基于相似度模型的可融合興趣點分類研究
2014-10-16 07:22:22李瑞姍高新院
中國海洋大學學報(自然科學版) 2014年9期
張 巍,李瑞姍,高新院
(中國海洋大學信息科學與工程學院,山東 青島266100)
POI(Point of Interest)即興趣點,泛指一切可以抽象為點的地理對象,尤其是與人們生活緊密相關的地理實體,如政府部門、景點、學校、醫院、銀行、商業區、標志性建筑等。每個POI包含這個實體4個方面的信息:名稱、地址、類型、經緯度,同時還可能有電話、評價等信息[1]。最近幾年,由于基于位置的服務快速發展,尤其是對網絡電子地圖、移動位置服務(LBS)、便攜式自動導航(PND)的使用,使得原有的POI很難繼續支撐這類服務。能否獲取高質量的POI信息,成為提高此類服務質量的關鍵所在。
然而多數基于位置服務的提供商并沒有自己完整、有效的數據采集和維護機制,他們的數據仍然是由專門的數據提供商供給。大多數POI信息數據生產廠家的數據采集方式主要依靠人海戰術,雇用大量的調繪、調查人員,對城市進行地毯式作業[2]。這樣的作業方式效率低,成本高,并且無法及時更新,因此部分廠家根據自己的經驗,創造性地將數據采集工作轉移到了室內。文獻[2]運用基于GPS技術與實景影像相結合開發建立POI快速采集系統平臺,可實現POI的快速采集和更新;專業POI生產廠商卡貝斯對互聯網數據做了實時監測,分類抓取互聯網上同POI相關的信息。大多遠程采集機制可以充分把握住新出現的POI信息,但忽略了那些原有POI信息變化,使得數據的準確度降低。以餐飲業為例,餐館的節假日活動可能會頻繁的變化,按照卡貝斯的機制這部分信息就不能在POI中被更新,甚至當餐館因為遷址導致地址這一關鍵字段發生的變化時,POI也不會被更新,造成這個POI價值驟減。還有些餐館因經營不善而關門倒閉,但是它的POI信息仍然出現在數據庫里,成為無用的“死點”,久而久之便會出現大量的冗余。
本文使用機器學習領域中的分類方法[3-4]初步解決了以上POI數據冗余、精確度低的問題。在互聯網上抽取數據,篩選出POI中字段的信息,根據這些信息與原有POI的關系進行分類處理。
本文通過分析POI中各特征字段的形式、特點,提出了POI特征相似度[5]用以表示一個POI與原有POI集的關系,利用這種形式化的關系在機器學習方法中分類,最終區分出可融合與不可融合的POI。相似度的形式化表示主要由名稱、地理信息相似度兩部分組成,其中的地理信息包括POI中的地址和經緯度。名稱部分是指2個不同POI名稱字段間的相似度,通過幾種經典字符串匹配方法[6]計算得出,過程中考慮到因為詞語的存在使得不同漢字具有不同的關聯性,本文假設中文字符串匹配的最小單位是詞,打破了傳統中最小單位是單個漢字的假設。美國是地理編碼[7]應用最早、最廣泛的國家,早在1970年代就建立了全國的地理編碼標準,根據經緯度便可確定出一個唯一的英文地址,其地址匹配可達到較好的效果,因此很容易就可以得到地理位置信息相似程度的準確的結果。但是我國尚且沒有成熟的地理編碼,既不完整也不精確,利用經緯度并不能確定2個地址匹配、相似與否。對于地理位置信息的相似程度,國內主要根據地址信息計算[8],過程中對地址中各特征字段進行匹配,綜合各字段的情況得出地址相似度。本文在考慮地址相似度的同時,還結合了根據地理空間信息得出的不同POI之間的距離,彌補了同一POI具有多種中文地址描述所導致的問題。
1 字符串匹配方法
POI中名稱字段大多比較精短、無明顯規則,同時也缺乏語義上的特征,是一類普通的中文字符串。目前這種中文字符串相似度[9]的計算在中文信息檢索、中文文本校對等領域中已有廣泛的應用。衡量2個字符串的相似度,常用的方法有3種,即萊文史特距離算法、Jaccard相似方法和Jaro距離算法。
根據已有資料的分析,現有的這些計算字符串相似度的算法大多基于一個假設:中文字符串匹配的最小單位是單個漢字,這樣并沒有考慮到漢字中詞語對相似度的影響,所以將匹配的最小單位假設為詞。
1.1 萊文史特距離算法
萊文史特距離算法(Levenstein edit distance algorithm)是一種字符串編輯距離算法,指一個字符串通過多少次操作(增、刪、改)得到另外一個字符串。例如,字符串S1為“aaabc”,S2為“aabb”,S1通過‘a’變為‘b’,刪除‘c’兩步可以得到S2,所以編輯距離等于2。在這里,定義字符串相似度為:
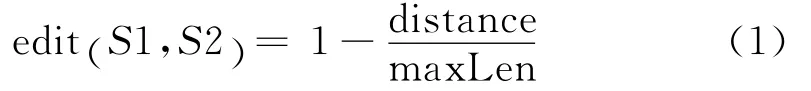
其中:distance是S1、S2的編輯距離,maxLen是S1、S2字符串長度中較大的那個值。edit值越大說明相似度越大,0表示沒有任何相似度,1則代表完全匹配。
1.2 Jaccard相似方法
這個相似度等于兩個字符串中相同詞(無重復)的個數與所有詞(無重復)個數的比值。也就是說,2個字符串S1、S2的Jaccard相似度可定義為:
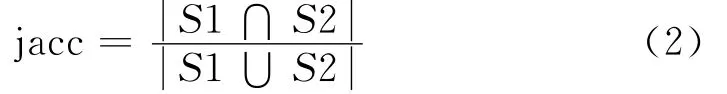
和edit一樣,jacc越大說明相似度越大。
1.3 Jaro距離
與上邊2種算法相比,Jaro distance算法的優點在于其考慮到字符不同位置的問題,如“粥全粥到臺東三路店”和“粥全粥到三店”,其中的“三”根據位置的不同可判斷為不匹配。首先定義一匹配窗口:
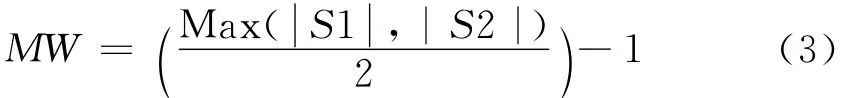
其中:S1、S2是待匹配字符串。S1、S2匹配過程中,若兩者中同有字符x,并且這2個x的距離不大于MW ,此時可以認為這2個x是匹配字符。
Jaro相似度定義如下:
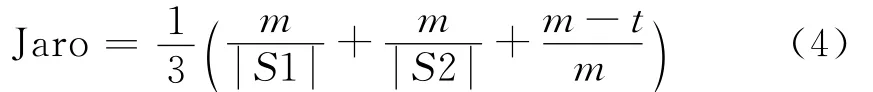
其中:S1、S2是待匹配的2個字符串;m是匹配的字符數;t是換位的數目,其值等于不同順序的匹配字符數目的一半。比如:2個字符串“ABCDE”和“EBCDA”做匹配操作,字符串中僅有B、C、D3個字符是匹配的,即m=3。雖然A、E都出現在2個字符串中,但是通過公式得出匹配窗口MW 為。而2個字符串中A、E字符的距離均大于1.5,所以不算作匹配。在另一組字符串AxByCDz與AzBDC。匹配的字符為A~B~C~D,但在2個字符串中C~D 2個字符順序不同,因此t=1,m=4。
2 地理信息的相似度
地理信息主要包括2部分,即空間地理信息和非空間地理信息。POI中的經緯度就是一種典型的空間地理信息,而POI中的中文地址則屬于地理信息系統中的非空間信息。我國地理信息的相似度主要是根據中文地址的匹配程度得出,但是對于那些具有多種描述情況的地理實體,比如有別名的實體、處于2條路交叉口的實體,這種地址匹配方法就不能得出其真實的相似程度。為解決這個問題,本文借助空間地理信息對這個相似度進行了補充。
2.1 中文地址的相似度
地址是各類服務系統中運用自然語言描述空間位置的最常用手段。中文地址是一種具有一定格式的中文字符串,但又不是標準統一格式,對于其相似度的計算,單靠本文提到的中文字符串匹配方法并不能達到很好的效果。目前我國主流的地址匹配方法就是對地址分詞,利用各個地址要素進行匹配。本文基于小詞典和特證詞對中文地址進行分詞,成功分開了中文地址中的各個要素,然后根據設置好的規則,綜合所有要素給出其相似程度。
分詞過程中用到的小詞典是根據行政區劃表構造出來的,主要目的是規范地址中省、地、縣、鄉級行政區名稱,如“嶗山區松嶺路238號”,分詞結果為“山東(省)青島(市)嶗山(區)松嶺(路)238(號)”,不僅劃分出字符串中各個部分,其省略部分也會補充完整。地址字符串中除省、地、縣、鄉級行政區以外的其它部分,因為信量太大,嚴重影響分詞速度,況且現在沒有合適完整資料來源,所以只對其進行特征字分詞。得到最終分詞結果格式為“X(省)X(地)X(縣)X(鄉)X(路)X(號)X(建筑)X(號碼)X(其它)”,括號內是其對應地址要素的特征詞。
對待匹配的2個中文地址,分詞處理后對其進行相似度計算,因為分詞過程中對鄉級及以上行政區字段進行了規范和補充,所以該4級字段中低級字段若相等,較高級字段也一定匹配。對于其它5個字段,先分別計算出相似度,再根據不同權值合算出總的相似度。如果2個中文地址中對應字段不同時存在,就無法進行相似度計算,對于這種情況把相似度計為-1,表示不考慮該字段。若SIM1、SIM2、SIM 分別表示中地址前4個字段、后5個字段以及整體的相似度,計算的具體流程如下:
Step1 初始化SIM1、SIM2、SIM 都為-1。
Step2 若鄉級字段匹配,對SIM1賦值為1,轉向Step3;若不匹配,則匹配縣級字段,縣級若相等SIM1為0.8,轉向Step3;以同樣方法處理地級、省級字段,SIM1分別為0.4、0.3;省級字段也不匹配,SIM1仍為-1。
Step3 若路級字段對應可比,且2個字段字符串相似度t大于0.8,則將路級、號級字符串的相似度記為s1,t小于0.8時s1等于t的一半;路級字段不可比時,s1等于-1。
Step4 和路級、號級字段一樣,計算出建筑級、號碼級字段相似度記為s2。
Step5 根據2.2.1中提到的一般字符串相似度算法,計算其它字段的相似度記為s3。
Step6 設置決定SIM2各字段的權值,s1、s2、s3分別對應a1、a2、a3,其值分別為4、3、3;若s1、s2、s3值為-1,表示對應字段不可比,則使這個權值為0。后5個字段的相似度為:
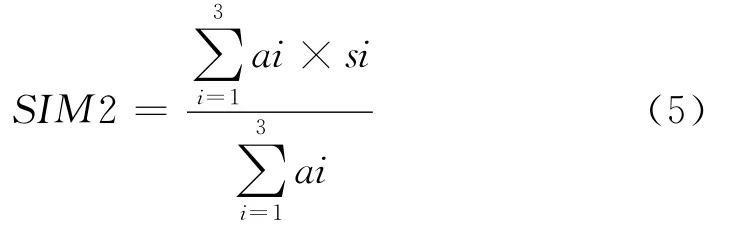
其中:s1、s2、s3都等于-1時,SIM2為-1;
Step7 設置SIM1、SIM2字段的權值b1、b2分別為1、3;若SIM1、SIM2值為-1,則使其對應的權值置0。待匹配2個中文地址的相似度為:
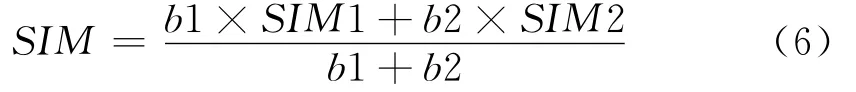
如果SIM1、SIM2值都為-1,SIM 的值定為0。
2.2 空間地理信息相似度
經緯度被定義在三度空間的球面上,用來標示地球上的任何一個位置,是一種典型的空間地理信息。POI中的經緯度作用和地址字段相同,都是用來描述一個位置,只是形式不同。通過經緯度來衡量2個POI是否匹配相似,最簡單有效的方法就是計算這2點之間的球面距離。該地理坐標相似度[10]定義為:
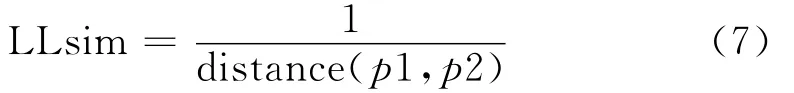
其中:distance(p1,p2)是匹配的2個POI點p1、p2的球面距離。當LLsim這個相似度大于閥值時,就認為這2個POI相似匹配。
3 POI相似度及機器學習分類模型
3.1 POI相似度
在互聯網上抓取感興趣的網頁,篩選出其中與POI相關的字段信息,之后對其進行分類處理,本文將POI分為可融合和不可融合兩類。分類的依據則是這個POI信息與數據庫中現有POI集的關系這個現有POI集并不是數據庫中所有的數據,這個集合是通過在互聯網上抽取的POI的名稱字段在數據庫中模糊搜索的結果。
為了方便構建模型,本文將之前提到的待分類POI與現有POI集的關系轉換成為1個向量,該向量中包括這個待分類POI和現有POI集中的各特征字段相似度的最大值,即
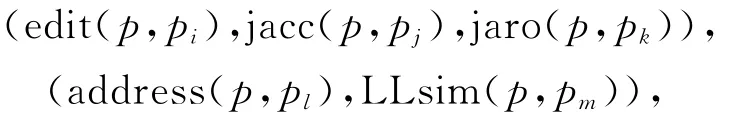
其中:p是待分類POI;px是現有POI集合中的某個可以不同,但必須使得其所在的函數值在組內最大分 別表示公式(1)、(2)、(4)提到的2個POI名稱字段 Levenstein相似度、Jaccard相似度、Jaro相似度,表示的2個POI的非空間地理信息相似度表示的2個POI的空間地理信息相似度。
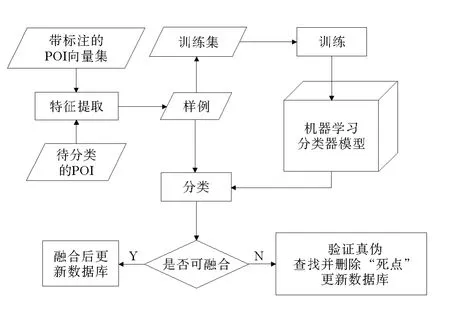
圖1 機器學習分類模型的訓練、分類過程Fig.1 Training and classifying process of machine learning model
3.2 機器學習分類模型
通過大量數據轉換得到的向量集,進行特征提取后將作為訓練集,依據機器學習的方法構建出分類模型,將待分類的POI實例分為可融合和不可融合兩類。具體過程如圖1所示。可融合是指該POI信息已經存在,只需對這些信息進行融合,對部分字段進行更新處理;不可融合則是指該POI信息不在現有數據集中,可能是新出現的POI信息,也可能是錯誤不真實的POI。對這些不可融合信息真偽性的驗證,可以像卡貝斯那樣通過電話情景腳本的方式實現,也可以運用自然語言處理相關技術實現。對于驗證為正確、真實存在的POI,對其進行融合后便可做為一有效信息添加到數據集中。而對那些驗證為錯誤、甚至不存在的POI不作任何處理,是對原有數據集中那些與之相似的POI要經過驗證,最終去除其中的“死點”。
在實驗中,運用了幾個不同的分類器,其中包括貝葉斯分類器、C4.5分類器、Adaboost提升分類器。每個分類器都有各式各樣、復雜的標準,利用這些標準構造不同的模型。比如,C4.5采用信息增益比作為選擇測試屬性的標準,從根節點開始,賦予最好的屬性,在將該屬性各種取值都生成相應的分支,在每個分支上又生成新的節點,加之一些剪枝方法構造出決策樹,使其最大程度地擬合訓練集。C4.5產生的分類規則易于理解,準確率較高,但是在構造樹的過程中,需要對數據集進行多次的順序掃描和排序,因而導致算法的低效。此外,C4.5只適合于能夠駐留于內存的數據集,當訓練集大得無法在內存容納時程序就無法運行了。
4 實驗數據及結果
4.1 數據集
實驗中,本文從美團團購網上抽取了1 095個頁面,每個頁面上有1個POI信息,即之前提到的待分類POI,隨后在google地圖、mapabc、baidu地圖上按照待分類POI中的名稱字段進行模糊搜索,將搜索結果集作為現有POI集合。本文對于這些數據進行了人工標注,根據現有POI集合判斷其對應的待分類POI是否可被融合,標注結果中744個POI是可融合的,238個是不可融合,其余113個POI模糊搜索沒有結果,本文不予以考慮。將以上可融合的和不可融合的(共982個)POI轉換成向量集,作為本實驗的數據集。
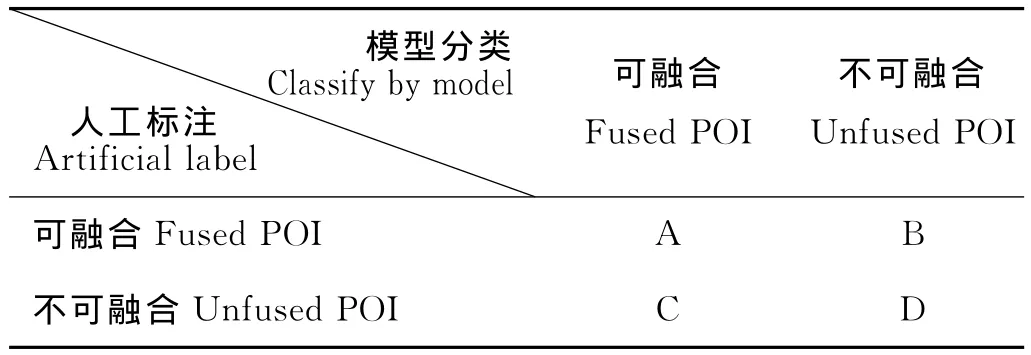
表1 結果關系表Table1The relation of classification result
4.2 測評指標
本節將分析模型分類結果和人工標注結果是否一致,為評測模型的分類效果實驗中用到了3個重要指標,即召回率(Recall)、準確率(Precision)和F值。人工標注結果與模型分類結果關系表示(見表1)。
可融合的召回率r1是指模型分類與人工標注結果均為可融合的POI數目占人工標注中可融合總數的百分比,反映分類模型的完備性;可融合的準確率p1是指模型分類與人工標注結果均為可融合的POI數目占模型分類結果中可融合總數的百分比,可反映分類模型的準確程度。可融合的召回率r1可表示為同樣不可融合的召回率r0可表示為不可融合的準確率整個分類的準確率p則可表示為F值是召回率和準確率這2個指標的綜合值,定義如下:
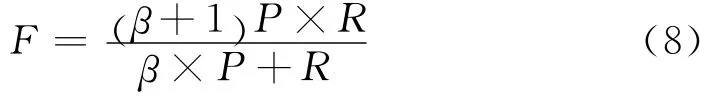
式中:P為準確率;R為召回率;β為召回率和準確率相對權重,一般取1;因此F值可以表示為:

4.3 基于規則的分類結果
本文首先分別對POI中的各特征字段的相似度進行線性回歸,通過設置不同的閥值進行分類,得到每個特征相似度單獨參與分類的表現(見圖2):
圖中f1是可融合的F值,f0是不可融合的F值,p為整個分類結果的準確率。從3個圖中可以看出,無論是哪個字段,p和f1的變化趨勢是一樣的,且f1總是處于最上方,f0總是處于最下方。因為可融合的POI占大部分,所以f1會更大程度地影響整體分類結果。圖中的峰值并不是說此時的p1或r1是最大值,而是說p1和r1處在一個最佳的平衡點,不至于2個值一個過太一個過小。對于p0、r0也是一樣。在圖2(a)中,p和f1在[0.85,1]區間內逐漸減小,對應的f0不斷增大,但最大值仍舊很小,此時所有POI分類的結果為可融合。在圖2(b)中,3個曲線同增減,并在0.36處出現峰值。圖2(c)中的3條線變化趨勢也相同,且在0.001處出現峰值,同樣是這種情況下的平衡點。具體結果(見表2)。
從上述結果分析可知,POI中各字段在區分可融合、不可融合分類過程的表現不同,其分類效果由弱到強分別是名稱、經緯度、地址字段。名稱字段之所以比較差,主要因為現有POI集中的POI是根據待分類POI的名稱進行模糊搜索得到的,它們的名稱相似度已經很高,不足以有效區分POI。其中對地址和經緯度字段進行了融合,其結果表現的最佳。

圖2 POI不同字段的分類結果Fig.2 Classification results for different POI attributes
4.4 基于機器學習方法的分類結果
在實驗中,本文運用了樸素貝葉斯、C4.5、Adaboost 3種分類器對數據集進行了訓練、測試,因為數據有限,所以在這里采用了十折交叉驗證的方法。分類結果(見表3)中可看出,各分類器效果差不多,對可融合的POI分類較好,但對不可融合部分各指標還是偏低。總體來說,C4.5效果較好,適合應用在這個分類中。
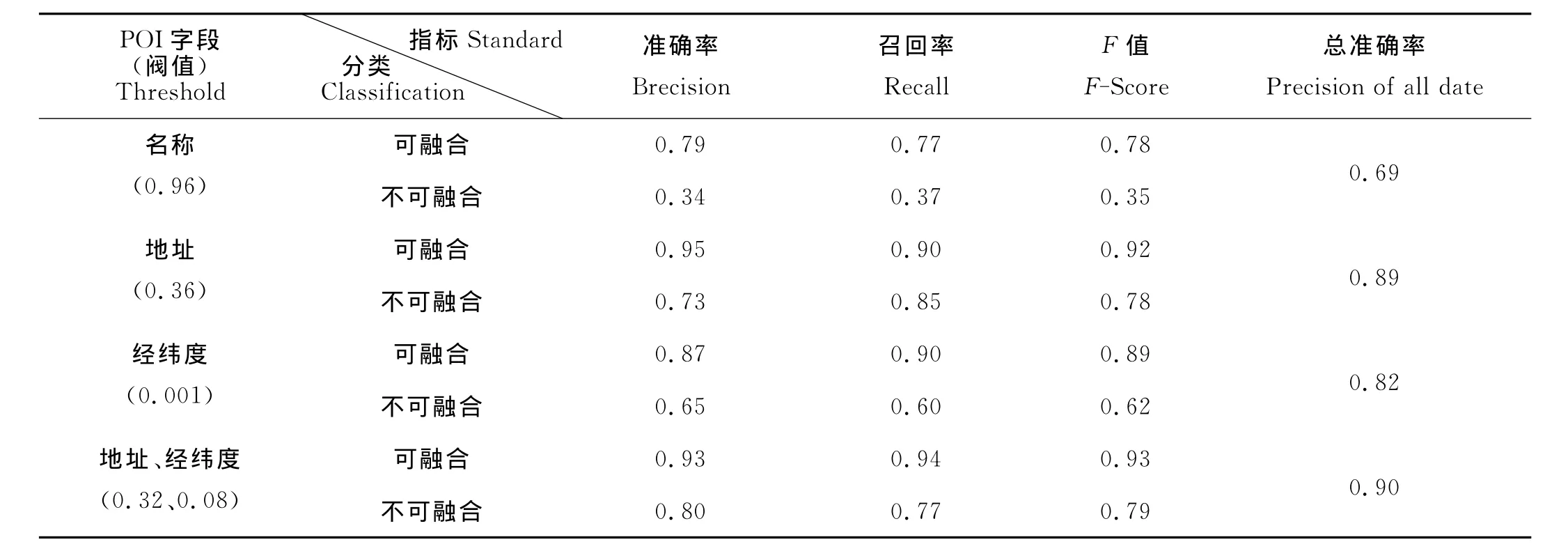
表2 根據不同字段分類的最佳閥值及結果Table 2 The optimal threshold and result
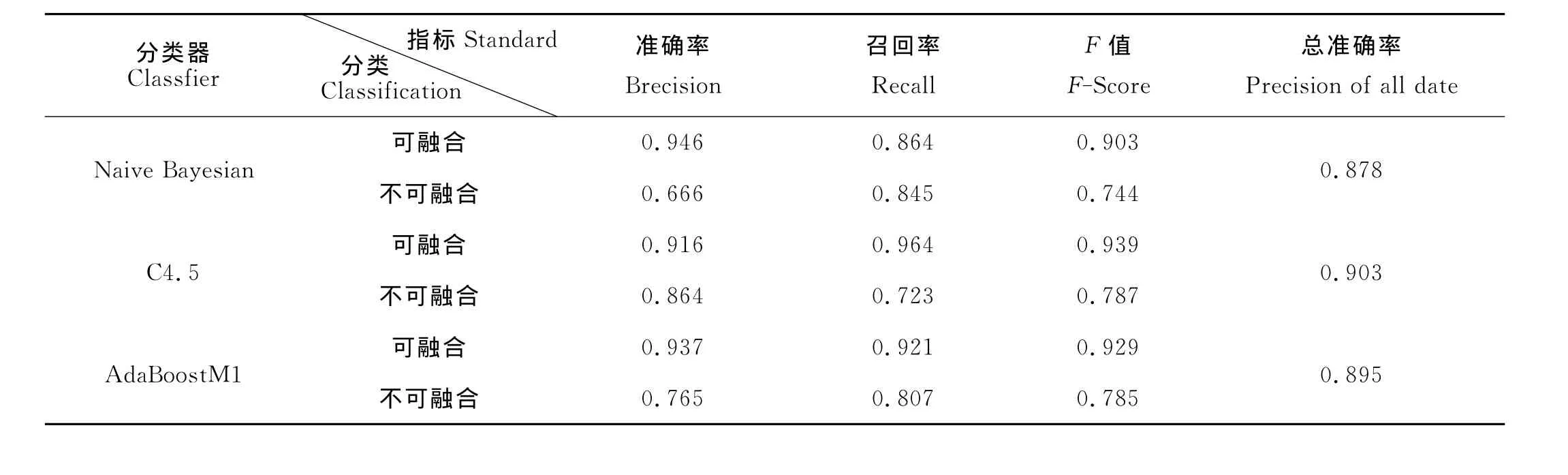
表3 不同分類器的分類結果Table 3 Classification result for different classifier
5 結語
本文分別定義了POI各個特征字段的相似度,根據這些相似度構造出POI相似模型,并對網絡上抽取的POI數據進行有效分類。最后實驗結果準確率可達到90%左右,驗證了根據相似度構建模型的正確性和可行性。同時還說明對POI各字段進行適當的融合,對其分類可以起到一定的積極作用。
對于這些分類為可融合的POI,除名稱、地址、經緯度外的其它部分不具有統一的數據結構,并且還存在大量的冗余信息,仍然不能不能直接應用于位置服務中。下一步還需要研究改進POI的融合模型,得更有價值的融合結果。
[1] Krosche J,Boll S.The xPOI Concept[C].//Location and Context Awareness,Oberpfaffenhofen:Germang Springer,2005:113-119.
[2] 王海波.基于GPS與實景影像的POI快速采集技術 [J].中國科技信息,2007(12):121-122.
[3] Tom M,Mitchell.Machine Learning[M].曾華軍,譯.北京:機械工業出版社,2005:38-56,112-135.
[4] Ryszard S.Michalshi,Ivan Bratko.Machine Learning and Data Mining:Methods and Applications[M].朱明,譯.北京:電子工業出版社,2004:67-94,114-117.
[5] Vivek S.Entity Resolution in Geospatial Data Integration [J].ACM-GIS,2006,11:10-11.
[6] 牛永潔,張成.多種字符串相似度算法的比較研究 [J].計算機與數字工程,2012,3:14-17.
[7] 江洲,李琦.地理編碼(Geocoding)的應用研究 [J].地理與地理信息科學,2003(3):22-25.
[8] 孫亞夫,陳文斌.基于分詞的地址匹配技術 [C].//中國地理信息系統協會第四次會員代表大會暨第十一屆年會論文集.北京:科學出版社,2007:114-125.
[9] 宋玲,徐白.中文檢索系統的相似匹配技術研究和實現 [J].計算機科學 A輯,2010,37(12):46-48.
[10] Beeri C,Kanza Y,Safra E.Object Fusion in Geographic Information System [C].Toronto:Proceeding of the 30th VLDB Conference,2004:816-827.
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
