基于動(dòng)態(tài)權(quán)值的多策略領(lǐng)域本體概念自動(dòng)抽取
2014-09-12 11:17:14張華楠劉勝全劉艷劉華鵬李鵬
計(jì)算機(jī)工程與應(yīng)用 2014年21期
張華楠,劉勝全,劉艷,劉華鵬,李鵬
1.新疆大學(xué)信息科學(xué)與工程學(xué)院,烏魯木齊 830046
2.新疆大學(xué)現(xiàn)代教育技術(shù)中心,烏魯木齊 830046
基于動(dòng)態(tài)權(quán)值的多策略領(lǐng)域本體概念自動(dòng)抽取
張華楠1,劉勝全2,劉艷1,劉華鵬1,李鵬1
1.新疆大學(xué)信息科學(xué)與工程學(xué)院,烏魯木齊 830046
2.新疆大學(xué)現(xiàn)代教育技術(shù)中心,烏魯木齊 830046
為了提高中文領(lǐng)域本體概念抽取的自動(dòng)化程度及準(zhǔn)確率,提出了一種基于動(dòng)態(tài)權(quán)值的多策略中文領(lǐng)域本體概念自動(dòng)抽取方法。針對(duì)中文領(lǐng)域本體概念的特點(diǎn),采用自動(dòng)學(xué)習(xí)的規(guī)則學(xué)習(xí)模式,篩選出候選概念,將改進(jìn)的DR&DC、TF-IDF和NC-Value三種策略融合,對(duì)候選概念進(jìn)行領(lǐng)域歸屬度排序,將最終權(quán)重超過(guò)閾值的概念存入最終概念集合。實(shí)驗(yàn)證明了該方法抽取領(lǐng)域概念的可行性和有效性。
動(dòng)態(tài)權(quán)值;本體學(xué)習(xí);多策略;概念抽取
本體(ontology)是概念模型的明確的規(guī)范說(shuō)明[1]。目前,本體已經(jīng)被廣泛應(yīng)用于語(yǔ)義Web、智能信息檢索、信息集成、數(shù)字圖書(shū)館等領(lǐng)域[2]。本體中的知識(shí)總在不斷地發(fā)展和更新,這種動(dòng)態(tài)性就決定了本體不能以手工方式構(gòu)造,需要自動(dòng)或半自動(dòng)方式來(lái)構(gòu)建本體。因此,本體學(xué)習(xí)(ontology learning)[3]技術(shù)應(yīng)運(yùn)而生,它可以實(shí)現(xiàn)本體的自動(dòng)或半自動(dòng)構(gòu)建。本體概念獲取是本體構(gòu)建的基礎(chǔ)問(wèn)題,影響著本體后續(xù)步驟的構(gòu)建和應(yīng)用。
純文本缺乏一定的結(jié)構(gòu),要使機(jī)器能夠自動(dòng)地理解純文本并從中抽取出所需要的知識(shí),則必須利用自然語(yǔ)言處理(NLP)技術(shù)對(duì)其預(yù)處理,然后利用統(tǒng)計(jì)、機(jī)器學(xué)習(xí)等手段從中獲取知識(shí)。與國(guó)外相比,中文領(lǐng)域本體概念獲取的研究工作相對(duì)較少。文獻(xiàn)[4]提出利用Bootstrapping的機(jī)器學(xué)習(xí)技術(shù),從大規(guī)模無(wú)標(biāo)注真實(shí)語(yǔ)料中自動(dòng)獲取領(lǐng)域詞匯。但并未對(duì)抽取的概念進(jìn)行領(lǐng)域量化導(dǎo)致學(xué)習(xí)到的領(lǐng)域詞數(shù)目偏少。文獻(xiàn)[5]提出采用非線性函數(shù)與“成對(duì)比較法”相結(jié)合的方法,進(jìn)行關(guān)鍵詞的自動(dòng)抽取。但只考慮了位置與詞頻兩個(gè)因素,實(shí)驗(yàn)結(jié)果的準(zhǔn)確率并不很高。文獻(xiàn)[6]提出一種將統(tǒng)計(jì)方法與規(guī)則方法相結(jié)合的專業(yè)領(lǐng)域術(shù)語(yǔ)抽取算法。但概念的過(guò)濾算法很不完善導(dǎo)致結(jié)果中出現(xiàn)大量噪聲詞語(yǔ)。文獻(xiàn)[7]提出一種主題概念抽取的多文檔文摘方法,但該方法是以句子為單位進(jìn)行抽取,并不適用于文本。文獻(xiàn)[8]提出一種利用詞語(yǔ)之間量化關(guān)系來(lái)提取文本主題的方法。但只考慮了詞語(yǔ)間的量化關(guān)系,使得該方法只適合主題概念突出的領(lǐng)域文本。
目前,多特征融合進(jìn)行概念抽取的趨勢(shì)越來(lái)越明顯。文獻(xiàn)[9]采用互信息與log-likelihood相結(jié)合的策略對(duì)候選雙字詞匯進(jìn)行左右擴(kuò)充,過(guò)濾后得到領(lǐng)域概念。文獻(xiàn)[10]使用子串歸并、搭配檢驗(yàn)和領(lǐng)域相關(guān)度計(jì)算技術(shù)來(lái)分別解決短語(yǔ)結(jié)構(gòu)完整度判斷、搭配合理性檢查、領(lǐng)域信息量三個(gè)問(wèn)題。以上方法自動(dòng)化程度不高,且各策略融合時(shí)所取的權(quán)值為靜態(tài),不能真實(shí)反應(yīng)概念的領(lǐng)域歸屬度。
本文嘗試將改進(jìn)的DR&DC、TF-IDF和NC-Value三種策略融合,提出一種基于動(dòng)態(tài)權(quán)值的多策略融合中文領(lǐng)域本體概念自動(dòng)抽取方法,旨在提高中文領(lǐng)域本體概念抽取的自動(dòng)化程度及正確率。
1 基于動(dòng)態(tài)權(quán)值的多策略融合概念抽取框架
基于動(dòng)態(tài)權(quán)值的多策略融合的中文領(lǐng)域本體概念自動(dòng)抽取的框架如圖1所示,系統(tǒng)的輸入是領(lǐng)域文本,輸出是領(lǐng)域本體概念集合。領(lǐng)域文本經(jīng)過(guò)預(yù)處理以后進(jìn)行分詞和詞性標(biāo)注。概念抽取過(guò)程中,首先使用自動(dòng)學(xué)習(xí)到的規(guī)則過(guò)濾出可能成為領(lǐng)域概念的候選概念,而在對(duì)候選概念進(jìn)行排序時(shí),本文采用多策略融合排序算法,這種算法融合了各策略的優(yōu)點(diǎn)且能動(dòng)態(tài)分配權(quán)值,從而能更加真實(shí)地反應(yīng)概念的領(lǐng)域歸屬度。最后將權(quán)重超過(guò)給定閾值的概念存入最終本體概念集合。

圖1 基于動(dòng)態(tài)權(quán)值的多策略融合概念自動(dòng)抽取框架
2 策略分析與融合
2.1 預(yù)處理與分詞
在面向文本進(jìn)行概念抽取之前,首先要進(jìn)行文本預(yù)處理。預(yù)處理是指對(duì)文本中的無(wú)用信息進(jìn)行處理,以便減少誤差。尤其對(duì)于領(lǐng)域中的論文和專著,需要?jiǎng)h除其中的作者、數(shù)學(xué)公式、圖片等無(wú)關(guān)信息。然后進(jìn)行分詞、詞性標(biāo)注等工作。
在本研究采用的分詞工具是中國(guó)科學(xué)院計(jì)算技術(shù)研究所開(kāi)發(fā)的ICTCLAS(一種基于隱馬爾可夫模型的漢語(yǔ)詞法分析系統(tǒng)[11])。經(jīng)過(guò)分詞處理之后,文本被切分成具有詞性標(biāo)注的中文組詞及符號(hào)。
2.2 規(guī)則自動(dòng)學(xué)習(xí)
在規(guī)則的學(xué)習(xí)階段,以往的方法都是憑借經(jīng)驗(yàn)總結(jié)領(lǐng)域概念的詞性組合規(guī)則,但中文名詞性短語(yǔ)的詞性構(gòu)成方式多種多樣,無(wú)法一一列舉出這些組成方式,且規(guī)則模板的精確度與靈活性不可兼得。
科技文獻(xiàn)中關(guān)鍵詞嚴(yán)謹(jǐn)科學(xué),是一種半結(jié)構(gòu)化的數(shù)據(jù),因此,根據(jù)關(guān)鍵詞的組合模式本文提出一種基于關(guān)鍵詞的規(guī)則自動(dòng)學(xué)習(xí)方法,流程如圖2所示。

圖2 規(guī)則自動(dòng)學(xué)習(xí)流程
基于關(guān)鍵詞的規(guī)則自動(dòng)學(xué)習(xí)步驟如下:首先提取科技文獻(xiàn)的關(guān)鍵詞部分,然后對(duì)每組關(guān)鍵詞進(jìn)行分詞及詞性標(biāo)注,記錄其組合模式及頻次,檢查組合模式的合法性,最后將符合Rule的規(guī)則按其頻次放入規(guī)則庫(kù)中。
在規(guī)則檢查階段使用的規(guī)則如下:
Rule1:概念中不得包含如下性質(zhì)的詞語(yǔ):標(biāo)點(diǎn)符號(hào)、代詞、語(yǔ)素、習(xí)用語(yǔ)、狀態(tài)詞、非語(yǔ)素詞、處所詞、擬聲詞、嘆詞、語(yǔ)氣詞和成語(yǔ)。
Rule2:概念不得以連詞、助詞和后接成分作為詞首。
Rule3:概念不得以連詞、方位詞和前接成分性質(zhì)的詞語(yǔ)結(jié)尾。
Rule4:概念中至少有一個(gè)詞屬于名詞、動(dòng)詞、量詞、習(xí)用語(yǔ)、簡(jiǎn)稱略語(yǔ)或后接成分。
同時(shí)滿足這四條規(guī)則的概念在候選概念集合中占到了96.33%[10]。系統(tǒng)使用上述規(guī)則進(jìn)行規(guī)則的自動(dòng)評(píng)價(jià),符合規(guī)則且在系統(tǒng)規(guī)則庫(kù)中未出現(xiàn)的規(guī)則加入到規(guī)則庫(kù)中。在后繼步驟中,使用規(guī)則庫(kù)中的規(guī)則來(lái)抽取候選概念。
2.3 多策略融合排序
候選排序方法涉及到兩個(gè)問(wèn)題:策略的選擇和策略的加權(quán)算法。
本文采用改進(jìn)的DR&DC、TF-IDF和NC-Value三種策略融合進(jìn)行候選概念的領(lǐng)域歸屬度排序。
2.3.1 改進(jìn)的DR&DC
傳統(tǒng)的DR&DC[12]只考慮了詞頻、領(lǐng)域文本與參照文本數(shù)量這兩個(gè)特征,因此其結(jié)果受普通文本集質(zhì)量的影響很大,從而影響了該方法的實(shí)際可行性。本文借鑒并改進(jìn)DR&DC,采用領(lǐng)域相關(guān)性和領(lǐng)域一致性對(duì)候選概念進(jìn)行領(lǐng)域歸屬度計(jì)算。
本文綜合考慮如下幾點(diǎn):(1)復(fù)合短語(yǔ)的長(zhǎng)度,越長(zhǎng)的概念表示的語(yǔ)義信息越豐富,越有可能成為領(lǐng)域概念;(2)領(lǐng)域文本的數(shù)量與參照文本的數(shù)量;(3)詞的位置信息,不同位置的短語(yǔ)反映了該詞在領(lǐng)域中的相對(duì)重要性。
改進(jìn)后的領(lǐng)域相關(guān)性DR定義如下:
定義1

其中,dj指領(lǐng)域Dk中的第j個(gè)文本;twt,j是復(fù)合短語(yǔ)t在文本j中的詞重;Nk是領(lǐng)域Dk中的文本數(shù)量;N是所有文本的數(shù)量;L是復(fù)合短語(yǔ)t的長(zhǎng)度,即中文詞語(yǔ)數(shù)與英文單詞數(shù)之和,Tt,j是復(fù)合短語(yǔ)t在文本j題目中出現(xiàn)的次數(shù),At,j是復(fù)合短語(yǔ)t在文本摘要中出現(xiàn)的次數(shù),Bt,j是復(fù)合短語(yǔ)t在文本j正文中出現(xiàn)的次數(shù),x,y,z分別為概念出現(xiàn)在標(biāo)題、摘要、正文的權(quán)重。
領(lǐng)域一致性是指概念在特定領(lǐng)域的分布程度,也就是說(shuō)對(duì)于領(lǐng)域相關(guān)度相同的語(yǔ)義串,在領(lǐng)域文本中分布越均勻的概念越有可能是領(lǐng)域的概念。領(lǐng)域一致性DC的定義如下:

其中,ft,j是指詞t在領(lǐng)域Dk中的文本dj中的頻率。此公式可解釋為若某復(fù)合短語(yǔ)在領(lǐng)域文本中均勻分布,那么相對(duì)于在單個(gè)文本中出現(xiàn)多次的復(fù)合短語(yǔ),前者更可能是領(lǐng)域的概念。
復(fù)合短語(yǔ)的權(quán)重TW可以表達(dá)為:

改進(jìn)后的DR&DC額外考慮了概念長(zhǎng)度、領(lǐng)域文本域參照文本的數(shù)量比、概念位置信息等影響概念領(lǐng)域歸屬度的因素,因此能得到更加準(zhǔn)確的權(quán)值,切實(shí)反應(yīng)概念的領(lǐng)域歸屬度。
2.3.2 TF-IDF
TF統(tǒng)計(jì)候選概念在文檔中出現(xiàn)的頻率;IDF計(jì)算候選概念在領(lǐng)域的聚合程度;但傳統(tǒng)的TF-IDF[13]只能計(jì)算概念在單一文本內(nèi)的權(quán)重,本文對(duì)其進(jìn)行了改進(jìn),使其適應(yīng)大語(yǔ)料場(chǎng)景,改進(jìn)后的公式如下:

某一特定文件內(nèi)的高詞語(yǔ)頻率,以及該概念在整個(gè)文件集合中的低文件頻率,可以產(chǎn)生出高權(quán)重的TF-IDF。因此,TF-IDF傾向于過(guò)濾掉常見(jiàn)的詞語(yǔ),保留重要的詞語(yǔ)。
2.3.3 NC-Value
NC-Value是Frantzi[14]提出的,通過(guò)當(dāng)前詞在較長(zhǎng)候選概念中的出現(xiàn)頻率來(lái)確定。NC-Value參數(shù)將概念的上下文信息作為重要的特征引入到了考慮范圍,避免了只抽取到長(zhǎng)概念中的前部分就按照規(guī)則停止的情況。
其定義如下:
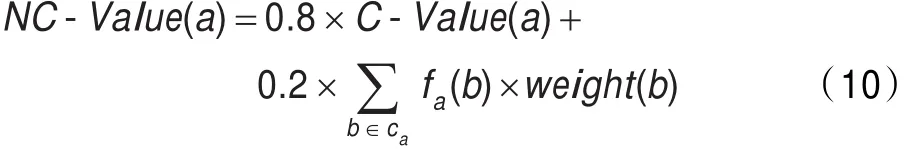
其中C-Value(a)表示概念a的C-Value值,fa(b)表示a的上下文b的詞頻,weight(w)表示a的上下文b的權(quán)重。
2.3.4 多策略融合算法
改進(jìn)的DR&DC考慮了概念長(zhǎng)度、概念位置、領(lǐng)域文本與參照文本的數(shù)量等特征;TF-IDF考慮單篇文檔中的概念頻率以及在文檔集合中概念的分布特征;NC-Value不僅考察了詞匯的頻率,還引入了具有包含關(guān)系的詞串的頻率對(duì)比,同時(shí)考慮了上下文信息以及概念內(nèi)部的結(jié)合強(qiáng)度。由于各方法所采用的特征類型重疊不多,將三種方法進(jìn)行融合能夠覆蓋中文概念抽取領(lǐng)域考慮的大多數(shù)特征類型[15],避免了只由個(gè)別特征類型決定最終排序情況的發(fā)生。融合三種方法,發(fā)揮各個(gè)方法的優(yōu)勢(shì),根據(jù)方法特性動(dòng)態(tài)賦予相應(yīng)的權(quán)值,使結(jié)果更能真實(shí)地體現(xiàn)概念的領(lǐng)域歸屬度。綜合考慮影響抽取結(jié)果的所有特征類型,旨在提高概念抽取的準(zhǔn)確率。
基于動(dòng)態(tài)權(quán)值的多策略融合的概念篩選模型如圖3所示。

圖3 基于動(dòng)態(tài)權(quán)值的多策略加權(quán)融合模型
改進(jìn)的DR&DC、TF-IDF、NC-Value分別計(jì)算某個(gè)概念的權(quán)重,然后根據(jù)方法本身考慮的特征綜合決定各策略的權(quán)值,各方法加權(quán)后得到概念的最終權(quán)重。基于動(dòng)態(tài)權(quán)值的多策略加權(quán)融合模型可以動(dòng)態(tài)設(shè)置各策略的權(quán)值,模型包含了靜態(tài)權(quán)值的策略融合,如將某兩種策略的權(quán)值設(shè)為零則表示余下一種策略的單一結(jié)果。
概念t的最終權(quán)重W(t)定義如下:
定義5

其中wk(t)是概念在某一策略的初級(jí)權(quán)重,wk是各策略的權(quán)值,其定義如下:


最終權(quán)重W(t)超過(guò)閾值θ的候選概念存入最終概念集合。
3 實(shí)驗(yàn)結(jié)果與分析
規(guī)則自動(dòng)學(xué)習(xí)所用的語(yǔ)料是計(jì)算機(jī)領(lǐng)域的267篇科技文獻(xiàn),共自動(dòng)學(xué)習(xí)到了89條規(guī)則,其中長(zhǎng)度3以下的64條,長(zhǎng)度4~6的25條。其中排名前十的規(guī)則如表1所示。
為了驗(yàn)證本文所提出方法的準(zhǔn)確性,選取了100篇計(jì)算機(jī)網(wǎng)絡(luò)的相關(guān)語(yǔ)料,同時(shí)用172篇政治、人文等領(lǐng)域的語(yǔ)料作為參考文本。實(shí)驗(yàn)用Java語(yǔ)言編程,經(jīng)過(guò)多次實(shí)驗(yàn)同時(shí)參考文獻(xiàn)[5]、文獻(xiàn)[12],最終設(shè)定的參數(shù)如表2所示。

表1 詞法構(gòu)成模式

表2 參數(shù)設(shè)定
表3是自動(dòng)抽取到的前15個(gè)概念及最終權(quán)重。

表3 概念與最終權(quán)重
從表3中可以看出,計(jì)算機(jī)網(wǎng)絡(luò)領(lǐng)域的重要概念都被正確抽取出來(lái)了。
為了比較,人工抽取了領(lǐng)域文本的224個(gè)概念,表4是動(dòng)態(tài)權(quán)值多策略融合方法在設(shè)定不同權(quán)值時(shí)的抽取結(jié)果比對(duì)。

表4 各方法比較
其中前三種方法分別是其他兩種策略權(quán)值為零時(shí)的結(jié)果,第四種方法則表示靜態(tài)權(quán)值(各策略均賦予1/3)的結(jié)果,第五種為本文的動(dòng)態(tài)權(quán)值多策略抽取結(jié)果,從實(shí)驗(yàn)結(jié)果可以看出,無(wú)論是在準(zhǔn)確率還是召回率方面,本文所提出的多策略融合方法均比其他方法有所提高。某些概念(如“電路”)在各策略初級(jí)權(quán)重排在較前的位置,但策略融合后的最終權(quán)重的排名卻后退了,更加符合現(xiàn)實(shí)情況,這驗(yàn)證了基于動(dòng)態(tài)權(quán)值的多策略融合抽取方法的合理性。動(dòng)態(tài)權(quán)值的多策略融合抽取方法能將發(fā)揮各策略的優(yōu)勢(shì),使結(jié)果更加真實(shí)地體現(xiàn)概念實(shí)際的領(lǐng)域歸屬度,但相應(yīng)地會(huì)增加抽取模型的復(fù)雜度。
分析可知,本文方法在概念抽取的準(zhǔn)確率和召回率提高的原因是采用了自動(dòng)的規(guī)則學(xué)習(xí),由此能得到盡可能多的候選概念,而后把多特征進(jìn)行綜合考慮,進(jìn)行動(dòng)態(tài)權(quán)值的多策略融合,篩選出能夠真實(shí)代表領(lǐng)域的領(lǐng)域概念。因此該方法對(duì)中文領(lǐng)域本體概念的自動(dòng)抽取有一定的積極意義。
4 結(jié)束語(yǔ)
本文在前人工作的基礎(chǔ)上進(jìn)行了擴(kuò)展和改進(jìn),嘗試將改進(jìn)的DR&DC、TF-IDF和NC-Value三種策略融合,提出了一種基于動(dòng)態(tài)權(quán)值的多策略融合的領(lǐng)域本體概念自動(dòng)抽取方法,實(shí)驗(yàn)證明該方法對(duì)領(lǐng)域概念抽取的準(zhǔn)確率有一定的提高,亦提高了概念抽取的自動(dòng)化程度。下一步的工作是用更大的語(yǔ)料進(jìn)行規(guī)則的自動(dòng)學(xué)習(xí),提高規(guī)則庫(kù)的完整度及準(zhǔn)確性,并在此基礎(chǔ)上擴(kuò)展抽取模型,提高模型的包含度,后期進(jìn)行領(lǐng)域本體概念關(guān)系的抽取,以探索自動(dòng)構(gòu)建本體的新方法。
[1]Guber T R.A translation approach to portable ontology specifications,Technical Report,KSL 92-71[R].Knowledge System Laboratory,1993.
[2]Deng Z H,Tang S W,Zhang M,et al.Overview of ontology[J]. Acta Scientiarum Naturalium Universitatis Pekinensis,2002, 38(5):730-738.
[3]杜小勇,李曼,王珊.本體學(xué)習(xí)研究綜述[J].軟件學(xué)報(bào),2006,17(9):1837-1847.
[4]Chen W L,Zhu J B,Yao T S.Automatic learning field words by bootstrapping[C]//Proc of the JSCL.Beijing:Tsinghua University Press,2003:67-72.
[5]Zheng J H,Lu J L.Study of an improved keywords distillation method[J].Computer Engineering,2005,31(18):194-196.
[6]Du B,Tian H F,Wang L,et al.Design of domain-specific term extractor based on multi-strategy[J].Computer Engineering,2005,31(14):159-160.
[7]宋宜辰,劉貴全.基于主題概念抽取的多文檔文摘方法[J].計(jì)算機(jī)工程,2010,36(4):190-192.
[8]蔣建惠,陳玉泉.基于詞語(yǔ)量化關(guān)系的主題概念抽取算法研究[J].計(jì)算機(jī)仿真,2009,26(12):122-125.
[9]田懷鳳.基于多策略的專業(yè)術(shù)語(yǔ)抽取處理技術(shù)的研究[J].計(jì)算機(jī)與現(xiàn)代化,2008(12):94-96.
[10]周浪,史樹(shù)敏,馮沖黃,等.基于多策略融合的中文術(shù)語(yǔ)抽取方法[J].情報(bào)學(xué)報(bào),2010,29(3):460-467.
[11]Qun L,Hua Ping Z,Hong-Kui Y,et a1.Chinese lexical analysis using cascaded hidden Mazkov model[J].Computer Research and Development,2004,41(8):1421-1429.
[12]Navigli R,Velardi P.Learning domain ontologies from document warehouse and dedicated web sites[J].Computational Linguistics,2004,30(2):151-179.
[13]Salton G,McGill M J.Introduction to modern information retrieval[M].[S.l.]:McGraw-Hill,1983.
[14]Frantzi K,Anaiadou S,Mima H.Automatic recognition of multi-word terms:the C-value/NC-value method[J]. International Journal on Digital Libraries,2000,3.
[15]游宏梁,張巍沈,鈞毅,等.一種基于加權(quán)投票的術(shù)語(yǔ)自動(dòng)識(shí)別方法[J].中文信息學(xué)報(bào),2011,25(3):9-16.
ZHANG Huanan1,LIU Shengquan2,LIU Yan1,LIU Huapeng1,LI Peng1
1.School of Information Science and Engineering,Xinjiang University,Urumqi 830046,China
2.Modern Educational Technology Center,Xinjiang University,Urumqi 830046,China
To improve the automation degree and accuracy of Chinese domain ontology concept extraction,a method of concepts automatic extraction based on dynamic weighted multi-strategy integration is proposed.This paper filters out the candidate concepts according to the rule templates using automatic learning;and then improved DR&DC,TF-IDF and NC-Value are integrated;it sequences the degree of domain membership of the candidate concept sets,and puts concepts whose weight exceeds the threshold value into final concept sets.After lots of experiments,the feasibility and validity of this method are proved.
dynamic weight;ontology learning;multi-strategy;concept extraction
A
TP182
10.3778/j.issn.1002-8331.1212-0040
ZHANG Huanan,LIU Shengquan,LIU Yan,et al.Automatic extraction method of domain ontology concepts based on dynamic weight multi-strategy.Computer Engineering and Applications,2014,50(21):152-156.
新疆維吾爾自治區(qū)科技攻關(guān)項(xiàng)目(No.200931103);新疆大學(xué)自然科學(xué)基金(No.XY110121)。
張華楠(1986—),男,碩士研究生,研究方向:本體學(xué)習(xí);劉勝全,教授,碩士生導(dǎo)師,研究方向:網(wǎng)絡(luò)應(yīng)用、語(yǔ)義Web;劉艷,講師,研究方向:電子商務(wù);劉華鵬,碩士研究生,研究方向:語(yǔ)義Web;李鵬,碩士研究生,研究方向:本體構(gòu)建。E-mail:zhangchris@163.com
2012-12-04
2013-02-06
1002-8331(2014)21-0152-05
CNKI出版日期:2013-03-13,http://www.cnki.net/kcms/detail/11.2127.TP.20130313.0950.013.html
猜你喜歡
現(xiàn)代裝飾(2022年1期)2022-04-19 13:47:32
小獼猴智力畫(huà)刊(2022年3期)2022-03-29 01:09:42
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:26:14
現(xiàn)代裝飾(2020年2期)2020-03-03 13:37:44
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·高一版(2018年9期)2018-10-09 06:46:48
Coco薇(2017年11期)2018-01-03 20:59:57
中學(xué)生數(shù)理化·高一版(2017年9期)2017-12-19 12:15:14
暨南學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版)(2016年9期)2017-01-15 13:52:02
