語料庫輔助下英語作為外語目標語翻譯中的詞匯處理
2014-01-04 08:40:12王健燕
西華大學學報(哲學社會科學版) 2014年6期
王健燕
(桂林理工大學外國語學院 廣西桂林 541004)
翻譯是源語和目標語二者之間信息傳遞的交互過程,在這個過程當中,信息傳達是否準確有賴于譯者是否能對這兩種語言進行熟練的語碼轉換。“翻譯的過程不是線性的而是(譯者對源語和目標語)混合交錯的認知過程”[1]86。譯者能否在多個具有近似意義的外語目標語詞匯中做出符合源語語境的恰當選擇,將直接影響著譯文表述的地道與否以及翻譯質量的優劣。
翻譯是“在一定社會語境下發生的交際過程”[2]3,而“不同民族的語言,因物質環境和所處地域不同、社會文化的哲學淵源不同,因而也必然存在各自獨特的民族個性”[3]96。因此,語境是不同語言轉換過程中非常重要的參考因素。翻譯過程中的語境概念,不僅涉及源語和目標語的篇章語境,還應包括目標語的詞匯語境。前者是譯文是否忠實原文題材,話題類型的體現,后者是譯文目標語是否精準、地道的考量。
計算機處理技術的完善和語料庫語言學的蓬勃發展促生了“語料庫翻譯學”(Corpus Translation Studies),或者稱為“基于語料庫的翻譯研究”(Corpus-based Translation Studies)。語料庫翻譯學是“以語言理論和翻譯理論為研究指導,以概率和統計為手段,以大規模雙語真實語料為對象,采用語內對比與語際對比相結合的方法,對翻譯現象進行歷時或共時的描寫和解釋,探索翻譯本質的一種翻譯學研究方法”[4]4。因篇幅所限,本文將著重討論英語作為外語目標語在翻譯中的詞匯處理,尤其是英語語料庫在詞匯選擇方面所提供的輔助作用。
一、英語語料庫的歷史與發展現狀
早期英語語料庫的基礎資料完全來自于手工整理,1959年R.Quirk教授在倫敦大學學院(University College London)領隊成立了“Survey of English Usage”(SEU,英語使用調查)研究中心。這是當時歐洲第一個與語料庫相關的研究中心。后期SEU演變成為后來被世人熟知的倫敦-隆德語料庫(London-Lund Corpus,LLC)則得益于上世紀70年代中期瑞典Lund大學同行的計算機語料處理技術,該語料庫是第一個英語口語語料庫。
1964年由Francis和Kucera等學者共同努力在美國布朗大學建成的BROWN語料庫標志著電子語料庫時代的開始,也是現代語料庫語言學的開端。該語料庫由500篇書面文本構成,總計100萬詞次,是當時美國英語語料庫的代表。1978年英國語言學者、Lancaster大學教授G.Leech聯合挪威的Oslo大學和Bergen大學學者共同編制完成了LOB英國英語語料庫(Lancaster-Olso/Bergen Corpus of British English),其中包含了100萬詞次且是1961年前后的書面英式英語。
自上世紀80年代以來,隨著計算機技術的迅猛發展,語料庫建設的規模也越來越大,同時語料標注和檢索的手段也不斷更新,語料庫的分類也相應逐漸精細化,語料庫的應用領域隨之向更廣的領域延伸拓展。以美國Brigham Young大學的語料庫語言學教授Mark Davies創建的BYU在線語料資源庫系統為例,英語語料庫資源分為美國英語、英國英語、加拿大英語和世界英語等。其中,美國英語語料庫又包含了美國當代英語語料庫(COCA,4.5億詞次)、美國歷史英語語料庫(COHA,4億詞次)、《時代》雜志英語語料庫(Time Magazine Corpus,1億詞次)、美國電視劇英語語料庫(Corpus of American Soap Operas,1億詞次)等。世界英語語料資源來自于全球網絡英語語料(Global Web -Based English,GloWbE),共收集了來自于20個國家的互聯網英語語料,時間跨度為2012~2013年,高達19億詞次。
語料庫作為研究語言的工具最初并未得到學術界的廣泛認同,在轉換生成語法盛行時期,喬姆斯基認為語料只是外在化的話語匯集,語料只能對語言能力做出部分解釋,既不完整也不充分。因此,語料分析法在當時并未得到推行,人們在自然語言理解、生成、翻譯等研究中主要采用的方法是基于規則的(rule-based);而當計算機語言信息處理技術的發展促進語料庫規模的擴大,并在信息檢索、文本分析、信息過濾等方面取得飛速進步之后,人們利用大容量語料庫資源對自然語言所開展的研究則轉變為基于數據(data-based)。這些客觀的現實語料數據能夠揭示“真實語言使用的傾向性規律及其所傳遞的意義、功能乃至思想意識”[5]1,為語言研究提供富有說服力的證據,語料庫于是開始大規模地被運用于詞典、語法、文學、翻譯和教學等多個語言領域。
二、語料庫對英語作為外語目標語詞匯翻譯的輔助作用
詞匯是語言的基礎,而語言與文化密不可分,詞匯中自然也缺少不了文化內涵。詞匯文化往往突顯于詞義,即詞匯的顯性文化(explicitness),它是人們在經驗基礎上對客觀世界萬象和行為的提煉概括,具有很強的民族文化特征。除此之外,詞匯的內在語法特點,即詞匯的隱性文化(implicitness),也是詞匯文化的重要體現。這其中包括:一詞與它詞的搭配、詞在句中的語法位置、詞的語域范圍等。翻譯過程不可避免會涉及到源語和目標語在詞匯文化層面的差異和趨同問題,而忽略這一點,將很有可能造成原文和譯文在語碼轉換時的信息失真,有悖翻譯的最基本要求。源語和目標語之間的差異通常“不會以明顯不符合目的語語法規則的形式出現,而往往以多少有些異常的形式偏離語言使用的規范”[6]226,[7]16,這也可能造成譯文在目標語多方語境下可接受程度的大大降低。
Bowker認為,在對專業領域的理解、術語的準確選用及其習慣表達等方面,借助語料庫所完成的譯文比僅用傳統資源(如詞典等參考工具書)所完成的譯文質量更高[8]644-648,[9]52。考慮到目前語料庫的規模之大與語用真實等特點,目標語語料庫可以對翻譯過程中的詞匯選擇提供有力借鑒。譯者通過對目標語語料庫數據分析,可以將詞匯翻譯中的文化失真情況盡可能縮小至最低可控范圍內。例如,語料庫在漢語作為源語和英語作為目標語的翻譯中對最終目標語詞匯選擇所提供的輔助作用可從圖1中反映出來,而這一作用通常體現于對目標語語料庫所提供的英語詞匯隱性文化進行的數據分析。

圖1 英語語料庫輔助下翻譯過程中的詞匯處理
如前文所提到,外語詞匯的隱性文化特征是指導譯文遵循目的語語用規范的重要手段。在意義基礎之上,譯文所選擇用詞的詞頻(word frequency)、搭配(collocation)、語義韻(semantic prosody)等都是翻譯中跨文化信息傳遞正確與否的重要考量手段。而語料庫對英語作為外語目標語翻譯中詞匯處理的輔助功能也集中體現在這三個方面。
1.基于英語語料庫詞頻數據的詞匯處理
詞頻統計是語料庫最基礎最直觀的一項功能,因為“頻率是衡量語言結構可用性的概率特征”[10]424。所以,從語料庫提供的自然語料中詞匯使用頻率高低排列順序,可以推測英語母語使用者的詞匯選擇習慣。通常,詞頻數據可用于翻譯時對近義詞(短語)甚至詞匯句式用法選擇的考慮。一般情況下,近義詞匯、短語及句式的某些顯著特征差異可以從其詞頻高低中得到印證。雖然高詞頻未必是選詞的絕對標準,但確實可以支持真實語用背景下英語母語者的選擇傾向。
同時,英語語料庫數據收集編排的賦碼也可以展示不同語域(register)、語場(semantic field)環境中詞頻的分布狀況。不同的語域決定了詞匯頻率高低順序的差異。英語科學論文的翻譯和普通小品文的翻譯在用詞選擇上存在明顯不同,這就意味著譯者在翻譯不同文體時對多個近義詞(短語)的選擇不能隨心所欲。譯者將源語翻譯為英語目標語時,可以依據文本題材在英語語料庫中、相應的語域分類中以最簡單的詞頻檢索方法確定目標詞匯是否遵從英語為母語者的使用習慣。
英語語料庫不僅可以對單個詞匯(短語)的使用頻率進行排列統計,還能夠以該詞(短語)為中心,檢索分析其周邊的其它詞(短語)的出現頻率高低,于是詞頻的概念便擴大到了詞語的搭配。而語料庫也提供了更進一步的分析手段,即KWIC(語境關鍵詞)功能。
2.基于英語語料庫KWIC功能的詞匯處理
KWIC(Key Word In Context,語境關鍵詞)是英語語料庫檢索系統的一個很具實用性和可信度的重要數據庫。由于語料庫所收集的語料來自不同行業文本,因此,它提供了非常寬泛的真實語境范圍。語料庫通過設立關鍵詞檢索,在整個電子文本數據中,將以關鍵詞為中心按照預定跨距的所有共現詞在該句行語境下直接展示出來,重復出現頻率高的詞一目了然。從英語作為外語目標語翻譯中的詞匯處理角度來看,KWIC功能“對研究詞匯的語法關系、詞匯用法、詞匯搭配、詞叢(word cluster)、詞匯在連續語篇中呈現的范型(pattern)以及主題詞之間的意義關系提供了可靠的捷徑”[11]20,從而也支持譯者對譯文目標語詞匯做出更加合理的正確選擇。
以近義詞 conference(n.)和 meeting(n.)為例,在對“會議”一詞的英語翻譯用詞選擇時,可以使用KWIC這一功能對二者進行比較。在COCA(美國當代英語語料庫)中輸入conference(限定為名詞),設定關鍵詞跨距為左4詞和右4詞范圍(圖2)進行檢索,結果會在conference中心跨距范圍內以不同顏色代表不同詞性來呈現語境下的語用情況。按照譯文參考需要,還可以具體查詢到與conference共現的名詞、動詞、形容詞等,檢索結果也可以以詞頻列表顯示。以同樣的方法檢索meeting關鍵詞的語境共現詞之后,語料庫同樣能夠以詞頻數據顯示二者的用法差別(表1)。從表中結果也不難看出,在對待不同語境下“會議”一詞的英語翻譯處理時譯者應當如何做出選擇了。
圖2 COCA語料庫conference語境關鍵詞檢索條件(所有共現詞)
3.基于英語語料庫語義韻分析的詞匯處理
語義韻是基于語料庫KWIC功能基礎上對詞匯的再分析,同時也離不開詞頻統計。它呈現的是關鍵詞語境中的一種特殊的搭配現象,所體現的不僅是關鍵詞與共現詞之間的語義關系,而且還包括彼此之間的韻律關系。這種特定語義氛圍下的韻律關系大致可以分為積極的(positive)、中性的(neutral)和消極的(negative)三類[12]176,主要取決于其語場范圍內共現高頻詞的語義情緒。
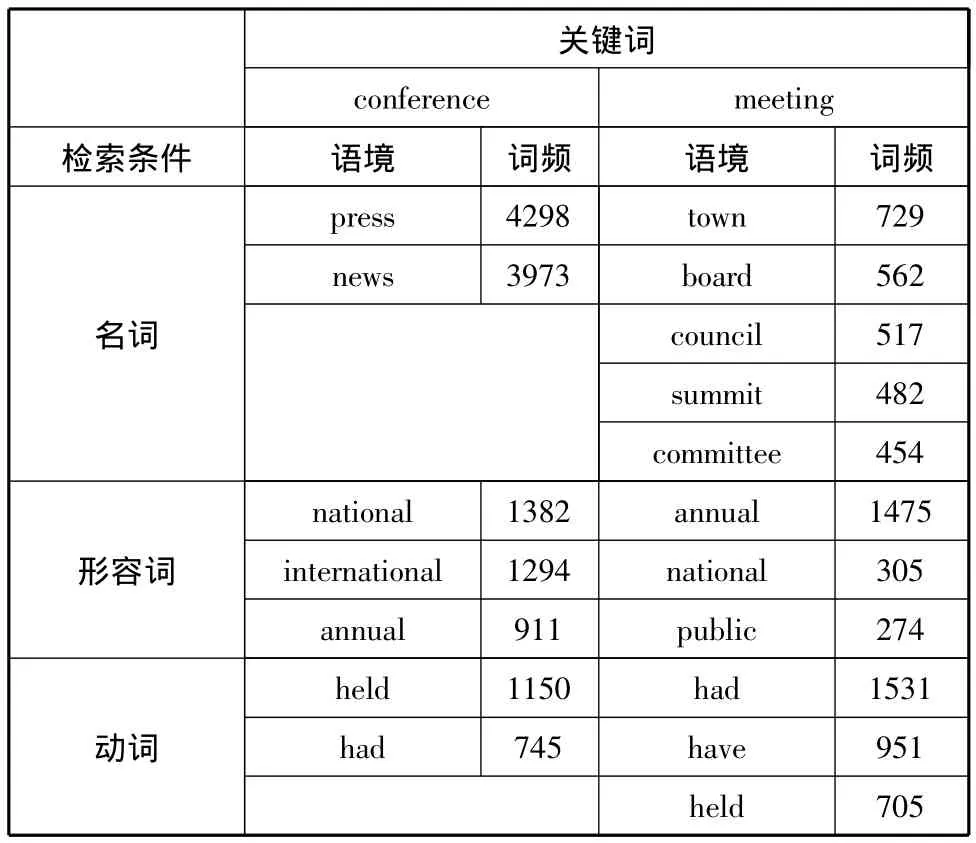
表1 conference和meeting的KWIC檢索結果(節選)
語義韻賦予了詞匯聯想意義,外語詞匯的聯想意義有時候并不能從詞典釋義中獲得。翻譯語碼轉換過程中,外語目標語詞匯的典型搭配如果被忽視的話,譯文的地道性便會大打折扣,甚至完全背離原文使得譯文完全不可接受。因此,語義韻揭示的是詞匯在其意義之外的語用功能。衛乃興[13]51在對中國學生英語調查研究中就曾指出,commit在COBUILD語料庫中,關鍵詞語境中顯著搭配詞有crime、offense、suicide、murder、abuse 等 14 個,具有明顯的消極語義特點;而中國學生雖然習得了commit的部分典型搭配,卻不能用該詞表達多種具體的“犯罪”意義。同樣,在英語作為外語目標語的翻譯中,詞匯的選擇處理不應該是盲目的語義匹配,而應該是基于對詞匯語用功能的分析而選擇。英語語料庫的語境關鍵詞功能和詞頻高低排序能夠突顯詞匯的典型搭配,在翻譯過程中為譯者在目標語的近義詞選擇、意義組合、語氣塑造等方面提供頗具價值的參考。
語料庫數據甚至可以對目標語詞匯的句法特點進行歸納,而且通常上述三類功能是共同發揮作用。例如,在翻譯“理由、原因”意義,對 cause和reason二詞進行甄別時,語境關鍵詞數據將揭示出cause語義韻接近消極,常與高頻消極語義詞death、disease、cancer、alarm、crash 等搭配,因此,在翻譯諸如此類的“緣由”時應當優先考慮cause。但同時對reason的搭配詞詞頻分析卻顯示出no、why、whatever排序靠前,結合KWIC分析可以得出結論:在處理否定句、why定語從句和“無論什么原因”等英語句式翻譯的時候,譯者則應當考慮reason。由此看來,語料庫對目標語詞匯的借鑒作用是多方位的。由于翻譯本身還涉及其它語言技能和翻譯技巧,盡管語料庫的任何一項功能所提供的語料分析是輔助的和參考性的,并不能作為翻譯時的唯一標準,但語料庫卻可以更有針對性地將譯文打磨得更加真實,從而進一步完善翻譯過程。
三、結語
現代英語語料庫的發展趨勢迅猛,其應用領域也不斷拓寬。英語語料庫與翻譯的相關研究包括了翻譯共性、翻譯文體、翻譯過程及應用研究等諸多方面。語料庫語言學的研究成果的使用不應局限于科學研究人員,而是任何從事翻譯實踐、進行翻譯教學的專家和學者都可以利用語料庫來輔助工作。詞匯是語言的基礎,也是從源語到目標語的翻譯活動中最基本的語碼要素。對譯文詞匯的選擇處理很大程度上決定了譯文的地道與否,從這個意義上來看,目標語語料庫對目標語翻譯貢獻頗大,語料庫以詞匯為基礎,其對翻譯研究的輔助作用也將不斷深化,影響也將不斷深遠。
[1] 唐文生.認知語言學理論與中國翻譯研究的回顧與前瞻[J].西華大學學報(哲學社會科學版),2011(2).
[2] Hatim,B.and Mason,I.Discourse and the Translation[M].London:Longman,1990.
[3] 張華琴.民族文化特征在英語習語翻譯中的體現[J].西華大學學報(哲學社會科學版),2008(3).
[4] 王克非.語料庫語言學探索[M].上海:上海交通大學出版社,2012.
[5] 何安平.語料庫語言學[J].中國外語,2012(5).
[6] Toury,G.In Search of a Theory of Translation[M].Tel Aviv:The Porter Institute for Poetics and Semiotics,1980.
[7] 王克非,胡顯耀.基于語料庫的翻譯漢語詞匯特征研究[J].中國翻譯,2008(6).
[8] Bowker,L.Using Specialized Monolingual Native-Language Corpora as a Translation Resource:A Pilot Study[J].Meta:Translators’Journal,1998(4).
[9] 楊曉軍.基于語料庫翻譯研究和譯者教育[J].外語與外語教學,2007(10).
[10] Goethals,M.E.E.T.:The European English Teaching Vocabulary-list[C]//B.Lewandowska-Tomaszczyk.Practical Applicationsin Language and Computers.Frankfurt:Peter Lang,2003.
[11] 李文中,濮建忠.語料庫索引在外語教學中的應用[J].解放軍外國語學院學報,2001(2).
[12] Stubbs,M.Text and Corpus Analysis[M].Oxford:Blackwell Publishers,1996.
[13] 衛乃興.基于語料庫學生英語中的語義韻對比研究[J].外語學刊,2006(5).
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
現代語文(2016年21期)2016-05-25 13:13:44
小學生導刊(低年級)(2016年2期)2016-02-24 23:02:11
大連民族大學學報(2015年2期)2015-02-27 08:28:11
小天使·五年級語數英綜合(2014年5期)2014-06-25 05:22:42
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
外語學刊(2011年1期)2011-01-22 03:38:33
