近紅外光譜結合化學計量學研究芝麻油的真偽與摻偽
2014-01-09 06:06:45武彥文李冰寧劉玲玲歐陽杰
中國糧油學報 2014年3期
楊 佳 武彥文 李冰寧 劉玲玲 歐陽杰
近紅外光譜結合化學計量學研究芝麻油的真偽與摻偽
楊 佳1,2武彥文2李冰寧2劉玲玲1歐陽杰1
(北京林業大學生物科學與技術學院食品科學與工程系林業食品加工與安全北京市重點實驗室1,北京 100083)
(北京市理化分析測試中心北京市食品安全分析測試工程技術研究中心2,北京 100089)
應用傅里葉變換近紅外光譜(FTNIR)結合化學計量學分別建立了芝麻油的真偽鑒別與摻偽定量的快速分析方法。真偽鑒別分別采用FTNIR結合主成分分析-簇類軟獨立模式識別(PCA-SIMCA)和偏最小二乘法-人工神經網絡(PLS-ANN),建立了芝麻油、大豆油、花生油、葵花籽油的分類模型。經過驗證,兩種分類模型的準確識別率均達到了100%。芝麻油中摻偽油的定量分析采用FTNIR結合PLS。通過采集不同比例的芝麻油-大豆油與芝麻油-葵花籽油二元系統的FTNIR譜圖,應用PLS分別建立二元系統定量分析模型并通過驗證集檢驗其可靠性,研究結果表明該模型可以準確預測芝麻油中10%~100%的摻假油,其預測值與實際值的相對標準偏差(SEP)分別為1.027(大豆油)和0.9660(葵花籽油)。
芝麻油 真偽鑒別 摻偽分析 近紅外光譜 化學計量學
芝麻油香味濃郁,營養豐富,深受我國居民青睞。然而,近年來市場上出現芝麻油摻入大豆油、葵花油等低價植物油,甚至用芝麻香精與低價植物油勾兌成假冒芝麻油的現象[1]。為了維護廣大消費者與合法商家的利益,盡快開發快速、準確的芝麻油真偽和摻偽分析方法非常必要。目前,分析芝麻油摻偽的方法主要有化學顯色法、紫外-可見分光光度法(UV-Vis)、傅里葉變化紅外光譜法(FTIR)、色譜法等等。化學顯色與UV-Vis類似,都是利用芝麻油中特征成分與顯色劑反應呈色進行定性定量分析[2],該方法操作簡單,適于快速檢測,但靈敏度較差,不能準確測定芝麻油的摻偽量。色譜法包括氣相色譜(GC)分析芝麻油的脂肪酸組分含量[3],以及高效液相色譜(HPLC)測定芝麻油中芝麻素等木質素類化合物的含量[4]等。由于摻偽芝麻油的脂肪酸組成與純芝麻油比較接近,芝麻油中芝麻素等成分的含量較低(μg/g),使得色譜法的分析難度較大,對分析條件和分析人員的要求也比較高。
近年來,隨著FTIR的不斷發展,FTIR在食用油脂定性鑒別與定量分析領域的應用越來越多[5-7]。針對芝麻油的摻偽分析,周志琴等應用近紅外(FTNIR)結合溫度微擾的二維相關光譜建立了大豆油、芝麻油、花生油等6種食用油的快速鑒別方法[8];范璐等[9]利用食用油脂的紅外特征峰 1 746、2 855、1 099、1 119 cm-1的比值建立了花生油、大豆油和芝麻油的鑒別方法;梁丹[10]應用 NIR與主成分分析(Principal Component Analysis,PCA)結合 BP人工神經網絡法(Artificial Neural Networks,ANN)建立芝麻油真偽的判別方法。這3種方法僅對食用油種類做出快速判定。在此基礎上,馮利輝等[11]采用FTNIR結合偏最小二乘法(Partial Least Square,PLS)建立了芝麻油中菜籽油摻偽量的測定方法,該方法可以對10%的菜籽油準確定量。本試驗提出將芝麻油定性鑒別與定量測定相結合,即利用FTNIR分別結合簇類軟獨立模式(Soft Independent Modeling of Class A-nalogy,SIMCA)、ANN和PLS建立芝麻油真偽判別與摻偽量的快速分析方法。
1 材料與方法
1.1 樣品來源與制備
芝麻油(36種)、大豆油(30種)、葵花籽油(22種)和花生油(16種)純品均由北京市糧油檢定所提供。分別配制芝麻油中摻入不同大豆油或葵花籽油比例的二元摻偽油,其中大豆油或葵花籽油的質量分數分別為3%~100%(體積分數)共102個(分別51種)。
1.2 儀器設備與參數設置
Spectrum 400型傅里葉變換紅外光譜儀:美國Perkin Elmer公司;DTGS檢測器,光譜范圍為10 000~4 000 cm-1,分辨率8 cm-1,掃描信號累加次數為64次,掃描時扣除了水和二氧化碳的干擾。
1.3 試驗過程與數據處理
1.3.1 紅外光譜分析
紅外光譜獲得:取樣品約1 mL置于光程為1 mm石英比色皿中,透射法掃描獲得FTIR譜圖,每個樣品至少掃描3次。數據處理包括建立定性分類和定量分析。
1.3.2 定性分析
定性分類是指對芝麻油與非芝麻油的分類識別。分別采用了PCA-SIMCA和PLS-ANN 2種方法建立分類模型。PCA-SIMCA模型采用Spectrum與Quant+軟件分析建立。首先通過PCA分析樣本的光譜數據矩陣,提取特征變量,在此基礎上,分別選取芝麻油(28個)和大豆油(20個)、葵花籽油(16個)和花生油(14個)組成訓練集,建立PCA分類方法;然后,應用SIMCA對上述訓練集譜圖進行分類識別,建立芝麻油的FTNIR-SIMCA的分類鑒別模型;最后通過驗證集(其余的8個芝麻油、10個大豆油、6個葵花籽油和2個花生油)依據正確識別率驗證該模型的可信度。
PLS-ANN模型采用NIRSA analyst Ver 3.0軟件分析建立。首先,將芝麻油等104個樣品的FTNIR譜圖導入軟件,隨機選取78個樣品組成訓練集,剩余26個樣品組成驗證集(樣品分類與PCA-SIMCA相同)。然后,比較不同預處理方法的保留相關系數(R2)、校正集(或訓練集)標準偏差(SEC)和預測集標準偏差(SEP)的數值,以R2接近1,SEC與SEP的值接近0為優。在此基礎上,通過PLS分析處理樣本的光譜數據進行主成分壓縮和降維提取主成分數,并將此作為ANN的輸入層,依次設定參數(隱含層,輸出層,訓練步長,訓練次數等),多次試驗,確定定性分析模型。最后通過比較驗證模型實際輸出值與期望輸出值的偏差,參考軟件自動分類范圍,得出模型預測分類結果。
1.3.3 定量分析
采用Quant+軟件中的PLS建立芝麻油-大豆油和芝麻油-葵花籽油的二元混合物的定量分析模型。首先,將二元混合物樣本的紅外譜圖導入軟件,并輸入對應樣本的實際摻偽含量。然后比較不同預處理方法R2、SEC和SEP的數值,反復試驗,確定光譜的預處理方式以及消除異常點后,其中,隨機選取40個樣品(3%~100%)作為校正集,剩余11個樣品作為驗證集,采用交互驗證的方法確定最佳主因子數,利用PLS分析得到定量分析模型。
2 結果與討論
2.1 植物油的近紅外光譜圖
圖1是大豆油、花生油、芝麻油和葵花籽油的近紅外光譜圖。其中,9 000~8 000 cm-1的譜峰是油脂中—CH2—、—CH3和—═CH CH—的第2組合頻;7 500~6 500 cm-1為油脂中—CH2和—CH3的二級倍頻;6 500~5 500 cm-1內的吸收峰為—CH2—,—CH3和—═CH CH—等官能團的第1組合頻;5 000~4 500 cm-1范圍的譜峰是順式雙鍵的組合頻,其峰強隨不飽和度的增加而增大[12-13]。由圖1可見,上述4種植物油的FTNIR譜圖極為相似,它們在8 267、7 074、5 795、5 678、4 663、4 592 cm-1附近均出現相似的—CH2—,—CH3和—═CH CH—等振動吸收峰。這與食用植物油組成均為多種脂肪酸三酰甘油混合物的化學組成相符[14],因此,僅僅通過直觀比較譜圖是很難區分食用油的種類,必須借助化學計量學等數學處理方法進行分類鑒別。
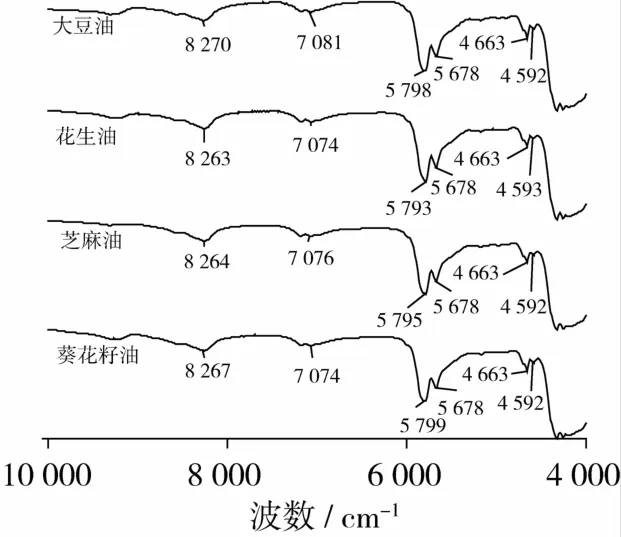
圖1 芝麻油、大豆油、花生油和葵花籽油的近紅外譜圖
2.2 真偽鑒別分析
2.2.1 SIMCA分類模型的建立
SIMCA是一種有監督的模式識別方法,一般由4個步驟組成,包括:1)樣本光譜數據的收集,采用常規方法對樣本進行鑒別分析;2)光譜圖的預處理,如取導數和標準化處理等;3)特征變量的提取,一般常用PCA和因子分析方法;4)SIMCA方法建立分類模型,并檢驗模型的可信度。通常,人們將不同樣本的分子光譜數據經過模式識別進行樣品的類別和質量等級的定性分析[15]。近年來,應用紅外光譜結合SIMCA建立分析方法的研究逐漸增多[16-18],但應用FTNIR結合SIMCA建立鑒別芝麻油真偽的方法還鮮見報道。
2.2.1.1 譜圖處理
由于采集的FTNIR光譜受到高頻隨機噪聲、基線漂移、樣品不均勻、光散射等影響,需要進行光譜預處理來消除噪聲以提高譜圖的分辨率。常用的光譜數學預處理方法主要有一階求導、二階求導、多元散射校正(MSC)、矢量歸一化(SNV)等[19]。通常,一階導數可以校正基線的平移變化,二階導數可以校正基線的傾斜變化,對于混合物紅外光譜來說,導數光譜的重要意義在于分辨重疊峰,提高譜圖的分辨率。此外,對于由樣品顆粒散射等因素導致譜圖基線發生平移、吸收峰強度成比例改變的情況,可以采用MSC進行處理。SNV是針對每個樣本的譜圖分別校正,將每一個樣品的光譜數據進行標準正態化。SNV經常與De-trending算法一起使用,一般認為其校正效果要優于MSC。本文在經過多次嘗試,采用二階求導(13點)和SNV預處理方法,選擇了8 000~4 000 cm-1范圍的譜圖進行分析模型的建立。
2.2.1.2 主成分分析
以芝麻油和大豆油、花生油和葵花籽油為變量,將采集樣品的譜圖轉化為數據矩陣,用PCA方法將所有光譜數據進行數據壓縮,提取主成分得分數。以PC1和PC2得分分別作為橫縱坐標繪制4種植物油品的二維得分圖(圖2),圖中字母k代表葵花籽油、d代表大豆油、h代表花生油、z代表芝麻油,數字代表該油脂的編號。由圖2可見,4種油的分布具有一定的聚類特性,同一類樣品基本可以聚集在相同的區域,在PC1上的分布差別較大,分布范圍分別是:-0.18~-0.08(葵花籽油),-0.08~-0.02(大豆油),0.00~0.08(芝麻油)及0.12~0.22(花生油)。
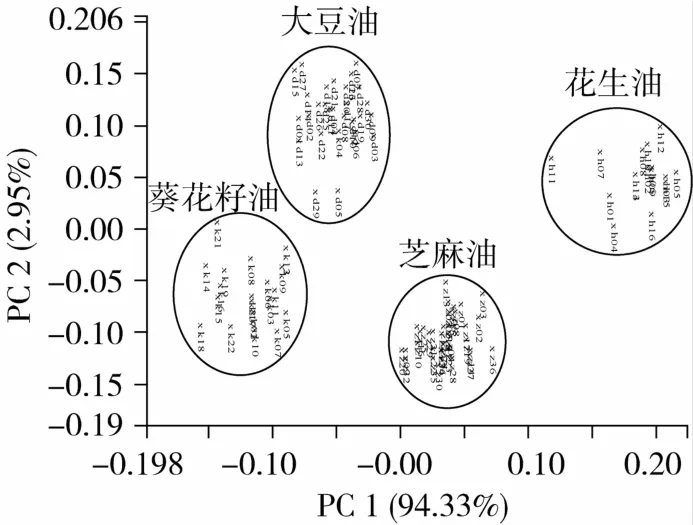
圖2 芝麻油、大豆油、花生油和葵花籽油的PCA得分圖
2.2.1.3 SIMCA模型建立與鑒別分析
為了精確建立芝麻油與其他植物油的分類識別模型,根據1.3.2節的方法,在PCA分析的基礎上,分別隨機選擇28個芝麻油,20個大豆油、16個葵花籽油和14個花生油組成訓練集,選取8 000~4 000 cm-1范圍的光譜圖,進行分析建立PCA分類模型;在此基礎上應用SIMCA建立芝麻油和非芝麻油兩類樣本的識別模型(圖3)。將余下的8個芝麻油與18個其他植物油共26個樣本作為驗證樣本,用來檢驗模型的可靠性(圖4)。
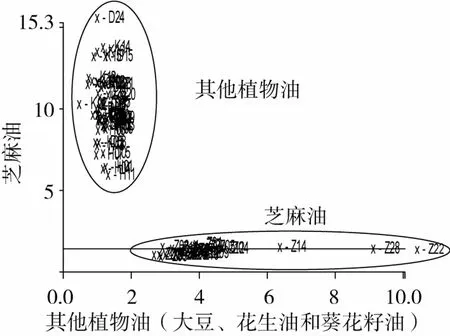
圖3 芝麻油與其他植物油的SIMCA分析結果
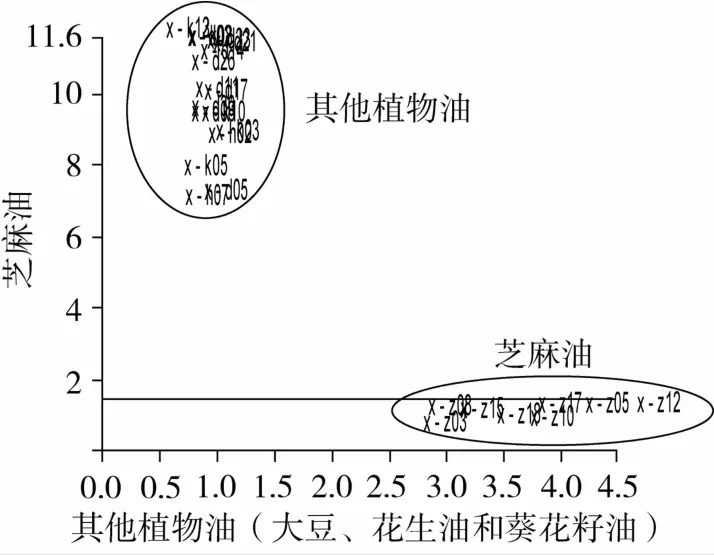
圖4 芝麻油與其他植物油的SIMCA分類識別模型
由圖3可以看出芝麻油與其他3種植物油之間沒有重疊,互不干擾,聚類結果比較理想。一般,我們可以通過類間距(Inter Material Distances)來評價FTNIR-SIMCA模型的分類識別效果,類間距是兩類(或幾類)樣本聚類中心之間的距離,類間距的數值越大表明樣本類與類之間的差異越明顯,則SIMCA模型的分類識別效果越好[20]。文中的真偽芝麻油的類間距為33.41,這個數值較大,說明基于食用植物油訓練集建立的NIR-SIMCA模型的分類識別效果較好。此外,識別率(Recognition rate)與拒絕率(Rejection rate)是反映類模型之間聚類可信度的常用指標。當兩個值都為100%時,表明兩類樣品之間沒有重疊,可以較好的將其聚類分開[20]。圖4為真偽芝麻油的SIMCA分類驗證模型,結果表明:兩類油品的正確識別率和拒絕率均為100%。一般來說,如果一個模型的正確識別率如果能達到60%以上,就說明該模型可行[21]。因此,本研究建立的真偽芝麻油的NIR-SIMCA分類識別模型基本可行。
2.2.2 ANN定性判別模型的建立
ANN算法是一種非線性建模方法。一般,ANN模型選用3層或3層以上的神經網絡,即輸入層,隱含層,輸出層。在ANN的應用過程中,常采用PCA或PLS法對光譜數據降維,獲得主成分得分并作為網絡的輸入變量。在建立ANN的過程中,需要確定一系列參數,如隱含層的節點數,輸入層到隱含層、隱含層到輸出層的初始權重,隱含層、輸出層的傳遞函數,學習速率、動量等。根據傳遞函數并按照一定的學習規則自動調節網絡各層之間的連接權重,進行迭代,以使得網絡的實際輸出值與期望輸出值相比達到一定的精度要求[22]。
2.2.2.1 譜圖處理與參數設置
按照1.3.2對芝麻油等4種植物油的FTNIR譜圖數據依次運用二階求導和中心化處理進行譜圖預處理,并選擇10 000~4 000 cm-1范圍的譜圖進行ANN分析模型的建立。
ANN建模過程中,選擇合適的PLS主成分作為神經網絡的輸入變量,可以減小神經網絡規模,降低訓練時間;而且可以充分利用原始光譜圖中的有用信息,剔除噪聲。本試驗將采集樣品的所有譜圖轉化為數據矩陣,應用PLS法對所有光譜數據進行數據壓縮,發現其中前4個主成分的累積貢獻率為98.37%,確定每張譜圖可以只需用前4個主成分代替,因此,設置ANN的輸入層節點數為4。當輸入層節點數確定后,其他參數不變,選擇隱含層節點數范圍,當隱含層節點數目為15,SEP為最小。網絡輸出層輸出一個預測的結果,故輸出層為1。考慮網絡穩定性,按照從小到大的順序選擇訓練速度,當最小訓練速度設為0.025,預測誤差達到最小。其中,動態參數取0.95,允許誤差設為0.001,最大迭代次數設為10 000次。
2.2.2.2 建立人工神經網絡ANN模型
選取28個芝麻油,20個大豆油、16個葵花籽油和14個花生油,共78個樣品作為校正集,剩余的26個樣品作為預測集。建模時,將大豆油、葵花籽油、花生油和芝麻油分別賦值為1、2、3、4;根據軟件自動分類結果,預測得到的數值范圍為:0.4~1.4為大豆油,1.6~2.4為葵花籽油,2.6~3.4為花生油,3.6~4.4為芝麻油。78個建模集的均方估計殘差(RMSEC)值為0.111 4。該模型經過對26個未知樣品進行預測,結果準確率為100%(表1),表明利用PLSANN法建立真偽芝麻油的鑒別模型是可行的。
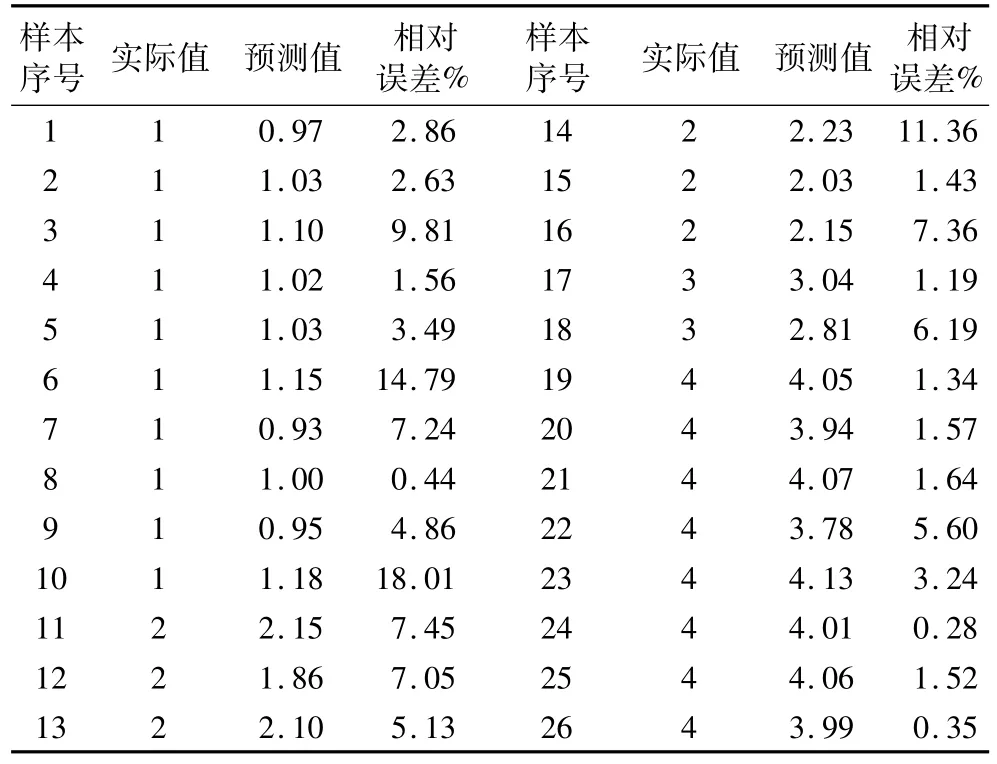
表1 人工神經網絡ANN對預測集樣品的識別結果
綜上,本試驗分別運用PCA-SIMCA以及PLSANN 2種分析法建立了芝麻油與其他植物油的分類模型,兩個模型驗證結果的準確率均為100%,表明兩種方法均可用于真偽芝麻油的定性檢測分析,可能成為快速鑒別芝麻油真偽的一種新方法。
2.3 定量分析
PLS通過因子分析將光譜數據壓縮為較低維的空間數據,該方法是將光譜數據向協方差最大的方向投影。與傳統多元線性回歸模型相比,PLS的特點是:1)能夠在自變量存在嚴重多重相關性的條件下進行回歸建模;2)允許在樣本點個數少于變量個數的條件下進行回歸建模;3)PLS在最終模型中將包含原有的所有自變量;4)PLS模型更易于辨識系統信息與噪聲(甚至一些非隨機性的噪聲);5)在PLS模型中,每一個自變量的回歸系數將更容易解釋。所以,PLS是一種具有較好發展前景的新型數據處理方法[23]。
2.3.1 芝麻油-大豆油二元體系定量模型的建立
按照1.3.3輸入不同比例的芝麻油-大豆油二元混合物的FTNIR譜圖與其對應的濃度,應用PLS進行分析處理,通過比較模型的R2、SEC數值確定譜圖的處理方法。結果表明:譜圖采用SNV結合Detrending算法,以及Offset基線校正處理,經過消除異常點,選擇主因子數為10,可以建立芝麻油中大豆油含量的PLS分析模型,該模型經過驗證,其R2值為0.999 4,SEP為1.027(圖5a)。該模型可以預測的最低質量分數為10%,此時相對誤差小于10%。表明FTNIR結合PLS可以快速分析摻入芝麻油中大豆油的含量。
2.3.2 芝麻油-葵花籽油二元體系定量模型的建立
同2.3.1,將FTNIR與PLS結合應用于芝麻油-葵花籽油二元體系的定量分析中,結果表明:采用SNV結合De-trending算法處理后,消除異常點,選擇主因子數為13,能夠建立芝麻油-葵花籽油的PLS定量分析模型。該模型經過驗證,其預測值與實測值的相關性較好,R2為0.999 7,SEP為0.966 0。該模型對大于10%的葵花籽油預測效果良好。
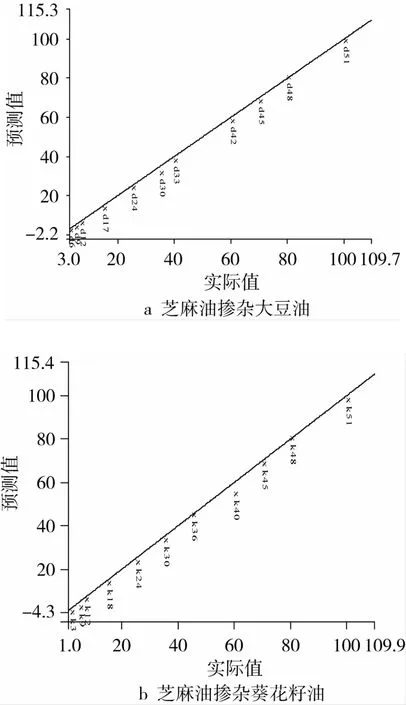
圖5 實際值與預測值的PLS驗證模型
3 結 論
根據近年來出現的芝麻油摻假現象,運用FTNIR結合化學計量學方法對芝麻油真偽鑒別與其中摻偽油的含量分析進行了研究。首先分別運用PCA-SIMCA以及PLS-ANN建立了針對芝麻油的兩種分類識別模型,經過驗證,這2種模型的正確識別率均達到100%。說明運用近紅外光譜能夠完成芝麻油的快速鑒別。進一步地,運用FTNIR結合PLS建立了芝麻油中大豆油和葵花籽油的定量分析模型,該模型可以對芝麻油中10%的大豆油或葵花籽油進行準確定量。本研究表明FTNIR結合化學計量學可以為油脂摻假提供一種快速、準確的分析方法。
[1]任小娜,畢艷蘭,楊國龍,等.散裝芝麻油品質檢測及摻偽分析[J].中國糧油學報,2011,26(11):106-109
[2]李凝.芝麻油質量現狀及摻假檢檢方法的探討[J].化學分析計量,2011,20(3):99-101
[3]林麗敏.氣相色譜法測定芝麻油摻偽的研究[J].糧食儲藏,2006,35(3):43-51
[4]孫榮華,何良興,李崗.芝麻油特征成分檢測及防偽技術的研究[J].中國衛生檢驗雜志,2010,20(1):49-60
[5]Rodriguez-Saona L E,Allendorf M E.Use of FTIR for rapid authentication and detection of adulteration of food[J].Annual Review of Food Science and Technology,2011,2:467-483
[6]褚小立,許育鵬.用于近紅外光譜分析的化學計量學方法研究與應用進展[J].分析化學,2008,36(5):702-709
[7]Costa Pereira A F,Coelho Pontes M J,Gambarra Neto F F,et al.NIR spectrometric determination of quality parameters in vegetable oils using iPLSand variable selection[J].Food Research International,2008,41:341-348
[8]周志琴,陳斌,顏輝.二維相關近紅外光譜快速鑒別食用植物油種類[J].中國糧油學報,2011,26(9):115-118
[9]范璐,王美美,楊紅衛,等.傅里葉變換紅外吸收光譜識別五種植物油的研究 [J].分析化學,2007,35(3):390-392
[10]梁丹.應用近紅外光譜分析判別芝麻油摻偽的研究[J].食品工程,2011(2):40-43
[11]馮利輝,劉波平,張國文,等.芝麻油中摻入菜籽油的近紅外光譜研究[J].食品科學,2009,30(18):296-299
[12]Hourant P,Baeten V,Morales M T.Oil and fat classification by selected bands of near-infrared spectroscopy[J].Applied Spectroscopy,2000,54:1168-1174
[13]李娟,范璐,鄧德文,等.近紅外光譜法主成分分析6種植物油脂的研究[J].河南工業大學學報,2008,29(5):18-21
[14]畢艷蘭.油脂化學[M].北京:化學工業出版社,2005
[15]禇小立.化學計量學方法與分子光譜分析技術[M].北京:化學工業出版社,2011:95
[16]楊忠,江澤慧,費本華,等.SIMCA法判別分析木材生物腐朽的研究[J].光譜學與光譜分析,2007,27(4):686-690
[17]于春霞,馬翔,張曄暉,等.基于近紅外光譜和SIMCA算法的煙葉部位相似性分析[J].光譜學與光譜分析,2011,31(4):924-927
[18]李娟,范璐,畢艷蘭,等.紅外近紅外光譜簇類的獨立軟模式方法識別植物調和油脂[J].分析化學,2010,38(4):475-482
[19]劉波平,榮菡,鄧澤元,等.近紅外光譜-BP神經網絡-PLS法用于橄欖油摻雜分析[J].分析測試學報,2008,27(11):1147-1150
[20]徐榮,孫素琴,劉友剛,等.基于PLS-自組織競爭神經網絡近紅外光譜技術對鮮乳和摻假乳的檢測方法研究[J].光譜學與光譜分析,2009,29(7):1860-1863
[21]孫素琴,湯俊明,袁子民,等.紅外光譜與聚類分析法無損快速鑒別肉蓯蓉[J].光譜學與光譜分析,2003,23(2):258-261
[22]劉名揚,趙景紅,孟昱.道地山藥紅外指紋圖譜和聚類分析的鑒別研究[J].吉林大學學報,2007,45(5):849-852
[23]耿響.二維紅外光譜分析技術在食用植物油品質檢測中的應用研究[D].鎮江:江蘇大學,2010:55-61.
Fourier Transform Near Infrared Spectroscopy in the Authentication and Adulteration of Sesame Oil
Yang Jia1,2Wu Yanwen2Li Bingning2Liu Lingling2Ouyang Jie1
(Department of Food Science and Engineering,College of Biological Sciences and Technology,Beijing Forestry University1,Beijing 100083)
(Beijing Center for Physical and Chemical Analysis,Beijing Engineering Research Center of Food Safety Analysis2,Beijing 100089)
The rapidly analytical method has been established by Fourier transform near infrared spectroscopy(FTNIR)combined with chemometrics for the authenticity and quantity of sesame oil.FTNIR was combined with two types of authentication and recognition model to classify the sesame oil,soybean oil,peanut oil and sunflower oil by means of principal component analysis-soft independent modeling of class analogy(PCA-SIMCA)and partial least squares-artificial neural network(PLS-ANN)respectively.The results of two models are validated to be the correct recognition rate of 100%.FTNIR with PLS is used to quantify the adulterated sesame oil.Sesame oil with different proportions of soybean oil and sunflower oil were collected.FTNIR spectra PLSis used to establish the model of quantitative analysis for testing its reliability through the validation set.The model can accurately predicts the sesame oil with 10%to 100%adulterated oil.the square error of prediction is 1.027(soybean oil)and 0.966 0(sunflower oil),respectively.
sesame oil,adulteration,NIR,chemometrics
TS227
A
1003-0174(2014)03-0114-06
國家自然科學基金(30701107),北京市自然科學基金(710 2021)
2013-03-20
楊佳,女,1988年生,碩士,農產品加工及貯藏工程
歐陽杰,男,1971年生,副教授,食品加工與質量安全
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
