漢語語義選擇限制知識的自動獲取研究
2014-02-27 07:07:13賈玉祥王浩石昝紅英俞士汶王治敏
中文信息學報 2014年5期
賈玉祥,王浩石,昝紅英,俞士汶,王治敏
(1. 鄭州大學 信息工程學院,河南 鄭州 450001;2. 北京大學 計算語言學教育部重點實驗室,北京 100871;3. 北京語言大學 漢語學院,北京 100083)
1 引言
一個句子不是詞語的隨意組合,除了要滿足語法約束外,還需要滿足語義約束。例如,Chomsky著名的例子“Colorless green ideas sleep furiously.”,在語法上是正確的,但(從常識上講)卻不符合語義,因此沒有意義。因為sleep的主語要求是人或動物,green修飾的應該是具體的事物,colorless修飾green及furiously修飾sleep都存在矛盾。
語義約束的一個主要體現是謂語(如動詞)對充當其句法成分(如主語、賓語等)或語義角色(如施事、受事等)的詞語(論元)在語義上具有選擇性,稱為語義選擇限制(Selectional Restriction/Selectional Preference, SP)。例如,動詞“吃(eat)”的主語(或施事)更傾向于選擇“人或動物”類的詞語,賓語(或受事)更傾向于選擇“食物”類的詞語。
SP知識可以用一個四元組
SP知識獲取就是對任意的
語義選擇限制是重要的詞匯語義知識[1],除了可以用來判斷句子的合法性之外,還具有數據平滑和消歧作用,因此被用于自然語言處理的很多任務,包括句法分析[2]、語義角色標注[3]、詞義消歧[4]、指代消解[5]、隱喻計算[6]等,在信息抽取、問答系統、機器翻譯等方面也有潛在的應用。
漢語研究者在語義選擇限制知識庫建設方面做了很多工作,也開展了一些語義選擇限制規律的探索[7-8],但語義選擇限制知識自動獲取方面的研究還相對較少[9]。本文研究漢語語義選擇限制知識的自動獲取,對比考察了基于語義分類體系的方法HowNet-SP和基于分布的方法LDA-SP,并對兩種方法的融合提出了一個可行的方案。本文的章節安排如下: 第2節介紹相關研究工作;第3節介紹兩種知識獲取方法;第4節給出實驗結果與分析;第5節提出一個知識獲取方法的融合方案;第6節給出總結和展望。
2 相關研究
語義選擇限制是詞匯知識庫的重要組成部分。劍橋大學等構建的綜合語言知識庫描述了動詞對名詞的語義選擇限制,規定了動詞主體和客體的語義類。VerbNet為每一類動詞涉及的相關語義角色描述了選擇限制。北京大學現代漢語語義詞典以義項為單位描述了實詞的配價信息和多種語義組合限制。清華大學等構建的現代漢語述語動詞機器詞典以義項為單位,描述每一個義項涉及的論旨角色的典型語義類。HowNet[10]描述的語義關系中的施事/經驗者/關系主體-事件關系、受事/內容/領屬物-事件關系等也體現了語義選擇限制。柏曉鵬[11]在建立現代漢語詞義分類體系時,把選擇限制作為詞語描述的屬性之一。
Resnik[4]最先提出語義選擇限制的自動獲取,結合WordNet和真實語料獲得英語動詞對賓語語義類的選擇限制。繼英語之后,德語、法語、拉丁語、荷蘭語、漢語、日語、韓語、泰語等多種語言都開展了SP自動獲取的研究。除面向語言學方面的研究之外,SP在自然語言處理方面也得到了廣泛應用。
SP獲取的關鍵是論元擴展,即基于已知的論元實例
第一類是基于語義分類體系的方法。該方法借助語義分類體系(如WordNet),計算謂語對論元語義類的sp值,那么對于未知論元,只要它出現在某一個語義類中,就可以給它一個sp值。這里的關鍵是語義類sp值的計算,Resnik使用一個基于相對熵的統計指標,Li和Abe[12]基于最小描述長度模型,Clark和Weir[13]基于假設檢驗。對于面臨的一詞多義問題,Judea等[14]通過只考慮沒有歧義的Wikipedia中的實體論元加以規避,Ciaramita和Johnson[15]則結合貝葉斯模型來加以處理。這類方法的優點是學習出的知識是關于語義類的排序,而不是簡單的詞語排序,易于人類理解,便于集成到詞匯知識庫中。缺點是需要一個語義分類體系,且由于詞典收詞有限會導致論元覆蓋率比較低。這類方法主要面向語言學研究和詞匯知識庫構建。
第二類是基于分布的方法。該方法不需要語義分類體系,而是利用詞語在語料中的分布情況來實現論元的擴展,具體模型包括基于概率的模型、基于向量空間的模型、基于機器學習的模型等。基于概率的模型把sp值定義為一個關于p、r、a的概率,計算sp就是估計概率值。其中最常用的是隱變量模型[16](如Latent Dirichlet Allocation, LDA),隱變量可以看成一個個隱含的語義類,把謂語和未知論元聯系起來。基于向量空間的模型[17]利用大規模語料構建一個向量空間,通過在該空間里計算未知論元和已知論元的相似度,把謂語和未知論元聯系起來。基于機器學習[5]的方法直接對論元進行二分類: 合適的論元和不合適的論元,把分類器給論元的打分作為sp值。Tian等[18]通過在謂語論元搭配圖上的隨機游走算法來解決未知論元問題和sp值的計算。基于分布的方法優點是不依賴語義分類體系,論元覆蓋率高,對一詞多義問題能更好地處理,易于和其他自然語言處理任務結合。缺點是學習出的知識是詞語的列表,與語義類列表相比,不易于人類理解。這類方法主要面向自然語言處理,也是SP獲取的主流方法。
SP知識獲取方法的評價可以有三種途徑: 一是與人的判斷進行一致性比較,由人制定標準測試集;二是偽消歧(pseudo-disambiguation)[19],自動構建測試集;三是嵌入自然語言處理任務。從以往研究可以看出,基于分布的方法一般要好于基于語義分類體系的方法,基于分布的方法的各種具體模型的表現各有優劣。
3 漢語SP獲取方法
對于漢語語義選擇限制知識的獲取,對比考察基于語義分類體系的方法和基于分布的方法。基于語義分類體系的方法采用Resnik[4]的統計指標和HowNet的分類體系,基于分布的方法采用LDA模型。
3.1 基于語義分類體系的方法——HowNet-SP
假設謂語動詞v,論元角色r,名詞語義類c,定義謂詞的選擇優先強度(selectional preference strength, SPS)為論元語義類的后驗概率分布和先驗概率分布之間差異,如式(1)所示。用相對熵表示,體現謂詞對論元語義類的選擇性,值越大選擇性越強,如“吃”(SPS = 0.585 318)對賓語的選擇性要比“想”(SPS = 0.185 432)對賓語的選擇性強。
謂詞v的論元角色r選擇語義類c的優先度(selectional preference, sp)即選擇關聯度(selectional association, SA)定義如式(2)所示。
即該語義類對謂詞選擇優先強度的貢獻,體現了該語義類用作謂詞論元的適合程度。選擇關聯度越大,謂詞對該語義類的選擇傾向性越強,如“edible|食物”(SA= 0.313 351)作為“吃”的賓語的選擇關聯度大于“stone|土石”(SA = 0.000 482 528)。
謂詞v的論元角色r選擇某一名詞n的優先度定義為v對n所屬的所有語義類的選擇優先度的最大值,如式(3)所示。
使用最大似然估計方法來估計概率P(c|r)及P(c|v,r),如公式(4)~(5)所示。
文本中出現的是詞w,不是語義類c。用詞頻freq(r,w)(統計w作為角色r出現的次數,比如w作為動詞賓語出現的次數)或共現詞頻freq(v,r,w)來估計語義類出現的頻率freq(r,c)或共現頻率freq(v,r,c),如式(6)~(7)所示,需要借助語言知識本體(語義分類體系),這里使用HowNet。一個詞可能有多個義項,每個義項對應于HowNet中的一個概念(語義類)。這里對詞的義項不做區分,假設詞的出現對每個義項均起作用,并且對義項的所有上位概念均起作用。包含詞w的語義類集合classes(w)是由w所在的各個概念及其所有上位概念組成,而且w對這些語義類的貢獻均等,即詞頻要除以語義類的個數|classes(w)|。
3.2 基于分布的方法——LDA-SP
概率主題模型LDA(Latent Dirichlet Allocation)[20]是一種有效的文檔表示模型,把文檔看作隱含主題的隨機混合,隱含主題看作詞的分布。該模型既可以挖掘文本中潛在的語義信息,又可以降低文檔表示的維度。
這里把描述文檔詞項共現的LDA模型遷移到謂詞論元共現的描述,把謂詞(如動詞)看作文檔,把論元(如做動詞賓語的名詞)看成詞項,把論元的語義類看成隱含主題。這樣基于LDA的語義選擇限制表示模型稱為LDA-SP,如圖1所示。
空心點表示隱含隨機變量或參數,實心點表示可觀察值,箭頭代表依賴關系。矩形表示重復過程,右下角是重復次數。大矩形表示從Dirichlet分布中為每個謂詞v反復抽取語義類分布Θv,共V個謂詞。小矩形表示從語義類分布中反復抽樣產生謂詞的論元名詞,共N個名詞。
LDA-SP的具體生成過程如下:
1) 對每一個謂詞v,選擇隱含語義類上的一個多項式分布Θv,Θv是參數為α的Dirichlet分布。
2) 對每一個語義類z,選擇論元名詞上的一個多項式分布Φz,Φz是參數為β的Dirichlet分布。
3) 生成一個謂詞v的論元名詞n,先以分布Θv從隱含語義類中選擇一個語義類z,再以分布Φz從論元名詞中選擇一個論元名詞n。
模型生成的結果可以用公式(8)表示。
在此基礎上可以定義謂詞對論元語義類和論元名詞的選擇優先度如式(9)~(10)所示。
LDA-SP兩個重要的參數是各語義類下論元名詞的概率分布P(n|z)和各謂詞的語義類概率分布P(z|v,r)。參數估計可以采用期望最大化(Expectation Maximization ,EM)算法和Gibbs采樣等方法。給定參數α,β,語義類個數T及謂詞論元搭配集,就可以得出訓練參數P(n|z)及P(z|v,r)。
4 實驗與分析
我們選擇動賓關系、主謂關系來對語義選擇限制知識獲取進行評價。對《人民日報》2000年全年語料使用哈工大語言技術平臺進行依存句法分析,抽取動詞—名詞賓語對935 319對、動詞—名詞主語對459 913對。對于LDA-SP模型,忽略只出現一次的動詞,使用GibbsLDA++來實現,主題(語義類)數量設為200,迭代次數設為2 000,其他參數為缺省設置。
4.1 優選語義類
基于語義分類體系的方法可以獲取動詞優選語義類的列表,基于分布的方法一般獲得的是詞語的列表。LDA-SP方法中的隱含變量z是詞語的聚類,相當于語義類。表1給出“吃”、“喝”、“寫”、“唱”四個動詞的賓語最優先選擇的語義類的情況,即SA最大的Class及P(z|v,r)最大的z。可見,HowNet-SP與LDA-SP方法所獲取的優選語義類與人的認知基本一致。比較而言,以語義類表示的前者要比后者更清楚更易于理解。給隱含變量標注語義類標簽將是提高LDA-SP方法所獲取知識的可理解性的手段。

表1 優選語義類比較
文獻[7]選取46個高頻動詞,考察動詞賓語語義類的情況,只給出作賓語的頂層語義類,如“發揮”的賓語語義類是“attribute|屬性”,“舉行”的賓語語義類是“fact|事情”。本文對文獻[7]中的所有動詞,從語料庫中自動獲取對賓語的語義優選,得到動詞對各層次所有語義類的選擇優先度。表2給出每一個動詞選擇關聯度SA最大的賓語語義類。可見,大部分的語義類都是符合常識的。但是結果還是受一些因素的影響: (1)語料的規模。受語料庫規模影響,一些動賓搭配的頻率比較小,比如“改掉”只有一個賓語“陋習”、“建筑”只出現8次、“震驚”出現20次、“改正”出現21次,這些都可能影響所獲取語義類的質量。(2)語料的領域。本文是新聞領域語料,某些搭配的分布很不平衡,例如,“附”的賓語基本都是“圖片”,因此優選的語義類是“image|圖像”。(3)文本自動分析的錯誤。分詞、詞性標注、句法分析等的錯誤會導致搭配抽取的錯誤,如“計算機愛蟲病毒”這句話里把“蟲”分析成“愛”的賓語,由于這樣的分析出現了49次,直接導致“愛”最優選的語義類是“InsectWorm|蟲”。(4)HowNet中的詞匯知識沒有充分利用。HowNet中名詞出現在多個語義分類體系中,除“entity|實體”外,還有“attribute|屬性”等,這里只用了“entity|實體”,導致不少名詞成了未登錄詞因而被忽略。另外,這里使用詞語定義中的第一義原來表示詞語所屬的語義類,在有些情況下,第一義原并不明確反映詞語的語義類,真正有用的義原是其他義原,這一問題也有待解決。
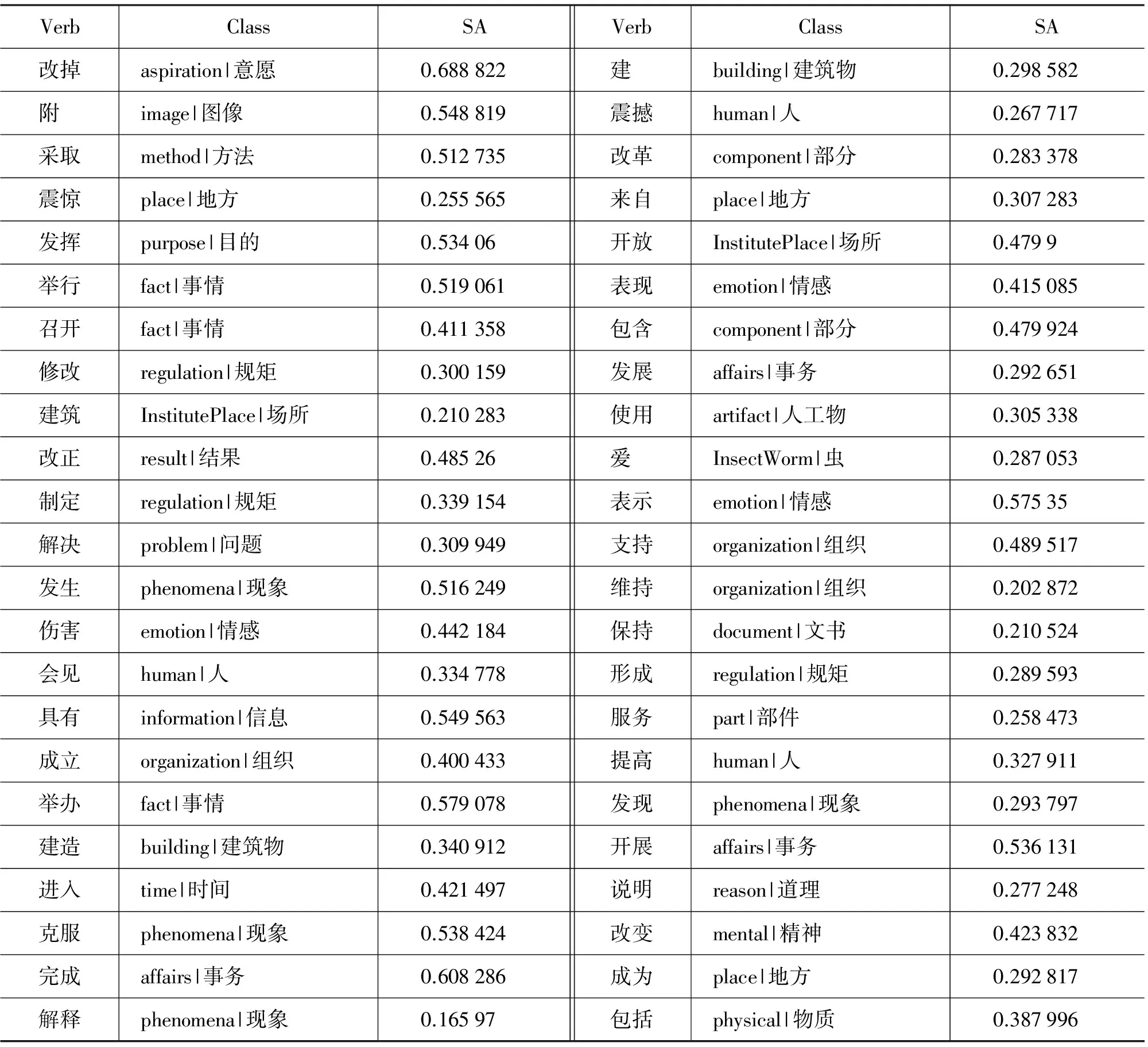
表2 動詞賓語優選語義類
語言中的隱喻表達可以看作是一種搭配異常,例如,“編織夢想”“嫁接資本”等就是由動賓搭配異常而形成的語言創新用法。獲得動詞的優選語義類,進而獲得動詞字面用法下的優選語義類(字面語義類,如“嫁接”的賓語字面語義類“plant|植物”),對隱喻的判別和理解都有重要的作用。我們選擇10個常用于隱喻用法的動詞,考察其賓語或主語優選語義類(選擇關聯度SA最大的語義類)的獲取情況(見表3)。
可見,“嫁接”、“提煉”等給出了準確的字面語義類。“編織”的賓語有多個“網”(有一個語義類是“internet|因特網”),其實“網”前有修飾詞,如“關系”,這里就形成了動詞隱喻和名詞隱喻的嵌套(如編織關系網),比較難處理。“medicine|藥物”泛濫、“fund|資金”流入,本身是隱喻用法,已成為動詞最常用的搭配。解剖“part|部件”和“part|部件”癱瘓,這里的“part|部件”就是一個不能準確反映詞語語義類信息的義原,例如,“身體”這個詞的定義是“DEF=part|部件,AnimalHuman|動物,body|身”,第一義原“part|部件”不如義原“body|身”更能反映“身體”的語義類信息。要準確獲得動詞的字面語義類,可以結合概念的抽象和具體信息,具體的概念更易于成為字面語義類。例如,作為“滑坡”的主語,“stone|土石”的SA值小于“experience|感受”,但是前者是具體概念,后者是抽象概念,可以過濾掉后者,而得到字面語義類“stone|土石”。
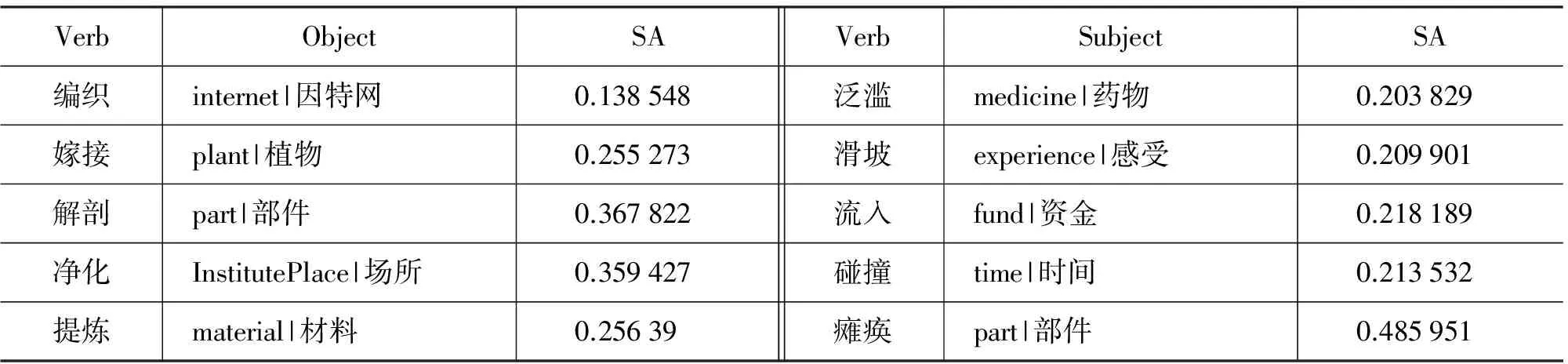
表3 隱喻動詞優選語義類
4.2 偽消歧
語義選擇限制獲取的一個標準評價方法是偽消歧(pseudo-disambiguation)。偽消歧最初是用來評價詞義消歧的,詞義消歧評價的一個難點就是需要人工來標注標準測試集。為了減少人工標注的工作量,提出了偽消歧這種自動構建測試集的方法。具體做法是(以動賓搭配為例): 從語料中自動抽取動賓搭配集,認為都是正確的搭配。對每一個搭配
評價指標采用覆蓋率(coverage)和正確率(accuracy),定義如公式11和12所示。四元組
測試數據使用1998年1月的《人民日報》語料(使用哈工大語言技術平臺進行依存句法分析),從中抽取動詞和名詞賓語搭配,要求: (1)動詞和名詞的頻率在20和300之間。(2)動賓搭配頻率大于2。(3)動詞和名詞都是二字詞。這樣得到1 952個不同的動賓搭配,通過人工校對最后確定搭配1 329對,包含373個動詞和386個名詞。
給每一個搭配中的名詞,選擇一個替代詞。替代詞的選擇可以有不同的策略,比如隨機選擇、選擇相近詞頻的詞等[19]。我們選擇一個更加嚴格的策略,先對名詞按詞頻從大到小降序排列,然后用直接前驅詞替代目標名詞。目標詞和替代詞一起形成一個測試樣本。
從訓練數據中去掉測試樣本中的所有搭配,包括原搭配和偽搭配,這樣來保證所有的測試樣本對模型來說都是沒有見過的,更能反映所獲取的語義選擇限制知識的泛化能力和數據平滑能力。
總體結果如表4所示。可見,LDA-SP模型在覆蓋率和正確率上都比HowNet-SP模型好。LDA-SP模型的覆蓋率是100%,而HowNet-SP模型的覆蓋率是62.53%。一個原因是我們只使用了分類體系“entity|實體”(HowNet 2000版的名詞語義分類體系“entity|實體”包括142個義原,涵蓋 27 267個詞),而有些名詞則屬于其他的語義分類體系,如“主題”“困境”“內容”“局面”等詞都屬于“attribute|屬性”。考慮更多的語義分類體系可能會提高覆蓋率。對于被覆蓋的樣本,HowNet-SP模型的正確率也比LDA-SP模型低很多。
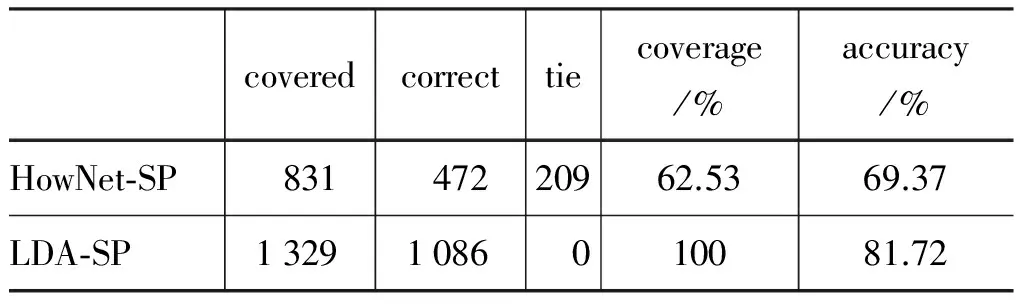
表4 總體結果
表5給出了HowNet-SP模型的幾個例子,c是包含n且sp(v,r,c)最大的語義類。表6給出LDA-SP模型的兩個例子。可見,LDA-SP錯誤的例子在HowNet-SP中是正確的。總體上,79個樣本(約占樣本總數的5.94%)在LDA-SP是錯的,但HowNet-SP是正確的,所以兩個模型的結合可以進一步提高實驗結果。

表5 HowNet-SP模型結果舉例
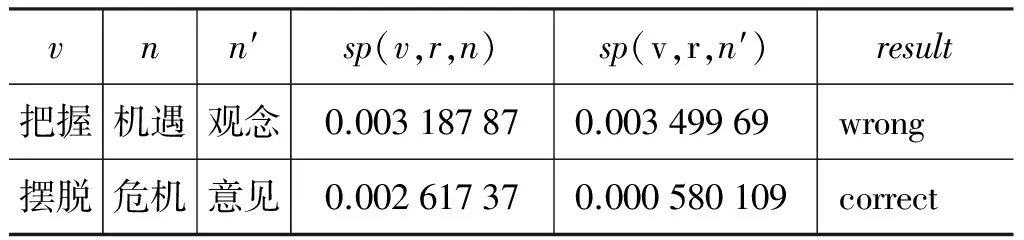
表6 LDA-SP模型結果舉例
5 方法的融合
基于語義分類體系和基于語料庫分布的方法有很強的互補性。從理論上說,二者的結合可以充分利用詞匯語義知識和語料庫分布信息,從而獲得更理想的語義選擇限制知識。從實驗結果看,二者的結合也會使知識獲取的質量得到提升。這里嘗試為兩種方法的融合提出一個可行的方案。
把SP知識獲取分成兩個步驟。第一步是獲取基礎論元搭配,形成基礎搭配庫;第二步是論元擴展。基礎搭配可以從一個較小規模的語料中自動獲取,也可以融合各種知識源,例如,搭配詞典、樹庫treebank等。通過計算已知論元和未知論元之間的相似度來實現論元的擴展并得到選擇優先度sp。論元相似度計算可以把詞匯語義知識和語料庫分布信息融合起來。
謂語對一個論元的選擇優先度sp定義為該論元與基礎搭配庫中該謂語的所有已知論元的相似度的加權組合[17],如公式13所示。
權值weight(p,r,a)可以用來區分不同的論元類型,若設為1,表示所有類型的論元統一看待;也可以根據基礎搭配的數據來源設置不同的權值,如搭配詞典高于樹庫、樹庫高于自動獲取的搭配等。相似度sim(a,a0)的計算可以基于詞匯知識庫與語料庫。基于詞匯知識庫的方法利用詞典中的信息建立詞語之間的關聯并計算相似度,如英語基于WordNet,漢語基于HowNet。語料庫方法基于分布性假設,即語義相似的詞語通常有著相似的上下文,具體實現有基于向量空間的模型和基于概率的模型,基于深度學習的詞語表示方法也可以用于計算詞語相似度。
這里把論元相似度定義為兩種方法計算所得相似度的線性組合,如公式14所示。
其中,α+β=1,0≤α≤1,0≤β≤1,simLKB表示基于詞匯知識庫的方法,simDIST表示基于語料庫分布的方法,兩個相似度都歸一化到[0,1]。這樣就會給每一個
6 總結與展望
本文研究漢語語義選擇限制知識的自動獲取,分別基于HowNet和LDA模型實現了基于語義分類體系和基于分布的知識獲取方法,對知識獲取的結果進行了比較與分析。基于語義分類體系的方法所獲得的優選語義類易為人類理解,而基于分布的方法所獲取的知識在自然語言處理中有更好的應用效果。兩種方法有很好的互補性,我們提出了一個二者的融合方案。本研究下一步將對方法進行改進和優化,擴大數據規模,考察更多的謂語論元類型,考察句法分析等數據預處理中的錯誤對結果的影響。實現方法融合,對不同方法進行更深入的對比研究。
[1] Y Wilks. A Preferential Pattern-seeking Semantics for Natural Language Inference [J]. Artificial Intelligence, 1975, 6: 53-74.
[2] Guangyou Zhou, Jun Zhao, Kang Liu, et al. Exploiting Web-Derived Selectional Preference to Improve Statistical Dependency Parsing [C]//Proceedings of ACL2011, 2011: 1556-1565.
[3] 邵艷秋, 穗志方, 吳云芳. 基于詞匯語義特征的中文語義角色標注研究[J]. 中文信息學報, 2009, 23(6): 3-10.
[4] P Resnik. Selection and Information: A Classed-Based Approach to Lexical Relationships [D]. University of Pennsylvania, Philadelphia, PA, 1993.
[5] Shane Bergsma, Dekang Lin, Randy Goebel. Discriminative Learning of Selectional Preference from Unlabeled Text [C]//Proceedings of EMNLP2008, 2008, 59-68.
[6] Yuxiang Jia, Shiwen Yu. Unsupervised Chinese Verb Metaphor Recognition Based on Selectional Preferences [C]//Proceedings of the 22nd Pacific Asia Conference on Language, Information and Computation (PACLIC 22), 2008: 207-214.
[7] 吳云芳, 段慧明, 俞士汶. 動詞對賓語的語義選擇限制[J]. 語言文字應用, 2005, 5月第2期: 121-128.
[8] 李斌. 現代漢語動賓搭配的語義分析和計算[D]. 南京師范大學博士學位論文, 2009.
[9] 賈玉祥, 俞士汶. 語義選擇限制的自動獲取及其在隱喻處理中的應用[C]//第四屆全國學生計算語言學研討會(SWCL 2008), 2008: 90-96.
[10] 董振東. HowNet [DB/OL]. http://www.keenage.com.
[11] 柏曉鵬. 現代漢語詞義分類體系的建立和自動標注[D]. 新加坡國立大學博士學位論文, 2012.
[12] H Li, N Abe. Generalizing case frames using a thesaurus and the MDL principle [J]. Computational Linguistics, 1998, 24(2): 217-244.
[13] S Clark, D Weir. Class-based probability estimation using a semantic hierarchy [J]. Computational Linguistics, 2002, 28(2): 187-206.
[14] Alex Judea, Vivi Nastase, Micheal Strube. Concept-based Selectional Preferences and Distributional Representations from Wikipedia Articles [C]//Proceedings of LREC2012, 2012: 2985-2990.
[15] M Ciaramita, M Johnson. Explaining away ambiguity: Learning verb selectional preference with Bayesian networks [C]//Proceedings of COLING2000, 2000: 187-193.
[16] Diarmuid 'O S'eaghdha. Latent variable models of selectional preference [C]//Proceedings of ACL2010, 2010: 435-444.
[17] Katrin Erk, Sebastian Pado, Ulrike Pado. A Flexible, Corpus-driven Model of Regular and Inverse Selectional Preferences [J]. Computational Linguistics, 2010, 36(4): 723-763.
[18] Zhenhua Tian, Hengheng Xiang, Ziqi Liu, et al. A Random Walk Approach to Selectional Preferences Based on Preference Ranking and Propagation [C]//Proceedings of ACL2013, 2013: 1169-1179.
[19] Nathanael Chambers, Dan Jurafsky. Improving the use of pseudo-words for evaluating selectional preferences[C]//Proceedings of ACL2010, 2010: 445-453.
[20] D Blei, A Ng, M Jordan. Latent Dirichlet Allocation [J]. Journal of Machine Learning Research, 2003, 3:993-1022.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
