基于流形學習的JPEG圖像定量隱寫分析算法
2014-09-12 11:17:14張明超蔡曉霞陳紅
計算機工程與應用 2014年21期
張明超,蔡曉霞,陳紅
電子工程學院,合肥 230037
基于流形學習的JPEG圖像定量隱寫分析算法
張明超,蔡曉霞,陳紅
電子工程學院,合肥 230037
提出了一種基于DCT系數統計特性的JPEG圖像定量隱寫分析算法。該算法在對JPEG圖像DCT系數的統計模型進行研究的基礎上,提取了能夠反映嵌入容量變化規律的特征參數α。以特征參數α為基礎,提出了基于流形學習的特征提取算法,通過LIB-SVM分類器進行訓練,估計隱寫對DCT系數的更改比率。實驗結果表明,與傳統的定量分析算法相比,提出的算法具有更高的估計準確率和穩定性。
定量隱寫分析;特征提取;流形學習;JPEG圖像
1 引言
隱寫術[1]是研究如何隱藏信息的存在,目的是保護隱藏在載體中的秘密信息。隱寫分析,作為隱寫術的對抗技術,也是信息安全領域一個重要的研究方向,其目的是檢測進而提取載體中的秘密信息。目前,隱寫分析的研究主要集中于隱寫信息的檢測。而隱寫的提取作為隱寫分析與密碼分析的交叉領域[2],有關它的研究還非常少,尚沒有成熟的理論和方法。通常只要能夠判斷出秘密信息是否存在,就認為隱寫已被攻破。然而,為了能夠提取出秘密信息,分析者還需要隱密信號的更多細節,如隱密信息的長度或載體信號的更改比率。
定量隱寫分析[3],作為隱寫信息檢測和提取的中間環節,是指準確估計秘密信息的長度或信號的更改比率。目前只有少數文獻[4-7]提出了能估計嵌入信息長度的隱寫分析算法,而且大多數是針對具體一個或者一類圖像隱寫術的專用隱寫分析算法[4-6]。
Bohme[4]在WS(Weighted Stego image)方法的基礎上,提出了擴展的WS法,對Jsteg隱寫的嵌入容量進行快速估計。陳嘉勇等[5]對一類偽隨機置換隱寫術建立有向圈模型,證明了有向圈模型中存在大量等價密鑰和相鄰密鑰,并給出計算等價密鑰量的方法。利用等價密鑰和相鄰密鑰的性質,結合突變點檢測法,提出一種針對隨機LSB隱寫術的基于選擇密鑰的提取攻擊算法,但是對消息嵌入率估計存在較大誤差。Jan Kodovsky等[6]基于圖像統計特征參數,采用最大似然估計(maximum likelihood estimator)和零值信息假設(Zero Message Hypothesis,ZMH)提出了針對Jsteg隱寫的定量隱寫分析算法。Pevny等[7]提出基于自檢測特征進行定量隱寫分析的思路,并且針對多種JPEG隱寫,采用平凡最小二乘(Ordinal Least Square,OLS)和支持向量回歸分析(Support Vector Regression,SVR)訓練出相應的定量隱寫分析器。
本文針對JPEG圖像的Jsteg和F5隱寫算法,在文獻[7]的基礎上,提出了一種基于DCT系數統計模型的定量隱寫分析算法。該方法對原始圖像和載密圖像的DCT系數進行統計分析,找到了能夠反映嵌入容量變化規律的特征參數α。在此基礎上,采用文獻[8]的方法,共提取了276個具有一定區分能力的特征參數組成特征向量,然后利用流形學習的方法進行降維處理,將處理后的數據作為LIB-SVM分類器的輸入,通過自學習的訓練過程得到定量隱寫分析的分類器,從而達到對現有的基于JPEG隱寫的定量分析方法進行改進的目的。
2 JPEG圖像的DCT系數統計模型
在隱寫分析領域,國內外已有很多學者對圖像DCT系數的統計分布模型進行了研究,提出了相關的統計分布模型算法(高斯模型[9]、廣義高斯模型(GGD)[10]、拉普拉斯模型(Laplacian)[11]、柯西模型(Cauchy)[12])。由文獻[12]可以知道,在以上傳統的概率模型中,柯西模型能夠更好地擬合DCT系數的直方圖分布。本文在SαS模型(Symmetric Alpha-Stable)[12]的基礎上,提出了一種改進的統計分布模型(Ameliorate alpha-Stable,AαS)算法。
對于SαS模型來說,當特征指數α越大,其分布統計模型就越尖銳;相反,當特征指數α越小,其分布模型就越平坦。因為SαS模型的概率分布函數是由其特征函數經傅里葉反變換(IDFT)得來,但是由于經IDFT后的結果為復數,計算不方便,同時IDFT與JPEG數據壓縮標準不兼容,應用受到很大限制。因此,本文直接利用其特征函數來擬合JPEG圖像的DCT系數分布,提出了AαS模型,即
fX(x)=|exp(jμt-δ2/2·|t|α)|·max(h(x))(0≤α≤3)(1)其中,h(x)表示DCT系數的直方圖分布,0≤h(x)<1。對于AαS模型來說,當特征指數α越大,其分布統計模型就越平坦;相反,當特征指數α越小,其分布模型就越尖銳。
為了評估兩曲線的相似程度,定義了兩曲線的相似度(Similarity Measurement)。設兩隨機變量X和Y的概率模型函數分別為fX(x)和fY(x),則其相似度為:

式(2)左式是連續型的概率模型相似度定義,右式是離散型的概率模型相似度定義。當相似度(SM)值越小,則兩種概率曲線就越接近。當SM=0時,則說明兩曲線完全重疊。利用式(2)對圖1的三種概率模型進行相似度計算,結果如表1。
從表1可以看出,AαS模型的相似度值最小,柯西模型的相似度值最大。因此對于圖1,其概率模型與AαS模型最匹配。

圖1 woman圖像

表1 woman圖像三種概率模型的相似度
圖2(a)是250幅圖像取最優AαS模型時對應的特征指數α,其值在0到3之間,平均值為0.595 4。而圖2(b)是250幅圖像取最優AαS模型時對應的相似度值,其值大部分介于0~0.5之間,平均值為0.385 9。結合表1可以看出,圖像DCT系數最理想的分布模型為AαS模型。而AαS模型的特征指數α能夠很好地反應DCT系數的分布特點,下面將它作為主要的特征參數用于分析實驗。
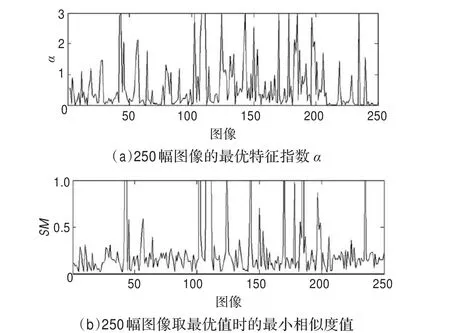
圖2 AαS模型的特征指數和相似度值
3 基于DCT系數統計特性的定量隱寫分析算法
載密圖像的有效特征隨信息嵌入率的變化而變化,從而可以根據圖像特征估算載密圖像的信息嵌入率。已有的大部分定量隱寫分析方法必須要知道隱寫算法的嵌入規則,這些定量隱寫分析算法不具有通用性。為了提高估計值的準確性,在文獻[7]的基礎上,本文提出了采用新的特征提取方法和應用流形學習的方法,得到新的基于DCT系數統計特性的JPEG圖像定量隱寫分析方法。該方法主要包括3個部分:載體圖像預測、統計特征提取、SVM訓練和檢測。下面逐一介紹。
3.1 載體圖像預測

圖3 載體圖像預測流程圖
通常情況下載體圖像的DCT系數直方圖是未知的,這給通用隱寫分析算法的設計帶來了極大的不便。Fridrich等人在文獻[13]中提出:將待測圖像解壓縮到空間域,然后剪裁掉最上邊的4行和最左邊的4列后,進行低通濾波,再按相同的量化表(量化表可以從待測圖像的文件頭中讀出)重新壓縮,可以構造出一幅統計特性與載體圖像相近的預測圖像,其中,預測圖像與待測圖像大小相同。具體流程如圖3所示。
3.2 統計特征提取
為了衡量待測圖像和預測圖像中某個特征統計量的差異大小,構建如下公式:

其中,f為圖像的某個特征統計量,J1表示待測的JPEG圖像,J2表示對該圖像的預測圖像。
首先采用文獻[8]中的方法從待測圖像和預測圖像中分別提取一階統計特征、二階統計特征和Markov特征等參數,并添加了由第2章中式(1)和式(2)得到的特征指數α和δ2。然后,采用式(3)分別計算從待測圖像和預測圖像中提取的特征參數間的差異,得到276維統計特征向量。
為了降低數據處理的復雜性并提高分類的準確率,需要對其進行維數約簡。流形學習是一種有效的非線性降維方法,它可以挖掘出隱藏在高維數據中的低維流形。局部線性嵌套(LLE)[14]能夠較好地發現高維數據中的局部幾何結構,并具有計算簡單的優點。因此,下面采用LLE方法對276維特征向量進行降維處理,具體步驟如下:
假設經過特征提取后得到的JPEG圖像的特征向量集合為:X={x1,x2,…,xN∈RD},其中,N代表圖像樣本數,xi代表第i個圖像的特征向量,D代表特征向量維數。
算法的第一步是計算出每個樣本點的k個近鄰點。把相對于所求樣本點距離最近的k個樣本點規定為所求樣本點的k個近鄰點。k是一個預先給定值。
LLE算法的第二步是計算出樣本點的局部重建權值矩陣。這里定義一個誤差函數,如下所示:
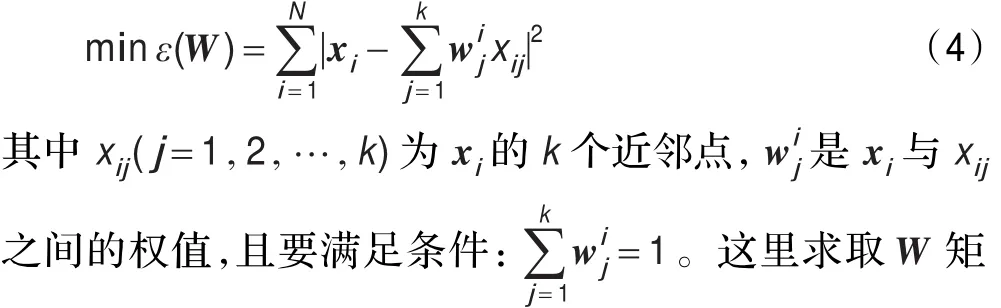

在實際運算中,Qi可能是一個奇異矩陣,此時必須正則化Qi,如下所示:

其中r是正則化參數,I是一個k×k的單位矩陣。
LLE算法的最后一步是將所有的樣本點映射到低維空間中。映射條件滿足如下所示:

其中,ε(Y)為損失函數值,yi是xi的輸出向量,yij(j= 1,2,…,N)是yi的k個近鄰點,且要滿足兩個條件,即


其中M是一個N×N的對稱矩陣,其表達式為:

要使損失函數值達到最小,則取Y為M的最小m個非零特征值所對應的特征向量。在處理過程中,將M的特征值從小到大排列,第一個特征值幾乎接近于零,那么舍去第一個特征值。通常取第2~m+1間的特征值所對應的特征向量作為輸出結果。
3.3 LIB-SVM分類器
支持向量機(Support Vector Machine,SVM)[15]是Cortes和Vapnik于1995年首先提出的,它在解決小樣本、非線性及高維模式識別中表現出許多特有的優勢,并能夠推廣應用到函數擬合等其他機器學習問題中,因此,被廣泛應用到很多領域中。它是建立在統計學習理論、VC維理論和結構風險最小原理的基礎上,其基本原理就是尋找最優分類面(Optimal Hyperplane),將空間中兩類樣本點盡可能多的正確分離,同時使得支持向量(即兩類樣本中離分類面最近的樣本點)距離分類面最遠。

表2 對Jsteg隱寫的嵌入率估計(%)
設訓練樣本集為(xi,yi),i=1,2,…,n,xi∈Rd,yi∈{+1,-1},d維空間中線性判別函數的一般形式為g(x)= w·x+b,分類面方程為w·x+b=0。為了使所求得的最優分類面能夠對所有樣本正確分類,且分類間隔最大,則對于樣本點(xi,yi)應滿足以下兩個條件:
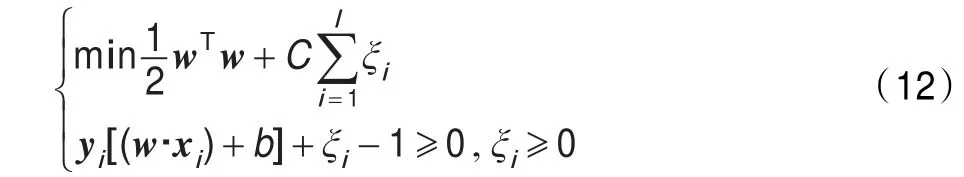
其中,C為懲罰因子;ξi為非負松弛變量。
這是一個二次凸規劃問題,由于目標函數和約束條件都是凸的,根據最優化理論,這一問題存在唯一全局最小解。應用Lagrange乘子法并滿足條件:

最后得到SVM的分類器具有以下形式:

其中,αi≥0是拉格朗日乘子,K(xi,x)表示核函數。目前,最常用的核函數有線性核、多項式核、RBF核和sigmoid核四種。在本實驗中,主要利用臺灣大學林智仁等人開發設計的LIB-SVM軟件包。
目前,常用的多分類支持向量機方法有“一對多”(One-Versus-Rest)和“一對一”(One-Versus-One)算法。針對本文中訓練樣本的數目要求較小,運算量不大的特點,以提高檢測的正確率為準則,采用“一對一”的算法設計了多類分類器,該分類器不僅可以檢測出待測圖像是否載密,而且能夠進一步判斷載密圖像中嵌入了多少秘密信息。
4 實驗與結果分析
首先構建實驗所用的載體圖像庫。收集了索尼、佳能等品牌的幾款不同型號的數碼相機拍攝的250張數碼照片,其格式均為質量因子90以上的真彩色JPEG圖片。利用MATLAB 7.10把它們統一處理成大小為512× 512、質量因子為75的灰度JPEG圖像。然后,從得到的250幅圖像中隨機選取150幅圖像構成訓練圖像庫,剩下的100幅構成測試圖像庫。
4.1 對Jsteg隱寫的定量分析實驗
采用Jsteg隱寫對載體圖像進行嵌入率為α=0.05,0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5的更改(嵌入率即為更改的系數在所有可嵌入系數中所占的比率),得到10組載密訓練圖像和10組載密測試圖像。然后分別采用文獻[7]和本文的方法提取相應的統計特征向量;將訓練圖像中提取出的所有特征向量作為分類器的輸入;設定LIB-SVM的參數,經過機器的自學習過程,訓練得到分類器。最后采用相應的分類器對兩種情況下的測試圖像進行嵌入率的估計。具體實現如下:
(1)將這10組圖像分別記作類別A~J,選取其中任意兩個不同的類別分別標記為“+1”和“-1”,經過訓練可以得到45個二分類器。
(2)提取待測圖像的特征向量,分別輸入到45個已訓練好的LIB-SVM分類器中進行檢測,根據檢測結果對A~J十個類別進行投票,獲得票數最高的類別即被判定為待測圖像的嵌入率。
表2給出了文獻[7]以及本文方法的檢測結果。
從表2可以看出:針對Jsteg隱寫,在不同嵌入率下,相比于文獻[7],本文提出的基于流形學習的特征提取算法,能夠獲得較高的正確檢測率。
4.2 對F5隱寫的定量分析實驗
采用F5隱寫對載體圖像進行嵌入率為α=0,0.05,0.1,0.15,0.2,0.25的更改(嵌入率即為更改的系數在所有可嵌入系數中所占的比率),得到6組載密訓練圖像和6組載密測試圖像。然后分別采用文獻[7]和本文的方法提取相應的統計特征向量;將訓練圖像中提取出的所有特征向量作為分類器的輸入;設定LIB-SVM的參數,經過機器的自學習過程,訓練得到分類器。最后采用相應的分類器對兩種情況下的測試圖像進行嵌入率的估計。具體實現如下:
(1)將這6組圖像分別記作類別A~F,選取其中任意兩個不同的類別分別標記為“+1”和“-1”,經過訓練可以得到15個二分類器。
(2)提取待測圖像的特征向量,分別輸入到15個已訓練好的LIB-SVM分類器中進行檢測,根據檢測結果對A~F六個類別進行投票,獲得票數最高的類別即被判定為待測圖像的嵌入率。
表3給出了文獻[7]以及本文方法的檢測結果。

表3 對F5隱寫的嵌入率估計(%)
從表3可以看出:針對F5隱寫,在不同嵌入率下,相比于文獻[7],本文提出的基于流形學習的特征提取算法,同樣能夠獲得較高的正確檢測率。
分析表2和表3的實驗結果,可以驗證在JPEG圖像的DCT域中存在一個相應的低維流形,而流形學習方法有從高維數據中找到這個低維流形的能力,從而找到最重要的區分信息。而將未經處理的高維數據直接用于分類和訓練,并不能達到很好的分類效果。
需要說明的是:在使用LLE進行降維處理時,當引入新的測試樣本時,需要重新構造和求解最小重構權值矩陣,然后通過該矩陣計算相應的特征向量來求其低維嵌入結果。這樣做要耗費巨大的計算代價,對圖像目標的實時性有一定的影響,這就是流形學習的樣本外點學習問題。在實際目標的識別實驗中還發現基于流形學習算法的特征提取識別時間要比原始方法的長一些,而這也正是下一步研究需要解決的重點問題。
5 結束語
本文提出了一種基于DCT系數統計特性的JPEG圖像定量隱寫分析算法。該算法在分析JPEG圖像DCT系數統計模型的基礎上,采用了基于流形學習的特征提取方法,得到目標數據的低維流形,將其作為特征參數并利用支持向量機進行分類識別。在對Jsteg和F5的定量分析實驗結果表明,該算法的魯棒性和準確性都有了較大提高,在實際中具有重要的應用價值。但該算法仍然存在一些不足:特征提取識別的時間較長,運算速度較慢。如何解決上述所提出的問題,研究更有效的定量分析算法,將是下一步工作研究的重點和難點。
[1]夏煜,郎榮玲.基于圖像的信息隱藏檢測算法和實現技術研究綜述[J].計算機研究與發展,2004(4).
[2]張衛明,李世取,劉九芬.對空域圖像LSB隱寫術的提取攻擊[J].計算機學報,2007,130(9):1625-1631.
[3]Fridrich J,Goljan M,Hogea D,et al.Quantitative steganalysis of digital images:estimating the secret message length[J].ACM Multimedia Systems Journal:Special Issue on Multimedia Security,2003,9(3):288-302.
[4]Bohme R.Weighted stego-image steganalysis for JPEG covers[C]//Proc of the 10th Int Workshop on Information Hiding.Berlin:Springer,2008:178-194.
[5]陳嘉勇,祝躍飛,張衛明,等.對隨機LSB隱寫術的選擇密鑰提取攻擊[J].通信學報,2010,31(8):73-80.
[6]Kodovsky J,Fridrich J.Quantitative structural steganalysis of Jsteg[J].IEEE Transactions on Information Forensics and Security,2010,5(4):681-693.
[7]Pevny T,Fridrich J,Ker A D.From blind to quantitative steganalysis[C]//Proc of Electronic Imaging,Security and Forensics of Multimedia Contents XI.Bellingham,WA:SPIE,2009.
[8]Pevny T,Fridrich J.Merging Markov and DCT features for multi-class JPEG steganalysis[C]//Proc of Electronic Imaging,Security,Steganography,and Watermarking of Multimedia Contents IX.Bellingham,WA:SPIE,2007:1-13.
[9]Fridrich J.Feature-based steganalysis for JPEG images and its implications for future design of steganographic schemes[C]//Proc of the 6th Information Hiding Workshop.Berlin Heidelberg:Springer-Verlag,2004:67-81.
[10]Zhang Li,Qian Gongbin.Multi-bit optimum image blind watermark detector based on dual channel detection[J]. Journal of Electronics&Information Technology,2007,29(7):1717-1721.
[11]Lie Wen-Nung,Lin Guo-Shiang.A feature based classification technique for blind image steganalysis[J].IEEE Transactions on Multimedia,2005,7(6).
[12]毛家發,鈕心忻.基于JPEG凈圖定量描述的隱寫分析方法[J].電子學報,2011,39(8):1907-1912.
[13]Fridrich J,Goljan M,Hogea D.Steganalysis of JPEG images:breaking the F5 algorithm[C]//Lecture Notes in Computer Science 2578.Berlin:Springer-Verlag,2002:310-323.
[14]Roweis S T,Saul L K.Nonlinear dimensionality reduction by locally linear embedding[J].Science,2000,290(5500):2324-2326.
[15]Pevny T,Fridrich J.Towards multi-class blind steganalyzer for JPEG images[C]//Proceedings of International Workshop on Digital Watermarking.[S.l.]:Springer-Verlag,2005:39-53.
ZHANG Mingchao,CAI Xiaoxia,CHEN Hong
Electronic Engineering Institute,Hefei 230037,China
A quantitative steganalysis algorithm of JPEG images based on DCT coefficient statistical characteristics is proposed.Based on the research of DCT coefficient statistical model of JPEG images,the characteristic parameterα,which can reflect the embedding capacity change rule,is extracted in the proposed method.With the LIB-SVM classifier,a kind of manifold learning algorithm is applied to feature extraction from the characteristic parameters includingα.By this means,the change ratio of DCT coefficients caused by steganography can be estimated.The results show that compared with other traditional quantitative analysis,the algorithm gains higher estimation accuracy and stability.
quantitative steganalysis;feature extraction;manifold learning;JPEG
A
TP391
10.3778/j.issn.1002-8331.1211-0325
ZHANG Mingchao,CAI Xiaoxia,CHEN Hong.Quantitative JPEG images steganalysis algorithm based on manifold learning.Computer Engineering and Applications,2014,50(21):175-179.
張明超(1987—),男,碩士在讀,主要研究方向為信息安全。E-mail:1139708343@qq.com
2012-11-27
2013-01-11
1002-8331(2014)21-0175-05
CNKI出版日期:2013-01-29,http://www.cnki.net/kcms/detail/11.2127.TP.20130129.1543.017.html
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年18期)2018-11-14 01:48:24
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
