改進(jìn)譜聚類算法在多模型軟測量中的應(yīng)用
2014-04-03 02:23:12
自動(dòng)化儀表 2014年6期
關(guān)鍵詞:模型
(南京工業(yè)大學(xué)自動(dòng)化與電氣工程學(xué)院,江蘇 南京 211816)
0 引言
在化工過程和很多其他工業(yè)應(yīng)用領(lǐng)域中,由于大多數(shù)系統(tǒng)存在機(jī)理復(fù)雜、高度非線性、強(qiáng)耦合、大時(shí)滯等特點(diǎn),采用單一的軟測量模型無法全面地描述復(fù)雜系統(tǒng)的全局特性,并且存在回歸精度低和泛化能力差等問題。
為了解決上述問題,一種能夠提高系統(tǒng)模型精度和泛化能力的多模型軟測量建模方法應(yīng)運(yùn)而生[1-3]。仲蔚等[4]提出模糊C均值聚類和徑向基核函數(shù)(radial basis function,RBF)網(wǎng)絡(luò)相結(jié)合的策略來進(jìn)行多模型建模。現(xiàn)場應(yīng)用表明,該方法易于實(shí)現(xiàn)且具有更好的泛化結(jié)果和預(yù)報(bào)精度。周立芳等[5]提出基于K均值聚類算法的多模型預(yù)測控制,試驗(yàn)證明了多模型建模的模型精度和泛化特性。然而,傳統(tǒng)的聚類算法如K均值算法、模糊C均值算法等都是建立在凸球形的樣本空間上,當(dāng)樣本空間不為凸球形時(shí),算法將會陷入局部最優(yōu)。
針對傳統(tǒng)聚類方法存在的問題,本文提出一種基于改進(jìn)譜聚類的多模型建模算法。該算法具有識別非凸分布聚類的能力,不會陷入局部最優(yōu)解,且能避免數(shù)據(jù)的維數(shù)過高所造成的奇異性問題,以便得到更加精確的聚類結(jié)果,提高模型精度。樣本聚類后,采用最小二乘支持向量機(jī)(least square-support vector machine,LS-SVM)建立各子類模型,并采用粒子群(particle swarm optimization,PSO)算法對多模型權(quán)值進(jìn)行尋優(yōu),系統(tǒng)軟測量模型輸出可視作各子模型的加權(quán)組合。本文所研究方法在丙烯精餾塔塔頂丙烯含量軟測量中進(jìn)行了應(yīng)用研究,結(jié)果表明,該方法具有較高的精度和良好的泛化性能。
1 譜聚類算法
1.1 標(biāo)準(zhǔn)譜聚類算法
譜聚類是建立在圖論中譜圖理論的基礎(chǔ)上[6],將聚類問題轉(zhuǎn)化為一個(gè)無向圖的最優(yōu)劃分問題的過程,其本質(zhì)是通過Laplacian Eigenmap實(shí)現(xiàn)降維的過程。譜聚類的思想來源于譜圖劃分理論,將每個(gè)樣本數(shù)據(jù)看作圖中的頂點(diǎn)V,根據(jù)樣本間的相似度將相應(yīng)頂點(diǎn)之間的連接邊E賦權(quán)重W,從而得到基于樣本相似度的無向加權(quán)圖G=(V,E,W)。此時(shí),可以將聚類問題轉(zhuǎn)化為在圖G上的圖劃分問題。根據(jù)圖論的劃分理論來看,譜聚類的本質(zhì)就是使得劃分后的子圖之間相似度最小[7],子圖內(nèi)部相似度最大。
根據(jù)準(zhǔn)則函數(shù)和譜映射方法的不同,譜聚類算法有多種實(shí)現(xiàn)方法。實(shí)現(xiàn)過程一般分為三步:①定義數(shù)據(jù)樣本點(diǎn)之間的相似性度量,建立數(shù)據(jù)點(diǎn)之間的相似矩陣;②通過計(jì)算相似矩陣的前k個(gè)特征值與特征向量,構(gòu)建新的數(shù)據(jù)特征空間;③采用K均值或者其他傳統(tǒng)聚類算法對特征空間中的特征向量進(jìn)行聚類。
雖然K均值算法實(shí)現(xiàn)簡單,可以重復(fù)運(yùn)行而不受初始化的影響,但是K均值算法也有一些致命的缺點(diǎn),如不能處理非球型簇以及不同尺寸和不同密度的簇,對于含有離群點(diǎn)的聚類也不太適應(yīng)。同時(shí),K均值算法是一種貪心算法,經(jīng)常會陷入局部最優(yōu)解。然而,譜聚類算法只需要數(shù)據(jù)之間的相似度矩陣,不必像K均值算法那樣要求數(shù)據(jù)必須是N維歐氏空間向量。因此,本文采用改進(jìn)譜聚類算法來克服K均值算法的缺點(diǎn),從而得到準(zhǔn)確的聚類結(jié)果,提高模型精度。
1.2 改進(jìn)的譜聚類算法
在譜聚類算法中,特征值和特征值向量的選擇對聚類結(jié)果影響很大,而特征值和特征向量的選擇以聚類分組數(shù)為依據(jù)[8]。因此,本文采用基于特征差值與正交特征向量的改進(jìn)譜聚類算法,對標(biāo)準(zhǔn)譜聚類算法進(jìn)行改進(jìn),實(shí)現(xiàn)聚類數(shù)目的自動(dòng)確定。譜聚類算法的基本思想是:先利用樣本數(shù)據(jù)構(gòu)建相似矩陣,然后對由相似矩陣生成的規(guī)范化相似矩陣進(jìn)行譜分解,從而得到相應(yīng)的特征值和特征向量;隨后對特征值按降序排列,并用本征間隙來表述相鄰特征值之間的差,通過第一個(gè)極大本征間隙出現(xiàn)的位置來自動(dòng)確定類個(gè)數(shù);最后結(jié)合獲得的類個(gè)數(shù)和特征向量之間的夾角實(shí)現(xiàn)數(shù)據(jù)分類。本文選擇規(guī)范割集劃分準(zhǔn)則來實(shí)現(xiàn)譜聚類算法。
設(shè)輸入數(shù)據(jù)集為S={S1,S2,…,Sn},且S為Rn空間中待聚類的數(shù)據(jù)集;輸出為聚類分組數(shù)k和聚類結(jié)果。聚類算法具體步驟如下。
① 構(gòu)造數(shù)據(jù)集的親和(相似)矩陣Wij,Wij=exp(-‖Si-Sj‖2/2δ2),i≠j,且Wii=0,其中δ為閾值參數(shù)。
② 構(gòu)造拉普拉斯矩陣L=D-1/2AD1/2,D為對角矩陣,其對角元素為Dii=∑Wik。
③ 求解拉普拉斯矩陣L的特征值(λ1,λ2,…,λn)及其對應(yīng)的特征向量(η1,η2,…,ηn)。
④ 計(jì)算特征值差值g1,g2,…,gn-1,其中g(shù)i=λi-λi+1。

⑥ 構(gòu)造矩陣X=[x1,x2,…,xk],其中x1,x2,…,xk為拉普拉斯矩陣L的前k個(gè)特征值對應(yīng)的特征向量。
⑦ 對矩陣X中的每一行進(jìn)行單位化處理,得到矩陣Y。
⑧ 將Y中的每一行看作Rk空間中的一個(gè)點(diǎn),并對其使用K均值算法,得到k類樣本子集,如果矩陣Y中第i行屬于第j類,則Xi也屬于第j類。
根據(jù)矩陣的攝動(dòng)理論,當(dāng)?shù)趉和(k+1)個(gè)特征值之間的差值越大時(shí),所選的k個(gè)特征向量構(gòu)成的子空間就越穩(wěn)定。此時(shí),以矩陣Y中的每一行作為k維空間中的一個(gè)點(diǎn),形成k個(gè)聚類。它們將彼此正交地分布于k維空間中的單位球上,且在單位球上形成的這k個(gè)聚類對應(yīng)著原來空間中所有點(diǎn)形成的k個(gè)聚類。由此根據(jù)拉普拉斯矩陣的特征值之間的差值來確定類個(gè)數(shù),其中差值取[0.06,0.1]。
與標(biāo)準(zhǔn)譜聚類算法相比,改進(jìn)后的譜聚類算法可以自動(dòng)確定聚類個(gè)數(shù)[9],對樣本數(shù)據(jù)建立規(guī)范化相似矩陣并進(jìn)行譜分解;利用本征間隙自動(dòng)確定樣本數(shù)據(jù)的類個(gè)數(shù);根據(jù)確定的類個(gè)數(shù)和譜分解后的特征向量間的夾角,實(shí)現(xiàn)樣本數(shù)據(jù)的分類。
2 基于LS-SVM的子模型建模
支持向量機(jī)是一種小樣本學(xué)習(xí)理論,它的基本思想是采用結(jié)構(gòu)風(fēng)險(xiǎn)最小化原則構(gòu)造最優(yōu)決策函數(shù)[10],解決樣本空間中高度非線性回歸問題。最小二乘支持向量機(jī)(LS-SVM)是一種改進(jìn)的支持向量機(jī),它將求解二次規(guī)劃問題轉(zhuǎn)化為求解線性方程組[11],解決了一般標(biāo)準(zhǔn)支持向量機(jī)求解凸二次規(guī)劃問題所帶來的復(fù)雜度的問題,提高了學(xué)習(xí)速度。LS-SVM算法的優(yōu)化問題描述如下。
(1)
式中:φ(xi)為核空間映射函數(shù);ω為權(quán)矢量;ei為誤差變量;b為偏差量;γ為正則化參數(shù)。
為了求解上述優(yōu)化問題,需要把有約束優(yōu)化問題變?yōu)闊o約束優(yōu)化[14]。為此建立相應(yīng)的Lagrange函數(shù):
(2)
根據(jù)KKT(Karush-Kuhn-Tucher)最優(yōu)條件,得到如下線性方程組:
(3)
式中:y=y(y1,y2,…,yl);e=[1,1,…,1]T;α=(α1,α2,…,αl)T為拉格朗日乘子;Ωij=φT(xi)φ(xj)=K(xi,xj)為核函數(shù)(核函數(shù)采用徑向基核函數(shù))。
因此,LS-SVM算法的優(yōu)化問題轉(zhuǎn)化為求解線性方程組(3),最終可得到LS-SVM的模型表達(dá)式為:
(4)
3 軟測量多模型建模
本文軟測量多模型建立步驟如下。首先,采用改進(jìn)譜聚類算法對訓(xùn)練樣本集X1聚類,得到n個(gè)類別,對各類建立LS-SVM子模型;然后,根據(jù)歐氏距離將測試樣本集X2中的測試樣本點(diǎn)劃分到相應(yīng)的子模型中,得到相應(yīng)的子模型輸出yi(i=1,…,n);最后,將各子模型按照“加權(quán)方式”進(jìn)行組合,得到系統(tǒng)模型輸出Y,完成多模型的建立。基于改進(jìn)譜聚類算法的軟測量多模型結(jié)構(gòu)如圖1所示。
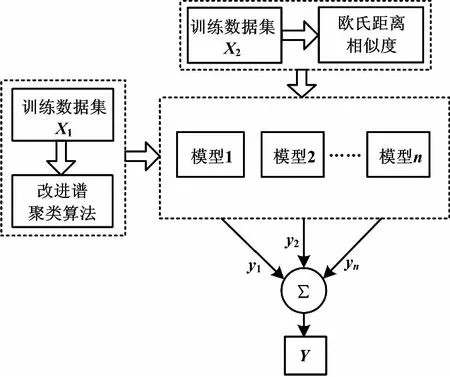
圖1 多模型軟測量系統(tǒng)結(jié)構(gòu)圖
在辨識出系統(tǒng)各個(gè)子模型的基礎(chǔ)上,按照“加權(quán)方式”進(jìn)行組合,得到系統(tǒng)的軟測量模型輸出。描述如下:
(5)
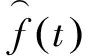
粒子群算法是一種適應(yīng)性較強(qiáng)的全局優(yōu)化算法,能夠快速找到合適的權(quán)向量[12]。本文采用粒子群算法對多模型權(quán)值進(jìn)行尋優(yōu),算法步驟如下。
① 初始化粒子種群及參數(shù),設(shè)定多模型中加權(quán)系數(shù)個(gè)數(shù)n、粒子數(shù)目c;對于第i個(gè)粒子,將每個(gè)加權(quán)系數(shù)作為粒子i的位置編碼;計(jì)算各粒子的適應(yīng)度,設(shè)置粒子i的初始速度為0。反復(fù)進(jìn)行,生成m個(gè)粒子。
② 由初始化粒子群得到粒子的個(gè)體最優(yōu)位置Pid(i)和全局最優(yōu)位置Pgd。
③ 更新初始化粒子的速度和位置,慣性因子ξ按式(6)計(jì)算:
(6)
式中:D為當(dāng)前迭代次數(shù);Dmax為最大迭代次數(shù);ξmax=1,ξmin=0。
④ 對于每一個(gè)粒子i,比較它們的適應(yīng)度函數(shù)和經(jīng)歷過的最好位置的適應(yīng)度值Pid(i),若更好,則更新Pid(i)。
⑤ 對于每個(gè)粒子i,比較它們的適應(yīng)度值和群體所經(jīng)歷的最好位置Pgd的適應(yīng)度值,若更好,則更新Pgd。
⑥ 檢查終止條件(是否到達(dá)設(shè)定迭代次數(shù))。若條件滿足,迭代終止,輸出全局最優(yōu)加權(quán)解,否則返回步驟③。
4 仿真實(shí)例
丙烯是重要的石油化工基礎(chǔ)原料,用于生產(chǎn)聚丙烯、苯酚、丙酮等。丙烯精餾塔中丙烯濃度是重要的質(zhì)量指標(biāo),人工采樣離線分析的方法存在長時(shí)間滯后問題,不利于生產(chǎn)過程的在線檢測與控制。因此,本文將基于改進(jìn)譜聚類的多模型軟測量建模方法應(yīng)用于丙烯生產(chǎn)過程中質(zhì)量指標(biāo)的預(yù)測。
根據(jù)丙烯生產(chǎn)工藝,選擇塔頂溫度、進(jìn)料量溫度、回流溫度、進(jìn)料壓力、塔釜壓力、回流量、塔釜液位以及回流罐液位作為輸入變量,丙烯含量作為輸出變量。將現(xiàn)場采集的樣本數(shù)據(jù)進(jìn)行異常樣本數(shù)據(jù)的剔除,對輸入變量的樣本數(shù)據(jù)進(jìn)行歸一化處理,得到150組樣本數(shù)據(jù),其中100組用于訓(xùn)練模型,50組作為測試。采用改進(jìn)譜聚類算法進(jìn)行聚類的步驟如下。
首先,用改進(jìn)譜聚類算法對訓(xùn)練樣本聚類,樣本數(shù)據(jù)被自動(dòng)聚為3類,分別建立子模型;然后根據(jù)歐氏距離將測試樣本歸類,用相應(yīng)的子模型預(yù)測輸出;最后,根據(jù)粒子群算法求解多模型權(quán)值,將建立的子模型按照“加權(quán)方式”組合,得到丙烯質(zhì)量指標(biāo)的軟測量模型。
為了驗(yàn)證本文方法的有效性,分別采用基于K均值-LS-SVM多模型建模(分類參數(shù)取為2)和基于LS-SVM單模型建模,然后與本文方法進(jìn)行比較。同時(shí),采用均方根誤差(root-mean-square error,RMSE)和最大絕對誤差(maximum absolute error,MAXE)來評價(jià)模型預(yù)測性能。
(7)
(8)
式中:f(xi)和y(xi)分別為模型的輸出值和真實(shí)值;n為樣本個(gè)數(shù)。
根據(jù)試驗(yàn)結(jié)果,3種方法的模型測試誤差比較結(jié)果如表1所示。
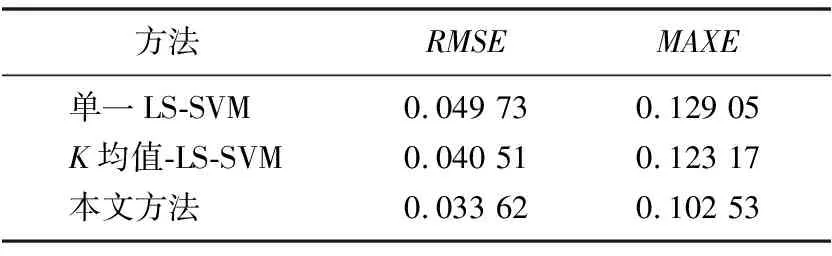
表1 模型預(yù)測誤差
精餾塔塔頂丙烯質(zhì)量指標(biāo)的3種方法模型預(yù)測結(jié)果如圖2~圖4所示。
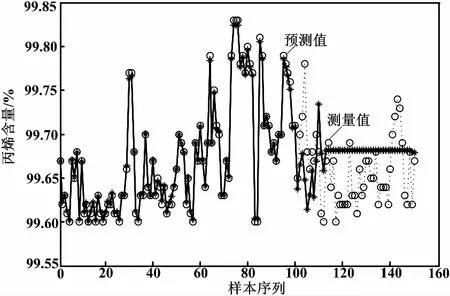
圖2 單一LS-SVM模型預(yù)測
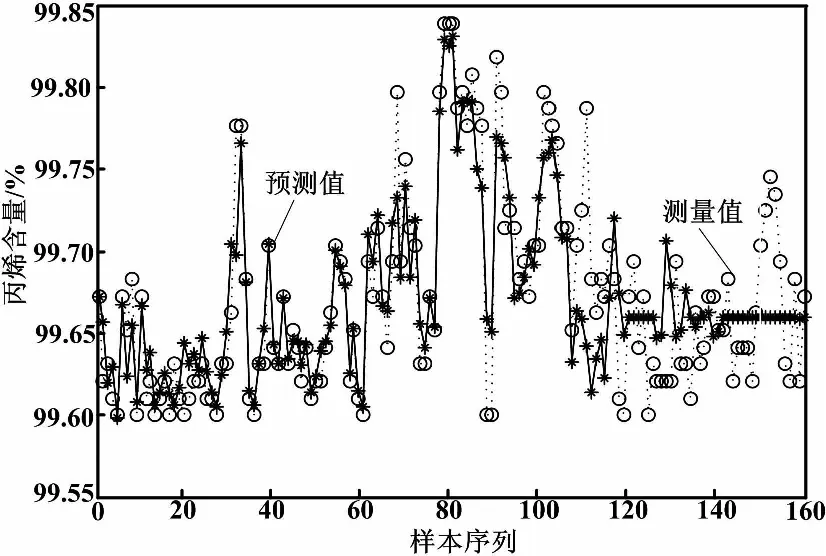
圖3 K均值LS-SVM多模型預(yù)測
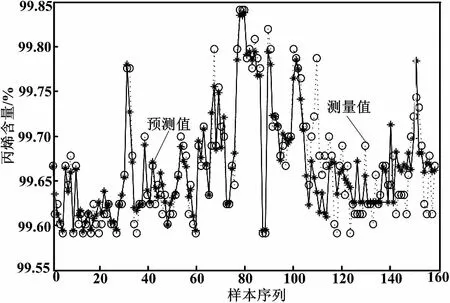
圖4 改進(jìn)譜聚類LS-SVM多模型預(yù)測
由表1可以看出,采用本文提出的方法得到的模型均方根誤差(RMSE)和最大絕大值誤差(MAXE)均體現(xiàn)了該方法的優(yōu)勢。
比較圖2、圖3和圖4的預(yù)測結(jié)果可知,本文方法建立的模型較其他建模方法具有更好的跟蹤效果,說明了本文方法的有效性。
5 結(jié)束語
本文提出的基于SC-LS-SVM多模型建模方法,通過改進(jìn)譜聚類算法對樣本數(shù)據(jù)進(jìn)行聚類,對各子類樣本建立LS-SVM子模型,采用粒子群算法對多模型權(quán)值進(jìn)行尋優(yōu),并將子模型按照“加權(quán)方式”進(jìn)行組合,得到系統(tǒng)軟測量模型。將該方法應(yīng)用于丙烯精餾塔塔頂丙烯含量的軟測量建模中,通過仿真試驗(yàn)對比,本文方法可以較好地跟蹤丙烯質(zhì)量指標(biāo)的變化,具有更好的模型預(yù)測精度。
[1] 王孝紅,劉文光,于宏亮.工業(yè)過程軟測量研究[J].濟(jì)南大學(xué)學(xué)報(bào):自然科學(xué)版,2009,23(1):80-86.
[2] Petr K,Bogdan G,Sibylle S.Data-driven soft sensors in the process industry[J].Computers and Chemical Engineering,2009,33(4):795-814.
[3] Fortuna L,Graziani S,Rizzo A.Soft sensors for monitoring and control of industrial processes[M].London:Springer,2007.
[4] 仲蔚,俞金壽.基于模糊c均值聚類的多模型軟測量建模[J].華東理工大學(xué)學(xué)報(bào):自然科學(xué)版,2000,26(1):83-87.
[5] 周立芳,張赫男.基于聚類多模型建模的多模態(tài)預(yù)測控制[J].化工學(xué)報(bào),2008,59(10):2546-2552.
[6] Luxburg U V.A tutorial on spectral clustering[J].Statistics and Computing,2007,17(4):395-416.
[7] 戴月明,高倩.自適應(yīng)半監(jiān)督模糊譜聚類算法[J].計(jì)算機(jī)工程與應(yīng)用,2010,46(33):212-214.
[8] Zhao F,Jiao L C,Liu H Q,et al.Spectral clustering with eigenvector selection based on entropy ranking[J].Neurocomputing,2010,73(10-12):1704-1717.
[9] Ng A Y,Jordan M I,Weiss Y.On spectral clustering:analysis and an algorithm[C]//Cambridge:MIT Press,2002:121-526.
[10]Vapnik V N.The nature of statistical learning theory[M].New York:Springer Verlag,1995.
[11]Suykens J A K,Vandewale J.Least squares support vector machine classifiers[J].Neural Processing Letters,1999,9(3):293-300.
[12]Kennedy J,Eberhart R C.Particle swarm optimization[C]//Proceedings of 1995 IEEE International Conference on Neural Networks,New York,1995:1942-1948.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
