類結果的統計數據一般采用關聯表來表示,如下表所示。其中,真正確tp(true positive)和真錯誤tn(true negative)表示分類正確的樣本數目,偽正確fp(false positive)表示被錯分為欄目類的非欄目樣本數目,偽錯誤fn(false negative)表示被錯分為非欄目類的欄目樣本數目。
網絡資源分類的性能評價可以參考信息檢索的性能評價指標:查全率(recall)和查準率(precision)。這種評價方法在自然語言處理研究中具有通用性。[7]
查全率定義為分類正確的樣本數量與該樣本數量的比值,反映了對分類方法某一類別的識別正確程度。
查準率定義為分類正確的樣本數量與分為該類別的樣本總數的比值,反映了分類方法對非欄目樣本的排斥能力。
此外,查全率和查準率還可以采用一個更全面的綜合度量尺度F測度(F Measure)。F測度定義為查全率和查準率的函數。
3.實驗結果
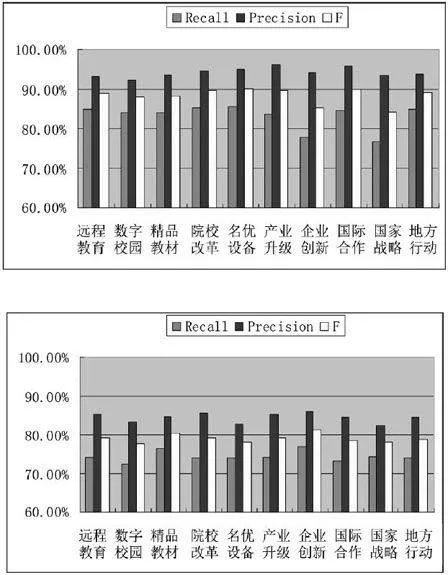
實驗樣本包括遠程教育、數字校園、精品教材、院校改革等欄目的3213個欄目樣本和400個非欄目樣本,特征空間總維度為100。實驗分別采用本文提出的分類方法(以下簡稱為方法1)和K最臨近分類法(以下簡稱為方法2)對3613個樣本進行分類,方法1和方法2的查全率、查準率和F測度等性能評價指標分別如圖1和圖2所示。
從圖1可以看出,和方法2比較而言,方法1具有較好的欄目識別性能和分類效果,各項性能評價指標均有一定程度的提高,其中各欄目的Recall基本上達到80%以上,Precision達到90%以上,F達到85%以上。在實驗中發現,個別欄目如企業創新、國家戰略等,分類效果欠佳,Recall、Precision等較低。分析表明,是由于建立類別特征模型時選取欄目特征項不夠科學造成的,即未充分考慮欄目特征項重要性、代表性、權威性和合理性等因素。因為這部分工作是由人工完成的,所以受主觀影響較大,爭取在以后的工作中對此加以改進。從總體上講,方法1達到了較好的分類效果,在一定程度避免了非欄目樣本的誤判所引起的欄目模糊效應。實驗表明,在行業網站中,尤其是門戶網站,本文提出的方法具有一定的應用價值。
● 結束語
針對教學網絡資源多維性、動態性、交互性的特點,本文提出了一種基于人工和機器學習相結合的分類方法。采納K最臨近分類法的基本思想,在領域專家的幫助下,綜合考慮重要性、代表性、權威性、合理性等因素,從類別層次出發人工選取類別特征項。在小樣本集環境下,通過機器學習的方法訓練類別特征項權重。在向量余弦相似度的基礎上,引入類別特征權重以表征一級核心特征、二級核心特征和外圍特征不同的重要程度,計算待分類資源與類別的匹配程度。最后通過實驗驗證得出:本文提出的分類方法具有較好的欄目識別性能和分類效果,查全率、查準率以及F測度等各項性能評價指標均有一定程度的提高。
參考文獻:
[1]張帆.信息存儲與檢索[M].北京:高等教育出版社,2003.
[2]方金城.分類挖掘算法綜述[J].沈陽工程學院學報,2006,2(1):73-76.
[3]錢曉東,王正歐.基于改進KNN的文本分類方法[J].情報科學,2005,23(4):550-554.
[4]胡鑫.中文文本分類的特征選取研究[J].甘肅科技,2006,22(5):119-120.
[5]余俊英,王明文,盛俊.文本分類中類別信息特征選擇方法[J].山東大學學報(理學版),2006,41(3):144-148.
[6]萬樂,劉萬春.類別特征詞權重加權文本分類方法[J].軍民兩用技術與產品,2006,(3):38-39.
[7]董寶力.Web制造資源的語義發現關鍵技術研究[D].博士學位論文,浙江大學,2006.
基金項目:浙江省哲學社會科學規劃課題“基于專利引證網絡的知識基因提取方法探索”(13NDJC19YBM),浙江省軟科學研究計劃項目“技術標準下提升企業自主創新能力——基于專利池的組建與管理”(2013C35064),臺州市哲學社會科學規劃課題“技術標準下面向自主創新的專利池構建與管理研究”(12GHB02),臺州市高校重點學科“機械制造及其自動化”(臺教高[2010]28號),臺州市教育科學規劃研究課題“網絡環境下基于VRML的虛擬機械加工實驗室建設探索”。
