大數(shù)據(jù)環(huán)境下的增強學習綜述*
2014-11-27 08:15:00馮延蓬孟憲軍江建舉何國坤
深圳職業(yè)技術(shù)學院學報 2014年3期
仵 博,馮延蓬,孟憲軍,江建舉,何國坤
(深圳職業(yè)技術(shù)學院 教育技術(shù)與信息中心,廣東 深圳 518055)
增強學習(Reinforcement Learning,簡稱RL)是一種有效的最優(yōu)控制學習方法,實現(xiàn)系統(tǒng)在模型復雜或者不確定等條件下基于數(shù)據(jù)驅(qū)動的多階段優(yōu)化學習控制,是近年來一個涉及機器學習、控制理論和運籌學等多個學科的交叉研究方向.增強學習因其具有較強的在線自適應性和對復雜系統(tǒng)的自學能力,使其在機器人導航、非線性控制、復雜問題求解等領域得到成功應用[1-4].
經(jīng)典增強學習算法按照是否基于模型分類,可分為基于模型(Model-based)和模型自由(Model-free)兩類.基于模型的有TD學習、Q學習、SARSA和ACTOR-CRITIC等算法.模型自由的有DYNA-Q和優(yōu)先掃除等算法.以上經(jīng)典增強學習算法在理論上證明了算法的收斂性,然而,在實際的應用領域,特別是在大數(shù)據(jù)環(huán)境下,學習的參數(shù)個數(shù)很多,是一個典型的NP難問題,難以最優(yōu)化探索和利用兩者之間的平衡[5-8].因此,經(jīng)典增強學習算法只在理論上有效.
為此,近年來的增強學習研究主要集中在減少學習參數(shù)數(shù)量、避免后驗分布全采樣和最小化探索次數(shù)等方面,達到算法快速收斂的目的,實現(xiàn)探索和利用兩者之間的最優(yōu)化平衡.當前現(xiàn)有算法按照類型可分為五類:1)抽象增強學習;2)可分解增強學習;3)分層增強學習;4)關(guān)系增強學習;5)貝葉斯增強學習.
1 抽象增強學習
抽象增強學習(Abstraction Reinforcement Learning,簡稱 ARL)的核心思想是忽略掉狀態(tài)向量中與當前決策不相關(guān)的特征,只考慮那些有關(guān)的或重要的因素,達到壓縮狀態(tài)空間的效果[9].該類算法可以在一定程度上緩解“維數(shù)災”問題.狀態(tài)抽象原理如圖1所示.
目前,狀態(tài)抽象方法有狀態(tài)聚類、值函數(shù)逼近和自動狀態(tài)抽象等方法.函數(shù)逼近方法難于確保增強學習算法能夠收斂,采用線性擬合和神經(jīng)網(wǎng)絡等混合方法來實現(xiàn)函數(shù)逼近是當前的研究熱點和方向.狀態(tài)聚類利用智能體狀態(tài)空間中存在的對稱性來壓縮狀態(tài)空間,實現(xiàn)狀態(tài)聚類.自動狀態(tài)抽象增強學習方法利用 U-樹自動地由先驗知識推理出狀態(tài)抽象,是狀態(tài)抽象增強學習研究的方向之一.以上算法都在一定程度上緩解了增強學習中大規(guī)模狀態(tài)造成算法無法收斂的問題,但是存在以下缺點:1)增強學習的績效依賴于狀態(tài)抽象方法對狀態(tài)空間的劃分,如何合理劃分子空間是狀態(tài)抽象增強學習面臨的難題.如果空間劃分過粗,難以實現(xiàn)增強學習算法的快速收斂;而如果空間劃分過細,則會喪失泛化能力.2)狀態(tài)抽象方法與特定問題表示相關(guān),缺少統(tǒng)一的理論框架,阻礙了狀態(tài)抽象增強學習的廣泛應用.
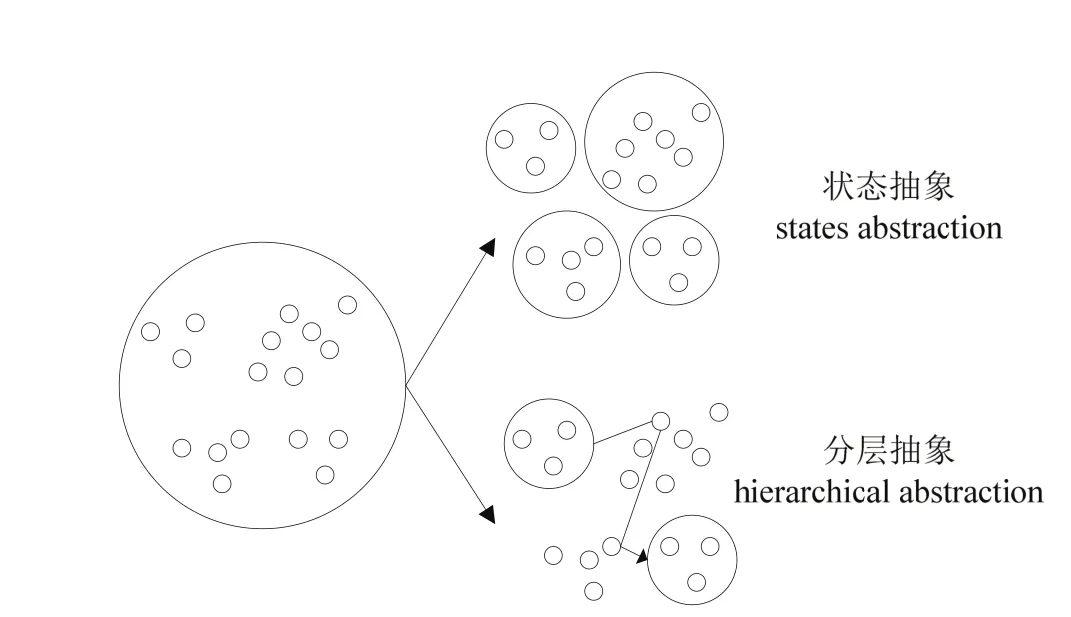
圖1 狀態(tài)抽象原理示意圖
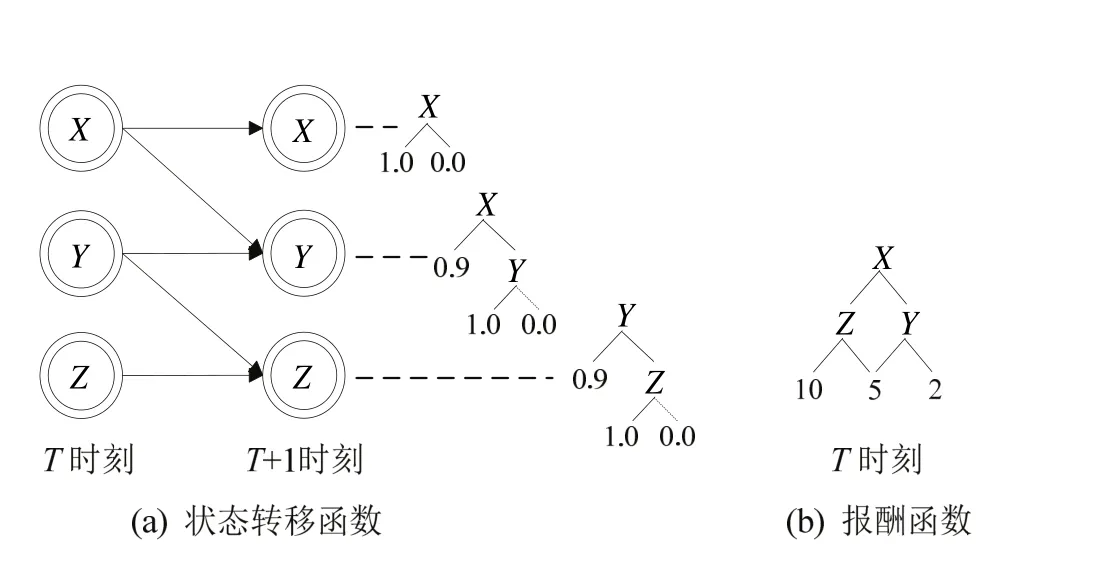
圖2 可分解原理示意圖
2 可分解增強學習
可分解增強學習(Factored Reinforcement Learning,簡稱 FRL)是一種對狀態(tài)轉(zhuǎn)移函數(shù)和報酬函數(shù)進行壓縮表示的增強學習方法[10].該方法的核心思想是首先利用動態(tài)貝葉斯網(wǎng)絡的條件獨立特性和上下文獨立特性將狀態(tài)轉(zhuǎn)移函數(shù)和報酬函數(shù)進行可分解描述,將離散的概率分布函數(shù)轉(zhuǎn)化成決策樹來表示,達到將大規(guī)模指數(shù)級的狀態(tài)空間壓縮到多項式級別的狀態(tài)空間的目的,然后采用決策論回歸方法對決策樹進行學習,可分解原理如圖2所示.
可分解增強學習的思想來源于Boutilier等人在2000年發(fā)表在《Artificial Intelligence》上的論文,該論文指出采用可分解表示方法可以將高維狀態(tài)空間壓縮為低維可求解空間,并詳細介紹可分解的理論和方法,以及結(jié)構(gòu)化動態(tài)規(guī)劃(Structured Dynamic Programming,簡稱SDP)算法,為可分解增強學習奠定了理論基礎.更進一步,Guestrin等人[11]提出結(jié)構(gòu)化線性規(guī)劃(Structured Linear Programming,簡稱SLP)算法和可分解增強學習算法,實現(xiàn)了求解240~250規(guī)模的問題.
由于FRL極大地降低求解問題的規(guī)模,提供學習算法收斂速度,成為近年來的研究熱點.例如,Degris等人提出的SDYNA算法,Kroon等人提出的KWIK算法[12],Kozloval等人提出的IMPSPITI算法和 TeXDYNA 算法[13],Hester等人提出的RL-DT算法[14],Szita等人提出的 FOIM 算法[15],Vigorito等人針對狀態(tài)和動作連續(xù)情況下提出的OISL算法[16]0.
以上FRL算法相同之處是首先采用監(jiān)督學習方法建立狀態(tài)轉(zhuǎn)移函數(shù)和報酬函數(shù)的可分解表示,然后根據(jù)觀察結(jié)果,采用不同的方法來更新狀態(tài)轉(zhuǎn)移函數(shù)模型和報酬函數(shù)模型.因此,如何建立應用對象的可分解泛化表示,減少學習的參數(shù)個數(shù),提高在后驗分布采樣算法的性能是目前研究的難點.
3 分層增強學習
分層增強學習(Hierarchical Reinforcement Learning,簡稱HRL)實質(zhì)上也是一種任務分層方法,其核心思想是將一個大規(guī)模難于求解的問題分解成若干個較小規(guī)模易于求解的問題[10].該算法可以有效解決學習參數(shù)數(shù)量隨狀態(tài)變量維數(shù)成指數(shù)級增長這一“維數(shù)災”問題[17].HRL任務分層方法可分為手工分層和自動分層,手工分層方法是根據(jù)智能體先驗知識采用手工方式來分解,自動任務分層方法是通過自動探索,自動發(fā)現(xiàn)和構(gòu)造某種形式的層次結(jié)構(gòu).根據(jù)先驗知識,采用自動任務分層方法是目前HRL領域的研究熱點.HRL原理如圖3所示.
圖3 分層原理示意圖
由于HRL能夠有效降低求解問題的規(guī)模,成為當前增強學習研究的熱點和難點.在當前研究成果中,具有里程牌意義的算法為Option算法、HAMs算法和MAXQ算法.Option算法的任務分層其實是在大數(shù)據(jù)空間上探索子目標并構(gòu)造Option的過程.HAMs算法通過引入有限狀態(tài)機概念,使之用于表達大數(shù)據(jù)空間中的區(qū)域策略.MAXQ算法的任務分層是在任務空間上構(gòu)造多個子任務的過程,它直接從任務分層的角度來處理大數(shù)據(jù)模型,所有子任務構(gòu)成一個任務圖.
近年來,國內(nèi)外研究人員針對以上三個算法缺點,提出不少改進型 HRL算法.例如,Subramanian等人提出的 Human-Options方法[18],Joshi等人[19]采用面向?qū)ο蟊硎痉椒▉順?gòu)造HRL模型,利用特定領域知識進行動作選擇,以提高學習效果.Jong等人結(jié)合 Rmax算法和MAXQ算法的優(yōu)點,提出一種混合型RMAXQ算法[20].
以上算法在特定的實驗平臺和應用領域有效,但是面對如何劃分層次來保證HRL算法收斂的實時性和策略求解的最優(yōu)性是目前的難題.
4 關(guān)系增強學習
人們在處理復雜領域的問題的時候,會很自然的使用關(guān)系的方法.關(guān)系增強學習(Relational Reinforcement Learning,簡稱RRL)是采用關(guān)系邏輯或圖結(jié)構(gòu)等表示方法來描述環(huán)境[21].當前RRL的研究主要以關(guān)系表示為基礎,考慮在關(guān)系表示上如何把握環(huán)境的不同狀態(tài)[22].RRL在的優(yōu)點在于:首先,它可以將在相似環(huán)境中的對象和已經(jīng)學習到的知識泛化到不同的任務中;其次,使用關(guān)系表示也是一種比較自然的利用先驗知識(背景知識)的方式.目前比較常用的方法就是用一階邏輯形式擴展成關(guān)系先驗,或者擴展成能表達概率和效用的擴展邏輯行為語言[23,24].
RRL利用關(guān)系邏輯的形式來描述復雜問題,利用先驗知識進行邏輯推理,符合人類的思維習慣.但是,從目前應用來看,RRL只在小規(guī)模特定問題有效,例如積木世界、十五子棋和一些小游戲中.如何實現(xiàn)RRL的泛化,如何在大規(guī)模動態(tài)不確定環(huán)境下進行邏輯推理是RRL領域中的難題.
5 貝葉斯增強學習
貝葉斯增強學習(Bayesian Reinforcement Learning,簡稱 BRL)利用模型先驗知識對未知模型參數(shù)建模,然后根據(jù)觀察數(shù)據(jù)對未知模型參數(shù)的后驗分布進行更新,最后根據(jù)后驗分布進行規(guī)劃,以期最大化期望報酬值[25].由于 BRL為最優(yōu)化探索和利用之間的平衡提供一種完美的解決方案,得到廣泛關(guān)注,成為當前RL領域研究的熱點.RRL原理如圖4所示.
BRL可分為模型自由[26]和基于模型[27]兩類.模型自由增強學習算法直接學習最優(yōu)策略和最優(yōu)值函數(shù),需求太多的探索,造成算法收斂速度慢,無法實現(xiàn)在線學習.同時,在實際的應用領域狀態(tài)轉(zhuǎn)移函數(shù)往往會丟失數(shù)據(jù),造成算法的失真.基于模型的增強學習利用先驗知識緩和數(shù)據(jù)丟失,加速算法收斂,減少探索次數(shù),能夠最優(yōu)化平衡探索和利用二者之間的關(guān)系.但是,基于模型的增強學習計算量大,使其無法實現(xiàn)在線學習.為此,如何有效降低未知參數(shù)個數(shù),提高在高維后驗概率分布上規(guī)劃的效率是目前增強學習的難題.
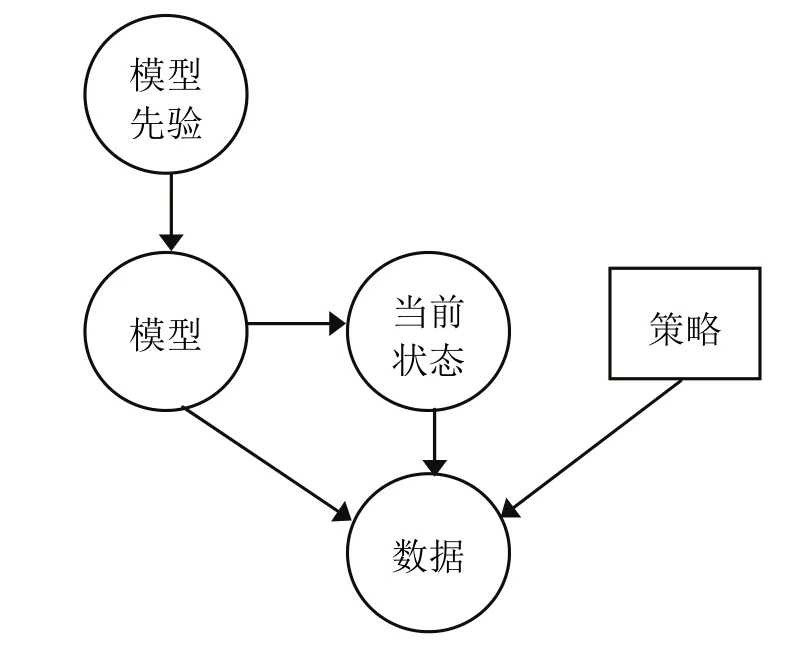
圖4 貝葉斯增強學習原理示意圖
6 結(jié) 論
在大數(shù)據(jù)中進行機器學習,特別是增強學習,是當前大數(shù)據(jù)基礎研究的熱點和難點,也是推進大數(shù)據(jù)應用的關(guān)鍵.規(guī)模巨大的數(shù)據(jù)是增強學習的瓶頸,針對于此,本文研究了當前五類增強學習方法,并指出它們的優(yōu)勢和缺點.大數(shù)據(jù)的關(guān)鍵在于應用,選用何種增強學習方法需要根據(jù)特定的應用而定.當前,在大數(shù)據(jù)應用領域,將監(jiān)督學習或半監(jiān)督學習與增強學習相結(jié)合是一條有效的方法.
[1] Silver D, Sutton R, Müller M. Temporal-difference search in computer Go[J].Machine Learning, 2012,87:183-219.
[2] 徐昕,沈棟,高巖青,等.基于馬氏決策過程模型的動態(tài)系統(tǒng)學習控制:研究前沿與展望[J].自動化學報,2012,38(5):673-687.
[3] Wang F Y, Jin N, Liu D R, et al. Adaptive dynamic programming for finite horizon optimal control of discrete time nonlinear systems with ?-error bound[J].IEEE Transactions on Neural Networks,2011,22(1):24-36.
[4] Hafner R, Riedmiller M. Reinforcement learning in feedback control: challenges and benchmarks from technical process control[J].Machine Learning,2011,84:137-169.
[5] Choi J, Kim K E. Inverse reinforcement learning in partially observable environments[J].Journal of Machine Learning Research, 2011,12:691-730.
[6] Meltzoff, A N, Kuhl, P K, Movellan J, et al. Foundations for a new science of learning[J].Science, 2009,325:284-288.
[7] Kovacs T, Egginton R. On the analysis and design of software for reinforcement learning with a survey of existing systems[J].Machine Learning, 2011,84:7-49.
[8] Doshi-Velez F, Pineau J, Roy N. Reinforcement learning with limited reinforcement: Using Bayes risk for active learning in POMDPs[J].Artificial Intelligence,2012,1870-188:115-132.
[9] Frommberger L, Wolter D. Structural knowledge transfer by spatial abstraction for reinforcement learning agents[J].Adaptive Behavior, 2010,18(6):531-539.
[10] Kozlova O. Hierarchical & Factored reinforcement learning[D].Paris: Université Pierre et Marie Curie, 2010.
[11] Guestrin C, Koller D, Parr R, et al. Efficient solution algorithms for factored MDPs[J].Journal of Artificial Intelligence Research, 2003,19:399-468.
[12] Kroon M, Whiteson S. Automatic feature selection for model-based reinforcement learning in factored MDPs[C]//Wani M A, Kantardzic M M, Palade V, et al.Proceedings of 2009 International Conference on Machine Learning and Applications. Washington, DC:IEEE Press, 2009:324-330.
[13] Kozloval O, Sigaud O, Wuillemin P H, et al. Considering unseen states as impossible in factored reinforcement learning[C]//Buntine W. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases: Part I. Berlin:Springer-Verlag, 2009:721-735.
[14] Hester T, Stone P. Generalized model learning for reinforcement learning in factored domains[C]//Decker K, Sichman J, Sierra C, et al. The Eighth International Conference on Autonomous Agents and Multiagent Systems. Richland, SC: IFAAMS, 2009:10-15.
[15] Szita I, Lorincz A. Optimistic initialization and greediness lead to polynomial time learning in factored MDPs[C]//Wani M A, Kantardzic M M, Palade V, et al.Proceedings of 2009 International Conference on Machine Learning and Applications. Washington, DC:IEEE Press, 2009:1001-1008.
[16] Vigorito C M, Barto A G. Incremental structure learning in factored MDPs with continuous states and actions[R].Amherst: University of Massachusetts Amherst,2009.
[17] 杜小勤,李慶華,韓建軍.HAMs體系中的同態(tài)變換方法研究[J].小型微型計算機系統(tǒng),2008,29(11):2075-2082.
[18] Subramanian K, Isbell C, Thomaz A. Learning options through human interaction[C]//Beal J, Knox W B.Proceedings of 2011 IJCAI Workshop on Agents Learning Interactively from Human Teachers. Palo Alto: AAAI Press, 2011:39-45.
[19] Joshi M, Khobragade R, Sarda S. Hierarchical action selection for reinforcement learning in infinite Mario[C]//Kersting K, Toussaint M. The Sixth Starting Artificial Intelligence Research Symposium.Lansdale, PA: IOS Press, 2012:162-167.
[20] Jong N K, Stone P. Hierarchical model-based reinforcement learning: Rmax+MAXQ[C]//McCallum A, Roweis S. Proceedings of the Twenty-Fifth International Conference on Machine Learning. Madison, Wisconsin: ACM Press, 2008:432-439.
[21] Liu Q,Gao Y,Chen D X,et al. A Heuristic Contour Prolog List Method Used in Logical Reinforcement Learning[J].Journal of Information & Computational Science, 2008,5(5):2001-2007.
[22] Song Z W, Chen X P, Cong S. Agent learning in relational domains based on logical MDPs with negation[J].Journal of Computers, 2008,3(9):29-38.
[23] Sanner S, Kersting K. Symbolic Dynamic Programming for First-order POMDPs[C]//Fox M, Poole D.Proceeding of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10). Atlanta: AAAI Press,2010:1140-1146.
[24] 劉全,周文云,李志濤.關(guān)系強化學習方法的初步研究[J].計算機應用與軟件,2010,27(2):40-43.
[25] Ghavamzadeh M, Engel Y. Bayesian actor-critic algorithms[C]//Ghahramani, Z. Proceedings of the 24thInternational Conference on Machine Learning. New York: ACM Press, 2007:297-304.
[26] Poupart P, Vlassis N. Model-based Bayesian reinforcement learning in partially observable domains [C] //Padgham L, ParkesD. Proceedings of the International Joint Conference on Autonomous Agents and Multi Agent Systems. New York: ACM Press, 2008:1025-1032.
[27] Ross S, Pineau J, Chaib-draa B, et al. A Bayesian approach for learning and planning in partially observable Markov decision processes[J].Journal of Machine Learning Research, 2011,12:1729-1770.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
