EM算法的改進及其在行為識別中的應用
2014-09-18 07:12:50趙桂儒李衛東劉典婷崔滿豐
電視技術 2014年13期
趙桂儒,李衛東,劉典婷,吳 敏,崔滿豐
(1.中國地震臺網中心,北京 100045;2.邁阿密大學,美國 佛羅里達州 33146)
高斯混合模型(Gaussian Mixture Model,GMM)作為一種通用的概率模型,能有效地模擬多維矢量的任意連續概率分布,在此基礎上發展起來的高斯混合模型通用背景模型(GMM-UBM)在語音識別[1]、圖像識別和檢索[2-4]等領域都取得了良好的效果。
GMM-UBM需要大量的訓練樣本數據通過GMM模擬所有樣本數據的空間分布狀態作為通用背景模型,因此GMM參數的估算顯得尤為重要。期望最大化(Expectation Maximization,EM)算法是傳統的估計GMM參數的方法,樣本數據規模增大時,EM算法存在迭代次數多、運行時間過長等問題,這影響了GMM參數估算的速度。在不影響參數估算準確程度的基礎上加快EM算法的運行速度將具有非常重要的現實意義。
本文針對EM算法運行時間過長的問題,提出了一種改進的EM算法,文章結合KTH人體行為數據庫,對改進的EM算法從運行速度和行為識別準確率兩方面進行了驗證,結果顯示改進后的EM算法能夠顯著提高GMM參數求解的速度,而對行為識別準確率的影響非常小。
1 GMM-UBM及其參數求解
1.1 GMM-UBM
GMM-UBM用來描述所有樣本數據的分布狀態,其概率密度函數描述為
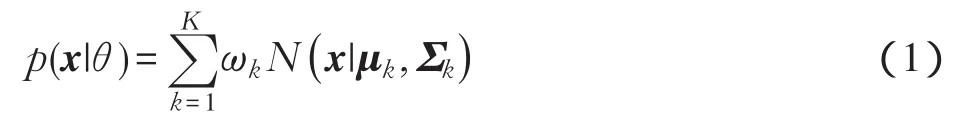
式中:x是D維特征向量;K代表高斯成分的數量;θ={ωk,μk,Σk}Kk=1是一組參數,包括每個高斯成分的權值ωk、均值向量μk和協方差矩陣Σk。
1.2 GMM參數求解
GMM的參數估計一般采用EM算法[5],GMM的對數似然函數(log-likelihood function)為
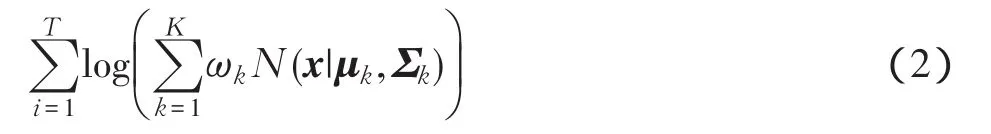
式中:T為樣本總數,適合當前樣本集的GMM參數將會使式(2)最大化。EM算法可分為E步和M步:
1)E步
根據當前GMM的參數計算每行樣本數據屬于第k類分布的后驗概率為
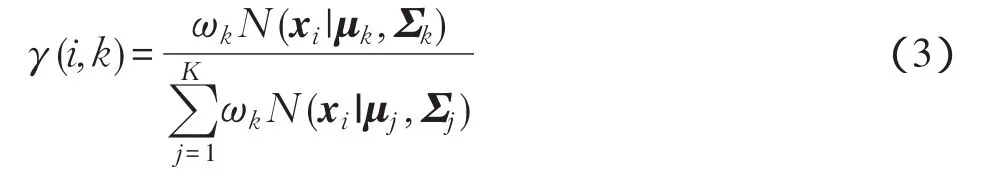
式中:γ(i,k)代表第i行樣本數據屬于第k類分布的后驗概率。
2)M步
利用E步得出的概率值,重新估計每類分布的參數值
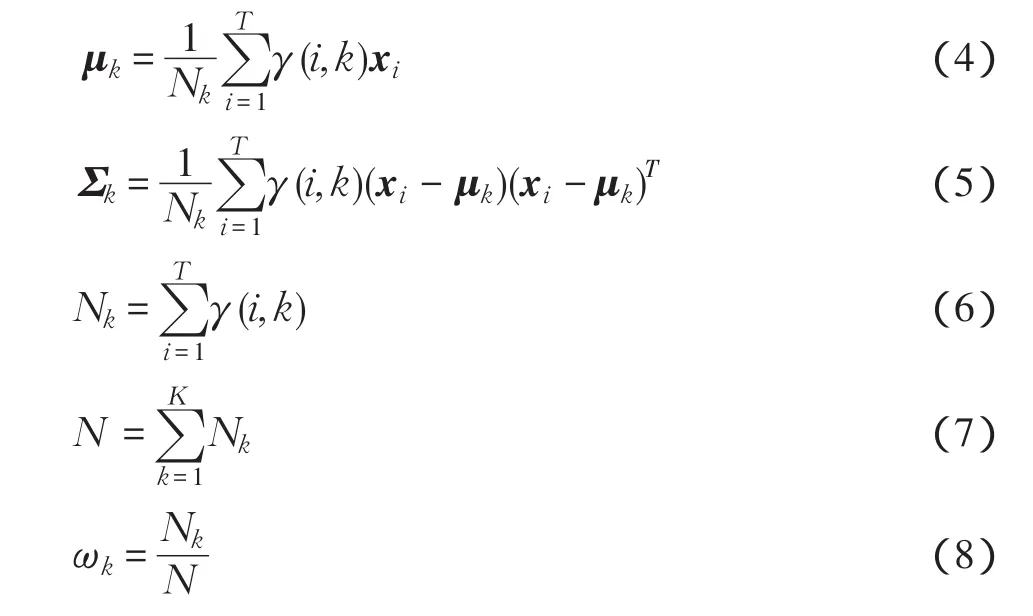
式中:N為重復1)和2)兩步直到式(2)收斂于一個充分小的值為止。
1.3 EM算法存在的問題及改進
在實際應用中,當樣本數據規模較大、GMM的高斯成分數K比較高時,EM算法往往需要運行很長時間并經過多次迭代才能收斂,這成為EM算法估算GMM參數的一個瓶頸。通過1.2節中對E步和M步的分析可以發現,M步中重新估計每類高斯分布的參數值(ωk,μk,Σk)時,需要利用每行樣本數據xi及其屬于第k類高斯分布的后驗概率值γ(i,k)來進行計算。后驗概率值γ(i,k)越大意味著xi對高斯分布參數估計的影響越大,反之亦然。舍棄那些后低驗概率值對應的數據,加快M步的運算速度,從而節省估算GMM參數的時間是本文改進EM算法的指導思想。
一行樣本數據xi屬于所有高斯分布的后驗概率γ(i,k)的總和為1,因此理論上γ(i,k)的取值只有兩種情況:大于等于平均概率值1/K或者小于該值,如果γ(i,k)遠小于(例如0.1%倍)平均概率值則意味著xi對估計第k類高斯分布參數值的影響更小,同時也意味著必有其他樣本數據xi在估計第k類高斯分布參數值時起到的作用更大。
鑒于此,本文提出了一種加快EM算法迭代速度的方法,基本思想為:在EM算法的M步中,只挑選部分特征數據來重新估計每類分布的參數值。挑選的原則為設置一個閾值CTH/K,當在E步中計算出的后驗概率γ(i,k)大于等于該閾值時,即選擇樣本數據xi,否則直接舍棄。
修改后的M步如下:
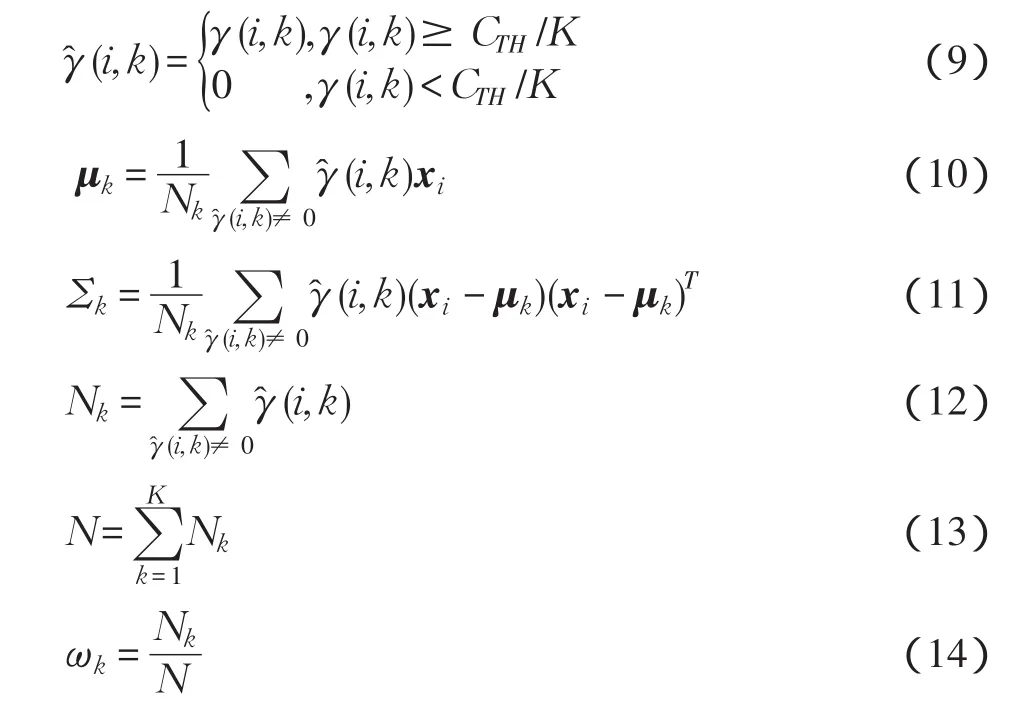
為了保證GMM參數求解的準確程度,CTH應當越小越好,為了提高EM算法的運行速度,CTH應當越大越好,這是一個矛盾,但總體上CTH的取值應當在0~1之間取舍。本文第3部分對CTH的設置進行了實際驗證和分析。
2 實驗平臺的設計
通過對E步和M步的分析可知,當樣本數據規模增大(行數增多、維數變大)、GMM的高斯成分數K增多時EM算法的運行時間將呈現非線性增長,在小規模的數據集上驗證改進的EM算法將沒有實際意義,但在大規模數據上驗證EM算法時又不能直觀地比較GMM參數估算值的差異,因此本文對改進后EM算法的驗證分成兩部分:第一部分在較大規模數據集上比較改進前后EM算法的運行速度,第二部分在實際應用中比較改進前后的EM算法對結果的影響。
2.1 數據準備及運行環境
為了讓算法的比較具有實際意義,文章選擇KTH人體行為數據庫作為實驗對象,KTH數據庫由瑞典皇家理工學院的Schldt[6]等在人體行為識別的研究中提出,該數據庫包括6個常見的行為類別:拳擊(boxing)、擊掌(hand clapping)、揮手(hand waving)、慢跑(jogging)、行走(walking)和跑步(running)。每個行為由25個不同的人在不同的場景中完成。4個場景包括室外、室外尺度變化、室外穿著變化和室內。該數據庫一共包含599段視頻序列,每段視頻以25 f/s(幀/秒)的速度持續10~15 s。
對KTH視頻數據提取STIP[7](Space-Time Interest Point)和SIFT[8](Scale-Invariant Feature Transform)特征,應用PCA降維方法將STIP特征從162維降為32維,SIFT特征從128維降為32維,高斯混合模型中的高斯成分數量設為256[3]。
算法實驗環境為美國邁阿密大學的超算平臺(IBM Platform LSF),GMM程序采用Bouman C A教授公開的3.6.6版本[9],文中將該程序中的GMM參數初始化修改為通過Kmeans聚類獲取。
2.2 實驗設計流程
從單個視頻提取的特征(STIP或SIFT)往往不足以精確地估算GMM的參數[10],因此從所有的訓練視頻樣本中提取特征,估算GMM參數,從而得出一個UBM。為了更好地描述特定視頻特征數據的分布狀態,用最大后驗概率(MAP)[11]方法來調整UBM參數(通常只調整均值向量μ)。以UBM中的第k個高斯成分為例,針對特定視頻的特征數據,首先計算γ(t,k),然后計算如下參數
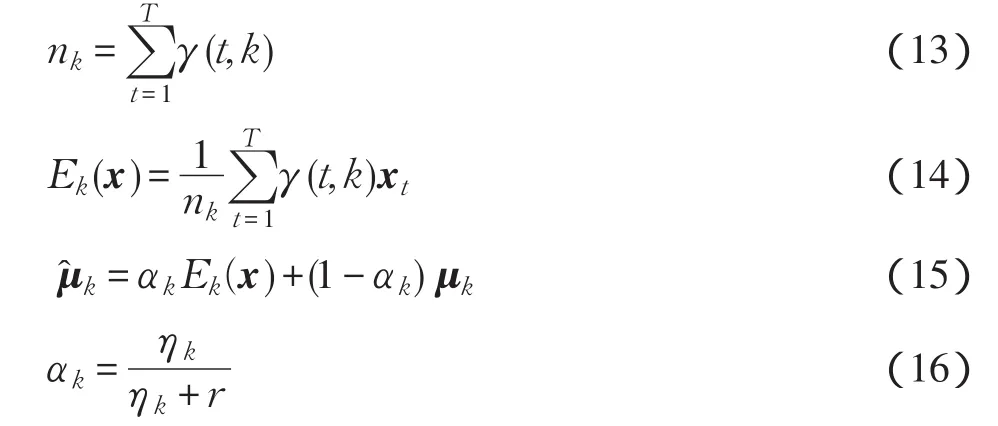
式中:xt代表某個視頻的第t行特征值;r是一個調節參數,通常設置值在8~20之間[12];Ek(x)代表所有樣本數據針對第k類高斯分布的加權平均;為調整后的第k類高斯分布的均值向量。
將調整后的所有高斯成分的均值歸一化后,連接起來就形成了GMM超向量,歸一化公式為

算法驗證的第一部分比較改進前后的EM算法估算GMM-UBM參數的運算速度。第二部分將在GMM-UBM的基礎上構建GMM超向量,結合SVM進行多值分類,對KTH進行留一交叉驗證法(LOOCV)驗證。實驗設計的流程圖如圖1所示。
3 算法驗證
3.1 GMM參數估算速度的比較
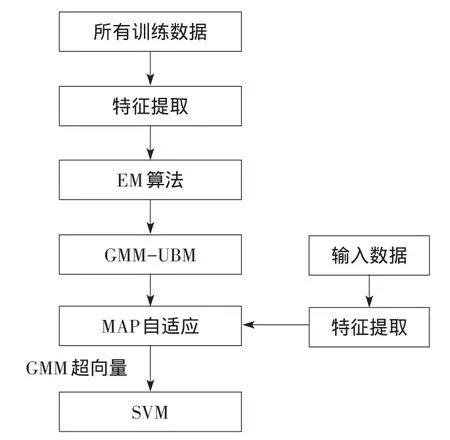
圖1 實驗設計流程圖
選擇STIP特征數據對KTH進行留一交叉驗證,每次用24人的視頻數據訓練GMM-UBM,共需25輪,經過降維、采樣等處理后,每輪STIP特征數據平均133 Mbyte左右。為了兼顧運行速度和參數估算準確程度,CTH取值選擇了5個參數值(0,0.001,0.01,0.1,0.5)進行比較。實驗結果如圖2所示。參數CTH值為0代表原EM算法。從實驗的幾組閾值可以看出當CTH設為0.001時相比原EM算法運行速度提高了很多(92.3%),而當CTH增加時運行速度的提高變得相對緩慢。通過查看EM算法迭代過程輸出的中間值γ(i,k)可以發現幾乎每行樣本對應的256個概率值大部分γ(i,k)都小于0.001/256,只有少數幾個比較大。隨著閾值的增大,運行速度的提高并不明顯,這說明CTH取0.001時已經舍棄了絕大多數樣本數據,只有少數樣本數據對應的γ(i,k)需要更大的閾值進行舍棄。

圖2 不同閾值參數運行時間比較
綜上分析可以得出用GMM擬合樣本數據分布時,大部分樣本數據具有明顯的傾向性,即屬于某個或某幾個高斯成分的概率大,屬于其他高斯成分的概率則很低,舍棄影響特別低的樣本數據有助于加快EM算法的運行速度。這進一步驗證了本文提出改進EM算法的指導思想。
3.2 在KTH上的應用比較
在STIP特征數據訓練出GMM-UBM的基礎上構建GMM超向量,結合LIBSVM[13]進行多值分類,SVM采用徑向基核函數(RBF)。采用不同閾值得出的識別準確率如表1所示。
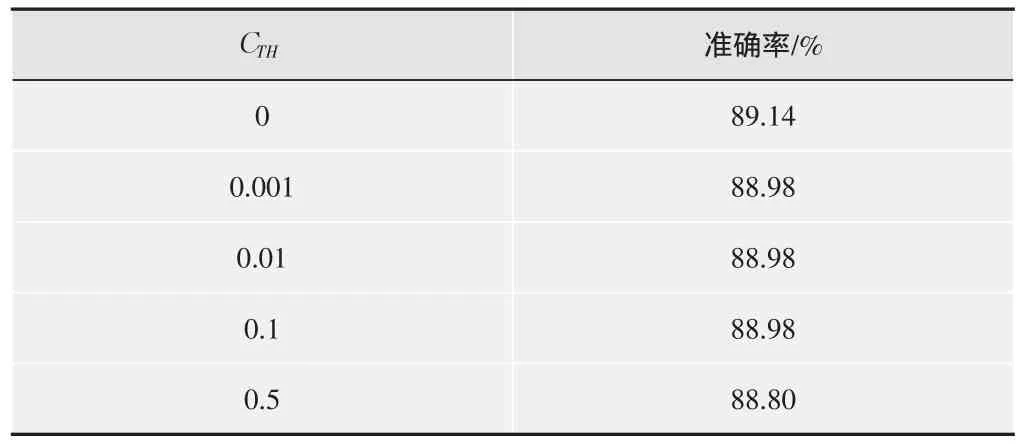
表1 不同閾值應用比較
由表1可以看出不同的閾值在實際應用中對識別準確率的影響不大,這說明改進后的EM算法幾乎沒有影響原EM算法求解GMM參數的準確度。
本文采用改進后的EM算法,將CTH設為0.001,分別基于STIP特征和SIFT特征進行行為識別,基于STIP特征的識別準確率為88.98%,基于SIFT特征的識別準確率為82.48%,合并兩種特征得出的相似度(SVM score)后得出的識別準確率為91.33%,其對應的混淆矩陣如圖3所示。
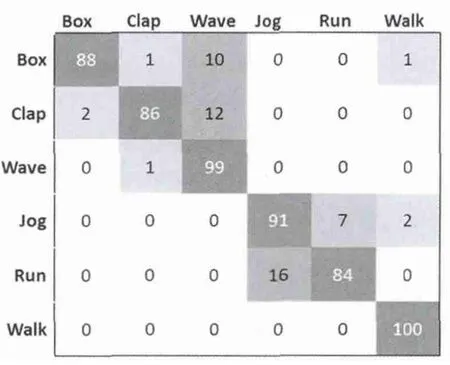
圖3 KTH數據庫混淆矩陣,平均準確率91.33%
4 結語
通過分析EM算法運行時間過長的原因,本文提出了一種改進的EM算法,改進后的EM算法通過設置一個閾值來挑選部分特征數據重新估計每類分布的參數值,實驗證明當數據規模較大、高斯成分數很高時,通過設置適當的參數,改進后的EM算法相比原有的EM算法在估算GMM參數時能夠顯著地提高運行速度,而在KTH人體行為庫的實際應用中,行為識別準確率只受到了很小的影響。
本文是通過降維和采樣的方法來縮小數據規模進行實驗,改進的EM算法還可以嘗試結合Hadoop應用到大數據處理上,來加快大數據求解GMM參數的時間。
:
[1]CAMPBELL W M,STURIM D E,REYNOLDS D A.Support vector machines using GMM supervectors for speaker verification[J].IEEE Signal Processing Letters,2006,13(5):308-311.
[2]INOUE N,SHINODA K.A fast MAP adaptation technique for GMM-supervector-based video semantic indexing systems[C]//Proc.19th ACM International Conference on Multimedia.[S.l.]:ACM Press,2011:1357-1360.
[3]LIU D,SHYU M L,ZHAO G.Spatial-temporal motion information integration for action detection and recognition in non-static background[C]//Proc.2013 IEEE 14th International Conference on Information Reuse and Integration(IRI).[S.l.]:IEEE Press,2013:626-633.
[4]陳曉,張尤賽,鄒維辰.一種基于GMM的圖像語義標注方法[J].電視技術,2013,36(23):35-38.
[5]鐘金琴,辜麗川,檀結慶,等.基于分裂EM算法的GMM參數估計[J].計算機工程與應用,2012,48(34):28-32.
[6]SCHULDT C,LAPTEV I,CAPUTO B.Recognizing human actions:a local SVM approach[C]//Proc.7th International Conference on Pattern Recognition.[S.l.]:IEEE Press,2004:32-36.
[7]LAPTEV I.On space-time interest points[J].International Journal of Computer Vision,2005,64(2/3):107-123.
[8]LOWE D G.Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[9]BOUMAN C A,SHAPIRO M,COOK G W,et al.Cluster:an unsupervised algorithm for modeling Gaussian mixtures[EB/OL].[2014-01-10].http://dynamo.ecn.purdue.edu/~bouman/software/cluster.
[10]INOUE N,SAITO T,SHINODA K,et al.High-level feature extraction using sift GMMs and audio models[C]//Proc.2010 20th International Conference on Pattern Recognition(ICPR).[S.l.]:IEEE Press,2010:3220-3223.
[11]REYNOLDS D.Gaussian mixture models[J].Encyclopedia of Biometrics,2009(10):659-663.
[12]CHARBUILLET C,TARDIEU D,PEETERS G.GMM-supervector for content based music similarity[C]//Proc.International Conference on Digital Audio Effects.Paris,France:IEEE Press,2011:425-428.
[13]CHANG C C,LIN C J.LIBSVM:a library for support vector machines[J].ACM Trans.Intelligent Systems and Technology(TIST),2011,2(3):27.
猜你喜歡
數學小靈通(1-2年級)(2024年4期)2024-05-14 09:30:52
健康之家(2021年19期)2021-05-23 11:17:39
醫學食療與健康(2021年27期)2021-05-13 18:46:23
數字通信世界(2021年3期)2021-04-09 02:05:00
農業科技與信息(2021年2期)2021-03-27 07:27:38
湖北理工學院學報(2020年4期)2020-08-22 06:43:26
小學生學習指導(低年級)(2019年6期)2019-07-22 03:33:10
中國交通信息化(2018年5期)2018-08-21 03:37:40
計算機應用與軟件(2017年4期)2017-04-24 10:39:07
四川師范大學學報(自然科學版)(2015年2期)2015-02-28 14:07:36
