仿射傳播聚類在室內(nèi)定位指紋庫(kù)中的應(yīng)用研究
2014-07-02 00:21:32張儷文汪云甲王行風(fēng)
測(cè)繪通報(bào) 2014年12期
張儷文,汪云甲,王行風(fēng)
(中國(guó)礦業(yè)大學(xué)環(huán)境與測(cè)繪學(xué)院,江蘇 徐州 221116)
仿射傳播聚類在室內(nèi)定位指紋庫(kù)中的應(yīng)用研究
張儷文,汪云甲,王行風(fēng)
(中國(guó)礦業(yè)大學(xué)環(huán)境與測(cè)繪學(xué)院,江蘇 徐州 221116)
基于位置指紋的室內(nèi)定位,指紋數(shù)據(jù)結(jié)構(gòu)復(fù)雜、信號(hào)時(shí)變性強(qiáng)等原因影響了定位的時(shí)效性。K-means聚類算法雖可以有效地減少數(shù)據(jù)遍歷的工作量,但該方法僅僅考慮了采樣點(diǎn)在信號(hào)域的相關(guān)性,導(dǎo)致定位精度下降,同樣難以滿足室內(nèi)定位的實(shí)時(shí)性要求。本文基于位置指紋方法,借鑒K-means聚類算法的思路,研究了指紋的樣本點(diǎn)位置域和信號(hào)域特征的融合方法,并將融合后的特征引入了仿射傳播聚類算法。試驗(yàn)測(cè)試表明,該方法在保證精度的前提下,可使時(shí)間消耗平均減少40%,有效地提高了系統(tǒng)的實(shí)時(shí)性,可以滿足室內(nèi)定位的基本要求。
室內(nèi)定位;位置指紋;仿射傳播聚類;特征融合
一、引 言
目前,室內(nèi)指紋定位系統(tǒng)的研究主要集中在提高系統(tǒng)的定位精度和系統(tǒng)實(shí)時(shí)性上[1]。提高精度的途徑主要有兩種:一是改進(jìn)定位算法[2-3];二是加密定位中使用的指紋庫(kù)[4-5]。如果參與計(jì)算的點(diǎn)較多,無論是直接插值定位[6-7],還是基于概率分布定位[8-9],在時(shí)間消耗上都會(huì)增加。其中基于概率分布的算法會(huì)有更多的時(shí)間消耗[10];而加密指紋庫(kù)可以得到較高精度的結(jié)果,但也會(huì)增加搜索時(shí)間。因此,減少匹配的數(shù)據(jù)量對(duì)于增強(qiáng)系統(tǒng)的時(shí)效性和提高系統(tǒng)精度十分重要。
對(duì)定位指紋庫(kù)進(jìn)行聚類處理可以很好地降低系統(tǒng)搜索樣本點(diǎn)的數(shù)據(jù)規(guī)模[11-12]。在聚類特征選取上,有使用最強(qiáng)接入點(diǎn)(access point,AP)作為特征的[12],也有使用樣本點(diǎn)(respective point,RP)信號(hào)之間的距離作為特征的[13]。使用最強(qiáng)AP作為特征的聚類處理并不能明顯減少定位計(jì)算量,這是由于無線信號(hào)在室內(nèi)強(qiáng)反射環(huán)境中陰影衰落效應(yīng)較為顯著[14];利用信號(hào)之間的距離作為特征可以很好地避免這種情況[13],但是定位算法的最終目的是確定未知點(diǎn)的位置,僅使用信號(hào)之間的距離并不能很好地反映位置之間的關(guān)系,因此造成定位結(jié)果的精度不高。
本文將指紋庫(kù)中樣本點(diǎn)的信號(hào)特征與位置特征進(jìn)行融合,引入仿射傳播聚類(affinity propagation clustering,APC)方法進(jìn)行聚類,從而實(shí)現(xiàn)指紋庫(kù)的分塊處理。試驗(yàn)場(chǎng)測(cè)試表明,本文使用的聚類算法在保證精度的前提下,可使平均時(shí)間消耗減少40%。
二、原 理
指紋定位區(qū)域中的AP點(diǎn)組成集合B={b1,b2,…,bn},在該區(qū)域中還有人為規(guī)劃的采樣點(diǎn)RP組成的集合L={l1,l2,…,lm}。每一個(gè) L中的元素 li(1≤i≤m)都記錄兩部分?jǐn)?shù)據(jù),一部分是該點(diǎn)的位置向量 Gi=(xi,yi),另一部分是在該點(diǎn)接收到的AP點(diǎn)的信號(hào)強(qiáng)度向量 Vi=(vi,1,vi,2,…,vi,n),其中vi,j(1≤j≤n)表示在li點(diǎn)接收到來自bj的信號(hào)強(qiáng)度。S={s1,s2,…,sn}表示在區(qū)域中的某個(gè)未知位置接收到的信號(hào)強(qiáng)度集合,其中sk(1≤k≤n)表示未知位置接收到來自bk的信號(hào)強(qiáng)度。
1.融合距離與信號(hào)信息的特征提取
在提取聚類特征的過程中,需要使用采樣點(diǎn)在位置域和信號(hào)域的距離。信號(hào)域距離與位置距離類似,文獻(xiàn)[13]中將兩組信號(hào)之間的歐式距離定義為信號(hào)距離SigDisdd,如下
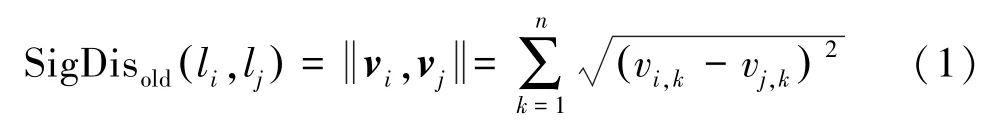
空間距離較近的樣本點(diǎn),搜索的相同AP信號(hào)數(shù)目多;空間距離較遠(yuǎn)的樣本點(diǎn),搜索到的相同AP信號(hào)數(shù)目少。相同AP數(shù)目可以在一定程度上反映樣本點(diǎn)之間的空間距離關(guān)系。因此,在計(jì)算信號(hào)距離時(shí),引入相同AP數(shù)目,可以擴(kuò)大遠(yuǎn)距離點(diǎn)之間的數(shù)值,縮小近距離點(diǎn)之間的數(shù)值。本文改進(jìn)的信號(hào)距離SigDisnew為
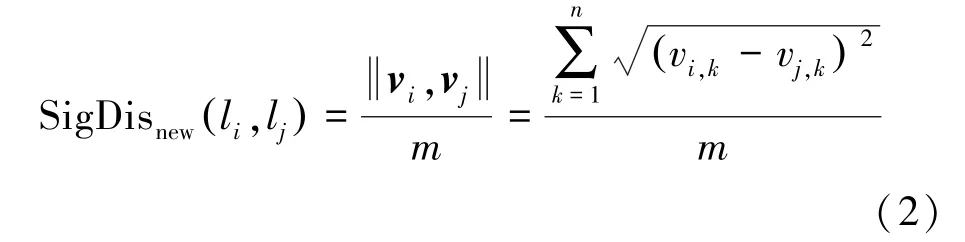
式中,m為(li,lj)點(diǎn)之間的相同AP數(shù)目。
兩采樣點(diǎn)之間的位置域距離GeoDis為
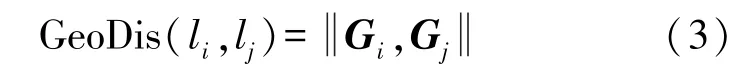
信號(hào)域距離與位置域距離的量綱不同,為了融合特征,試驗(yàn)中使用的距離是歸一化之后的結(jié)果。兩種距離在數(shù)值分布的趨勢(shì)上大體相似,但是由于信號(hào)的不穩(wěn)定性,信號(hào)域距離中噪聲更多。為了排除噪聲的影響,融合特征MixDis利用位置域距離對(duì)信號(hào)域距離進(jìn)行限制。融合特征MixDis的定義為
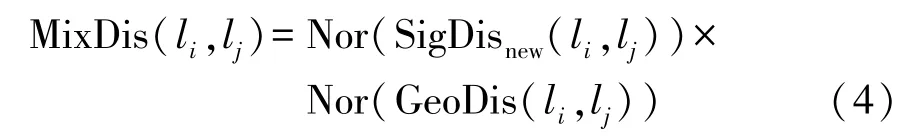
式中,Nor為歸一化函數(shù)。
使用地理位置對(duì)信號(hào)距離進(jìn)行修正,得到的融合特征可以更好地反映采樣點(diǎn)之間的地理關(guān)系。本文第3部分的試驗(yàn)中顯示,使用融合特征進(jìn)行聚類,得到的類分布更加均勻,更加接近空間結(jié)構(gòu)劃分。
2.仿射傳播聚類
通常的聚類算法是在多次迭代中選出一個(gè)聚類中心,使該類其他成員與聚類中心的距離平方和最小。以經(jīng)典的K-means算法為例,算法啟動(dòng)時(shí)需要提供一系列的類中心初始值,并且算法對(duì)系統(tǒng)的初始值依賴性較大,容易陷入局部極值[15]。而 APC是將所有的點(diǎn)連接成網(wǎng)絡(luò),每個(gè)節(jié)點(diǎn)都是潛在的聚類中心,通過迭代,點(diǎn)之間不斷發(fā)射和接收吸引度和歸屬度消息,從而不斷擴(kuò)大中心點(diǎn)和附屬點(diǎn)之間的差距,最終確定中心點(diǎn)[16]。與K-means方法相比,APC的收斂速度更快,得到的絕對(duì)平均誤差和平均方差要比K-means的結(jié)果低[16-17]。
APC的輸入信息為n個(gè)點(diǎn)之間的相似度矩陣Sn×n,本文使用的就是融合后的特征MixDis。對(duì)于s(k,k),需要設(shè)置一個(gè)合理的值來表示,通常選擇Sn×n中的中值,試驗(yàn)中選擇S的第k行的中值作為s(k,k)的初始值。之后為算法的核心,計(jì)算兩兩參考點(diǎn)間的消息傳遞:吸引度消息r(i,j)和歸屬度消息a(i,j)。其中吸引度消息r(i,j)是從i點(diǎn)傳到j(luò)點(diǎn),表明j作為i的聚類中心的可靠度;歸屬度消息a(i,j)是從j點(diǎn)傳到i點(diǎn),表明i選擇j作為聚類中心的可行度。
(1)吸引度消息r(i,j)
由樣本點(diǎn)li傳到樣本點(diǎn)lj,表明了在除lj點(diǎn)之外的樣本點(diǎn)的作用下lj作為聚類中心對(duì)li的吸引度的積累,公式如下式中,s(i,j)是MixDis(i,j);a(i,j)是下面要定義的歸屬度消息。
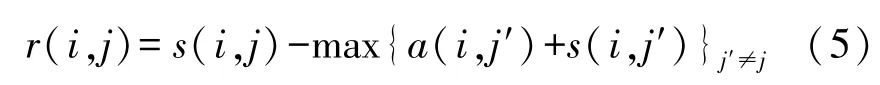
(2)歸屬度消息a(i,j)
由樣本點(diǎn)lj傳到樣本點(diǎn)li,表明了在除lj點(diǎn)之外的樣本點(diǎn)的作用下li認(rèn)為lj為聚類中心的歸屬度的積累,公式如下
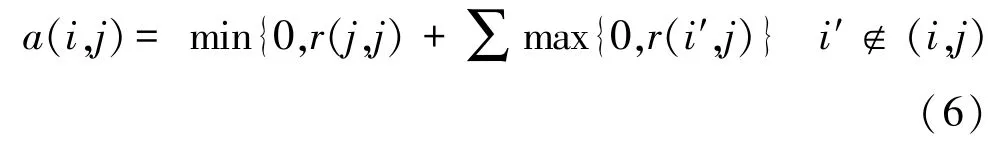
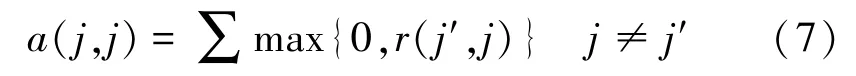
(3)自歸屬度消息通過以上兩種消息在樣本點(diǎn)之間的傳遞,實(shí)現(xiàn)了中心和歸屬點(diǎn)的劃分。具體來說,如果j′=i,則參考點(diǎn)li為中心;否則lj′點(diǎn)為中心。
三、試驗(yàn)與結(jié)果分析
1.試驗(yàn)條件
選取中國(guó)礦業(yè)大學(xué)南湖校區(qū)的環(huán)測(cè)學(xué)院樓4層A區(qū)和C區(qū)的走廊作為試驗(yàn)場(chǎng),面積約為350 m2,定位中使用的泛在信號(hào)為日常傳輸數(shù)據(jù)的WiFi信號(hào),共99個(gè),并未加設(shè)新的設(shè)備。圖 1是試驗(yàn)場(chǎng)的WiFi信號(hào)強(qiáng)度分布圖。

圖1 試驗(yàn)場(chǎng)WiFi強(qiáng)度分布
試驗(yàn)分為采樣過程、離線處理和定位3個(gè)步驟。使用三星GalaxyⅢ (Android 4.0平臺(tái))進(jìn)行采樣和定位,采樣率為100 Hz,接收信號(hào)強(qiáng)度為-110~15的整數(shù),采樣過程需要對(duì)東西南北4個(gè)方向采集可接收AP點(diǎn)的Mac地址和平均信號(hào)強(qiáng)度,共采集有效點(diǎn)93個(gè),平均采樣間隔3.5 m;離線處理即指紋庫(kù)的聚類處理;定位與采樣階段類似,但定位方向不一定,且定位時(shí)間較短。
2.聚類試驗(yàn)
通過提取融合特征,采用APC算法對(duì)樣本庫(kù)中的樣本點(diǎn)進(jìn)行聚類處理。APC是一種非監(jiān)督分類方法,因此不必設(shè)定分類數(shù)目。分類結(jié)果如圖2所示。
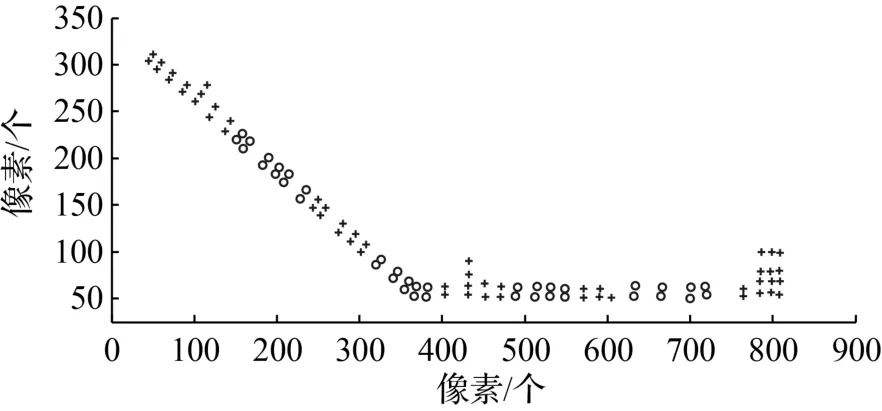
圖2 APC分類結(jié)果
同時(shí)與文獻(xiàn)[12]使用的K-means算法進(jìn)行對(duì)比,K-means需要設(shè)定分類數(shù)目,這里將仿射傳播分類的分類數(shù)代入,以進(jìn)行測(cè)試。分類結(jié)果如圖3所示。圈出的是分類不合理的位置,1為類成員過少,2為邊界模糊,3為走廊拐彎處沒有劃分。
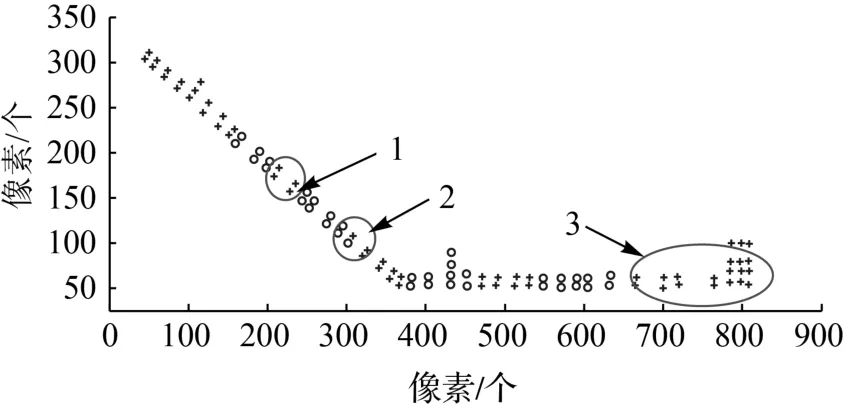
圖3 K-means分類結(jié)果
本文使用3種指標(biāo)對(duì)分類結(jié)果的均勻性進(jìn)行分析和評(píng)定,分別是類成員數(shù)目方差、類平均中心距方差和類覆蓋面積方差。類成員數(shù)目是指各類中的采樣點(diǎn)的數(shù)目;類平均中心距是指類中各采樣點(diǎn)到聚類中心的距離的平均值,這里為了統(tǒng)計(jì)采樣點(diǎn)的空間分布,選用空間距離;類覆蓋面積是指類中成員覆蓋的空間范圍,由于采樣點(diǎn)是沿走廊兩側(cè)分布的,可以使用各類采樣點(diǎn)的最小凸包代表類的空間覆蓋空間。這3種數(shù)據(jù)的方差值用于衡量分類的均勻性,見表1。
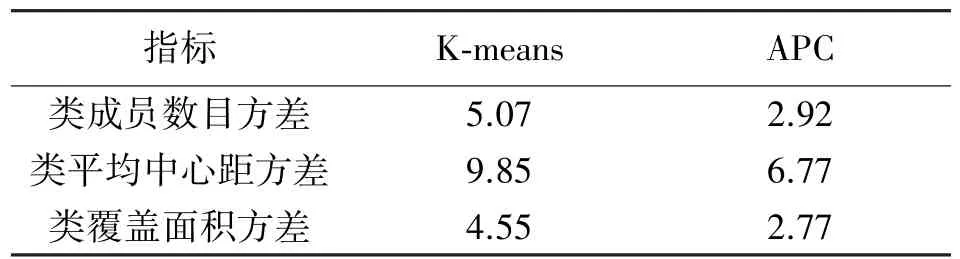
表1 分類均勻性指標(biāo)
從3項(xiàng)指標(biāo)來看,APC的數(shù)值要小于K-means。其中類成員數(shù)目是從數(shù)量上衡量類劃分的均勻程度,數(shù)目差別較大會(huì)對(duì)鄰域計(jì)算產(chǎn)生影響,當(dāng)類中點(diǎn)的數(shù)目少于鄰域計(jì)算數(shù)目時(shí)需要增加其他類的成員點(diǎn)參與計(jì)算,這就需要額外添加類之間的關(guān)聯(lián)關(guān)系。類平均中心距方差和類覆蓋面積方差反映了類在空間覆蓋上的均勻性,空間分布均勻有利于控制定位的精度在一定范圍內(nèi)變動(dòng)。
同時(shí),從圖2和圖3中可以看出,APC方法除了類劃分較為均勻之外,走廊的拐彎處也都是類劃分的邊界。這種處理方法有利于提高定位的精度,在拐彎處定位,若不進(jìn)行拐彎劃分,容易將位置定在走廊之外,形成邏輯錯(cuò)誤。
3.定位試驗(yàn)
試驗(yàn)選用 K近鄰法(K nearest neighborhood, KNN)作為定位算法。未知位置的計(jì)算公式[13]為
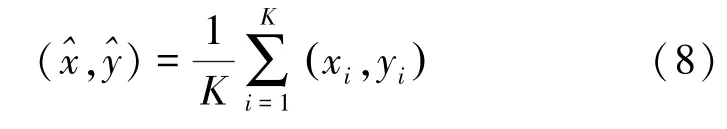
式中, (xi,yi)為第i個(gè)被選取點(diǎn)對(duì)應(yīng)的坐標(biāo);K為選取鄰近點(diǎn)的數(shù)目,試驗(yàn)中 K=6,采樣的平均間隔3.5 m。定位數(shù)據(jù)的搜集方法為:在試驗(yàn)場(chǎng)標(biāo)定26個(gè)待定位點(diǎn),使用相同設(shè)備采樣2 s,記錄WiFi信號(hào)數(shù)據(jù)。試驗(yàn)分別從時(shí)間效率和定位精度兩個(gè)方面分析對(duì)比APC和K-means的定位效果。
聚類處理作為數(shù)據(jù)的預(yù)處理,是通過減少定位時(shí)的數(shù)據(jù)檢索量,從而降低定位使用的時(shí)間。在手機(jī)平臺(tái)定位測(cè)試,單點(diǎn)定位時(shí)間如圖 4所示,K-means和APC聚類處理相對(duì)全局搜索在時(shí)間效率上有較大提升,全局搜索定位平均用時(shí)127 ms,K-means和APC分別是76 ms和70 ms,提速程度相當(dāng);其中K-means的最大降幅為88.2%,最小降幅僅為0.2%,而APC的最大降幅為87.2%,最小降幅也達(dá)到16.8%。APC的數(shù)據(jù)檢索平均減少75%,最多減少80%,其平均減少率與K-means相當(dāng),這就使兩種聚類處理方法的平均定位時(shí)間相近;但K-means的降幅變化較大,這是由于聚類結(jié)果不均勻,導(dǎo)致各個(gè)定位點(diǎn)搜索的采樣點(diǎn)數(shù)目相差較大,見表 2,K-means最大最小搜索數(shù)目之間相差20,而APC僅為10。
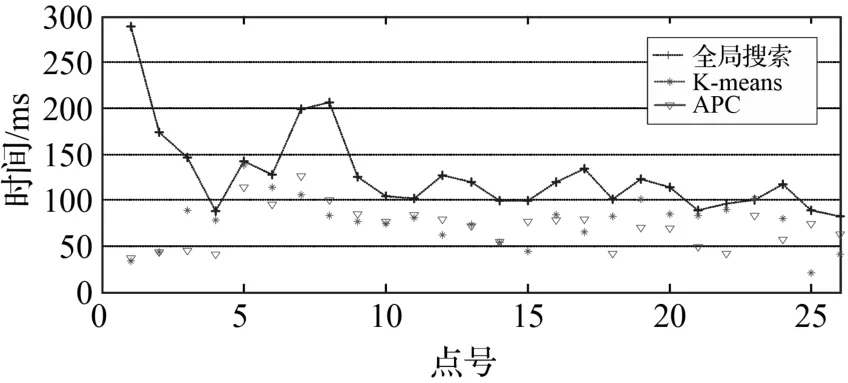
圖4 單點(diǎn)定位時(shí)間對(duì)比
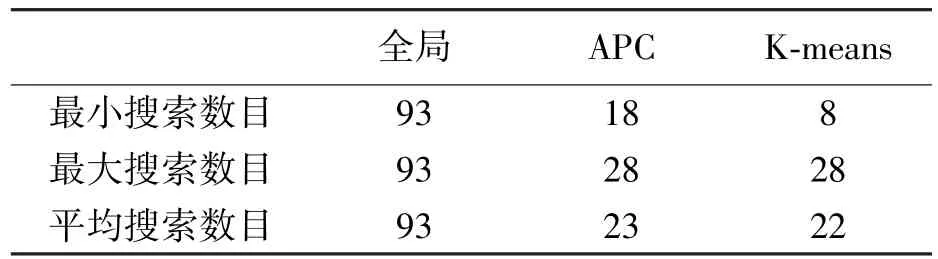
表2 點(diǎn)搜索數(shù)目對(duì)比 個(gè)
定位精度如圖5所示,經(jīng)過聚類處理的定位要比全局搜索定位的結(jié)果更加精確,全局搜索平均定位精度為2.6 m,K-means和APC的平均定位精度分別為1.6 m和1.5 m;K-means的最大定位誤差為5.6 m,最小為0.1 m,APC的最大定位誤差為2.8 m,最小為0.2 m。在平均誤差上 APC的結(jié)果要稍好于 K-means,而且誤差波動(dòng)較小。這是由于K-means中存在成員數(shù)目很少的類,該類的信號(hào)均值不能反映該類區(qū)域信號(hào)特點(diǎn),容易造成誤匹配,從而使得精度下降。
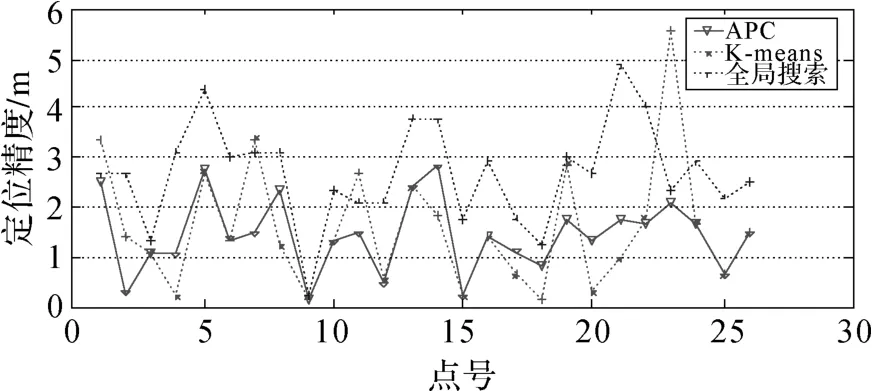
圖5 單點(diǎn)定位精度對(duì)比
四、結(jié) 論
本文通過APC對(duì)室內(nèi)定位指紋庫(kù)的位置指紋數(shù)據(jù)進(jìn)行聚類處理,以減少定位時(shí)遍歷數(shù)據(jù)量,提高定位精度。針對(duì)僅使用信號(hào)域的相關(guān)度衡量采樣點(diǎn)之間的關(guān)系造成的定位結(jié)果偏差的現(xiàn)象,本文將采樣點(diǎn)的位置域與信號(hào)域的相關(guān)度進(jìn)行組合,得到融合特征,將融合特征作為聚類特征代入APC算法,通過試驗(yàn)場(chǎng)測(cè)試得到以下結(jié)論:
1)本文使用的聚類算法和特征得到的聚類結(jié)果與K-means的結(jié)果相比,類劃分更接近空間結(jié)構(gòu)劃分,類分布更加均勻,更有利于提高定位精度。
2)以APC結(jié)果為基礎(chǔ)進(jìn)行KNN插值定位,定位結(jié)果精度高于K-means方法,遍歷點(diǎn)平均減少75%,時(shí)間較全局搜索平均減少40%。
因此使用APC對(duì)采樣點(diǎn)位置域和信號(hào)域進(jìn)行聚類分析,可以有效地減少系統(tǒng)的遍歷數(shù)據(jù)量,并且提高室內(nèi)定位的精度。
[1] KUO S P,TSENG Y C.Discriminant Minimization Search for Large-Scale RF-based Localization Systems[J].Mobile Computing,2011,10(2):291-304.
[3] LI K.Location Estimation in Large Indoor Multi-floor Buildings Using Hybrid Networks[C]∥Wireless Communications and Networking Conference.[S.l.]:IEEE,2013:2137-2142.
[4] ZHE X,ZHANG H,HUANG J,et al.A Hidden Environment Model for Constructing Indoor Radio Maps[C]∥World of Wireless Mobile and Multimedia Networks.[S. l.]:IEEE,2005:395-400.
[5] ZDRUBA G V,HUBER M,KARNANGAR F A,et al. Monte Carlo Sampling Based In-home Location Tracking with Minimal RF Infrastructure Requirements[C]∥Global Telecommunications Conference.[S.l.]:IEEE,2004:3624-3629.
[6] CHAI X Y,YANG Q.Reducing the Calibration Effort for Probabilistic Indoor Location Estimation[J].Mobile Computing,2007,6(6):649-662.
[7] KRISHNAN P,KRISHNAKUMAR A S.A System for LEASE:Location Estimation Assisted by Stationary Emitters for Indoor RF Wireless Networks[C]∥INFOCOM:Twentythird Annual Joint Conference of the IEEE Computer and Communications Societies.[S.l.]:IEEE,2004:1001-1011.
[8] WYMEERSCH H,JAIME L.Cooperative Localization in Wireless Networks[J].Proceedings of the IEEE,2009,97(2):427-450.
[9] YOUSSEF M,AGRAWAL A.Handling Samples Correlation in the Horus System[C]∥INFOCOM.[S.l.]:IEEE,2004:1023-1031.
[10] YOUSSEFF M,AGRAWALA A.On the Optimality of WLAN Location Determination Systems[J].UM Computer Science Department,2004,4(4):1-6.
[11] YOUSSEFF M,AGRAWALA A.WLAN Location Determination via Clustering and Probability Distributions[C]∥Pervasive Computingand Communications.[S.l.]:IEEE,2003:143-150.
[12] KUO S P.Cluster-enhanced Techniques for Pattern-Matching Localization Systems[C]∥Mobile Adhoc and Sensor Systems.[S.l.]:IEEE,2007:1-9.
[13] BAHL P,PADMANABHAN V N.RADAR:An In-building RF-based User Location and Tracking System[C]∥INFOCOM.[S.l.]:IEEE,2000:775-784.
[14] 賈明華.地鐵隧道環(huán)境毫米波傳播特性的研究[D].上海:上海大學(xué),2010.
[15] 王開軍,張軍英,李丹,等.自適應(yīng)仿射傳播聚類[J].自動(dòng)化學(xué)報(bào),2007,33(12):1242-1246.
[16] FREY B J,DUECK D.Clustering by Passing Messages Between Data Points[J].Science,2007,315(5814):972-976.
[17] 馮辰.基于壓縮感知的RSS室內(nèi)定位系統(tǒng)研究與實(shí)現(xiàn)[D].北京:北京交通大學(xué),2010.
Affinity Propagation Clustering for Fingerprinting Database in Indoor Localization
ZHANG Liwen,WANG Yunjia,WANG Xingfeng
RUNGSI K.Distribution of WLAN
Signal Strength Indication for Indoor Location Determination[C]∥Wireless Pervasive Computing.[S.l.]:IEEE,2006.
P237
B
0494-0911(2014)12-0036-04
張儷文,汪云甲,王行風(fēng).仿射傳播聚類在室內(nèi)定位指紋庫(kù)中的應(yīng)用研究[J].測(cè)繪通報(bào),2014(12):36-39.
10.13474/j.cnki.11-2246.2014.0392
2013-10-24
國(guó)家863計(jì)劃(2013AA12A201);地理空間信息工程國(guó)家測(cè)繪地理信息局重點(diǎn)實(shí)驗(yàn)室資助項(xiàng)目(201321)
張儷文(1990—),女,陜西渭南人,碩士生,研究方向?yàn)槭覂?nèi)定位、模式識(shí)別。
汪云甲
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評(píng)價(jià)·高一版(2020年6期)2020-11-02 02:45:24
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中國(guó)生殖健康(2019年3期)2019-02-01 06:12:26
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
鑿巖機(jī)械氣動(dòng)工具(2016年3期)2016-03-01 04:00:25
海軍航空大學(xué)學(xué)報(bào)(2015年3期)2015-11-11 17:20:00
