基于Intel Xeon Phi的激光等離子體粒子模擬研究*
2014-03-23 06:03:00姚文科杜云飛楊燦群
計算機工程與科學 2014年5期
姚文科,杜云飛,吳 強,楊燦群
(1.國防科學技術大學并行與分布處理國家重點實驗室,湖南長沙410073;2.國防科學技術大學計算機學院,湖南長沙410073)
1 引言
激光等離子體粒子模擬通常用于描述強激光與等離子體相互作用的非線性過程,從而預測、設計、解釋實驗結果[1,2]。它對于解釋激光等離子體多種耦合過程的物理圖像細節,發現新的物理現象具有重要的意義[1~4]。在實際應用中,模擬迭代的時間步通常可達數千萬步,模擬的粒子數目超過數百萬個[5,6],為了在有效的時間內獲得模擬結果,模擬對計算性能有著極高的要求。因此,使用高性能計算領域的最新成果加速激光等離子體粒子模擬具有重要的現實意義。
近年來,異構系統已經成為高性能計算領域的一種主流系統[2,7]。通過集成通用CPU和加速器單元如GPU等,異構系統在功耗和性能方面占有優勢。針對GPU等加速單元與CPU體系結構差異大、編程模型不兼容的問題[7],Intel發布了支持X86指令架構的Intel Xeon Phi協處理器[8]。Intel Xeon Phi一方面可以兼容原CPU上的程序庫、開發工具以及應用程序,另一方面對于特定類型的計算任務,可以提供極高的計算性能,如Intel Xeon PhiTMCoprocessor 5110P單卡雙精度浮點性能可達1.01 Tflops[2]。在2013年5月Top 500排名中,采用了CPU-Intel Xeon Phi異構結構的TH-2超級計算機排名榜首。可以預見,基于CPU-Intel Xeon Phi的異構系統將在未來高性能計算領域中發揮重要的作用。
基于這一背景,本文研究了三維等離子體粒子模擬程序LARED-P到Intel Xeon Phi的移植。首先采用Native模式對LARED-P程序中熱點計算任務進行優化研究,通過采用SIMD擴展指令進行手工向量化以及數據預取、循環展開的優化,使該計算任務獲得了4.61倍的加速。隨后采用Offload模式將程序移植到CPU-Intel Xeon Phi異構系統上,并通過使用異步數據傳輸和雙緩沖技術提升了程序性能。
本文結構如下:第2節介紹了Intel Xeon Phi的結構特點和LARED-P算法,回顧了相關工作;第3節描述了Native模式下LARED-P在Intel Xeon Phi上的SIMD優化;第4節展現了Offload模式下粒子運動方程的優化過程;第5節給出了性能測評結果;第6節對全文進行了簡要總結。
2 背景介紹
本節主要對Intel Xeon Phi加速器的結構和LARED-P程序結構進行簡單介紹;同時,對其他學者的類似研究工作進行總結。
2.1 Intel Xeon Phi的結構
Intel在2012年11月發布了Intel Xeon PhiTM協處理器,它基于Intel MIC(Many Integrated Core)架構。每片Intel Xeon Phi可以提供62個x86兼容的計算核心[8],每個核包含一個支持512位SIMD的向量處理單元(VPU)。通過使用VPU,每個核可同時處理8路雙精度或16路單精度浮點運算[8],目前,Intel通過提供Intel向量化庫、Intel Intrinsic函數等方式使用VPU。Intel Xeon Phi的每個核擁有32 KB的L1數據Cache和32 KB的L1指令Cache。此外,每個核還可以使用512 KB的L2 Cache。不同核的L2 Cache通過雙向內存控制器相連。
Intel提供了多種模式來使用Intel Xeon Phi,例如Native模式、Offload模式等。
Native模式將Intel Xeon Phi作為一個獨立的處理節點,其上運行有微Linux操作系統,內存空間作為全部的存儲空間。
Offload模式則將Intel Xeon Phi作為CPU的加速單元。CPU作為主控端,將計算密集部分傳送到Intel Xeon Phi上進行計算,然后再將計算結果返回給CPU。
2.2 LARED-P簡介
LARED-P程序是北京應用物理與數學研究所采用粒子云網格法[3,4]實現的三維等離子體粒子模擬程序。它適應于二維和三維Cartesian坐標系,本文主要針對三維模擬進行研究。它采用均勻矩形結構網格離散整個模擬空間,等離子體采用粒子云近似。
LARED-P程序流程如圖1所示,其中主要的三個任務為求解電磁場Maxwell方程、靜電勢Poisson方程和粒子運動方程。在計算過程中,LARED-P以有限差分方法離散Maxwell方程,然后采用蛙跳格式離散粒子運動方程,最后采用粒子云網格方法(PIC)耦合粒子和電磁場。這三個方程中粒子運動方程占據了計算時間的31.8%,粒子云方程占34.7%,粒子重排過程占27%。
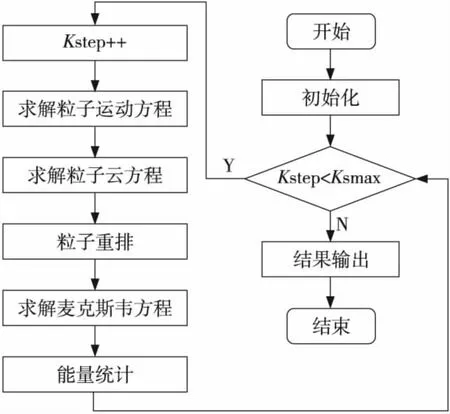
Figure 1 Flow chart of LARED-P圖1 LARED-P程序流程圖
2.3 相關工作
莫則堯等人[4]在所開發的串行LARED-P程序的基礎上引進網格與粒子的關系鏈表,重排粒子位置,消除了性能遷移,提高了單機性能。而后又開發了基于MPI環境的三維粒子模擬程序LARED-P,并采取三維分割、合理安排通信結構,設置虛網格等手段進行優化。
劉來國等人[6]完成了基于GPU的LARED-P加速技術的研究與實現。加速后的LARED-P程序在NVIDIA Tesla S1070的單個GPU上獲得了相當于主頻2.4 GHz的Intel(R)Core(TM)2 Quad CPU Q6600單核的6倍加速比。
石志才等人[9]則針對LARED-P中粒子運動方程在GPU上的實現提出八色分解方案,消除并行訪問的讀寫依賴,擴大了并行度,在NVIDIA Tesla M2090上獲得了相對于Intel Xeon X5670 CPU單核的20.08倍的加速比。
3 Native模式下基于SIMD的優化
本節介紹在Native模式下針對LARED-P所做的優化工作。該算法的實現部分見文獻[9]。運動方程的運行時間占整個算法運行時間的31.8%,在移植過程中為了提高其數據級并行,對它進行了向量化。在使用編譯器選項-O3-mmic與-O3-novec-mmic對比中,發現兩者運行時間沒明顯區別;加編譯指導#pragma vector命令后也沒太大提升。所以,我們選擇了手工向量化。
3.1 基于SIMD擴展指令的手工向量化
通過調用Intel提供的Intrinsic接口函數對粒子運動方程的求解進行手工向量化,該過程主要包括數據打包、向量計算以及數據解包等過程。以更新粒子位置為例,如圖2所示。其中,x、y、z三個數組分別存放粒子的x坐標、y坐標以及z坐標,vxj、vyj、vzj三個數組則存放粒子新速度的三個分量。
這樣經過SIMD向量化,程序局部性增強,性能得到可觀的提升。
在更新粒子新速度時,涉及許多乘、加操作,為了提高效率可以使用乘加指令:_mm512_fmadd_pd(_mm512d,_mm512d,_mm512d)。乘加指令的使用帶來了可觀的性能提升。
3.2 預取優化

Figure 2 Sketch map of vectorization圖2 向量化示意圖
512位寬度的向量處理給訪存帶來了巨大挑戰,為了降低訪問延遲,本文采用了預取指令mm_prefetch(),減少Cache失效。
每次迭代訪問八個網格,這種訪問模式可預測性給預取帶來了便利。本文測試了幾組不同預取距離的運行結果,如圖3所示。從圖3可以看出預取距離為一個迭代時性能最好。

Figure 3 Result of prefetch圖3 預取效果圖
4 基于Offload模式的程序移植
隨后我們利用offload模式將LARED-P移植到CPU-Intel Xeon Phi異構系統上。我們將熱點計算任務—運動方程的求解使用Intel Xeon Phi進行加速,程序的其余部分仍然在CPU上完成。在移植的過程中發現,CPU和Intel Xeon Phi之間的數據傳輸是程序性能瓶頸,占總時間60%。因此,如何降低傳輸開銷成為了本節工作的重點。我們主要采用了兩種優化方法:異步數據傳輸和雙緩沖。
4.1 異步數據傳輸
當使用Offload模式時,CPU在將數據傳給Intel Xeon Phi之后,由于數據依賴的原因,需要等待其計算完畢并將結果傳送回CPU以后,CPU才能繼續執行。為了減少CPU的空轉時間,我們采用了異步數據傳輸的方式對其進行優化。
首先采用一種CPU提前計算的方式減少CPU的空轉時間。當需要調用Intel Xeon Phi進行粒子運動方程加速時,CPU以異步方式將數據傳輸到Intel Xeon Phi上,并提前進行與粒子運動方程計算結果無關的任務的處理,如圖4所示。然而,由于大部分的計算任務都與運動方程相關,因此這種方式取得的效果并不明顯。
隨后采用了一種提前傳輸的方式來減少數據拷貝時CPU的等待時間。當粒子運動方程相關的數據已經準備完畢時,CPU立刻以異步的方式將數據傳給Intel Xeon Phi后,繼續以正常流程進行任務處理,這樣增加了CPU和Intel Xeon Phi并行執行的時間,從而隱藏了部分數據傳輸時間。

Figure 4 Sketch map of asynchronous mode圖4 異步傳輸示意圖
4.2 雙緩沖
為了進一步減少數據傳輸開銷,我們采用了雙緩沖技術,在CPU端開辟兩個發送緩沖區和兩個接收緩沖區。所需數據分組傳輸,相比之前MIC端需要接收全部數據之后才開始計算,在使用了雙緩沖之后,帶來的明顯好處是:以流水線方式執行傳輸和計算,可以將絕大部分數據傳輸時間隱藏,如圖5所示。

Figure 5 Sketch map of double buffer圖5 雙緩沖示意圖
5 性能評測
本節對LARED-P算法進行性能測試,測試平臺的具體配置如表1所示。我們采用的編譯器為Intel C++Compiler 13.0,MPI版本為3.0。

Table 1 Configuration of the test platform表1 測試平臺的配置
首先測試了手動向量化和數據預取取得的性能提升。測試網格數為64*128*128,平均每個網格包含10個粒子。圖6為沒有向量化、只有向量化和向量化加預取三種情況下程序的運行時間,從圖6中可以看出,向量化加速效果不錯,加速比可達到4.61,而預取的加速效果沒有向量化明顯,但是仍有19.7%的性能提升。因為MIC卡內存有限,無法再擴大規模,而當線程數接近64時,運行時間占整個程序時間的比例已經非常小了,所以只測試到了64線程。CPU上運行16線程時總時間為1.058 s,而MIC上64線程運行時間為0.717 s,所以在MIC上每個核運行一個線程的情況下,相對單塊CPU有1.48倍的加速。

Figure 6 Result in native mode圖6 Native模式下實驗結果
接著測試了Offload模式下的異步輸入和雙緩沖的效果,如圖7所示。從圖7中可以看出,異步輸入和雙緩沖都對運動方程產生了一定的性能提升,相比于傳統Offload分別有9.8%和21.8%的性能提升。
6 結束語
本文基于Intel Xeon Phi協處理器實現了LARED-P程序的移植。在移植的過程中,本文綜合運用了Native和Offload兩種編程模式:首先運用Native模式對LARED-P程序中熱點計算任務進行優化研究,通過采用SIMD擴展指令使該計算任務獲得了4.61倍的加速;然后運用Offload模式將程序移植到CPU-Intel Xeon Phi異構系統上,并通過使用異步數據傳輸和雙緩沖技術分別獲得9.8%和21.8%的性能提升。

Figure 7 Result in Offload mode圖7 Offload模式下實驗結果
[1] Zhu Shao-ping,Zhang Wei-yan.Overview of computer simulation on laser fusion in China[J].Journal of the Korean Physical Society,2006,49:33-38.
[2] Chang Tie-qiang.Laser-plasma interaction and laser fusion[M].Changsha:Hunan Science and Technology Press,1998.(in Chinese)
[3] Ma Yan-yun,Chang Wen-wei,Yin Yan,et al.An object-oriented 3D parallel simulation program PLASIM3D[J].Chinese Journal of Computation Physics,2004,21(3):305-311.(in Chinese)
[4] Mo Ze-yao,Xu Lin-bao,Zhang Bao-lin,et al.Parallel computing and performance analysis for 2D plasma simulation with particle clouds in cells method[J].Chinese Journal of Computation Physics,1999,16(5)496-504.(in Chinese)
[5] Cao Xiao-lin,Zheng Chun-yang,Zhang Ai-qing,et al.Program development of 3D plasma simulation oriented thousands of processors[J].Chinese Journal of Progress in Natural Science,2009,1(5):544-550.(in Chinese)
[6] Liu Lai-guo,Xu Wei-xia,Yang Can-qun,et al.Accelerating LARED-P algorithm based on GPU[J].Computer Engineering &Science,2009,31(A01):59-63.(in Chinese)
[7] Stantchev G,Dorland W,Gumerov N.Fast parallel particleto-grid interpolation for plasma PIC simulations on the GPU[J].Journal of Parallel and Distributed Computing,2008,68(10):1339-1349.
[8] Intel?Xeon PhiTMCoprocessor System Software Developers Guide[R].SKU#328207-001EN,2012.
[9] Yang Can-qun,Wu Qiang,Hu Hui-li,et al.Fast weighting method for plasma PIC simulation on the GPU-accelerated heterogeneous systems[J].Journal of Central South University,2013,20(6):1527-1535.
[10] MPI-2:Extensions to the message-passing interface[EB/OL].[2012-05-16].http://micro.ustc.edu.cn/Linux/MPI/mpi-20.pdf.
[11] Schulz K W,Ulerich R,Malaya N,et al.Early experiences porting scientific applications to the many integrated core(MIC)platform[C]∥Proc of the 2012 Highly Parallel Computing Symposium,2012:1.
附中文參考文獻:
[2] 常鐵強.激光等離子體相互作用與激光聚變[M].長沙:湖南科學技術出版社,1998.
[3] 馬燕云,常文蔚,銀燕,等.三維面向對象的并行粒子模擬程序PLASIM3D[J].計算物理,2004,21(3):305-311.
[4] 莫則堯,許林寶,張寶琳,等.二維等離子體模擬粒子云網格方法的并行計算與性能分析[J].計算物理,1999,16(5):496-504.
[5] 曹小林,鄭春陽,張愛清,等.面向數千處理器的三維等離子體粒子模擬程序研制[J].自然科學進展,2009,19(5):544-550.
[6] 劉來國,徐煒遐,楊燦群,等.基于GPU的LARED-P算法加速[J].計算機工程與科學,2009,31(A01):59-63.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
中國衛生(2015年3期)2015-11-19 02:53:32
