基于Hadoop的自動售票日志分析系統設計
2014-08-01 15:08:16蔣秋華
鐵路計算機應用 2014年7期
王 斌,李 超,蔣秋華
(1.中國鐵道科學研究院 研究生部,北京 100081;2.中國鐵道科學研究院 電子計算技術研究所,北京 100081)
基于Hadoop的自動售票日志分析系統設計
王 斌1,李 超2,蔣秋華2
(1.中國鐵道科學研究院 研究生部,北京 100081;2.中國鐵道科學研究院 電子計算技術研究所,北京 100081)
通過對自動售票系統日志數據分析,不僅能了解系統的運行狀況,還能在日常維護中更容易地發現問題,降低維護成本,提高維護的效率。針對這一目的,本文基于Hadoop框架設計一個自動售票系統的日志分析系統,搭建Hadoop集群環境,并對處于不同自動售票應用服務器上的日志進行收集,針對自動售票系統日志的特點,編寫Map/Reduce算法,對收集到的日志進行分析處理,使其結果滿足需求,同時,驗證基于Hadoop的自動售票日志分析系統的有效性及可行性。
Hadoop;自動售票機;分布計算;日志分析
近年來,隨著鐵路信息化的發展,自動售票系統在國內的高速鐵路已普遍使用。目前,全路自動售票機(TVM,Ticket Vending Machine)裝機量達3 000臺以上,日均售票量占總售票量的10%左右,在部分車站甚至高達40%。自動售票機的大量應用,取得了很好的效果,不僅方便了旅客,而且很大程度上緩解了車站售票的壓力。然而,與此同時,就會產生相當大規模的日志數據。目前,在日常維護中都是通過人工查看這些日志文件來發現問題,這樣不僅對維護人員要求較高,而且效率低下,因此,如何存儲并高效處理這些日志數據就變得尤為重要。
Hadoop[1~2]是一個流行的大規模數據處理框架,它能夠運行于多種平臺上,并且具有良好的健壯性和可擴展性,在大規模數據處理方面具有一定的優勢,成為進行日志分析的有效解決方案。
1 Hadoop簡介
Hadoop 的核心由HDFS(Hadoop Distributed File System)和MapReduce體現。HDFS提供了一個穩定的文件系統,而Map /Reduce提供一種分布式編程模型。一個HDFS 集群由一個稱為名稱節點(NameNode)和數個數據節點(Datanode)這兩類節點構成,這兩類節點以管理者—工作者模式運行。名稱節點負責維護整個文件系統。數據節點是文件系統中實際的工作者,它們提供存儲、定位塊的服務,并定時向名稱節點匯報存儲塊的信息。Map /Reduce 可以使得程序分布到集群上并發執行。Map /Reduce 將整個工作過程分為Map 階段和Reduce 階段。每個階段都以鍵/值對作為輸入、輸出。Map 將用戶的輸入數據以鍵/值對形式通過用戶自定義的映射過程轉變為一組中間鍵/值對的集合。而Reduce 過程則會對中間生成的臨時中間鍵/值對作為輸入進行處理,并輸出最終結果。目前,Hadoop被廣泛應用于海量數據的處理。
2 自動售票日志分析系統的設計
2.1 日志分析系統整體架構
日志分析系統的總體架構如圖1所示。
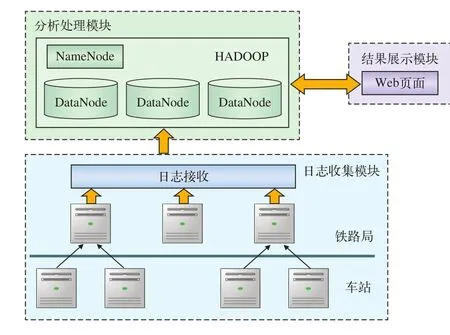
圖1 日志分析系統架構圖
2.1.1 日志收集模塊
對大規模日志數據進行處理,要把分散在前端目標主機上的日志文件進行收集[3]:
(1)在前端目標主機,對原有系統的日志進行收集并保存;
(2)將前端目標主機上保存的日志文件傳輸到 Hadoop 集群中;
(3)將處于Hadoop集群中的日志文件導入到HDFS,利用HDFS的存儲原理和備份機制,在各個節點間建立數據通信方式,配置相應的數據節點、數據備份的數目及對應的名稱節點信息。
日志傳輸的方式有很多種,既可以通過腳本實現,也可以通過現有的傳輸工具實現,本系統采用Flume系統進行日志采集。Flume是一個分布式、可靠和高可用的海量日志聚合的系統,支持在系統中定制各類數據發送方,用于收集數據。同時,Flume提供對數據進行簡單處理,并寫到各種數據接受方(可定制)的能力,其數據源支持console(控制臺)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(日志系統,支持TCP和UDP等2種模式),exec(命令執行)等。其邏輯架構如圖2所示。Agent代表一個需要進行日志收集的節點,其中Source表示數據來源,Sink表示數據去向[4]。
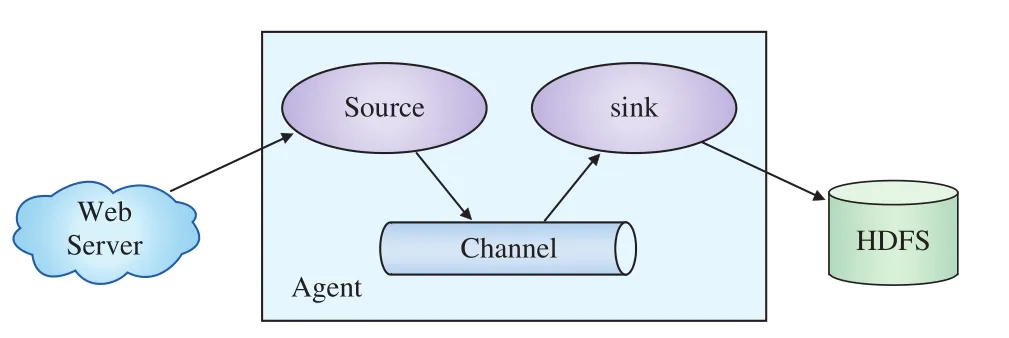
圖2 Flume邏輯架構圖
由于現有的自動售票系統存在兩種模式:(1)車站自主管理模式,即各站自主管理,每個車站均配有自動售票服務器及附屬設備;(2)鐵路局集中模式,即在各個鐵路局設置自動售票應用服務器集群,所有車站的終端設備都直接連接到鐵路局,將所有下轄車站的應用處理服務全部集中管控,采用負載均衡器實現業務均衡處理,保證系統的高可靠性和高安全性[5]。因此,要想使用Flume進行日志收集,需要在所有部署自動售票系統的應用服務器節點上部署一個Agent,并在f l umeconf.properties文件中配置相應的Source和Sink:
agent.sources=spooldirSource
agent.channels=memoryChannel
agent.sinks=hdfsSink
配置完成后,啟動每一個Agent節點。這樣,Flume系統就會自動將各節點上產生的日志文件收集到Hadoop集群中,以供分析。其日志收集流程如圖3所示。
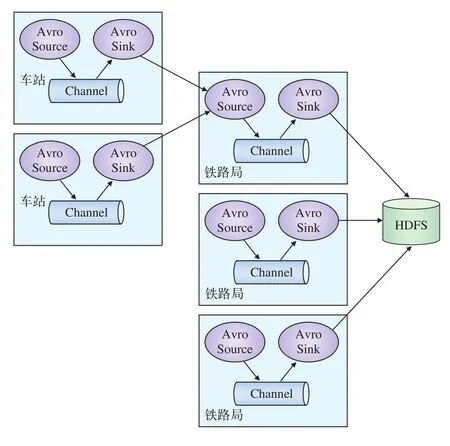
圖3 日志收集流程圖
2.1.2 日志分析處理模塊
日志分析處理模塊是進行大規模日志分析的核心,主要負責將收集到的日志進行分析處理,得到想要的結果。在系統中,其目標是處理所有自動售票應用服務器上產生的日志文件,由于這些日志文件記錄了全國各個車站TVM終端發送的請求以及服務器的響應信息,因此其數據規模相當大。提高系統日志分析處理效率以及降低系統成本是設計系統時必須要考慮的一個方面。
系統采用Hadoop開源框架實現日志分析處理模塊。Hadoop對大規模數據的處理通過Map/ Reduce算法實現[6]。(1)JobTracker創建并初始化一個作業對象,根據已劃分的輸入數據創建Map任務,并根據一定的屬性創建Reduce任務。(2)初始化完成后,JobTracker通過一定的調度算法為每個TaskTracker分配Map或者Reduce任務。(3)由TaskTracker執行相應處理。
2.1.3 結果展示模塊
通過Hadoop對日志進行分析處理,其處理結果有多種展現形式。可以通過某些靜態網頁的形式產生,可以直接輸出到文檔中保存,也可以輸出到關系型數據庫中保存。由于設計日志分析系統的目的是要通過Web頁面進行交互,用戶只需提交自己想要的查詢,系統進行處理后會在頁面展現最終的結果,使用戶可以更直觀地了解到系統的運行狀態,發現系統存在的問題并及時處理,因此,本系統的結果將通過Web頁面的形式展現。例如,在實驗中,通過分析處理,在頁面上展現一段時間內,自動售票終端發送各個請求的成功次數、失敗次數、成功響應平均時間和超時次數等。
2.2 通過Hadoop進行日志分析
2.2.1 實驗環境的搭建
(1)硬件環境
本系統的實驗在由4臺普通筆記本組成的集群上完成,其中一臺作為Master主機,主要負責NameNode以及JobTracker的工作,NameNode是Hadoop分布式文件系統的管理者和調度者,JobTracker的主要職責是啟動、跟蹤和調度各個Slave節點的任務執行。其余3臺作為Slave,負責DataNode以及TaskTracker的工作,DataNode 用來儲存系統中的數據信息及其備份,TaskTracker執行Map任務以及Reduce 任務,進行實際的數據處理。
(2)軟件環境
操作系統采用SUSE10版本,Hadoop采用Hadoop1.1.1版本。
2.2.2 Hadoop日志分析主要算法
本文的日志數據來源于自動售票應用服務器的日志文件,記錄了TVM終端用戶的請求行為和服務器響應的結果,主要內容如表1所示。
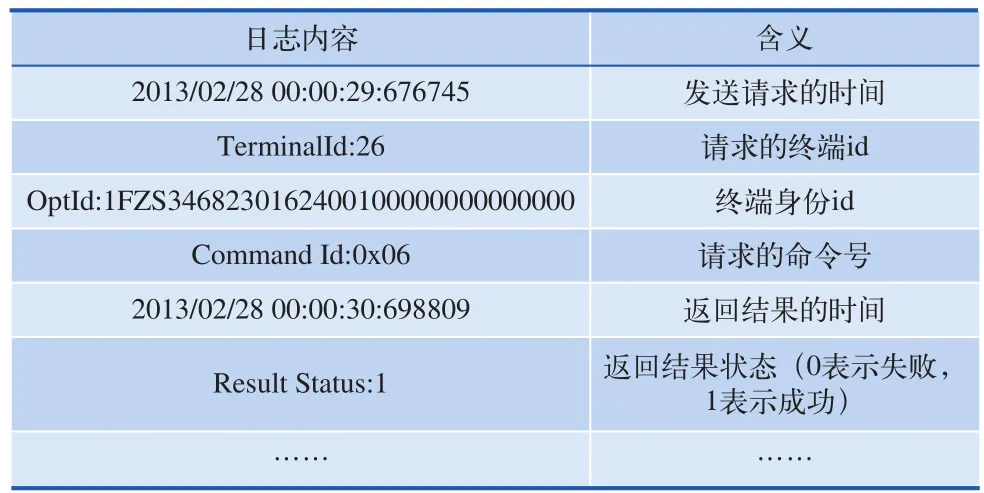
表1 自動售票系統日志內容
實驗通過對該日志文件分析,計算出不同請求的成功響應與失敗響應的次數以及相應的平均時間,其分析算法主要過程如圖4所示,其中none、fail、suc分別代表未匹配到、匹配失敗、匹配成功的狀態標簽。

圖4 程序流程圖
(1)導入HDFS中的日志文件分成M塊Split,將所有的Splits均衡地存儲在各個Slave節點。
(2)通過Hadoop的Map/Reduce算法對輸入分片Splits進行處理。Map階段,對輸入文件進行解析,通過終端ID以及終端身份信息進行請求與相應的匹配,將終端身份信息與終端ID拼接為key,如果請求與響應匹配成功,則將“suc”與響應時間拼接為value,如果匹配失敗,則value值為“fail:1”,如果未獲得響應信息,則value值為“none:1”, 將
(3)根據需求,輸出Reduce的結果。
3 結束語
本文設計了Hadoop分布式環境下自動售票日志數據分析系統。在實驗室集群環境中,對10 G的日志文件進行了分析,總約有1 000萬條記錄,僅用時430 s分析完成。
從實驗結果中可以看到:使用Hadoop建立的分布式日志分析系統,在大規模日志數據處理方面具有明顯的優勢,很大程度上節約了分析成本,提高了分析效率,因此具有很好的應用價值和研究空間。本文只是初步實現了對自動售票系統日志簡單的處理,今后完全可以根據需求實現更加復雜的業務,比如,對各個鐵路局的服務器運行狀況進行監控,統計售票、取票情況,甚至能夠分析用戶的購票行為與使用習慣,這樣不僅能夠提高維護效率,降低維護成本,而且還能為決策者提供一種決策支持。
[1] Apache. Hadoop 1.1.1 Documentation[EB/OL]. http://hadoop. apache.org/docs/r1.1.1/.
[2] Tom White. Hadoop權威指南[M]. 曾大聃,周傲英,譯.北京:清華大學出版社,2010.
[3] 張興旺,李晨暉,秦曉珠. 云計算環境下大規模數據處理的研究與初步實現[J]. 現代圖書情報技術,2011(4):17-23.
[4] Apache. Flume 1.4.0 User Guide[EB/OL]. http://f l ume.apache. org/FlumeUserGuide.html.
[5] 李士達,蔣秋華,康 勇,韓新建. 鐵路旅客自動售票系統設計與實現[J]. 鐵路技術創新,2012(4):42-44.
[6] Shim, Kyuseok. MapReduce algorithms for big data analysis[J]. Lecture Notes in Computer Science, 2013(7813): 44-48.
責任編輯 楊利明
TVM Log Analysis System based on Hadoop
WANG Bin1, LI Chao2, JIANG Qiuhua2
( 1. Postgraduate Department, China Academy of Railway Sciences, Beijing 100081, China; 2. Institute of Computing Science, China Academy of Railway Sciences, Beijing 100081, China )
TVMs could produce a large number of log data which included much valuable information. From these information, we could know the status of our system and maintain the system more eff i ciently. In all ways of data processing, Hadoop was an open source framework which was used widely in large data sets processing. For this purpose, this paper designed a log analysis system of automatic ticketing system based on Hadoop, in this way, we could collect and analyze the log data of TVM and make the result meet our demand by Map/Reduce Algorithm. Meanwhile it was verif i ed that the System was effective and feasible.
Hadoop; Ticket Vending Machine(TVM); distributed computing; log analysis
U293.22∶TP39
A
1005-8451(2014)07-0020-04
2014-01-06
王 斌,在讀碩士研究生;李 超,助理研究員。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
電子制作(2018年18期)2018-11-14 01:48:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
