基于頻域逐級回歸的聲學(xué)回聲控制
2014-06-02 04:23:14姜開宇國雁萌顏永紅
電子與信息學(xué)報(bào) 2014年12期
姜開宇 吳 超 國雁萌 付 強(qiáng) 顏永紅
?
基于頻域逐級回歸的聲學(xué)回聲控制
姜開宇*吳 超 國雁萌 付 強(qiáng) 顏永紅
(中國科學(xué)院聲學(xué)研究所 北京 100190)(中科院語言聲學(xué)與內(nèi)容理解重點(diǎn)實(shí)驗(yàn)室 北京 100190)
傳統(tǒng)聲學(xué)回聲控制算法一般采用基于隨機(jī)梯度法更新的頻域分塊自適應(yīng)濾波(PBFDAF)方法,但在以語音為主要回聲信號的室內(nèi)混響環(huán)境中,由于回聲路徑不穩(wěn)定,往往收斂速度較慢,難以實(shí)現(xiàn)足夠的回聲抑制。該文提出一種基于頻域逐級回歸的聲學(xué)回聲控制算法。通過逐級回歸分析遠(yuǎn)端信號和麥克風(fēng)信號之間的線性關(guān)系,可以在保持較小的偏差的同時實(shí)現(xiàn)收斂較快的系統(tǒng)估計(jì)。同時,由于逐級分析了兩通道間的短時相干性,因而該算法無需像常見方法一樣,額外進(jìn)行基于通道間相干函數(shù)的殘余回聲抑制或雙講檢測,從而保持系統(tǒng)的緊湊性。若進(jìn)一步假定近端背景噪聲準(zhǔn)平穩(wěn),則可利用基于近端信號非平穩(wěn)程度的自適應(yīng)平滑因子,在實(shí)現(xiàn)系統(tǒng)估計(jì)快速收斂的同時確保其穩(wěn)定性。實(shí)驗(yàn)表明,該方法在常見的近端環(huán)境噪聲水平下,在收斂速度和穩(wěn)態(tài)誤差上相對傳統(tǒng)方法有顯著優(yōu)勢,非常適合應(yīng)用在室內(nèi)遠(yuǎn)講模式下的聲學(xué)回聲控制中。
語音信號處理;聲學(xué)回聲控制;逐級回歸;聲學(xué)回聲抵消;聲學(xué)回聲抑制
1 引言
在語音通信和交互系統(tǒng)中,由于近端存在語音和背景噪聲,遠(yuǎn)端揚(yáng)聲器信號和近端麥克風(fēng)信號之間的線性關(guān)系會受到干擾,這通常被稱作“雙講”問題。而且,由于室內(nèi)混響的影響,經(jīng)常需要較多參數(shù)才能較精確地建模回聲路徑。更重要的是,回聲路徑可能時變,甚至因環(huán)境擾動而出現(xiàn)突變,因此只能基于有限時長內(nèi)的觀測數(shù)據(jù)進(jìn)行無偏估計(jì),這將導(dǎo)致估計(jì)方差較大。另外由于遠(yuǎn)端信號是語音,在時頻分布上比較稀疏,能量較弱的頻帶因?yàn)檠蜎]在近端噪聲中而無法被有效辨識,因而回聲路徑的估計(jì)相對于真實(shí)值經(jīng)常是有差異的。因此,在實(shí)際環(huán)境下,要保持以較小的方差獲得回聲路徑的無偏估計(jì),往往不太可能。相對而言,一個偏差不大,但收斂快速的系統(tǒng)估計(jì),對于確保算法在各種情況下都有足夠的回聲消除量,從而保證系統(tǒng)的穩(wěn)定性尤為重要。
基于以上考慮,本文提出在復(fù)頻域的逐級回歸方法,將兩通道之間的線性關(guān)系建模為逐級回歸模型,并利用逐級的短時譜估計(jì)實(shí)現(xiàn)長系統(tǒng)的辨識,在保持偏差較小的同時,不僅能夠?qū)崿F(xiàn)系統(tǒng)估計(jì)的快速收斂,而且具有抗瞬態(tài)干擾(近端語音)的能力。在本文的逐級回歸中,每級只進(jìn)行一個單參數(shù)的簡單回歸,所以不必進(jìn)行矩陣求逆就能求得逐級的最小二乘估計(jì),能夠達(dá)到較快的收斂速度。此外,如果估計(jì)時使用了足夠多的獨(dú)立樣本,則該估計(jì)對于非持續(xù)的干擾(近端語音)將保持魯棒。這是因?yàn)椋绻煤愣ǚ讲畹陌自肼曅蛄袑诵盘?包括近端語音和背景噪聲)建模,即使其分布不是高斯的,根據(jù)Gauss-Markov定理,最優(yōu)的線性無偏估計(jì)子為最小二乘估計(jì)。盡管逐級回歸相對于多元線性回歸通常有一定偏差[17],但它具有更快的收斂速度和對雙講的魯棒性。同時,通過對回聲路徑衰減形狀的合理假設(shè),可以預(yù)先合理確定逐級回歸中引入回歸變量的次序,并對估計(jì)得到的回歸系數(shù)做出合理約束,從而將系統(tǒng)估計(jì)的偏差和均方誤差控制在一個較低的范圍內(nèi),因而它非常適合于以語音為主要回聲信號的非平穩(wěn)混響環(huán)境。為防止因快速收斂特性而可能導(dǎo)致的快速發(fā)散,本文還提出利用基于近端信號非平穩(wěn)程度的自適應(yīng)平滑因子,從而保證了算法的穩(wěn)定性。
本文后續(xù)部分安排如下:首先介紹用于聲學(xué)回聲控制的模型近似及頻域逐級回歸算法,同時提出一個時頻依賴的平滑因子及隨機(jī)幅度譜最小值約束,從而實(shí)現(xiàn)一個完整的聲學(xué)回聲控制算法。然后,對該方法和一個分塊頻域自適應(yīng)濾波器(PartitionedBlock Frequency Domain Adaptive Filter, PBFDAF)結(jié)合自適應(yīng)控制的實(shí)現(xiàn)[2,3,18]進(jìn)行了多種條件下的性能對比測試,最后給出結(jié)論。
2 問題分析及逐級回歸介紹
2.1 模型近似
設(shè)麥克風(fēng)信號表示為

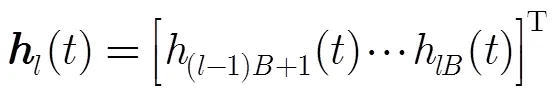


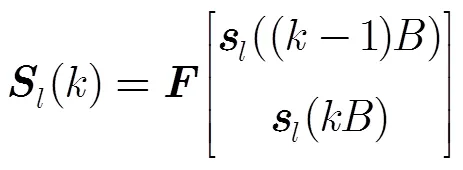

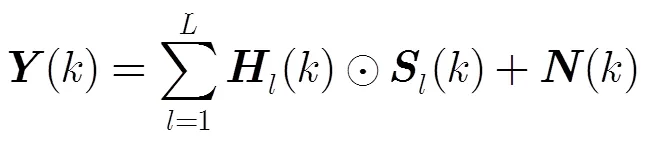

2.2 逐級回歸

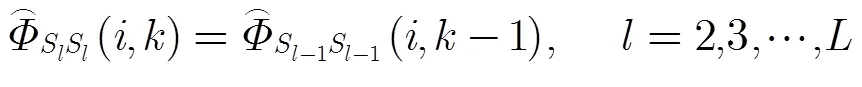
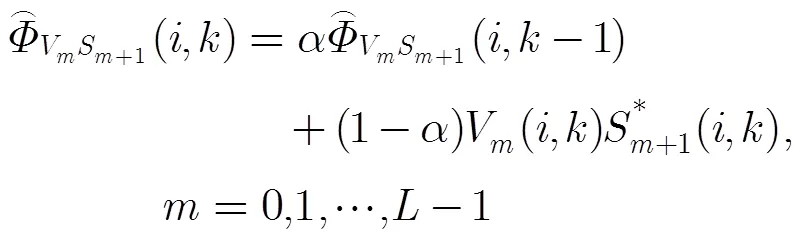
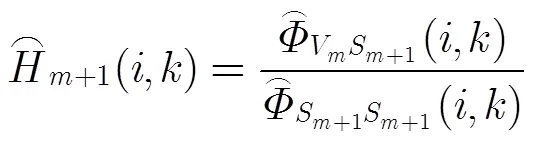
相應(yīng)的殘差為
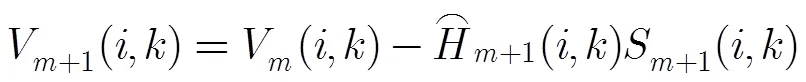
2.3 由非平穩(wěn)程度控制的自適應(yīng)平滑
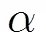
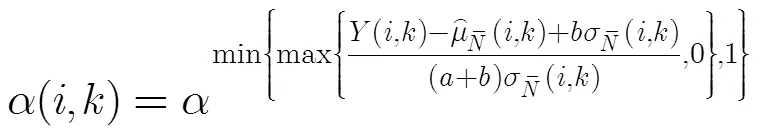
2.4 信號重建和過減
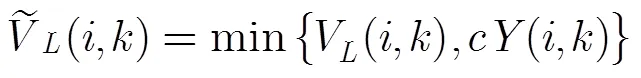
由于本文的方法具有快速收斂的特性,可以不必采用基于相干函數(shù)估計(jì)的后處理。但是在混響環(huán)境中,實(shí)際回聲路徑的模型階數(shù)較高,所以可能存在建模不足問題。而且,第2.1節(jié)中的模型近似會帶來一定偏差,可能導(dǎo)致一定殘余回聲。為進(jìn)一步抑制回聲,可以考慮采用幅度譜過減,并通過在時間維度上加入平滑處理來消除過減帶來的音樂噪聲。然而,這種處理會在近端語音的起始時刻引入失真。為此,本文不采用時間維度上的平滑,而利用隨機(jī)的幅度譜最小值約束,不僅避免了音樂噪聲,而且保持了語音起始端的音質(zhì)。隨機(jī)幅度譜最小值約束不需引入額外的隨機(jī)噪聲添加模塊,并能獲得更自然的背景噪聲。在此約束下,近端語音的過減估計(jì)為
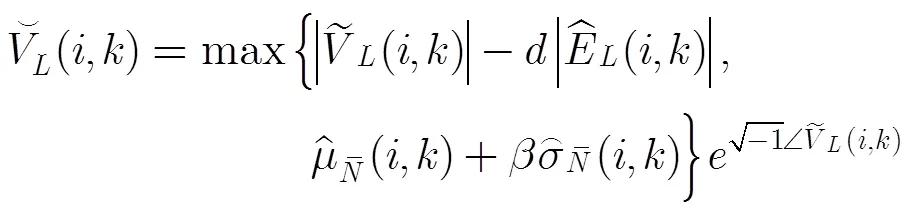

采用上述構(gòu)架,可以在需要時方便的加入背景噪聲抑制處理,本文在此不作進(jìn)一步討論。
3 實(shí)驗(yàn)和分析
根據(jù)引言分析,相對于傳統(tǒng)方法,本文提出的估計(jì)子具有更快的收斂速度以及對雙講和回聲路徑突變的相對魯棒性。并且,由于近端持續(xù)存在的背景噪聲對系統(tǒng)辨識的方差下界的制約,可以預(yù)期模型近似和逐級回歸的偏差在近端存在一定水平噪聲時表現(xiàn)不明顯。實(shí)驗(yàn)中,對本文提出的方法和PBFDAF結(jié)合自適應(yīng)控制方法的一個公開實(shí)現(xiàn)Speex[2,3,18],在不同的回聲和本地平穩(wěn)噪聲比值的條件下進(jìn)行了對比測試。
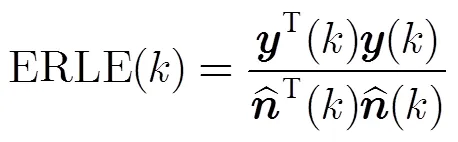
算法的瞬態(tài)特性通過短時上的ERLE和LSD來考察。回聲和本地平穩(wěn)噪聲比(Echo-to-Noise-Ratio, ENR)為10 dB和20 dB時的情形分別如圖1,圖2所示。為更清晰地進(jìn)行對比,圖中縱軸表示本文算法相對Speex的ERLE提高量。在兩種情況下,本文方法的收斂速度都更快,并在0~4 s和10~14 s的時間段上取得了更高的ERLE。當(dāng)ENR=20 dB,即近端背景噪聲相對回聲較弱時,Speex在部分時段取得相對本文算法稍高的ERLE。但是,當(dāng)近端信號中包含一定程度的背景噪聲時,如ENR=10 dB時,本文算法在幾乎整個20 s的時間上都取得了更高的ERLE。由此可見,本文算法非常適合于以語音為主要回聲信號的室內(nèi)混響環(huán)境。另外,本文算法50%和25%幀移的表現(xiàn)較為接近,但25%幀移的表現(xiàn)相對更好。
表1~表4顯示的結(jié)果由10次隨機(jī)抽取音頻后的測試指標(biāo)平均得到,以綜合考察非平穩(wěn)的近端語音和回聲信號在不同的時頻重疊情況下的算法表現(xiàn)。ERLE在整個時間段上計(jì)算。從表1,表2中可以看出,本文的方法在各種情況下均取得了更大的回聲衰減量,而表3和表4顯示近端語音損傷沒有增大,可懂度并沒有受到太大影響。同時,25%幀移的情況性能表現(xiàn)總體更好,但計(jì)算量更大。
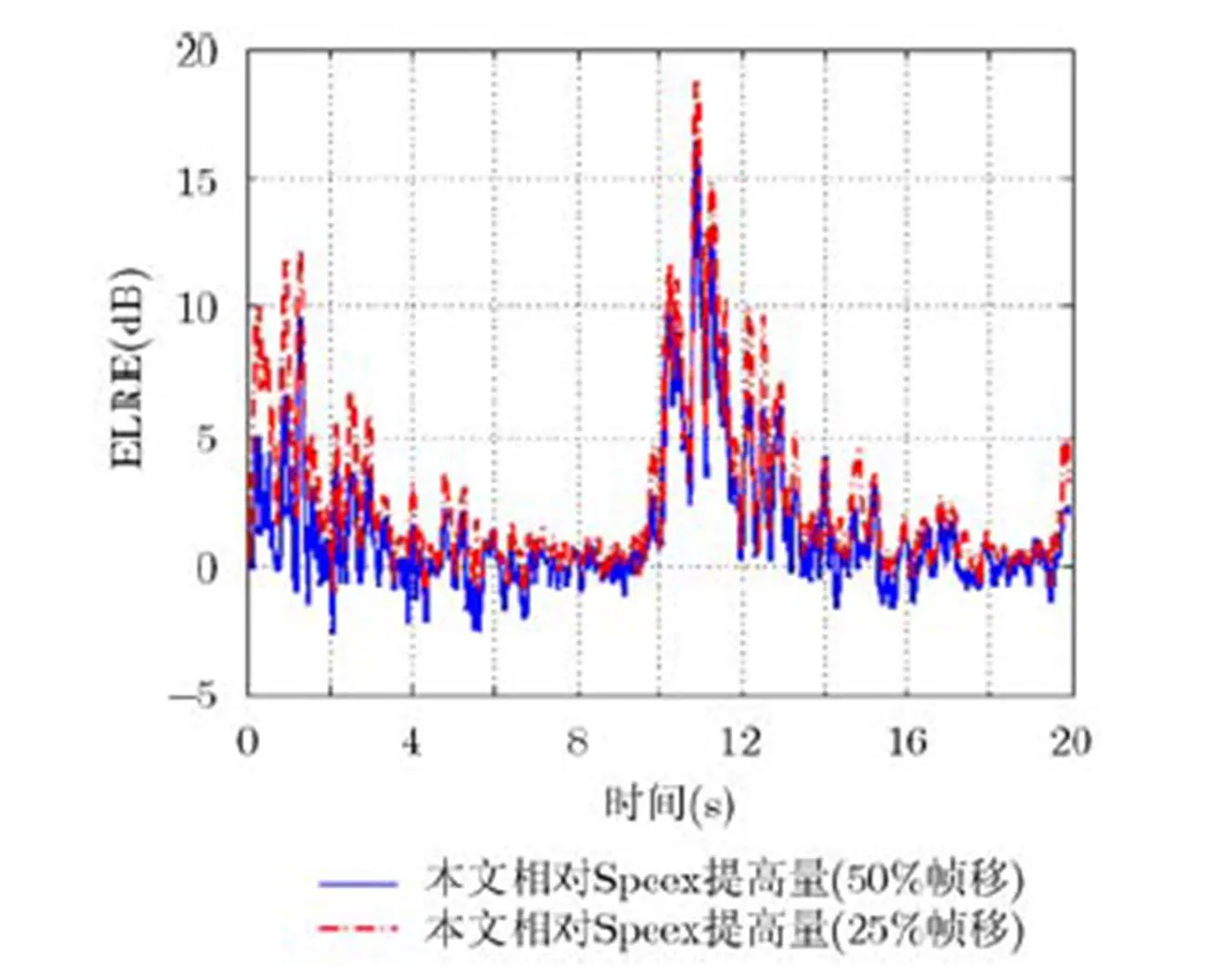
圖1 10 dB回聲噪聲比時,單講情況下的短時ERLE對比測試
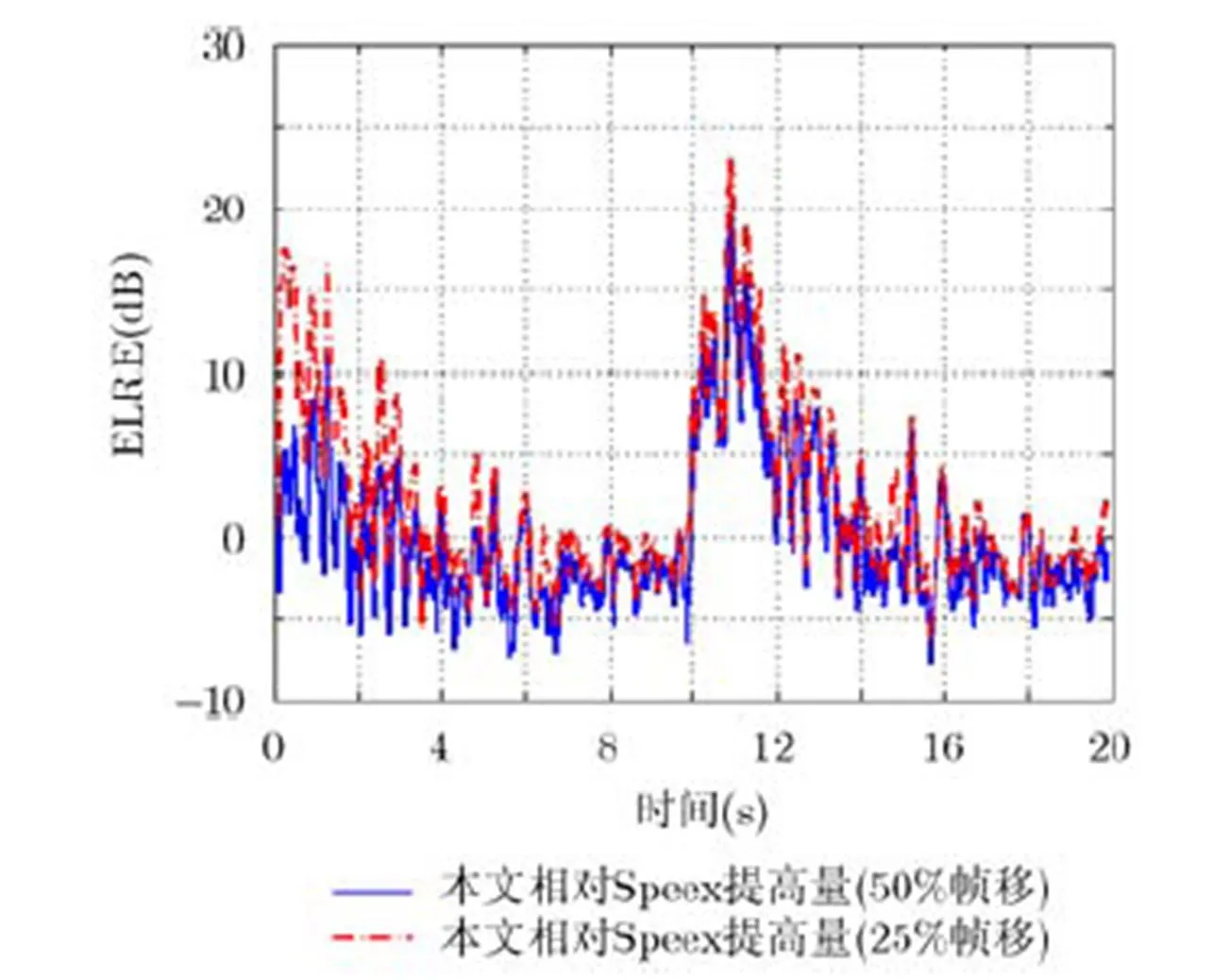
圖2 20 dB回聲噪聲比時,單講情況下的短時ERLE對比測試
由于常見的室內(nèi)遠(yuǎn)講或免提語音通信和人機(jī)交互應(yīng)用環(huán)境中,通常存在一定程度的背景噪聲以及不可避免的電路噪聲,且聲學(xué)環(huán)境可能存在各種因素引起的擾動或者突變,本文方法相對于傳統(tǒng)方法會在總體回聲抑制量上表現(xiàn)出顯著優(yōu)勢。另外在非正式的主觀測聽中,本文注意到由于本文方法較快的收斂速度和自適應(yīng)的隨機(jī)幅度譜最小值約束,殘余回聲通常較白,因而也相對不容易被聽覺感知。

表2 “雙講”時的ERLE(dB)
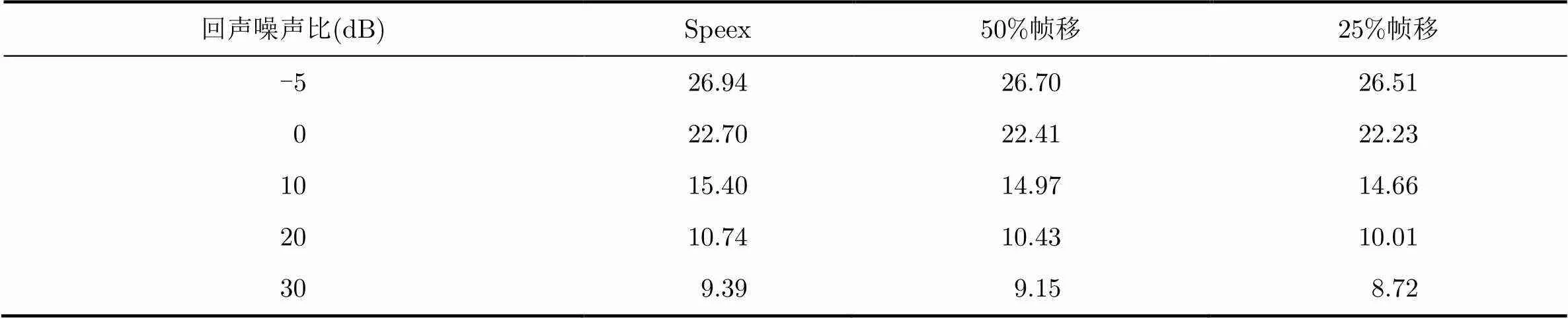
表3 “雙講”時的LSD(dB)

表4 “雙講”時的STOI
4 結(jié)束語
針對聲學(xué)回聲控制應(yīng)用中,作為回聲的語音信號非白,以及實(shí)際聲學(xué)環(huán)境中常見的回聲路徑較長且往往不能確保持續(xù)穩(wěn)定的特點(diǎn),本文提出了一種將逐級回歸分析方法在頻域處理框架下應(yīng)用于聲學(xué)回聲控制問題的算法。分級的加權(quán)最小二乘估計(jì)確保了算法的快速收斂和抗近端非平穩(wěn)干擾的穩(wěn)健特性。同時在不同近端噪聲水平下的實(shí)驗(yàn)表明,本文的算法在常見噪聲水平下的語音應(yīng)用中,能夠獲得很好的模型近似,估計(jì)偏差較小。與一個公開的PBFDAF結(jié)合自適應(yīng)控制的算法實(shí)現(xiàn)的對比實(shí)驗(yàn)顯示,在存在系統(tǒng)突變的環(huán)境下,本文方法在總體回聲抑制量上顯示出明顯的優(yōu)勢,同時在雙講時很好地保持了近端語音質(zhì)量。進(jìn)一步的研究可以考慮針對具體應(yīng)用場景的特點(diǎn),在建模誤差和估計(jì)偏差以及方差之間取得更適當(dāng)?shù)钠胶狻?/p>
[1] Sondhi M. An adaptive echo canceller[J]., 1967, 46(3): 497-511.
[2] Soo J S and Pang K K. Multidelay block frequency domain adaptive filter[J].,, 1990, 38(2): 373-376.
[3] Valin J M. On adjusting the learning rate in frequency domain echo cancellation with double-talk[J]., 2007, 15(3): 1030-1034.
[4] Gupta V K, Chandra M, and Sharan S N. Acoustic echo and noise cancellation system for hand-free telecommunication using variable step size algorithms[J]., 2013, 22(1): 200-207.
[5] Mayyas K. A variable step-size selective partial update LMS algorithm[J]., 2012, 23(1): 75-85.
[6] 張琦, 王霞, 王磊, 等. 自適應(yīng)回波抵消中變步長 NLMS 算法[J]. 數(shù)據(jù)采集與處理, 2013, 28(1): 64-68.
Zhang Qi, Wang Xia, Wang Lei,..Variable step-size NLMS algorithm in echo cancellation[J].&, 2013, 28(1): 64-68.
[7] Gansler T, Hansson M, Ivarsson C J. A double-talk detector based on coherence[J]., 1996, 44(11): 1421-1427.
[8] Tashev I J. Coherence based double talk detector with soft decision[C]. IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 2012: 165-168.
[9] Benesty J, Morgan D, and Cho J H. A new class of doubletalk detectors based on cross-correlation[J]., 2000, 8(2): 168-172.
[10] Schuldt C, Lindstrom F, and Claesson I. A delay-based double-talk detector[J]., 2012, 20(6): 1725-1733.
[11] Avendano C. Acoustic echo suppression in the STFT domain[C]. 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics,New Platz, NY, USA,2001: 175-178.
[12] Faller C and Chen Jing-dong. Suppressing acoustic echo in a spectral envelope space[J]., 2005, 13(5): 1048-1062.
[13] Wada T S and Juang B H. Enhancement of residual echo for robust acoustic echo cancellation[J]., 2012, 20(1): 175-189.
[14] Shrawankar U and Thakare V M. Acoustic echo cancellation postfilter design issues for speech recognition system[J]., 2011, 1(5): 38-43.
[15] Gustafsson S, Martin R, and Vary P. Combined acoustic echo control and noise reduction for hands-free telephony[J]., 1998, 64(1): 21-32.
[16] Enzner G, Martin R, and Vary P. Partitioned residual echo power estimation for frequency-domain acoustic echo cancellation and postfiltering[J]., 2002, 13(2): 103-114.
[17] Draper N R and Smith H. Applied Regression Analysis[M]. New York: Wiley Series in Probability and Mathematical Statistics, 1981: 337-341.
[18] Jonathan Rouach:Ported Speex AEC mdf algorithm from C to Matlab[OL]. https://github.com/wavesaudio/Speex-AEC- matlab. 2014.01.
[19] Doblinger G. Computationally efficient speech enhancement by spectral minima tracking in subbands[C]. Proceedings of EUROSPEECH, Madrid, Spain, 1995: 1513-1516.
[20] Cohen I. Analysis of two-channel generalized sidelobe canceller (GSC) with post-filtering[J]., 2003, 11(6): 684-699.
姜開宇: 男,1986年生,博士生,研究方向?yàn)檎Z音信號處理、陣列信號處理.
吳 超: 男,1988年生,博士生,研究方向?yàn)檎Z音信號處理.
國雁萌: 女,1976年生,副研究員,研究方向?yàn)檎Z音信號處理、傳聲器陣列、語音識別.
付 強(qiáng): 男,1972年生,研究員,研究方向?yàn)檎Z音信號處理、傳聲器陣列.
顏永紅: 男,1967年生,研究員,研究方向?yàn)檎Z音識別、語音搜索、機(jī)器學(xué)習(xí)、模式識別.
Acoustic Echo Control Based on Frequency-domain Stage-wise Regression
Jiang Kai-yu Wu Chao Guo Yan-meng Fu Qiang Yan Yong-hong
(,,100190,)(,,100190,)
Traditional echo control techniques as Partitioned Block Frequency Domain Adaptive Filter (PBFDAF) with stochastic gradient adaptive method usually endure slow convergence and insufficient echo suppression in reverberant room when the echo is speech and the echo path is unstable. An algorithm based on frequency domain stage-wise regression is proposed for acoustic echo control to achieve faster convergence of the system estimation with insignificant bias. Commonly used additional double-talk detector and inter-channel coherence based residual echo suppressor are not needed since short-time coherence analysis is performed in each stage. By further making mild assumptions on the quasi-stationarity of the near-end background noise, both fast convergence and stability of the estimation can be achieved simultaneously with a non-stationarity controlled smoothing factor. Experiments are carried out to show the superiority of the proposed approach in terms of convergence speed and steady state error in distant talking mode in ordinary room environment with various common levels of background noise.
Speech signal processing; Acoustic echo control; Stage-wise regression; Acoustic echo cancellation; Acoustic echo suppression
TN912.3
A
1009-5896(2014)12-2896-06
10.3724/SP.J.1146.2014.00131
姜開宇 jiangkaiyu@hccl.ioa.ac.cn
2014-01-20收到,2014-04-18改回
國家自然科學(xué)基金(10925419, 90920302, 61072124, 11074275, 11161140319)和中國科學(xué)院戰(zhàn)略性先導(dǎo)科技專項(xiàng)(XDA06030100)資助課題
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
中國生殖健康(2019年3期)2019-02-01 06:12:26
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機(jī)械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學(xué)學(xué)報(bào)(2015年3期)2015-11-11 17:20:00
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
