一種內核級多進程負載均衡會話保持方法
2014-06-02 06:34:24張穎楠顧乃杰彭建章王國澎魏振偉
計算機工程 2014年3期
關鍵詞:進程
張穎楠,顧乃杰,彭建章,王國澎,魏振偉
一種內核級多進程負載均衡會話保持方法
張穎楠1a,1b,1c,顧乃杰1a,1b,1c,彭建章1a,1b,1c,王國澎2,魏振偉1a,1b,1c
(1. 中國科學技術大學 a. 計算機科學與技術學院;b. 安徽省計算與通訊軟件重點實驗室; c. 中國科學技術大學中科院沈陽計算所網絡與通信聯合實驗室,合肥 230027;2. 國家高性能集成電路設計中心,上海 201204)
針對多進程負載均衡無法保持會話的問題,提出一個基于epoll機制的內核級高效解決方法。對于每個新建立的連接,在epoll的通知機制中使用源地址哈希算法,由epoll通知哈希選出的進程接收此連接,期望通過為同一個IP地址的請求選擇同一個負載均衡服務進程,保證該進程依據自身記錄的會話信息將同一個客戶的請求轉發給同一個后端服務器。此外,通過分析多隊列網卡的特性,給出維持收包發包中斷、軟中斷、協議棧處理、用戶態處理都在同一個核上的優化方法,以提高cache性能。實驗結果表明,該方法能解決基于epoll的多進程負載均衡服務器的會話保持問題,并且在多核處理器多隊列網卡環境下通過優化使cps提高12%,數據吞吐量提高4.6%。
多隊列網卡;多核;epoll機制;源地址哈希;會話保持
1 概述
網絡負載均衡[1]作為一種滿足大規模并發訪問服務的有效解決方案被廣泛使用。會話保持是網絡負載均衡服務器需要提供的重要功能,要求負載均衡服務器將攜帶相同會話信息的請求交給同一服務器處理。
為了充分利用多核處理器,現今的網絡負載均衡服務器一般采用多進程并發模式。對于基于socket的負載均衡服務器,在多進程服務模式下,多個進程共享同一個socket,與該socket建立的連接被哪個進程接收具有不確定性,客戶攜帶相同會話信息的多次請求被交由不同的進程處理,由于每個負載均衡服務進程分別保存各自的會話保持信息表,不能保證為同一客戶的請求選擇同一個后端服務器,因此無法做到會話保持。
由于攜帶同樣會話信息的請求來自同一客戶,本文提出了一種內核級的解決方案,旨在通過為同一客戶請求選擇同一用戶態服務進程處理來實現會話保持,在epoll[2]機制中基于源地址哈希選擇性地喚醒一個進程服務,以實現同一IP的請求交給同一進程處理,同時充分利用中斷親和性和進程親和性對內核協議棧及網卡的發包收包過程進行優化。
2 相關工作
針對多進程并發負載均衡服務器的會話保持問題,一種很普遍的解決方案是多個進程之間共享會話信息表,這種方式并發訪問的鎖操作會帶來較大的性能開銷,并且從單進程向多進程升級時需要修改程序框架。文獻[3]提出了一種方式,通過修改從內核空間到用戶空間傳遞請求部分的邏輯,從偵聽狀態的socket請求接收等待隊列上選擇一個進程,將連接請求傳遞到用戶空間,并保證同一個客戶的請求發給同一個用戶態服務進程。這種方法可以實現會話保持,也不存在鎖操作,但現在大多數基于Linux的負載均衡服務器都是利用epoll機制高效地管理網絡I/O事件的,這種基于Linux epoll機制的服務器程序在多進程模式下多會遇到驚群現象[4],當注冊事件發生時喚醒所有進程競爭,最終結果也只有一個進程成功,造成資源浪費。而文獻[3]并沒有解決這種驚群問題。
針對Linux操作系統內核中數據包接收和發送過程,有以下優化手段:
針對單隊列網卡,谷歌公司提出了Linux內核補丁RPS(Receive Packet Steering)[5],用軟件模擬的方式實現了多隊列網卡所提供的功能。對數據流通過hash進行歸類,將多核系統中數據接收時的負載分布在不同的核上,充分利用多核,提高網絡性能。
但RPS僅僅是把同一流的數據包分發給同一個核處理,這就有可能出現給該數據流分配執行軟中斷的核與操作該數據流的用戶態程序所在的處理器核不一致,仍會對cache性能造成影響,因此在RPS的基礎上谷歌公司又提出了RFS(Receive Flow Steering)[6]配合RPS使用,確保操作該數據流的應用程序與處理軟中斷在同一個核上,更加充分地利用cache。但RPS和RFS最適合在單隊列網卡環境下 使用。
除了對數據包接收過程性能的優化,谷歌又提出了針對多隊列網卡數據包發送過程的優化XPS(Transmit Packet Steering)[7]。
在發送數據包時,XPS會根據當前發送過程所在的核來選擇對應的硬件發送隊列,使得處理過程在同一個核上的數據包選擇相同的發送隊列,提高了cache的效率。但這種方法仍然會引起其他方面的cache行震蕩,也就是說,網卡發送完數據包向其中一個核發出中斷,這個核并不一定是處理數據包發送流程所在的核。
3 基于epoll的多進程負載均衡器會話保持
3.1 Linux內核的epoll機制
epoll[2]是一個異步事件的通知機制,可通知某個就緒的文件描述符事件,常用于網絡I/O事件管理。
用戶態程序通過epoll_create()創建epoll的句柄,即一個epoll監控容器,維護需要監控的socket事件;使用epoll_ctl()系統調用可以向容器中注冊某個sock上的監控事件并設置回調函數;系統調用epoll_wait()將當前進程掛載在當前容器的等待隊列上并進入可中斷掛起狀態,等待已注冊事件發生后被喚醒。
在基于epoll機制的多進程服務器模型中,多個進程間共享偵聽狀態的socket,這些進程都把該socket加入到epoll關注事件中,并阻塞在epoll_wait上等待監控事件發生。
當設備就緒即socket注冊事件發生時,調用設備等待節點上注冊的喚醒回調函數,把就緒事件加入到就緒隊列,并喚醒所有等待進程,這些進程在用戶態競爭后續accept操作,但最終只有一個進程成功,這樣便會發生驚群現象[4],造成資源浪費。而且所有共享此偵聽狀態socket的進程都被喚醒競爭此連接,最終成功建立連接的進程并不確定,無法做到同一個客戶的請求交由同一個進程處理。基于以上分析和考慮,本文設計了在epoll喚醒回調機制中基于源地址哈希算法選擇性地喚醒一個服務進程的方案。
3.2 基于源地址哈希的會話保持方案
本文期望可以按某種規則有選擇地喚醒其中一個進程,而非全部,這樣既可以避免驚群現象,也可以在規則設計合適的情況下實現來自同一個客戶的請求交給同一個進程處理的會話保持需求。
如圖1所示,本文采取對數據包源地址哈希來選擇進程,在喚醒回調函數中進行規則判斷,源地址哈希值落在某個等待進程上,就會將就緒事件插入到該進程的epoll就緒隊列中,并喚醒該進程進行后續的操作。采用數據包源地址哈希的方法選擇處理進程使得來自同一個客戶的請求都交由同一個進程處理,從而滿足會話保持的要求。
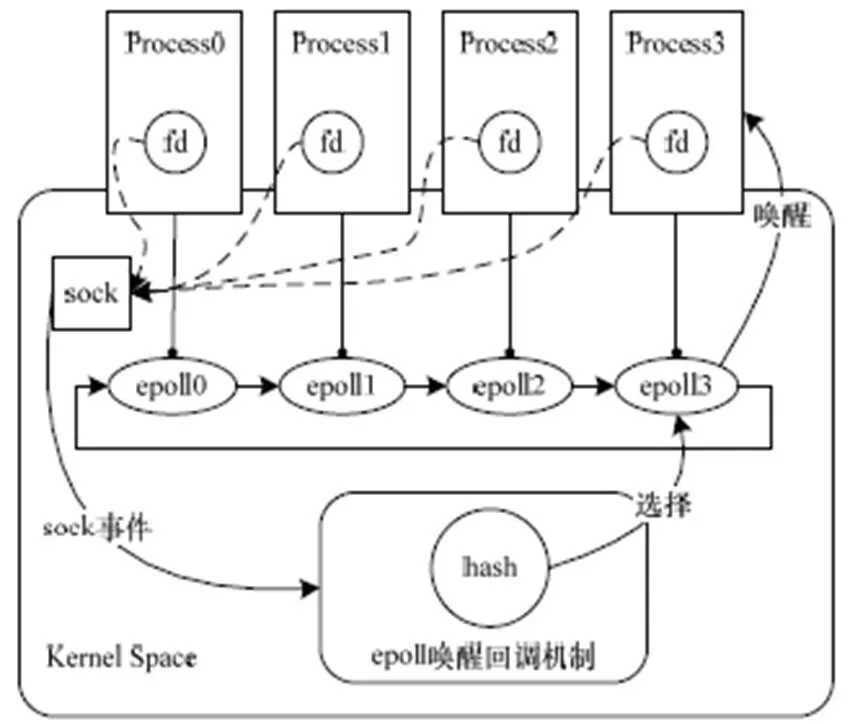
圖1 epoll機制中源地址哈希選擇喚醒進程
對于存在某個進程退出或者加入新的進程共享同一個socket的情況,本文加入一致性哈希算法[8]來減弱這種情況發生時對會話保持的影響。
因此,根據一致性哈希算法,整個會話保持方案如下:
(1)構造一致性哈希桶:對于同一個共享的socket,當每個進程向epoll容器中注冊該socket的關注事件時,由于每個進程都擁有各自不同的epoll容器對象,因此將容器對象的地址值通過哈希映射到一個32位的鍵值上,也就是0~232-1次方的數值,可以把這個數值空間映射到一個首(0)尾(232-1)相接的圓環,如圖2所示。

圖2 一致性哈希算法在選擇進程時的應用場景
(2)源地址哈希映射數據包:當有數據包到達時,根據數據包的源IP地址作哈希映射到同一個哈希數值空間中,即圖2圓環。
(3)選擇處理進程:在為數據包選擇處理進程時,從數據包計算所得哈希值出發,在環形空間中按順時針方向遇到的第一個進程哈希節點所對應的進程即處理該數據包的進程,如圖2虛線箭頭所指。
當有新進程加入或進程退出時,影響范圍僅是很少部分,而非整個范圍的震蕩。
該方案包括2個哈希函數,分別為對進程節點的哈希和對數據包源地址哈希,為了盡可能將進程節點及數據包的哈希值分散到232即32位數值空間中,本文選擇如下RSS哈希[9]算法:
ComputeHash(input[], N);
其中,input[]為epoll容器對象的地址值或數據包的源IP地址;N為輸入數據的字節數。算法描述如下:
(1)當系統啟動時,隨機生成一個320比特位的K,存 儲在數組中,數組每一個成員為一個字節,即K[0]K[1] K[2]…K[39]。
(2)初始化哈希結果值為0。
(3)對輸入的每一比特位循環,如果該位為1,則將結果值異或K最左邊的32位。
(4)左移一位K,進入步驟(3)的下一輪循環。
4 性能優化
本節針對多隊列網卡和多核環境對會話保持方案從收包發包流程方面做了優化。
4.1 從網卡到用戶態程序接收數據包流程的優化
多隊列網卡有多個硬件接收隊列,網卡在硬件層次直接對數據包使用哈希部件分流,放在不同的隊列中,多隊列網卡的哈希函數可以配置。既可以選擇對源目的IP地址和源目的端口作哈希,也可以配置為僅依據源目的IP地址計算哈希值的方式,比如intel82580網卡[9]。
在接收數據包的過程中,為了充分利用局部性原理,降低cache刷新頻率,提高其命中率,需要盡可能滿足如下條件:
(1)將特征相似的數據包分配給同一個CPU處理。
(2)同一個數據包的硬件中斷處理過程、軟中斷處理過程以及用戶態應用程序接收處理數據包的過程在同一個核上。
基于上述條件,期望在多隊列網卡多核環境下,網卡硬件哈希為數據包選擇的接收隊列綁定的核與epoll的喚醒回調函數中源地址哈希選擇的處理進程綁定的核是同 一個。
配置網卡使用僅對數據包源目的地址哈希的函數選擇隊列時,由于數據包目的地址不變,相當于在網卡硬件層對數據包做源地址哈希,交給不同的硬件隊列。在這種配置下,將用戶態進程綁定于固定的處理器核,利用中斷親和性為每個硬件隊列綁定唯一的處理器核,只需記錄下數據包硬中斷處理過程所在的核,向上傳遞,在epoll層次選擇同樣處理器核上的進程喚醒,如圖3所示,這個進程已然是源地址哈希選擇的結果,滿足會話保持的要求。

圖3 數據包接收過程中期望的接收隊列、CPU、進程間狀態
本文結合第3節中的會話保持方案將數據包接收流程修改如下:
(1)網卡接收數據包經過哈希落在某個硬件隊列上。
(2)網卡發出硬中斷給該隊列所綁定的CPU核,將數據包掛在該CPU的處理隊列上。
(3)記錄下處理硬中斷的CPU核存儲于skbuff(數據包在內核態的存儲形式),并觸發軟中斷過程執行內核協議棧的解析與處理。
(4)當該數據包為SYN包并且sock處于LISTEN狀態時,拷貝數據包的CPU核到sock中,向上層傳遞此記錄,并觸發sock上掛載的設備等待隊列調用喚醒回調函數。
(5)在使用epoll機制的情況下,喚醒回調函數的主要工作是掛載就緒事件到就緒隊列并喚醒等待進程。在選擇用戶態進程喚醒時,根據下層記錄的處理器核,選擇性地只喚醒綁定在該核上的用戶態進程。
(6)判斷當前處理器核綁定的進程:如果當前處理器核上綁定了唯一的進程,則喚醒該進程;如果當前處理器核綁定了不止一個進程,則獲取數據包的源IP地址作哈希,根據哈希值從該處理器核綁定的所有進程中選擇一個喚醒;如果當前處理器核沒有綁定進程,則將下一個處理器核作為當前處理器核,重新執行操作(6)。
4.2 從用戶態程序到網卡發送數據包流程的優化
數據包發送過程包括:應用程序將響應數據包遞交給內核;內核網絡協議棧封裝數據包向下層遞送;選擇發送隊列;網卡發送隊列中斷處理。其中,網卡發送中斷處理的主要工作是刪除數據包或重發數據包,該中斷在網卡發送數據完數據包時觸發。
為了在發送數據包過程中充分利用多隊列網卡和多核環境,提高發送數據的局部性,最理想的情況是將上述一系列發送數據包的流程都放在同一個處理器核上,如圖4所示。關鍵就是要為數據包選擇合適的硬件發送隊列,使得硬件發送隊列中斷綁定的處理器核與數據包在內核協議棧中處理過程所在的核為同一個。

圖4 數據包發送過程中期望的進程、CPU、發送隊列間的狀態
使用中斷親和性綁定發送隊列到唯一的處理器核上,在此前提下,本節設計的發送隊列選擇方法如下:
(1)獲取當前數據包內核協議棧處理過程所在的 CPU核。
(2)判斷該CPU核上綁定的發送隊列個數。
(3)如果處理器核對應唯一的發送隊列,則返回此隊列號——在這種情況下,硬件發送隊列發送成功或失敗后觸發中斷,中斷處理過程刪除數據包或重發數據包等操作都集中在之前發送過程的同一個核上完成。
(4)如果處理器核上綁定的隊列數大于1,則依據數據包的哈希值從綁定的隊列集合中選擇。
(5)如果處理器核上綁定的隊列數等于0,則依據數據包的哈希值從網卡所有可用隊列中選擇。
5 實驗結果與分析
5.1 實驗環境
為應對壓力測試,需要提供高性能的服務器作為測試機,以使負載均衡處理不會成為瓶頸;選用多隊列網卡使數據包收發流程充分利用優化特性。測試環境如表1所示。

表1 測試環境
5.2 會話保持測試
HAProxy為基于epoll的負載均衡軟件,存在多進程會話不能保持的問題,本節選擇該軟件作為測試例程。在不同的客戶端上使用curl工具向HAProxy監聽的地址發送http請求,發現同一個客戶發送的請求交給了同一個進程處理,表明實現了多進程會話保持的目的。
同時利用測試儀環境測試請求處理轉發的正確性,圖5所示的測試結果表明,在壓力測試下,數據包處理的正確率為100%。

圖5 基于修改后內核的數據包處理結果
5.3 性能測試
5.3.1 實驗方法
為測試本文方法在大規模訪問壓力下并未限制整體性能相反有所提高,采用了如下實驗方法:(1)關閉中斷負載均衡irqbalance服務;(2)內核關閉RPS;(3)設置網卡中斷親和性:使網卡隊列與處理器核綁定;(4)設置進程親和性:進程分別綁定在不同的處理器核上;(5)測試儀配置:模擬100個客戶端,6個服務器端,1個負載均衡代理服務器HAProxy。客戶端同時向HAProxy發送請求,測試HAProxy的響應速度和吞吐量。
5.3.2 結果分析
每秒處理連接數(cps)反映測試程序HAProxy在當前內核及硬件平臺下處理請求的速度。圖6和圖7為cps的測試結果,縱軸表示每秒新增連接個數,橫軸為時間軸,基于本文修改后的內核運行HAProxy每秒處理請求數平均在93 000左右,而未修改2.6.35內核下cps平均在83 000左右,表明修改后的內核處理速度有12%的提升,更能充分利用多核和多隊列網卡硬件環境。吞吐量(throughout)表示每秒處理的數據總量。利用IxLoad測試儀模擬100個客戶端,向HAProxy請求大小為1 MB的數據。測試結果如 圖8和圖9所示,縱軸表示每秒處理的數據總量,橫軸為時間軸,在一段時間的試探期后數據會穩定在一定范圍內。修改前的內核運行HAProxy吞吐量基本都維持在2.2 Gb左右,修改后平均維持在2.3 Gb,提升在4.6%左右。

圖6 基于修改后內核的每秒處理連接數

圖7 基于原2.6.35內核的每秒處理連接數

圖8 基于修改后內核的吞吐量

圖9 基于原2.6.35內核的吞吐量
6 結束語
本文提出一種在epoll機制中根據數據包源地址哈希結果選擇性喚醒處理進程的方法,有效地解決了基于epoll的多進程負載均衡服務器的會話保持問題。與以往的研究工作相比,在滿足會話保持要求的同時解決了epoll機制在多進程環境下多出現驚群現象的問題,而且基于修改后的內核將單進程的負載均衡服務向多進程擴展時也不需要大規模修改用戶態服務程序。此外,對多隊列網卡和多核處理器環境下的會話保持方案做了針對性優化,實驗結果顯示,優化方案對于上述網絡環境有很好的性能提升。但本文的解決方法仍然基于共享的sock,在內核態中共享的sock依舊會帶來互斥鎖的開銷,不利于網絡性能的進一步提升。下一步工作的主要方向是期望解決多進程偵聽在同一個地址上提供相同的服務時,如何能夠更有效地利用多核,減少內核中鎖的開銷,提高并行性。
[1] 李 輝. 網絡服務器負載均衡的研究與實現[D]. 大連: 大連海事大學, 2003.
[2] Libenzi D. Improving (Network) I/O Performance[EB/OL]. (2002-10-30). http://www.xmailserver.org/Linux-patches/nio- improve.html.
[3] Liu Xi, Pan Lei, Wang Chongjun, et al. A Lock-free Solution for Load Balancing in Multi-core Environment[C]//Proc. of the 3rd International Workshop on Intelligent Systems and Applications. Wuhan, China: [s. n.], 2011: 1-4.
[4] Molloy S P, Lever C. Accept() Scalability on Linux[C]//Proc. of USENIX Annual Technical Conference. San Diego, USA: [s. n.], 2000: 121-128.
[5] Herbert T. RPS: Receive Packet Steering[EB/OL]. (2010-09- 01). http://1wn.net/Articles/361440.
[6] Herbert T. RFS: Receive Flow Steering[EB/OL]. (2010-09-01). http://1wn.net/Articles/381955.
[7] Herbert T. XPS: Transmit Packet Steering[EB/OL]. (2010-10- 26). http://1wn.net/Articles/412062.
[8] Karger D, Lehman E, Leighton T, et al. Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web[C]//Proc. of the 29th Annual ACM Symposium on Theory of Computing. New York, USA: ACM Press, 1997: 654-663.
[9] Intel Corporation. Intel 82580EB/82580DB Gigabit Ethernet Controller Datasheet[EB/OL]. (2012-09-07). http://www.intel. com/content/www/us/en/ethernet-controllers/82580-eb-db-gbe-controller-datasheet.html.
[10] Ixia Corporation. IxLoad[EB/OL]. (2011-07-07). http://www. ixiacom.cn/products/applications/ixload.
[11] Tarreau W. HAProxy: The Reliable, High Performance TCP/ HTTP Load Balancer[EB/OL]. (2011-09-10). http://haproxy. 1wt.eu.
[12] 周少濤. 基于HAProxy的TCP長連接復用的研究與實 現[D]. 廣州: 華南理工大學, 2011.
編輯 任吉慧
A Kernel Level Session-persistence Method for Multi-process Load Balancing
ZHANG Ying-nan1a,1b,1c, GU Nai-jie1a,1b,1c, PENG Jian-zhang1a,1b,1c, WANG Guo-peng2, WEI Zhen-wei1a,1b,1c
(1a. School of Computer Science and Technology; 1b. Anhui Province Key Laboratory of Computing and Communication Software; 1c. USTC&SICT Network and Communication Joint Laboratory, University of Science and Technology of China, Hefei 230027, China; 2. National High Performance IC Design Center, Shanghai 201204, China)
This paper proposes an efficient method at the kernel level to solve the problem how to maintain the session in multi-process load balancing. In the wakeup-callback mechanism of epoll, this method wakes up a certain service process selectively to process the packet and accept this connection according to the source address hash algorithm. It hopes that the requests sharing the same IP address are responded by the same service process. So the requests from the same client are forwarding to the same backend server according to the session information kept in this load balancing process. This paper also devotes to optimize the performance of the procedure of receiving and sending packets. It is an intended way to keep this whole process on the same CPU core to reduce the refresh rate of the CPU cache. Experimental results reflect that the method in this paper achieves the objective to keep the session and also increases cps by 12% and throughput by 4.6% which is based on multi-queue NIC and multi-core processor.
multi-queue network card; multi-core; epoll mechanism; source address hash; session-persistence
1000-3428(2014)03-0076-06
A
TP393.03
“核高基”重大專項(2009ZX01028-002-003-005);高等學校學科創新引智計劃基金資助項目(B07033)。
張穎楠(1988-),女,碩士、CCF會員,主研方向:網絡負載均衡;顧乃杰,博士、博士生導師;彭建章,博士;王國澎、魏振偉,碩士。
2013-03-19
2013-04-23 E-mail:zyn@mail.ustc.edu.cn
10.3969/j.issn.1000-3428.2014.03.016
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58
中國外匯(2019年8期)2019-07-13 06:01:06
電腦愛好者(2018年15期)2018-08-23 17:24:06
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
電腦迷(2012年24期)2012-04-29 00:44:03
中華女子學院學報(2012年6期)2012-03-25 13:52:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
杭州師范大學學報(社會科學版)(2011年3期)2011-04-04 08:58:20
