基于標簽與協同過濾算法的淘書吧應用
2014-01-15 10:00:58張建明
電子設計工程 2014年23期
徐 彬,張建明
(江蘇大學 江蘇 鎮江 212013)
協同過濾(Collaborative Filtering,CF)由 Goldberg 等人[1]在1992年提出并首次應用在研究郵件推薦模型Tapestry中。協同過濾推薦算法的核心思想是利用用戶的歷史信息,計算用戶之間的相似性;利用與目標用戶相似性較高的用戶對其他產品的評價來預測目標用戶對特定產品的喜好程度;根據喜好程度來對目標用戶進行推薦。協同過濾又可分為兩種:基于用戶的協同過濾和基于商品的協同過濾。協同過濾算法的基本思想是找到與該用戶行為最相似的其他用戶,通過其他用戶的行為來預測該用戶的行為,并提出了k最近鄰的思想[2]。本文還將標簽屬性加入到推薦算法中,將具有相同標簽的書籍進行分類,使得內容之間的相關性和用戶之間的交互性大大增強[3]。協同過濾方法已成為電子商務中非常重要的一種推薦方法。國外用到協同過濾方法比較著名的網站有亞馬遜的網絡書店,通過記錄購買的商品以及對商品的評分還有瀏覽過的商品來判斷您的興趣,然后與其他用戶的購買行為進行比較,從而進行相似度的分析,最后推薦商品。而國內比較著名的有淘寶,當當,京東商城。他們利用改良后的協同過濾算法,將一系列可能滿足要求的商品推薦給用戶,以便用戶的篩選,將用戶體驗做到極致,為網站帶來了大量的流量。原有的協同過濾只依賴于用戶對項目的評分矩陣,對于各種特定的應用都有較好的適用性,但它也存在一些難以完全解決的問題,如新用戶問題、數據稀疏性問題及可信問題等[4]。
文中提出了一種將標簽集成到推薦系統的方法,首先對標簽進行預處理,然后構建用戶-商品評分矩陣,最后將標簽混合至用戶-商品評分矩陣的協同過濾推薦算法中。本文的貢獻如下:1)提出了通用的標簽預處理方法;2)通過標簽預處理減少推薦過程中同義標簽的計算,從而提高了推薦算法的性能;3)提出了一種改良后的協同過濾方法,該方法可以利用用戶、產品和標簽之間的三維關系,提高推薦系統的準確性。
1 基于標簽的協同過濾推薦算法
1.1 算法描述
1)根據用戶對商品的評分,建立用戶-商品評分矩陣。
2)對標簽進行預處理,整理商品與標簽之間的關系。
3)根據商品-標簽的評分矩陣來計算商品之間的相似度,確定商品的最近鄰,建立物品的協同過濾評分矩陣。
4)綜合商品-標簽評分矩陣和協同過濾方法來計算預測評分值。
5)按照排名先后將評分值最高的N個商品推薦給用戶。
1.2 用戶-商品評分矩陣C(m,n)
在矩陣C(m,n)中,其中m行代表m個用戶,n列代表n個評分商品,元素Cij表示用戶i對商品j的評分。該方法中用1,2,3,4,5離散值表示對該商品的偏愛度。值越大表示用戶喜愛程度越高。
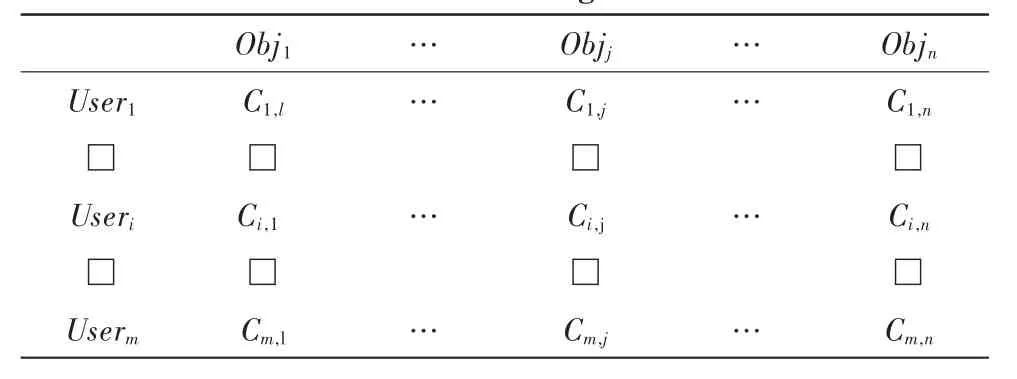
表1 用戶評分矩陣Tab.1 User rating matrix
1.3 商品-標簽評分矩陣
1.3.1 標簽處理
不同類型的商品通過分類將其區別。相同分類下的商品,我們通過設定不同的標簽,將有聯系的主從關系的商品聯系在一起。同一種商品可以使用多個標簽,同一個標簽也可以使用多個商品。商品和標簽之間是多對多的關系。我們通過這種復雜的關系,再結合用戶瀏覽和購買過的商品所屬的標簽。這很少一部分的標簽是頻繁用到的,而這些少量頻繁標簽集合也是穩定的[5]。根據用戶與標簽的關系,將用戶—標簽構成一個二部圖,如圖1所示。本系統使用SimRank算法計算商品之間的相似度。
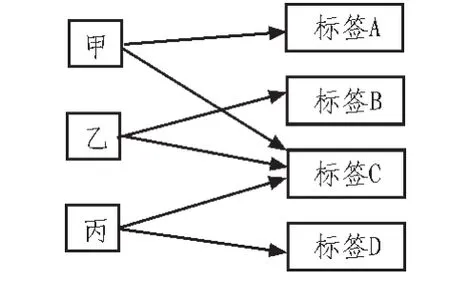
圖1 用戶標簽二部圖Fig.1 User tags bipartite graph
SimRank算法是在2002年提出的,為了衡量結構性上下文(structural-context)的相似性[6]。SimRank算法的根本就是:相似與同一個物品的兩個或兩個以上物品之間也存在相似性。
基于SimRank算法,我們假定:如果相同或相似的標簽都適用于兩個用戶,則這兩個用戶就存在相似性。構造如圖1,標簽集合NT和用戶集合NU,如果用戶甲和標簽A之間存在聯系,則用有向線段連接用戶甲與標簽A。它們之間的相似性按如下公式計算:
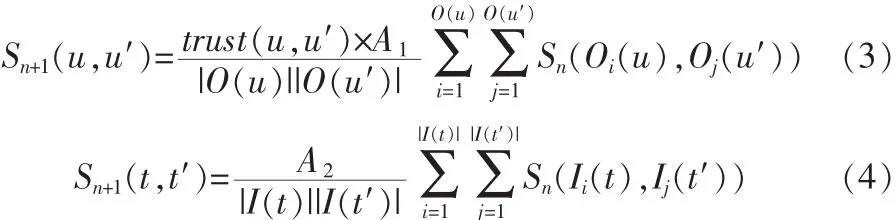
公式中:u′∈Ut,trust(u,u′)表示用戶 u 與 u′的信任度;O(u)表示用戶u的出鄰居集合,即由u出發所指向的標簽集合;n 是迭代的次數;|O(u)|表示用戶 u 的出鄰居數;A1,A2為常數,在0~1之間。
1.3.2 綜合相似度計算
基于傳統的協同過濾方法,要求每個商品的詳細評分數據。但客觀條件決定了用戶不可能對每個商品都進行評分。這就造成了商品的評分信息不夠全面,導致了評分矩陣稀疏,在該矩陣上產生的推薦,會有較大的誤差,對推薦的準確度也會產生比較大的影響。而基于商品標簽的協同過濾方法,彌補了單一評分矩陣稀疏的問題。常用的用戶相似度計算方法有余弦相似性、修正余弦相似性、皮爾森相似性。本文采用皮爾森相似性作為相似度度量標準,將商品的評分相似度和標簽相似度加權得到綜合相似度:
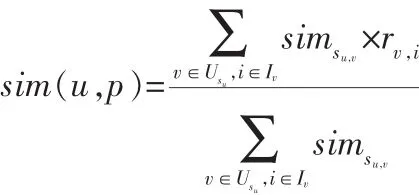
根據公式計算預測評分,將評分最高的Ns個項目生成推薦集Cs。對目標用戶u進行預測評分,simsu,v是社交網絡下經過SimRank算法迭代得到的用戶u和v的相似性Sn(u,v)。將得到預測評分記為sim(u,p),并將評分最高的Cs作為推薦結果。
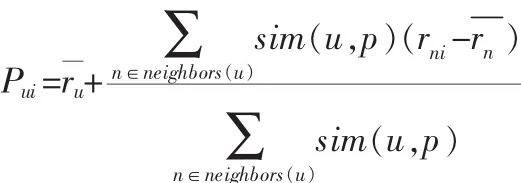
其中,neighbors(u)是評價過的商品i,且與用戶u最相似的n個用戶的集合。
此方法預測用戶u對于所有未評分商品的評分值,取預測評分值最高的N個商品推薦給用戶u。
2 實驗結果與分析
為驗證基于標簽協同過濾算法的有效性,取豆瓣站點(www.douban.com)的數據集進行實驗,該站點用戶可以自由發表有關書籍、電影、音樂的評論,可以自動進行推薦。展現在用戶面前的大部分內容,都是基于每個用戶的特點自動生成的。我們從該站點得到實驗數據集(包括65171個用戶和其標簽過的圖書)。實驗數據集分為訓練集和測試集,其中訓練集占90%,測試集占10%。
2.1 結果評價
本文使用平均絕對誤差 (Mean Absolute Error,MAE)來評價推薦系統的精確性。MAE通過計算項目的實際評分與預測評分之間的偏差來計算預測的準確性。MAE越小,推薦系統的準確度越高[7]。MAE公式如下:
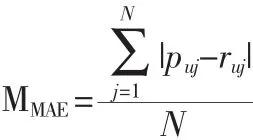
其中,ruj為用戶的實際評分;puj為用戶的預測評分;N為預測的項目個數。
2.2 實驗結果
為檢驗本文提出的基于標簽-協同過濾方法的有效性,本文參照傳統的協同過濾方法,在最近鄰居個數取值不同的時候,對比2種方法MAE的變化情況。實驗數據以下表所示,分別計算平均絕對誤差,結果如圖2所示。
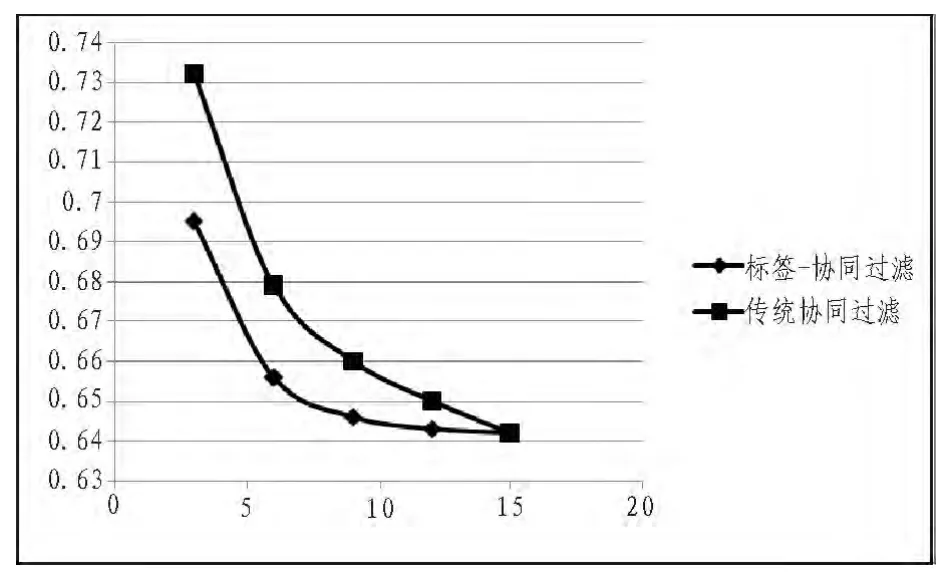
圖2 絕對評價誤差Fig.2 Absolute evaluation errors
由圖2可知,對比傳統的協同過濾方法,本文提出的標簽-協同過濾方法在同等條件下的MAE值更小,精確度更高。因此,將標簽信息和協同過濾方法相結合,可提高推薦系統的準確度。
3 結束語
本文使用的協同過濾推薦算法加入了標簽屬性。在原有的協同過濾算法的基礎上,通過標簽更加精確了算法的推薦程度。并通過實驗數據,客觀的證明了該方法能夠在一定程度上提高了推薦質量。
在以后的研究中,我們還要加強對近義詞,反義詞標簽的處理。并且結合用戶的檢索,用戶的購買時間,進一步提高相似度的計算,為用戶推薦更加精準的產品。
[1]Goldberg D,Nichols D,Oki B M,et al.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM,1992,35(12):61-70.
[2]Herlocker J L,Konstan J A,Borchers A,et al.An algorithmic framework for performing collaborative filtering.Proc of the 22nd Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval[M].New York:ACM,1999:230-237.
[3]踏莎而行.小Tag有大智慧[J].電子商務世界,2006(5):84-85.Lufthansa riding the line.Small Tag with great wisdom[J].Ecommerce World,2006(5):84-85.
[4]Chetto H,Chetto M.Some result of the earliest deadline scheduling algorithm [J].IEEE Trans on Parallel and Distributed Systems,1989,15(10):1261-1269.
[5]徐雁斐,張亮,劉煒.基于協同標記的個性化推薦[J].計算機應用與軟件,2008,25(1):9-13.XU Yan-fei,ZHANG Liang,LIU Wei.Recommended based on collaborative personalized tag[J].Computer Applications and Software,2008,25(1):9-13.
[6]Jeh G,Widom J.SimRank:a measure of structural context similarity [C]//Proc of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2002:538-543.
[7]陳志敏,沈潔,趙耀.基于相關均值的協同過濾推薦算法[J].計算機工程,2009,35(22):53-55.CHEN Zhi-min,SHEN Jie,ZHAO Yao.Related to the meanbased collaborative filtering recommendation algorithm[J].Computer Engineering,2009,35(22):53-55.
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
