面向遙感衛星數據獲取應用的時間序列云量預測方法
2014-08-01 01:47:36王志信黃鵬林友明賈秀鵬
遙感信息 2014年3期
關鍵詞:模型
王志信,黃鵬,林友明,賈秀鵬
(1.中國科學院大學,北京 100049;2.中國科學院遙感與數字地球研究所,北京 100094)
1 引 言
為滿足全球礦產資源、作物估產、水資源、森林生態和城市變化檢測等應用領域的特定數據獲取需求,遙感技術特別是光學遙感技術在其中發揮了重要作用[1-4]。在光學遙感數據獲取應用中,對于特定目標區域,如果在云量覆蓋較多的時候進行衛星成像規劃,則容易得到利用價值較低的多云數據,同時也會造成衛星資源的浪費,而如果能提前預知云量覆蓋情況,選擇云量覆蓋較少的時段進行衛星成像規劃,則更有利于獲取到滿足遙感應用需求的少云或無云數據。因此,如何進行云量預測,以獲取優質的能滿足遙感應用需求的無云或少云數據,便成為了一個重要問題。
然而,目前還沒有直接面向衛星成像規劃的云量預測方法。在云量預測相關模型方法方面,應用較多的是與氣象相關的短期預測模型,此類模型主要是利用一些模型方法,如模式識別、交叉相關法等來對云變化進行短期預測[5-6],預測期通常為幾小時。例如,利用衛星云圖對一個熱帶颶風進行為期幾小時的短期預測。而一般衛星成像規劃所需要的預測時間長度要遠大于幾小時,此類短期預測模型對于衛星成像規劃來說實際應用價值不大。還有一類有代表性的模型即人工神經網絡模型(Artificial Neural Network,ANN),這是一種應用于對大腦神經突觸聯接的結構進行信息處理的數學模型。它具有很多優點,如自學習功能,這對于預測有特別重要的意義,還具有聯想存儲功能、具有高速尋找優化解的能力等[7-8]。雖然神經網絡模型的這些優點使它可以應用于云量預測,但是由于影響云分布的因素眾多,且衛星規劃的區域范圍不定,大到國家小到城市都有可能,這中間牽涉到的眾多因素將導致神經網絡中節點的確定和學習過程非常復雜,因而,很難建立一個能夠全面描述并準確預測大范圍云量的模型。這使得神經網絡模型也不太適用于衛星數據獲取所要求的云量預測。
為了解決傳統云量預測模型不能滿足遙感實際應用需求的問題,本文采用時間序列分析預測的方法,對云量進行預測。首先,針對云量數據本身具有時間序列的特點,對云量進行分類。然后,在分類的基礎上對不同的類型采取不同的模型進行預測,最終得到云量預測結果,從而避免考慮眾多的云量影響因素導致建模困難的問題,利用云量預測結果信息可為衛星成像規劃提供參考,有利于更好地獲取無云或少云數據,減少衛星資源的浪費,滿足遙感數據應用需求具有重要的現實意義。
2 時間序列分析建模方法
1927年,英國統計學家G.U.Yule(1871~1951)提出了自回歸(Auto Regressive,AR)模型。不久之后,英國數學家、天文學家G.T.Walker爵士在分析印度大氣規律時使用了滑動平均(Moving Average,MA)模型和自回歸滑動平均(Auto Regressive Moving Average,ARMA)模型(1931年)。這些模型奠定了時間序列時域分析方法的基礎。1970年,美國統計學家G.E.P.Box和英國統計學家G.M.Jenkins聯合出版了《時間序列分析—預測與控制》一書(文獻[9])。在書中,Box和Jenkins在總結前人研究的基礎上,系統地闡述了對求和自回歸滑動平均(Autoreg Ressive Integrated Moving Average,ARIMA)模型的識別、估計、檢驗及預測的原理及方法。這些時間序列分析的方法,已經成為時域分析方法的核心內容。
2.1 ARMA模型
自回歸滑動平均模型(Auto Regression Moving Average,ARMA)是目前最常用的擬合平穩序列的模型。其模型結構如下:
(1)
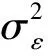
ARMA(p,q)模型可以簡寫為:
xt=φ1xt-1+φ2xt-2+…+φpxt-p+εt-θ1εt-1-θ2εt-2-…-θqεt-q
(2)
引進延遲算子,ARMA(p,q)模型簡記為Φ(B)xt=Θ(B)εt。其中,Φ(B)=1-φ1B-φ2B2-…-φpBp,為p階自回歸系數多項式。Θ(B)=1-θ1B-θ2B2-…-θqBq,為q階滑動平均系數多項式。當q=0時,ARMA(p,q)模型就退化成了AR(p)模型;當p=0時,ARMA(p,q)模型就退化成了MA(q)模型。所以,AR(p)模型和MA(q)模型實際上是ARMA(p,q)模型的特例,它們都統稱為ARMA模型。
2.2 ARIMA模型
ARMA(p,q)模型描述的是平穩時間序列,然而在實際工作中遇到的很多都是非平穩時間序列。為了將其平穩化,通常利用一次差分或多次差分運算把原時間序列轉化成平穩時間序列。一個時間序列如果能通過差分運算轉化為平穩時間序列,則稱這個非平穩時間序列為差分平穩時間序列。對差分平穩時間序列可以使用ARIMA模型進行擬合。
2.2.1 差分運算

2.2.2 ARIMA模型
具有如下結構的模型稱為求和自回歸移動平均(Autoreg Ressive Integrated Moving Average)模型,簡記為ARIMA(p,d,q)模型:
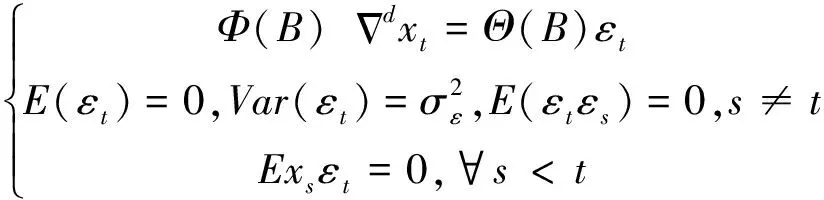
(3)
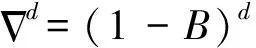
(4)
2.3 SARIMA模型
在某些時間序列中,存在著明顯的周期性變化。這種周期性是由于季節性變化(包括季度、月度、周度等變化)或其他一些固有因素引起的,這類序列稱為季節性序列。描述這類序列,本文用季節時間序列模型(Seasonal ARIMA model,SARIMA)表示。當序列具有短期相關性時,通常可以使用低階ARMA(p,q)模型提取。當序列具有季節效應,季節效應本身還具有相關性時,季節相關性可以使用以周期步長為單位的ARMA(P,Q)模型提取。由于短期相關性和季節效應之間具有乘積關系,所以擬合模型實質為ARMA(p,q)和ARMA(P,Q)的乘積。綜合前面d階趨勢差分和D階以周期S為步長的季節差分運算,對原觀察值序列擬合的乘積模型完整的結構如下:
(5)
式中:Θ(B)=1-θ1B-…-θqBq,ΘS(B)=1-θ1BS-…-θQBQS,Φ(B)=1-φ1B-…-φpBp,ΦS(B)=1-φ1B-…-φPBPS。該乘積模型簡記為ARIMA(p,d,q)×(P,D,Q)S。
3 實驗方法設計
3.1 數據源
數據源采用ISCCP的D2云數據集。國際衛星云氣候研究計劃(ISCCP)成立于1982年,作為世界氣候研究計劃(WCRP)之一,它主要通過收集和分析氣象衛星輻射測量值來研究全球云分布、屬性以及每日、每季和每年的變化。其生產的數據集不僅可以用來研究云在氣候變化中所扮演的角色,還可以用來研究云在輻射能量交換中所起的作用以及它在全球水循環中所起的作用[10-11]。ISCCP提供的云量數據分為不同的類別,主要包括:B3和BT級別,大氣數據,海冰和雪數據,DX、D1、D2級別。其中,D2數據是所有級別數據當中具有最優質云量信息的數據,在云量研究中應用廣泛,因而數據源選擇D2數據集。
3.2 實驗方法
3.2.1 數據讀取及分類
讀取ISCCP的D2數據集中與云量有關的數據并提取云量網格的歷史云量特征,對全球云量網格進行分類按照ISCCP數據集的說明讀取云氣候學數據中的月平均云量數據后,針對云量數據的時空分布各異的特征首先對全球云量網格進行分類,在此基礎上針對不同特征進行相應的建模預測。
首先,判斷每個網格的月平均云量時間序列的平穩性。判斷某個序列Xi的平穩性主要是通過單位根檢驗,判斷標準為ADF檢驗(Augmented Dickey-Fuller)。構造ADF檢驗統計量:是參數ρ的樣本標準差。當τ 大于DW臨界值,則序列存在單位根,是非平穩序列。反之則為平穩序列。在此基礎上,對于非平穩序列,進一步判斷序列是否具有季節性;主要判斷標準為自相關函數ACF(AutoCorrelation function)。自相關函數ρt,sρt,s=Corr(xt,xs),t,s=0,±1,±2,…,其中,{xt,t=0,±1,±2,…}是隨機過程。具有季節性的云量時間序列的ACF具有季節周期為12的周期性特征,即若某序列的ACF在滯后期12的整數倍出現峰值,則該序列存在季節性特征,反之,則序列不存在季節性特征。
其次,根據分類結果選擇合適的模型。采用分類樹分類方法對全球云量網格進行分類:對時間序列是否平穩進行判斷;進一步對時間序列是否存在季節性進行判斷,將全球云量網格分為以下3類:
分類①:月平均云量時間序列平穩類型;
分類②:月平均云量時間序列不平穩,同時具備季節周期性變化,即月平均云量時間序列季節非平穩類型;
分類③:月平均云量時間序列不平穩,不具備季節周期性變化,即月平均云量時間序列普通非平穩類型。
3.2.2 選取模型
針對不同的云量類型,選取相應的模型進行預測:
對于分類①,選擇建立平穩時間序列模型——ARMA模型;
對于分類②,選擇建立非平穩季節性時間序列模型——SARIMA模型;
對于分類③,選擇建立非平穩時間序列模型——ARIMA模型。
3.2.3 數據預處理
選取模型之后,根據不同的模型要求,對歷史云量數據進行相應的處理。ARMA模型可以直接應用原始數據;ARIMA模型則需要在結合檢驗平穩性的基礎上,對數據進行差分處理;季節性SARIMA模型需要結合檢驗平穩性的基礎上,根據需要對數據進行季節差分和普通差分處理。
3.2.4 參數估計
根據歷史云量數據和相應的模型,需要對模型進行參數估計。一般情形下,參數估計分兩步工作,第1步,找出參數的初步估計或稱參數的初始估計,利用樣本自相關函數對模型參數進行初步估計,例如對ARMA模型的特例AR(P)模型具體可利用Yule-Walker方程進行參數估計。第2步,在初步估計的基礎上,按照一定的估計準則,求得模型參數的精細估計。模型參數的估計計算復雜,需要由計算機完成。
3.2.5 模型診斷
為確定模型擬合是否充分,對殘差進行分析,檢驗殘差的同方差性、正態性和獨立性,檢驗殘差是否接近白噪聲,同時考慮過度擬合和參數冗余,對模型做出相應修正。
3.2.6 預測
基于最小化的均方預測誤差方法,利用第i個網格云量數據和相應模型對云量進行預測,得出該網格未來數月的云量預測結果數據。對于某序列Xi來說可獲得直到時間t的歷史數據,即x1,x2,…xT-1,xT,預測未來e期的值xe+t,稱時間t為預測起點,e為預測前置時間,用xt(e)代表預測值,最小均方誤差預測如下:xt(e)=E(xe+t|x1,x2,…xT-1,xT)。它的原理是用x1,x2,…xT-1,xT(為方便起見記為y)的函數來預測x,標準是最小化均方誤差,這里需要選擇函數h(y),使得下式達到最小:E[x-h(y)]2根據概率論條件期望性質,上述式子可寫為:E{[x-(y)]2|Y=y}=E{[x-h(y)]2Y=y},因此對于每個y,h(y)的最優選擇都是h(y)=E(x|Y=y),因而h(y)的這一選擇可使得E[x-h(y)]2整體達到最小,因此,h(y)=E(x|Y)是基于所有y的函數所得的x的最優預測[12]。
4 實驗及結果
4.1 2007年平均云量預測實驗
選取北京地區為感興趣區,在時間上選取1984年至2006年間22年的月平均云量數據。利用此歷史云量數據對2007年12個月的月平均云量進行預測,得到12個月份的月平均云量預測值并與2007年份真實云量值進行對比驗證。
提取北京地區所在網格的月平均云量時間序列;判斷月平均云量時間序列的平穩性。

圖1 1984年到2006年北京地區云量序列圖
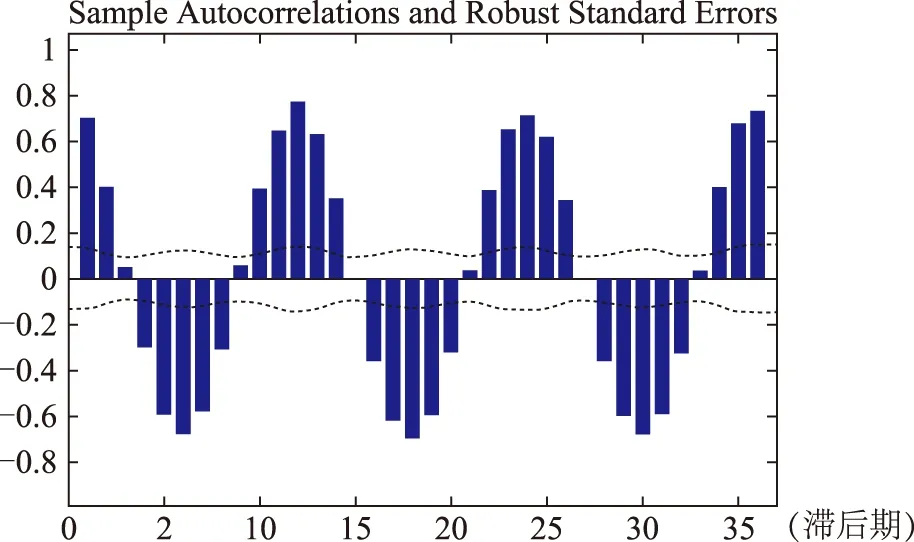
圖2 北京地區云量序列自相關函數圖
北京地區云量序列的ACF如圖2所示。從圖中可知該序列是非平穩的,并且具有明顯的季節性特征。采用ADF檢驗,h=0檢驗的P值:pValue=0.3543,樣本統計量:stat=-0.8112,拒絕臨界值:cValue=-1.9417,由此可見屬于第2類,模型識別為SARIMA模型。季節性SARIMA模型需要在檢驗平穩性的基礎上,根據云量數據本身特點對數據進行一次季節差分和一次普通差分處理,采用SARIMA模型進行分析預測后得出預測值,并跟真實值進行驗證。
如圖3所示,用1984年到2006年22年數據預測2007年12個月云量。得出2007年12個月份的預測值,預測值的80%、95%置信區間。與2007年實際值比較,實際真實值均落在80%置信區間內,平均相對誤差3.60%,最大相對誤差5.29%,均方誤差3.2199。
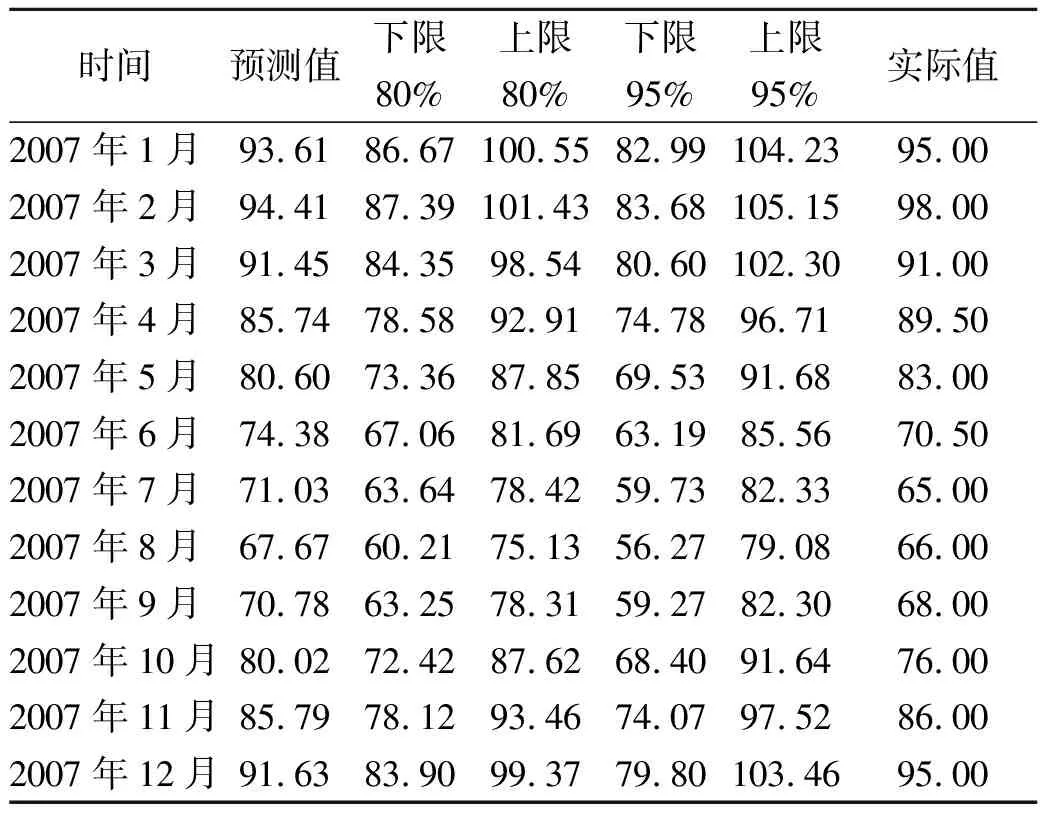
表1 北京地區2007年預測值與實際值
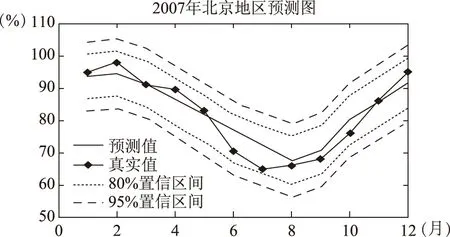
圖3 利用1984年到2006年22年數據預測2007年12個月份的預測圖
4.2 1997年平均云量預測
仍選取北京為感興趣區,但在時間上選取1984年到1996年的12年月平均云量數據,對1997年進行預測值并與1997年實際值進行比較,結果顯示,9月份實際值落在95%置信區間,其余月份實際值均落在80%置信區間內,平均相對誤差4.18%,最大相對誤差15.29%,均方誤差4.2902。
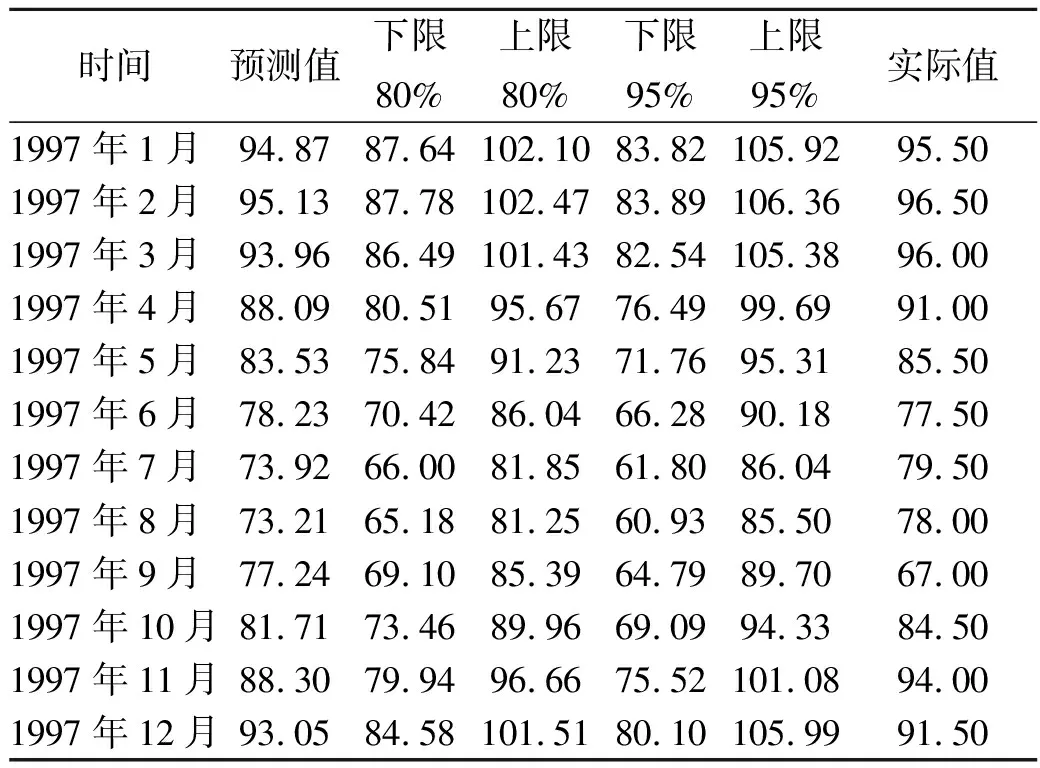
表2 北京地區1997年預測值和實際值
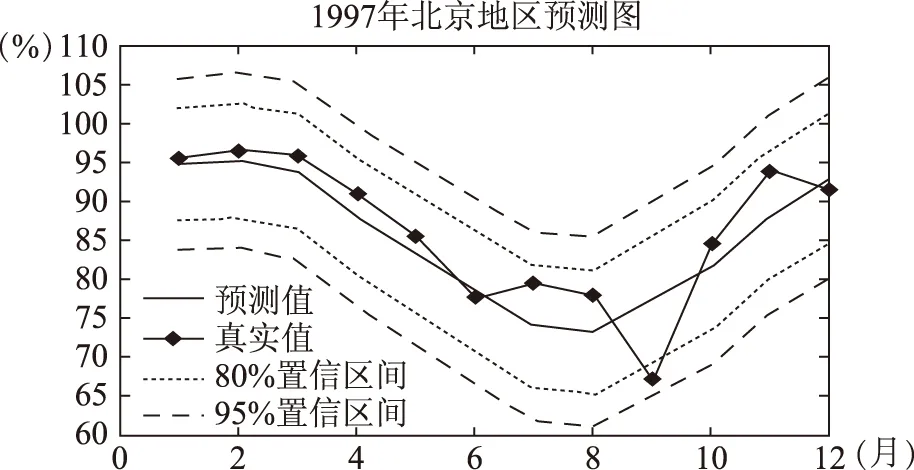
圖4 利用1984年到1996年12年數據預測1997年12個月份的預測圖
4.3 2009年平均云量預測實驗
選取烏魯木齊為感興趣區,在時間上選取1984年到2008年間24年月平均云量數據對2009年份12個月份月平均云量進行預測和驗證,結果顯示,2009年12個月份的預測值,預測值的80%、95%置信區間。與2009年實際值比較,實際值除一月份落在95%置信區間外,其余月份均落在80%置信區間內,平均相對誤差2.80%,最大相對誤差6.55%,均方誤差2.8871。
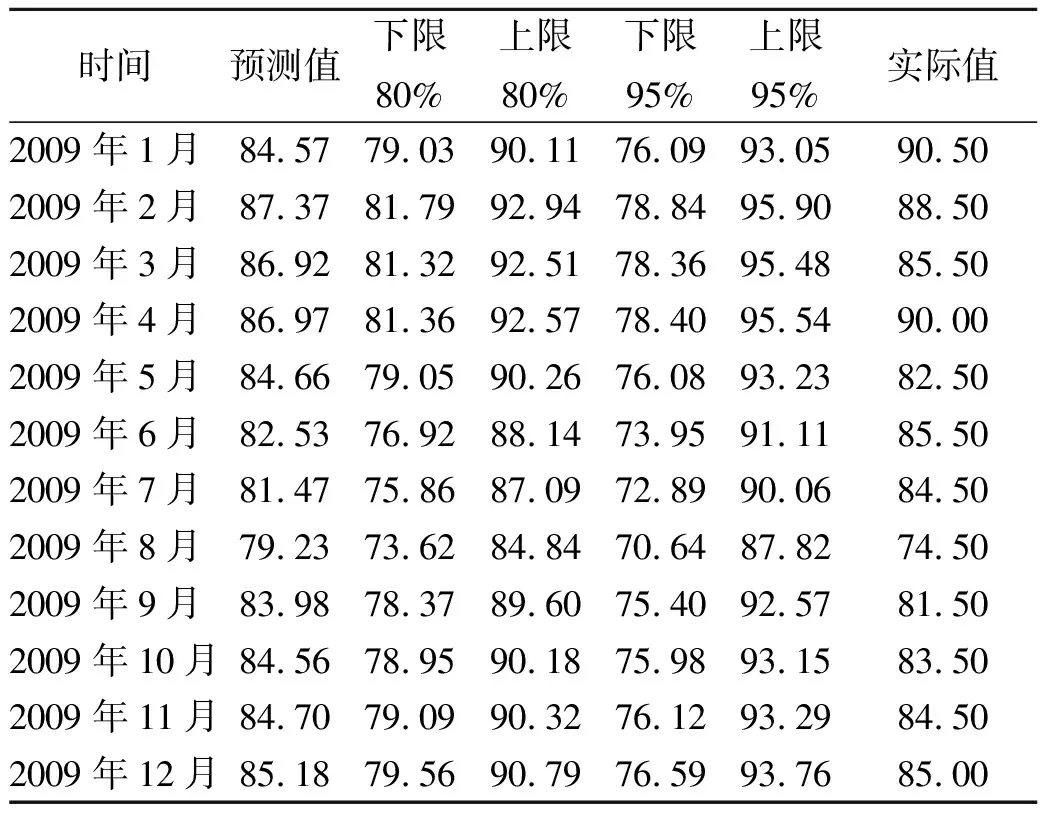
表3 烏魯木齊地區2009年預測值與實際值
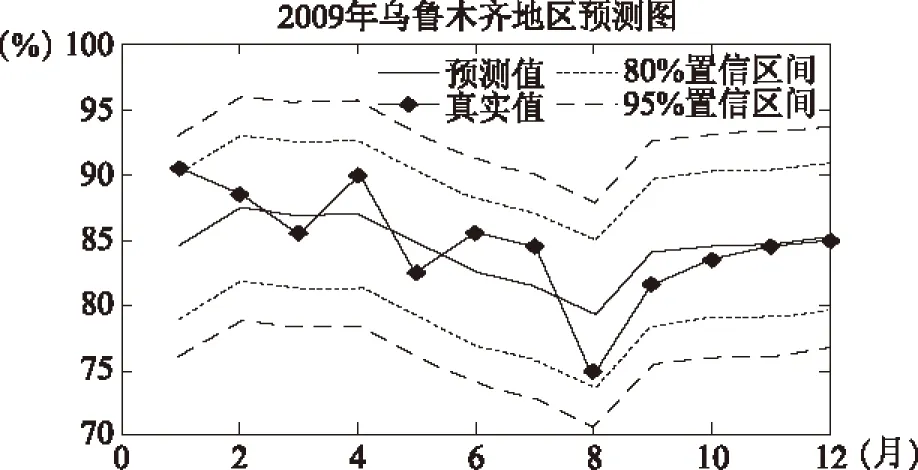
圖5 利用1984年到2008年24年數據預測2009年12個月份的預測圖
4.4 預測結果分析
由以上實驗結果可知,絕大部分云量實際值落在云量預測80%置信區間之內,而且,不論是利用10年還是20年的歷史數據,均能得到精度較好的結果,說明此方法的時間適應性較好。更為重要的是,云量預測結果較準確地反映了云量的變化趨勢,這對于衛星成像規劃具有很重要的意義,利用云量變化趨勢信息,可在長周期衛星成像規劃中發揮重要參考作用。以北京為例,根據云量預測參考信息,要想獲取此地區的少云數據,應該盡量選取云量低的7、8和9月份來進行規劃,相比在12、1和2月則更容易獲取到滿足遙感應用需求的數據。
5 結束語
針對目前沒有能夠直接滿足遙感數據獲取需求相關的云量預測方法的問題,本文提出了一種利用時間序列分析預測方法對云量進行預測的方法。在云量特征分類的基礎上,整合ARMA、ARIMA和SARIMA 3種模型對云量進行預測,并得到了滿意的預測結果。根據云量預測結果參考信息,選擇云量覆蓋較少的時間段進行衛星成像規劃,有利于更合理的進行衛星成像規劃,對滿足遙感數據獲取需求有重要意義。由于云量本身的復雜性以及當前云量預測研究還處在初步研究階段,本方法仍存在一定的不足,如為了更好地滿足衛星成像規劃的實際需求,以月為單位的預測結果在時間分辨率上還有待提高,更精確的預測方法還有待進一步研究。
參考文獻:
[1] SANKEY J B,WALLACEB C S,RAVIC S.Phenology-based remote sensing of post-burn disturbance windows in rangelands[J].Ecological Indicators,2013(30):35-44.
[2] TULBURE M G,BROICH M.Spatiotemporal dynamic of surface water bodies using Landsat time-series data from 1999 to 2011[J].Journal of Photogrammetry and Remote Sensing,2013,79(2013):44-52.
[3] JAWAK S D,LUIS A J.Improved land cover mapping using high resolution multiangle 8-band WorldView-2 satellite remote sensing data[J].Journal of Applied Remote Sensing,2013,7(1):73-86.
[4] HANSSAN Q K,RAHMAN K M.Remote sensing-based determination of understory grass greening stage over boreal forest[J].Journal of Applied Remote Sensing,2013,7(1):32-45.
[5] ENDLIEH R M,WOLF D E,HALL D L,et a1.Use of a pattern recognition technique for determining cloud motions from Sequences of Satellite photographs[J].Journal of Applied Meteorology,1971,10(2):105-117.
[6] THOMASM H,THOMASM N.A short-term cloud forecasts scheme using cross correlation[J].Weather and Forecasting,1993,8(4):401-411.
[7] LIU H,TIANA H Q,PANA D,et al.Forecasting models for wind speed using wavelet,wavelet packet,time series and Artificial Neural Networks[J].Applied Energy,2013,107(C):191-208.
[8] MALIK M H,ARIF A F.ANN prediction model for composite plates against low velocity impact loads using finite element analysis[J].Composite Structures,2013,101(2013):290-300.
[9] BOX G,JENKINS G M.Time series analysis:forecasting and control[M].Beijing:China Statistics Press,1997:101-135.
[10] HAN Q Y,ROSSOW W B,LACIS A A.Near-global survey of effective cloud droplet radii in liquid water clouds using ISCCP data[J].Journal of Climate,1994,7(1):465-497.
[11] HAN Q,ROSSOW W B,CHOU J,et al.Global variation of droplet column concentration in low-level clouds[J].Geophysical Research Letters,1998,25(9):1419-1422.
[12] JONATHAN D C,CHAN K S.Time series analysis with applications in R[M].2nd ed.Beijing:China Machine Press,2011:137-152.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
