基于主題本體擴展特征的短文本分類
2014-07-24 05:51:40湛燕陳昊
河北大學學報(自然科學版) 2014年3期
湛燕,陳昊
(河北大學 數學與計算機學院,河北省機器學習與計算智能重點實驗室,河北 保定 071002)
自動文本分類有著悠久的歷史,可以追溯到至少20世紀60年代,直到20世紀80年代末,作為知識工程自動分類的一個重要分支問題,即構建一套規則來編碼專家知識從而用于文檔分類.在20世紀90年代,隨著蓬勃發展的在線文檔的廣泛應用,自動文本分類增加和擴展了新的研究范圍[1].
文本分類是信息組織和信息管理任務中非常重要的組成成分.而短文本分類指的是一些短小文章(通常少于100字)的分類.國際上對于文本分類已經有了很多年的研究[1-2],但是對于短文本分類問題的研究相對較少[3-4].
短文本分類問題是文本分類的一個分支,除了在某種程度上與傳統文本分類類似,但是仍然需要面臨一些特殊問題需要解決,因為文本長度短、特征稀疏,很難衡量文章之間的相似性,常見的文本分類相似度測量方法應用在短文本分類中,通常并不能得到一個好的結果.
目前較為常用的傳統文本分類算法有貝葉斯、支持向量機、近鄰方法、神經網絡方法、決策樹法等[2].根據不同的文本表示形式的特點,這些方法可以分為2 種:一種是傳統的基于向量空間模型(vector space mode,VSM)的分類,另一個是基于語義信息的分類[5].一般來說,傳統的基于向量空間模型的分類方法,不使用語義信息來提高分類性能;同時,由于文檔比較短,描述特征詞信息的能力弱,在測試文檔中出現的詞不一定出現在訓練文檔中,所以第2種方法也不能直接應用于短文本的分類.
使用互信息[1](mutual information,MI)特征選擇,通過單詞測量文檔之間的相關性,但是短文本提供更少的單詞相關信息,因此有必要考慮其他語義關系(如:同義關系或近義關系等等).傳統的貝葉斯分類器(Naive Bayes)在知識儲備的不足的情況下,容易發生分類分錯的情況,如果分錯了文本過早加入分類器中,會降低其分類性能[6].除了文章短小的原因外,概念描述信息弱.單詞數量的缺少等特點,使得在短文本分類中很難準確衡量文本的相似性.由于本體理論強調相關領域的概念,但也強調這些概念之間的聯系.但是由于特征數量較少的缺陷,所以有必要強調語義之間的聯系,這和本體理論的表示一致.
1 基于主題本體的擴展特征
1.1 本體
本體論(ontology)原是哲學的分支,研究客觀事物存在的本質,它與認識論(epistemology)相對,認識論研究人類知識的本質和來源,也就是說,本體論研究客觀存在,認識論研究主觀認知.而本體的含義是形成現象的根本實體(常與“現象”相對).在人工智能領域,知識建模必須在知識庫和2個子系統之間建立聯系:agent行為(問題求解技能)和環境(問題存在的領域).而長期以來,人工智能領域的研究者較為注重前一個子系統,而領域知識的表達依賴于特定的任務,這樣做的好處是只需要考慮相關的領域知識,但是,大規模的模型共享、系統集成、知識獲取和重用依賴于領域的知識結構分析,因此,進入20世紀90年代以來,與任務獨立的知識庫(本體)的價值被發現,并受到廣泛關注〔7-8〕.
本體的目標是抓住相關的領域知識,提供領域知識中共同的認識,使用通用的字詞來定義領域知識,并且定義不同模式的領域詞之間的聯系.本體一方面屬于認知概念集的領域,這些概念有很多相關的語義,這些語義反映了概念之間的聯系.本體描述了概念和上下文之間內在的語義.總之,本體強調了相關領域間的重要性,同時也強調了這些重要概念的聯系.
由于短文本的獨有特點,例如文本長度較短,特征選擇分散不一,詞語測量較困難,使得短文本文類需要處理這些特殊的問題.基于本體理論涉及到了領域概念,但是對于短文本分析而言,難以處理短文本特征稀少的問題,所以需要重點強調文本特征之間的語義聯系.本文使用了基于主題本體的特征擴展方法,考慮了特征之間的語義關聯,達到了較好的分類性能[9-10].
1.2 基于主題本體的擴展特征
定義 主題本體 主題本體意味著最重要的核心和最必要的組合,可以對概念特征給出正式的描述,這些概念在其他領域很少出現,所以可以確定一個領域.
在特定的應用程序有許多不同的方式來表示本體,可以使用自然語言、框架和語義網絡或邏輯語言描述本體.在現有的本體模型中,對于不同的問題領域和不同的工程考慮,結構和過程在本體方法也不同.語言的邏輯表達式可以很強大,但其推理過程比較復雜,所以很難完成本體模型的創建.鑒于這個原因,本文提出了一種命名為主題本體擴展特征的分類.
在主題本體中主要有兩方面的內容:
第一,得到高頻域詞,指的是在某些領域高頻率域和其他場域的幾率很小的詞(即是在本領域中區分能力強的詞),這些高頻詞只能確定一個領域,所以可以使用它們作為高頻詞用于分類.
第二,通過概念來擴展高頻詞,使用主題本體對概念特征給出正式的描述,使原來的特征詞匯不是孤立的,所以這些特征詞語可以看作一種概念的集合以及相關詞匯.普通詞匯和特征詞的區別在于,它可以把概念進行比較,這樣可以更準確地確定2個領域之間的相似性.
通過以下詳細步驟得到主題本體的特征擴展.
1)對訓練文本進行預處理:通過詞性分析,保留名詞、動詞和形容詞,通過詞特征的選擇,過濾掉不適合用于分類的詞,從而減少計算的復雜度.
2)計算單詞的頻率,計算每個單詞在不同的類別中出現的次數,過濾掉出現頻率較少的單詞,同時對詞頻可以進行歸一化處理,如下公式:
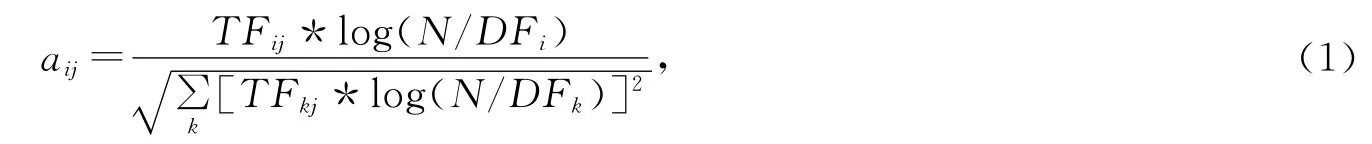
其中TFij表示單詞i在文檔j 中出現次數,DFi表示所有文檔集合中出現單詞i的文檔數目.
3)提取出現頻率比較高的單詞作為一個主題本體的高頻詞匯,過濾掉和本主題本體不相關的單詞,得到初始詞匯.
4)運用同義詞來擴展特征詞匯,通過概念來擴展高頻詞,例如“程序”,“編程”,“網頁設計”,“動畫設計”都可以屬于電腦編程方面的近義詞匯.使用主題本體對概念擴充以擴展其特征詞匯,從而可以解決在短文本分類中特征詞少的問題.
1.3 CBM(Case-base Maintenance)方法
本文使用了CBM(case-base maintenance)方法,它可以在K-近鄰算法中減少樣本個數,從而可以提高搜索近鄰的檢索效率.首先,本文介紹了一個概念叫做樣本的擴展能力.基于這個概念,提出了一種減少樣本個數的方法.樣本的擴展能力(generalization capability)表明了樣本解決分類問題的能力.根據這種方法,具有更好擴展能力的樣本會保留下來作為樣本的代表,其他多余的在其覆蓋范圍內的樣本就可以刪除了,從而減少了樣本個數.實驗表明這種方法在分類算法中,可以大大減少多余樣本或者對于分類用處不大的樣本,從而獲得更高的分類效率.
這種啟發式算法介紹如下(稱為GC算法):
1)集合R 被初始化為空集,其中S=X∪Y.
2)對于集合X 中的每一個樣本x,根據公式(2)計算Coverage(x).
3)找到這樣的樣本x*,其中|Coverage(x*)|=maxx∈S|Coverage(x)|.如果存在多于1個樣本的覆蓋范圍等于這個最大值,那么從中選擇rx最大的那個樣本x**.如果這時有很多樣本達到了這個最大值,那么可以隨機選擇1個即可.
4)置R=R∪{x*}和S=S-Coverage(x*),如果|S|=0那么停止,否則轉到2).
因此,集合R 就是最后選擇的有代表性的樣本集合,完整的正例集合是集合X.實際上,被選擇的樣本已經排除了負例樣本集合Y.
其中,樣本x 的覆蓋范圍Coverage(x)定義如下:

接著本文定義2個樣本之間的距離.對于每個樣本x={x1,x2,…,xn}和y={y1,y2,…,yn},它們之間的距離定義為

這里的距離測試ρj(xj,yj)依賴于特定的域,M 是位于0~1之間的一個正數.通常,參數M 是這樣確定的

假設X∪Y 沒有交集,也就是不存在2個樣本x∈Xand y∈Y,即x=y.
對于每一個正例x=(x1,x2,…,xn)∈X,正例樣本x 到負例樣本集合Y 的最短距離為

因此,保證了rx>0.
本文定義了一個正例的覆蓋范圍.如果x是一個正例,q是任意一個樣例,如果滿足公式(6)就說x覆蓋q

其中rx根據公式(5)進行計算.
一個正例覆蓋范圍有負例是不可能的,所以,換句話說,一個正例的覆蓋范圍一定是樣本集合X 的子集.一個樣本的覆蓋范圍表示了這個樣本的擴展能力.樣本覆蓋范圍包括的樣本個數越多,說明這個樣本的擴展能力越強.從公式(2)中,可以定義每個正例的覆蓋范圍.主要目標就是選擇正例樣本的一個子集,它們的覆蓋范圍可以代表整個正例集合X.實際上,所選擇的樣本已經排除了負例樣本集合Y.
把這種方法應用在K-近鄰分類算法中,選擇擴展能力強的樣本進行分類,刪除其他樣本,從而減少了樣本的個數,獲得更高的分類效率,這和主題本體的思想是一致的[11].
2 實驗
2.1 性能測試標準
為了評估文本分類系統的有效性,筆者使用召回率、準確率和F1 度量作為評估標準.召回率(recall(R))是定義為所有準確的文檔有多少被檢索出來.準確率(precision(P))是檢索出來的文檔正確的數量.F1度量結合了以上兩者的加權調和平均

2.2 實驗及其分析
筆者在人民日報選擇了1 000篇文章,分別屬于計算機編程、國際新聞、婦女、軍事和體育新聞等.在訓練樣本中使用基于主題本體的特征擴展方法,并對測試樣本進行預處理,只保留名詞、動詞和形容詞,使用K-近鄰分類算法進行文本分類.
在實驗中,每個數據集都被隨機分成2個獨立的集合,90%的文章作為訓練數據和10%的文章作為測試數據.
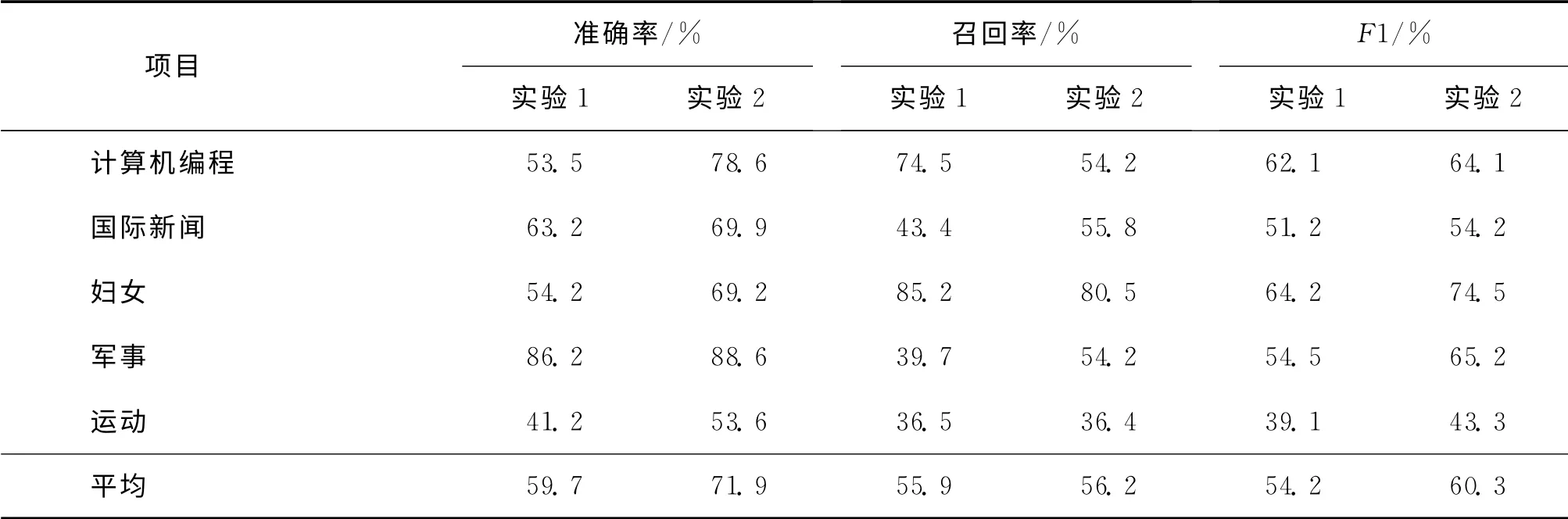
表1 準確率、召回率和F1度量Tab.1 Comparison of precision,recall and F1
實驗1使用傳統的互信息進行特征選擇和進行K-近鄰文本分類.實驗2使用基于主題本體的特征擴展以及通過CBM 進行K-近鄰文本分類.從表1中可以看到實驗2的基于主題本體的特征擴展學習提高了準確率,召回率和F1值.因此,由于考慮到了語義聯系,可以得到比傳統方法更好的分類性能.
3 結論
由于短文本的獨有特點,例如文本長度較短,特征選擇分散不一,詞語測量較困難,使得短文本文類需要處理這些特殊的問題.基于本體理論涉及到了領域概念,但是對于短文本分析而言,難以處理短文本特征稀少的問題,所以需要重點強調文本特征之間的語義聯系.本文使用了基于主題本體的特征擴展方法,考慮了特征之間的語義關聯,達到了較好的分類性能.本文通過基于CBM 方法的K-近鄰分類應用在短文本分類算法中,并且使用了基于主題本體的特征擴展方法.由于考慮了語義關系,可以得到比傳統的方法更好的分類性能.自從近鄰分類算法應用了特征擴展方法,可以提高分類性能,通過優化該算法使其廣泛的應用在文本分類中.
[1] SEBASTIANI F.A tutorial on automated text categorisation[Z].Proceedings of ASAI-99,1st Argentinian Symposium on Artificial Intelligence,Buenos Aires,AR,1999.
[2] SEBASTIANI F.Machine learning in automated text categorization[J].ACM Computing Surveys,2002,34(1):1-47.
[3] FAN Xinghua,SUN Maosong.A high-performance text categorization of two classes[J].Chinese Journal of Computer,2006,29(1):124-131.
[4] ZELIKOVITZ S,TRANSDUCTIVE M F.Learning for short-text classification problem using latent semantic indexing international[J].Journal of Pattern Recognition and Artificial Intelligence,2005,19(2):143-163.
[5] 翟延冬,王康平,張東娜,等.一種基于WordNet的短文本語義相似性算法[J].電子學報,2012,40(3):617-620.ZHAI Yandong,WANG Kangping,ZHANG Dongna,et al.An algorithm for semantic similarity of short text based on wordnet[J].Chinese Journal of Electronics,2012,40(3):617-620.
[6] 王永恒,賈焰,楊樹強.基于頻繁詞集聚類的海量短文分類方法[J].計算機工程與設計,2007,28(8):1744-1780.WANG Yongheng,JIA Yan,YANG Shuqiang.Massive short documents classification method based on frequent term set clustering[J].Computer Engineering and Design,2007,28(8):1744-1780.
[7] SONG D,BRUZA P D,HUANG Z,et al.Classifying document titles based on information inference[Z].Proceedings of the 14th International Symposium on Methodologies for Intelligent Systems,Maebashi City,Japan,2003.
[8] CHEN Enhong,WU Gaofeng.An ontology learning method enhanced by frame semantics[Z].Seventh IEEE International Symposium on Multimedia,Irvine,California,2005.
[9] 黃九鳴,吳泉源,劉春陽,等.短文本信息流的無監督會話抽取技術[J].軟件學報,2012,23(4):735-747.HUANG Jiuming,WU Quanyuan,LIU Chunyang,et al.Unsupervised conversation extraction in short text message streams[J].Journal of Software,2012,23(4):735-747.
[10] 彭澤映,俞曉明,許洪波.大規模短文本的不完全聚類[J].中文信息學報,2011,25(1):54-59.PENG Zeying,YU Xiaoming,XU Hongbo.Incomplete clustering for large scale short texts[J].Journal of Chinese Information Processing,2011,25(1):54-59.
[11] ZHAN Yan,CHEN Hao.Chinese text categorization study based on cbm learning[Z].2010 7th International Conference on Fuzzy Systems and Knowledge Discovery,Yantai,2010.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
