Web數據挖掘在校園網搜索引擎系統中的應用研究
2014-04-29 01:17:17牛凱
中國信息化 2014年11期
牛凱
隨著數字化校園的迅速發展,搜索引擎技術得到廣泛應用,Web數據挖掘作為數據挖掘技術的一種也應運而生。搜索引擎是基于Web數據挖掘的一個重要研究方向,校園網信息每天以不可估量的速度增長,數以萬計的網頁資源讓師生在浩瀚的信息海洋中眼花繚亂,而搜索引擎的出現則很好的解決了這一現實問題。Web數據挖掘能夠從大量的Web文檔和網頁中抽取出師生感興趣的、潛在的、隱含的信息,為校園網搜索引擎系統提供了強有力的技術支持。
1.Web數據挖掘技術
隨著信息時代的飛速發展,互聯網己成為人們獲取信息的重要途徑。網絡作為信息資源平臺,為人們的日常生活提供了便利快捷的服務。然而,在大量的網絡信息面前, 如何不被淹沒,如何從海量信息中及時發現提取有價值的信息,成為互聯網信息檢索面臨的首要問題。面對這一挑戰, Web數據挖掘技術提供了一種比較好的解決方法。Web數據挖掘技術包括數據庫、計算機網絡和人工智能技術,Web數據挖掘技術使用了很多數據挖掘技術,但是它并不是傳統數據挖掘技術的一個簡單應用,它是一個新的研究領域。Web數據挖掘技術一般分為Web結構挖掘、Web內容挖掘、Web日志挖掘三類。Web內容挖掘是指利用某種算法策略對網絡資源進行抽取,以期發現有用的知識,常用的策略有總結、分類、聚類和關聯分析等。Web頁面內部結構挖掘與外部結構(鏈接分析)是Web結構挖掘的兩個主要研究方向,內部結構挖掘應用于信息抽取、網站結構模式提取和頁面分類,鏈接分析則主要應用于搜索引擎領域。Web日志挖掘主要通過識別用戶瀏覽模式,并通過改進Web站點結構,達到用戶能夠更加方便瀏覽的目的,以此來吸引更多的用戶訪問站點。
Web數據挖掘與搜索引擎聯系緊密,校園網搜索引擎除了使用傳統搜索引擎相關的理論和技術方法外,還需要新的方法和技術來滿足學校師生要求,Web數據挖掘的很多技術可以應用在校園網的搜索引擎中,Web內容挖掘能對互聯網上海量的網頁信息進行總結、分類、集群、關聯分析和趨勢預測等。通過對網頁內容的挖掘,可以實現網頁的聚類和分類,能夠對網絡信息進行分類瀏覽和檢索,從而提高網絡信息的標引準確度,提高檢索效率。
根據數據挖掘的一般方法和相關理論,可以得出Web數據挖掘的流程圖,如圖1所示。
網絡數據的收集主要是從Web站點上的數據信息中提取一個數據子集,主要包括頁面數據、超鏈接信息和用戶的訪問歷史記錄等,為數據挖掘提供資源支持。數據的預處理主要是對數據源進行組織重構和加工處理,并以此構建主題數據庫,為Web數據挖掘提供相應的平臺。模式發現及分析是Web數據挖掘最核心的部分,它主要是通過運用各種數據挖掘技術,從數據對象中發現潛在的、能被人所理解的知識模式,并最終發現描述性模式和預測性模式。
2.校園網搜索引擎系統架構設計
2.1 整體框架模型設計
校園網搜索引擎系統設計以智能化為目標,最大程度上滿足學校師生不同需求的查詢。系統首先收集海量的網頁信息,然后搜索引擎程序會自動對收集到的網頁內容進行分析,并通過分詞程序得到語句關鍵詞,再利用索引來構建索引數據庫。當用戶通過Web頁面來查詢索引數據庫時,系統就會返回所有與檢索關鍵詞相匹配的網頁。一個搜索引擎系統主要由以下四部分組成,分別是:頁面采集模塊、頁面分析模塊、索引數據庫模塊和信息檢索模塊。從功能上來說,四部分內容既相互獨立,又相互聯系,形成一個有機的整體。搜索引擎系統架構如圖2所示。
2.2 系統模塊設計
本文設計的校園網搜索引擎系統與傳統搜索引擎系統的主要不同之處是搜索引擎被分解為多個任務不同的專業搜索引擎, 每個專業搜索引擎只搜索特定相關的信息。該搜索引擎系統主要包括5個模塊。
(1)信息抓取模塊:搜索引擎系統首先收集用戶所要查詢關鍵詞和搜索引擎返回的查詢結果,并對收集到的數據進行預處理。
(2)概念提取模塊:系統從收集到的搜索結果中選取前100條數據,進行概念提取,然后將提取到的概念存入相應數據庫。最后,搜索引擎系統計算概念聯系度并將計算結果存儲到數據庫中,為后面的概念聚類做好準備。
(3)用戶建模模塊:系統針對用戶的搜索關鍵字進行概念提取,從而獲得用戶感興趣的相關概念,然后,根據已經建立的概念聯系,確定與用戶搜索關鍵字有聯系的概念。
(4)查詢概念聚類模塊:系統根據用戶興趣模型建立查詢概念二分圖,然后使用基于查詢概念的二分圖聚類算法對查詢和概念分別進行聚類。
(5)查詢優化模塊:聚類形成相似的查詢和相似的概念,相似的查詢用以優化查詢語句,優化后的查詢語句由系統提交給搜索引擎。相似的概念以搜索建議的形式提供給用戶,系統根據用戶興趣模型產生聚類結果。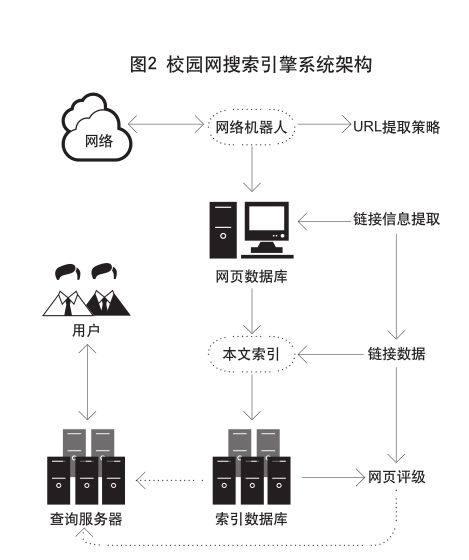
3.Web數據挖掘技術在數字化校園中的應用
在數字化校園建設中,主要以教師和學生為主體,如何更好地協調教師和學生的關系是數據挖掘首要考慮的問題。本文以學生的數字化校園中的基本信息作為基礎信息,通過對學校的各個子庫的個人信息進行加工處理,運用簡單的統計方法對每個子庫信息進行聚合,從而得到進行數據挖掘的基本信息。
搜索引擎系統首先需要將不同的數據源集中到統一的數據倉庫中,執行數據的清洗和轉換操作。為了方便不同數據倉庫之間的數據交換,采用統一的數據挖掘元數據模型。Web數據挖掘技術利用統一的驅動程序存取數據倉庫中的數據,并且采用統一的結果模型表示形式,應用程序通過統一的接口訪問數據挖掘服務。數據挖掘應用程序構架如圖3所示,其中Data是待挖掘數據,存放在關系數據庫或文件中。Data Access獲取文件、數據庫或視圖中的數據,并將數據保存到數據倉庫。數據源可以來自分布式和遠程數據庫。Data Warehouse用來存放待挖掘的數據,Driver提供統一的數據庫驅動程序,DMT提供不同的算法為應用程序服務。數據挖掘算法(DMM)在數據上應用所得的結果,不同DMT之間可以相互調用數據挖掘模型,用于結果應用、評估和可視化。Application是客戶端應用程序,調用一個或多個數據挖掘服務,得到數據挖掘的結果模型,從而獲得決策需要的信息。
Web數據挖掘中,應用關聯分析技術尋找網頁信息庫中的值的相關性,應用分類方法分析進行網頁信息庫中的web數據的分析,這樣能夠為每個類別實現數據模型建立、分類規則挖掘、從而對數據類別做出準確的描述,另外應用聚類方法對網頁信息庫中的記錄數據進行分析,也就是對記錄集合進行合理的規劃并對每個記錄所在的類別進行確定。這樣就能精煉出一個集成度高、易于使用、冗余度地的索引數據庫,方便師生的信息檢索和查找。
4.結論
Web數據挖掘技術是一個新興的且有著巨大發展前景的研究領域,經過眾多研究者的努力,已經取得了一些成果,在校園網搜索系統的應用中起到了很大的推動作用,但是要想將Web數據挖掘技術普及推廣到校園數字化建設中,還需要相當多的工作,還需要不斷深入研究。
作者單位:天津職業技術師范大學 信息技術學院
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
信息通信技術(2015年6期)2015-12-26 01:16:46
中國衛生(2015年12期)2015-11-10 05:13:38
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
