網絡編碼系統中基于訪問頻度的數據重建方法*
2014-07-25 07:45:02李凱
網絡安全與數據管理 2014年6期
李凱
(暨南大學 計算機科學系,廣東 廣州510632)
在這個大數據的年代,數據量增長的速度是驚人的。據IDC報告顯示,預計到2020年全球數據總量將超過 40 ZB(相當于4萬億 GB)[1],這一數據量是 2011年的22倍。為了給海量數據提供有效的存儲及服務的能力,誕生了許多大規模數據存儲系統,比如GFS、Hadoop、OceanStore、Lustre、Gluster等。在這些大型存儲系統中,數據分布在一系列的節點(磁盤等物理介質)上,為了保證數據的可用性,系統必須能夠容忍節點失效。為了達到這一目的,分布式存儲系統引入了冗余數據以提供容錯能力。
一般的容錯技術包括副本技術,糾刪碼技術和網絡編碼技術。副本技術對一個數據對象創建多個副本,并將這些副本分散到不同的節點上。當一個節點失效時,可以通過訪問其他節點的數據副本來重建新節點。比如GFS[1]為每個數據塊提供了3個副本。糾刪碼技術是能夠容忍一個或多個節點同時失效的編碼技術,而且比副本技術有更高的空間存儲效率。常見的糾刪碼有Reed-Solomon碼、LDPC碼等。網絡編碼技術通過選擇特殊的編碼系數來構造生成矩陣,在節點修復時,把存儲在同一節點上的若干數據塊做線性運算,所以該節點傳輸一個數據塊就等于提供了做運算之前的若干個數據塊的信息,從而有效地節省了帶寬。
DIMAKIS等人于2007年首先在分布式存儲系統中引入網絡編碼思想,提出了一種稱為再生碼(regenerating code)[2]的編碼技術。隨后,Rashmi等人提出了 E-MBR(Exact minimum Bandwidth Regenerating)碼[3],突破了網絡編碼的理論階段,給出了一個具體的最優帶寬再生碼方案。雖然網絡編碼在數據重建時,下載帶寬方面表現優越,但是其付出的運算開銷卻不可忽視[2]。據NCFS[4]研究表明,網絡編碼在退化模式下的表現明顯不如RAID5和RAID6。Tian Lei等人實現了以訪問頻度優先的數據重構優化方法[5]來改善磁盤陣列中數據重建緩慢的問題,不過他們只限于對RAID5和RAID10的研究。基于此,本文提出了一種在網絡編碼修復過程中利用80/20法則來加快數據重建過程的方法。在NCFS平臺上進行了仿真實現,并對RAID5、RAID6和E-MBR編碼在節點重建時間、用戶平均響應時間和吞吐率方面進行了比較。
1 背景知識
1.1 帕雷托法則(Pareto principle)
帕雷托法則又稱80-20法則,在計算機科學里,80-20法則代表80%的資源只被20%的操作所使用。具體到文件系統的訪問行為,是指80%的請求往往集中在20%的文件上,從而導致某一部分數據被頻繁重復地訪問,而其他數據則相對訪問頻度較低。比如視頻網站約20%的視頻文件由于經常被觀看而必須保存在內存中,以提供快速及時的響應;而剩余的80%視頻文件則觀看次數較少,可把這些數據置于存儲后端,需要訪問時再從后端提取。
80-20法則對數據重建具有非常重要的借鑒意義。因為一旦節點失效,系統就處于退化模式,處于退化模式下的文件系統同時兼顧重建節點和響應用戶請求的工作。此時對失效節點的寫請求可能被拒絕,讀請求轉化為對若干存活數據節點的讀請求再對讀出來的數據作編碼運算。若20%的熱點數據遲遲沒有重建完成,則會累積大量退化讀寫請求。此時不但額外增加了讀操作和運算,而且磁盤重建數據流和用戶請求數據流對不同區域的讀寫操作會導致磁盤來回長尋道,因而嚴重降低了系統的I/O性能和系統的響應能力。若優先重建熱點數據,則能明顯縮短退化模式的持續時間,改善系統的I/O效率和系統響應能力。
1.2 E-MBR編碼(Exact Minimum Bandwidth Regenerating Code)
一般再生碼分為最小帶寬再生碼(MBR)和最小存儲再生碼(MSR)。相比MSR,MBR以略增加節點的存儲量為代價,換取降低數據重建的帶寬開銷。通常用一個元組(n,k.,m,d)來描述一個MBR編碼系統。數據編碼后分布存儲在n個節點上,用戶連接其中任意k個節點可以還原出原始文件。節點修復時,新節點連接d個節點來完成修復。m=n-d,即當失效的節點多于m個時,就必須要通過還原整個原始文件來完成節點修復,這將帶來相比常規節點修復過程高得多的帶寬和計算開銷。一般最基本的編碼方式是d=n-1。E-MBR編碼[3]是Rashmi等人提出來的一種準確性修復MBR編碼。
2 實驗設計
2.1 NCFS系統架構
NCFS是基于FUSE[6],實現在用戶空間的網絡編碼文件系統。通過把物理節點掛載到當前的文件系統下面(如/mnt/ncfs)即可以像訪問邏輯節點一樣訪問節點中的數據。NCFS主要由文件系統層、編碼層、存儲層組成。文件系統層負責文件系統的操作,比如文件讀、寫、刪除等;編碼層提供了RAID5、RAID6、E-MBR的存儲編碼方式;存儲層提供訪問具體物理設備的接口。在實驗中,用Linux操作系統的偽塊設備/dev/loop來模擬物理磁盤的存儲行為,用戶的讀、寫請求都是針對/dev/loop1,/dev/loop2等塊設備的讀寫。其系統架構如圖1所示。
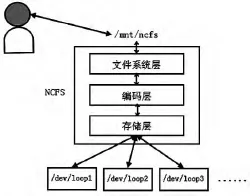
圖1 NCFS系統架構圖
2.2 以Zipf-like分布訪問塊設備
用Zipf-like分布模擬用戶訪問行為,由此產生的訪問請求具有80-20特征。把塊設備節點平均分成n個區域,用數組access_rec[n]記錄每個區域的訪問頻度,通過齊夫定律公式產生訪問的塊號去訪問該塊,訪問請求完成之后修改該塊號所在區域的訪問頻度。根據Zipf-like分布,可知第i塊的訪問概率為:
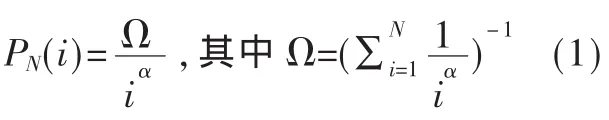
其中,α為一個常數,其取值范圍是 0<α≤1;N為塊總數,因此 Ω也是一個常量。實驗中通過齊夫定律公式產生的訪問行為如表1所示 (總訪問次數為1 000 000次,總區域數n=10)。
各區域按訪問頻度排序如圖2所示。

表1 訪問頻度分布

圖2 各區域排序
2.3 數據重建算法
(1)把記錄訪問頻度的數組 access_rec[n]排序,得出從大到小記錄區域號的數組blk_seq[n];
(2)從blk_seq[n]中取出一個區域號,進行該區域的數據重建;
(3)重復步驟(2),直到節點數據重建完成。
3 實驗評估與分析
對新系統和原系統的平均重建時間、平均響應時間和吞吐率3個性能指標進行了實驗數據收集,并進行了比對。
3.1 平均重建時間
平均重建時間代表了系統的重建效率,其計算公式如下:

其中總重建時間的單位為s,節點數據量的單位為MB,平均重建時間的單位為s/MB。實驗數據結果如圖3所示。
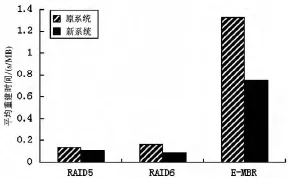
圖3 平均重建時間對比
3.2 平均響應時間
平均響應時間是指在重建過程中,系統每響應一個用戶請求所用的時間。其計算公式如下:

實驗數據結果如圖4所示。
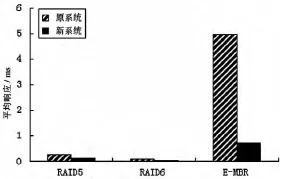
圖4 平均響應時間對比
3.3 吞吐率
吞吐率是指節點修復過程中重建數據流的每秒處理的數據量,其計算公式為:

實驗數據結果如圖5所示。
實驗分析:實驗數據顯示,E-MBR在平均重建時間、平均響應時間和吞吐率3個性能指標的表現都劣于RAID5和RAID6,這是因為網絡編碼的優勢主要在于節省重建帶寬,而為此付出了額外的時間開銷,導致重建過程較緩慢。
不過從圖表中可以看出,經過改進后的新系統在各性能的表現都比原系統好。其中平均重建時間從1.33 s/MB降低到0.75 s/MB,有43.6%的改善;平均響應時間從4.98 ms到改進后的0.71 ms,整整提高了7倍;吞吐率也有了3.23倍的提升。
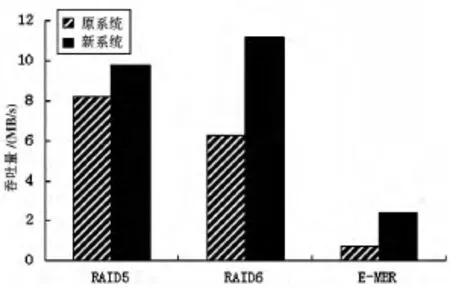
圖5 吞吐率對比
系統在退化模式下的性能提升關鍵在于讓訪問頻度最高的數據在最短的時間里重建完成并投入服務,使對這部分數據的大量訪問請求能夠得到及時的響應,從而減輕了CPU的壓力。另外,優先重建訪問頻度高的數據能夠讓重建數據流和用戶請求數據流盡可能地重疊,以減少大量的磁頭長尋道,從而得到更高的I/O效率。
本文基于網絡編碼文件系統(NCFS),利用80-20法則對原系統的數據重建過程進行了優化,結果顯示新系統在平均重建時間、平均響應時間和吞吐率各方面均有比較大的提升。實驗過程中用到了偽塊設備來模擬磁盤的存儲行為,所有節點都在同一臺計算機上。這與真實的分布式網絡有一定的差別。
[1]GHEMAWAT S,GOBIOFF H,LEUNG S T.The Google file system[C].Proc.of the 19th ACM Symp.on operating Systems Principles.December,2003:29-43.
[2]DIMAKIS A G,GODFREY P B,WAINWRIGHT M J,et al.Network coding for distributed storage systems[C].IEEE Proc.INFOCOM,May 2007:2000-2008.
[3]RASHMI K V,SHAH N B,KUMAR P V,et al.Explicit construction of optimal exact regenerating codes for distributed storage[C].In Proc.of Allerton Conference,2009:1243-1249.
[4]Hu Yuchong,Yu Chiuman,Yan Kit Li,et al.NCFS:on the practicality and extensibility of a network-coding-based distributed file system[C].Proceedings of the 2011 International Symposium on Network Coding(NETCOD),2011.
[5]Tian Lei,Feng Dan,Jiang Hong,et al.PRO:a popularity based multi-threaded reconstruction optimization for RAIDStructured Storage Systems[C].In FAST′07,San Jose,CA,2007:227-290.
[6]FUSE[OL].http://fuse.sourceforge.net/,2013.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
