融合影響因子的加權(quán)協(xié)同過(guò)濾算法
2014-12-02 01:13:58高全力楊建鋒
計(jì)算機(jī)工程 2014年8期
高全力,高 嶺,楊建鋒,王 海,任 杰,張 洋
(西北大學(xué)信息科學(xué)與技術(shù)學(xué)院,西安 710127)
1 概述
隨著網(wǎng)絡(luò)的急劇擴(kuò)張,網(wǎng)絡(luò)上的資源呈現(xiàn)幾何性的增長(zhǎng),包括音頻、視頻、新聞等充斥著整個(gè)網(wǎng)絡(luò)。這帶來(lái)了兩方面的困擾,一方面是從用戶的角度,從海量的資源中找到自己真正感興趣的資源越來(lái)越困難;另一方面是從網(wǎng)絡(luò)服務(wù)提供商的角度,由于用戶留給推薦系統(tǒng)有價(jià)值的信息非常少,為不同的用戶準(zhǔn)確地推薦資源也越來(lái)越困難。因此,對(duì)于高質(zhì)量推薦系統(tǒng)的需求也就越來(lái)越大。
許多研究人員提出了各種推薦算法的思路及其具體的實(shí)施方案,例如基于內(nèi)容過(guò)濾的推薦算法[1]、適應(yīng)性推薦算法[2]、基于項(xiàng)目的推薦算法[3]等。其中,協(xié)同過(guò)濾算法是目前最成功的推薦算法之一,在電影、歌曲、圖書等領(lǐng)域都有廣泛的應(yīng)用,其中在電子商務(wù)推薦系統(tǒng)中的成功應(yīng)用[4]使其受到廣泛關(guān)注。盡管協(xié)同過(guò)濾算法非常成功和受歡迎,但它仍有2 個(gè)局限性:數(shù)據(jù)稀疏性和冷啟動(dòng)問(wèn)題。數(shù)據(jù)稀疏性指的是在一個(gè)龐大的用戶空間里只有很少的用戶對(duì)項(xiàng)目進(jìn)行評(píng)分,這樣也就導(dǎo)致了在計(jì)算相似度時(shí),所能依賴的信息較少,降低了相似度計(jì)算的可信度[5]。冷啟動(dòng)問(wèn)題分為用戶冷啟動(dòng)問(wèn)題與項(xiàng)目冷啟動(dòng)問(wèn)題,指的是對(duì)于新加入系統(tǒng)的用戶或項(xiàng)目系統(tǒng)很難做出高質(zhì)量的推薦[6]。為了解決這2 個(gè)問(wèn)題,文獻(xiàn)[7]等通過(guò)分析基于內(nèi)容的推薦算法與協(xié)同過(guò)濾推薦算法的優(yōu)缺點(diǎn),提出了將兩者相融合的推薦算法;文獻(xiàn)[4]借鑒社會(huì)網(wǎng)絡(luò)中人與人之間的信任評(píng)價(jià)方法,提出一種基于信任機(jī)制的協(xié)同過(guò)濾推薦算法,提高了推薦質(zhì)量;文獻(xiàn)[8]通過(guò)將聯(lián)合聚類與協(xié)同過(guò)濾算法相結(jié)合,采用聚類技術(shù)解決數(shù)據(jù)稀疏性;文獻(xiàn)[9]通過(guò)降低矩陣維數(shù)來(lái)解決數(shù)據(jù)稀疏的問(wèn)題。然而,研究人員在關(guān)注于這2 個(gè)問(wèn)題時(shí),卻忽視了另一個(gè)重要的問(wèn)題——相似度的計(jì)算算法。單純地使用基于用戶或者基于項(xiàng)目或者僅僅將兩者簡(jiǎn)單結(jié)合的相似度算法[3-10],具有很大的局限性。首先由于數(shù)據(jù)集的潛在的稀疏性,可能導(dǎo)致算法計(jì)算出的相似性數(shù)值差別非常小,進(jìn)而無(wú)法找出真正的相似用戶或相似項(xiàng)目。其次沒(méi)有充分考慮,對(duì)任意2 個(gè)用戶共同評(píng)分過(guò)的項(xiàng)目個(gè)數(shù)與任意2 個(gè)項(xiàng)目間共同評(píng)分的用戶個(gè)數(shù)對(duì)相似性計(jì)算的影響。
針對(duì)上述問(wèn)題,本文提出種基于影響因子的相似度計(jì)算方法。從用戶與項(xiàng)目2 種角度來(lái)解決相似度的計(jì)算問(wèn)題,把用戶間共同評(píng)分項(xiàng)目的個(gè)數(shù)與項(xiàng)目間共同評(píng)分用戶的個(gè)數(shù)作為影響因子來(lái)修正相似度的計(jì)算,并根據(jù)2 種相似度計(jì)算方法,分別提出了不同的預(yù)測(cè)評(píng)分計(jì)算算法。為平滑預(yù)測(cè)評(píng)分,將基于用戶的預(yù)測(cè)評(píng)分與基于項(xiàng)目的預(yù)測(cè)評(píng)分進(jìn)行加權(quán),得到最終預(yù)測(cè)評(píng)分。
2 問(wèn)題描述
在協(xié)同過(guò)濾算法中,首先應(yīng)根據(jù)歷史數(shù)據(jù)庫(kù)建立一個(gè)user-item 評(píng)分矩陣,矩陣中的各個(gè)數(shù)值即表示用戶對(duì)相應(yīng)項(xiàng)目的評(píng)分值,如表1 所示。
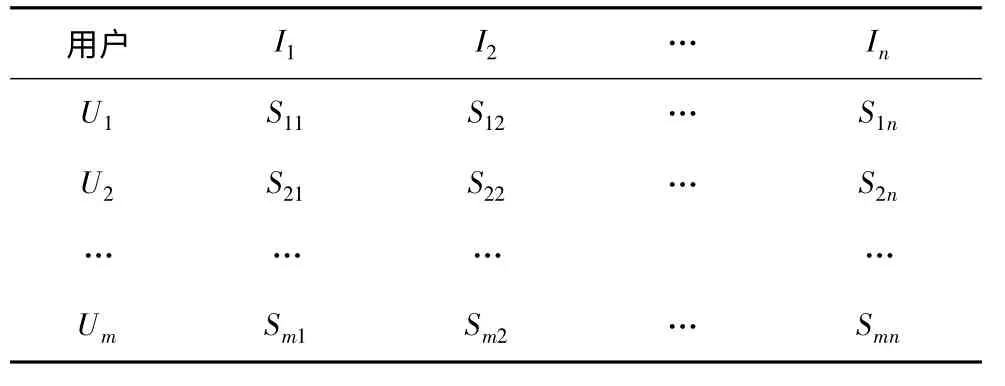
表1 user-item 評(píng)分矩陣S(m,n)
其中,表1 共有m 行n 列,分別代表m 個(gè)用戶與n 個(gè)項(xiàng)目;Smn表示用戶Um對(duì)于項(xiàng)目In的評(píng)分值。
然后以評(píng)分矩陣為基礎(chǔ),采用基于用戶或基于項(xiàng)目的余弦相似度、修正的余弦相似度[1]或者相關(guān)相似度[11]來(lái)計(jì)算用戶間或者項(xiàng)目間的相似度的值。并將其作為用戶間或項(xiàng)目間的最終相似度。根據(jù)相似度的值找出最近鄰用戶或最近鄰項(xiàng)目,以此為基礎(chǔ)通過(guò)評(píng)分算法計(jì)算出預(yù)測(cè)評(píng)分。最后根據(jù)預(yù)測(cè)評(píng)分的排序序列進(jìn)行推薦。
在余弦相似度計(jì)算方法中,對(duì)于用戶沒(méi)有做出評(píng)分的項(xiàng)目評(píng)分全部置為0 分,在用戶空間非常大且數(shù)據(jù)非常稀疏的情況下,這種假設(shè)會(huì)極大地影響相似度的計(jì)算[12]。在相關(guān)相似度的計(jì)算方法中,雖然在未評(píng)分項(xiàng)目的處理上,采取了一些措施來(lái)緩解其帶來(lái)的影響(在計(jì)算用戶相似性是采用用戶間共同評(píng)分的項(xiàng)目作為參評(píng)對(duì)象),并且通過(guò)減去用戶對(duì)所有項(xiàng)目評(píng)分的平均評(píng)分來(lái)修正不同用戶存在的評(píng)分偏見。但是這種做法在數(shù)據(jù)稀疏性的情況下,仍不能有效地計(jì)算出實(shí)際的相似度[13]。
3 本文算法
在本文的算法中,從用戶與項(xiàng)目2 種角度來(lái)解決相似度的計(jì)算問(wèn)題,將基于用戶間共同評(píng)分項(xiàng)目與項(xiàng)目間共同評(píng)分用戶的影響因子,與修正的余弦相似度的乘積計(jì)算用戶間及項(xiàng)目間的相似度。并根據(jù)2 種相似度計(jì)算方法,分別提出不同的預(yù)測(cè)評(píng)分計(jì)算算法,即融合影響因子的用戶協(xié)同過(guò)濾算法(Fused Impact Factor of User Based Collaborative Filtering,IFUBCF)、融合影響因子的項(xiàng)目協(xié)同過(guò)濾算法(Fused Impact Factor of Item Based Collaborative Filtering,IFIBCF)、融合影響因子的加權(quán)協(xié)同過(guò)濾算法(Weighted Collaborative Filtering Based Impact Factor,IFBWCF)。
3.1 融合影響因子的用戶協(xié)同過(guò)濾算法
用戶的相似度表示用戶間興趣的重合程度,相似度的計(jì)算是協(xié)同過(guò)濾算法較為關(guān)鍵的環(huán)節(jié)。選擇當(dāng)前用戶a 與任意用戶b,用戶a 與用戶b 已評(píng)分的項(xiàng)目集合分別為Ia與Ib,其評(píng)分項(xiàng)目集合的并集Iab=Ia∪Ib。在Iab上,用修正的余弦相似度[11]計(jì)算用戶a 與用戶b 的相似度公式如下:
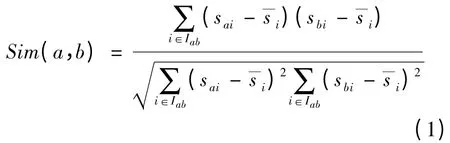
其中,sai表示用戶a 對(duì)于項(xiàng)目i 的評(píng)分;sbi表示用戶b 對(duì)于項(xiàng)目i 的評(píng)分表示項(xiàng)目i 的平均被評(píng)分值。由于僅僅根據(jù)式(1)得出的相似度的值,有可能會(huì)產(chǎn)生一些不準(zhǔn)確的情況[13]。例如,2 個(gè)用戶共同評(píng)分的項(xiàng)目較多,但是根據(jù)式(1)所得出的相似度的值卻有可能較低。并且用戶間共同評(píng)分項(xiàng)目的個(gè)數(shù),是反映用戶行為及興趣重合程度的重要因素。因此,在計(jì)算相似度時(shí)應(yīng)充分考慮其對(duì)相似度值的影響。所以本文用基于用戶間的共同評(píng)分項(xiàng)目的個(gè)數(shù)的影響因子來(lái)修正相似度的計(jì)算,影響因子βu的計(jì)算公式如下:

其中,cab表示用戶a 和用戶b 之間共同評(píng)分過(guò)的項(xiàng)目的個(gè)數(shù);αu是為了避免式中分母為0 導(dǎo)致無(wú)意義或者βu的值為0 導(dǎo)致式(1)中計(jì)算出的相似度為0而添加的常數(shù)參數(shù);c—u 表示其他任2 個(gè)用戶共同評(píng)分過(guò)的項(xiàng)目個(gè)數(shù)的平均值。由于當(dāng)用戶空間非常大時(shí)的值可能會(huì)趨于非常小,進(jìn)而導(dǎo)致βu的值過(guò)大,從而使得式(1)中計(jì)算的相似度對(duì)最終相似度值的影響過(guò)低。所以,需要根據(jù)不同的數(shù)據(jù)集調(diào)整αu,以修正影響因子的取值。
因此,相似度的最終計(jì)算公式為:

為了得到用戶a 對(duì)于未評(píng)分項(xiàng)P 的預(yù)測(cè)評(píng)分,首先根據(jù)式(3)中計(jì)算的相似度的值,得到其他用戶與用戶a 的相似度序列,找出用戶a 的k 鄰近用戶。根據(jù)k 鄰近用戶與當(dāng)前用戶的相似度與未評(píng)分項(xiàng)目P(P∈Iab)被評(píng)分的平均值,通過(guò)公式計(jì)算出未評(píng)分項(xiàng)目P 相對(duì)于當(dāng)前用戶a 的預(yù)測(cè)評(píng)分Sa(因?yàn)閍 為任意用戶,為體現(xiàn)一般性,用Susr代替Sa),即IFUBCF 算法,計(jì)算公式如下:

其中,m 為k 鄰近用戶中對(duì)于未評(píng)分項(xiàng)目P 有評(píng)分的用戶的個(gè)數(shù),顯然1≤m≤k,Im即為此m 個(gè)用戶空間即為用戶i 對(duì)于項(xiàng)目P 的評(píng)分為用戶i 平均評(píng)分值為項(xiàng)目的P 的平均評(píng)分。則基于用戶相似度的預(yù)測(cè)評(píng)分即體現(xiàn)為:k 鄰近用戶對(duì)于未評(píng)分項(xiàng)的評(píng)分與該用戶評(píng)分均值偏差的和,與其相對(duì)于當(dāng)前用戶相似度的乘積對(duì)于未評(píng)分項(xiàng)平均評(píng)分的影響。
3.2 融合影響因子的項(xiàng)目協(xié)同過(guò)濾算法
項(xiàng)目的相似度表示項(xiàng)目間的相似程度,對(duì)任意項(xiàng)目i 評(píng)過(guò)分的用戶集合為Ui,對(duì)項(xiàng)目j 評(píng)過(guò)分的用戶集合為Uj,其評(píng)分用戶并集Uij=Ui∪Uj。在Uij上用基于項(xiàng)目的修正余弦相似度[11]來(lái)計(jì)算項(xiàng)目i 與項(xiàng)目j 之間的相似度,公式如下:
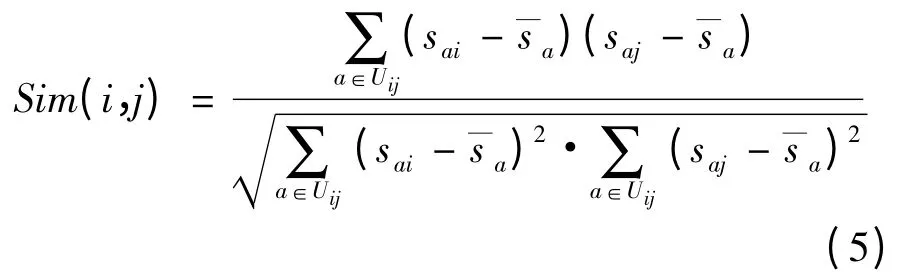

其中,cij表示對(duì)項(xiàng)目i 和項(xiàng)目j 共同評(píng)分用戶的個(gè)數(shù)表示其他任意2 個(gè)項(xiàng)目間共同評(píng)分用戶個(gè)數(shù)的平均值;αi為修正β 的常數(shù)參數(shù)。其最終相似度計(jì)算公式如下:

根據(jù)式(7)所得出的相似度序列,計(jì)算出項(xiàng)目P的k 鄰近項(xiàng)目,從而得出用戶a 對(duì)于未評(píng)分項(xiàng)目P的預(yù)測(cè)評(píng)分(因?yàn)镻 為任意項(xiàng)目,為體現(xiàn)一般性,用Sitem來(lái)代替Sp),即IFIBCF 算法,計(jì)算公式如下:
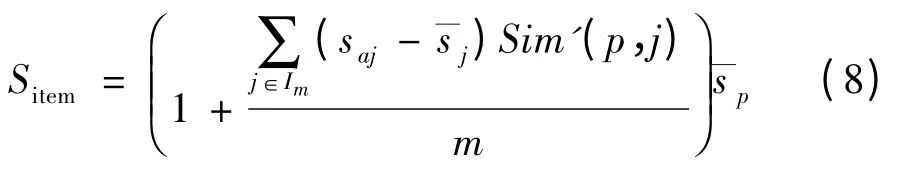
3.3 加權(quán)的協(xié)同過(guò)濾算法
用戶與項(xiàng)目作為影響整個(gè)推薦系統(tǒng)推薦質(zhì)量的2 個(gè)重要因素,單獨(dú)選擇其中一個(gè)作為預(yù)測(cè)評(píng)分的主要基準(zhǔn),是不合理的[14]。因此,本文將2 種算法結(jié)合起來(lái),通過(guò)引入加權(quán)系數(shù),平滑2 種情況下的預(yù)測(cè)評(píng)分,使預(yù)測(cè)評(píng)分更加合理與精確。具體做法是,將基于用戶的k 鄰近用戶中對(duì)于未評(píng)分項(xiàng)有評(píng)分的個(gè)數(shù)m 與基于項(xiàng)目的k 鄰近項(xiàng)目中相對(duì)于當(dāng)前用戶被評(píng)分項(xiàng)目的個(gè)數(shù)n 做為加權(quán)系數(shù),得出基于影響因子的加權(quán)協(xié)同過(guò)濾算法IFBWCF,即:

其中,Susr表示根據(jù)IFUBCF 算法計(jì)算出的預(yù)測(cè)分值;Sitem表示根據(jù)IFIBCF 算法計(jì)算出的預(yù)測(cè)分值。根據(jù)式(9)計(jì)算出當(dāng)前用戶對(duì)于未評(píng)分項(xiàng)目的最終預(yù)測(cè)評(píng)分,根據(jù)TopN 算法為當(dāng)前用戶推薦得分最高的N 個(gè)項(xiàng)目。
4 實(shí)驗(yàn)結(jié)果與分析
實(shí)驗(yàn)所采用的PC 機(jī)的配置為Intel(R)Core(TM)i5 2.8 GHz CPU,4 GB 內(nèi)存,操作系統(tǒng)為Windows XP,算法使用Matlab 實(shí)現(xiàn)。
4.1 數(shù)據(jù)集與實(shí)驗(yàn)方案
本文中所做實(shí)驗(yàn)采用的數(shù)據(jù)集為MovieLens 數(shù)據(jù)集,此數(shù)據(jù)集是常用的基于Web 的衡量推薦算法質(zhì)量的數(shù)據(jù)集。對(duì)每個(gè)電影采取5 分制的評(píng)分策略。本文選取的是其公開的一部分?jǐn)?shù)據(jù),包括943 個(gè)用戶對(duì)于1 682 部電影的100 000 條評(píng)分記錄。其中,每個(gè)用戶都至少對(duì)20 部電影進(jìn)行了評(píng)分。分?jǐn)?shù)的數(shù)值越高表示用戶對(duì)于這部電影的喜愛(ài)程度越高。為緩解采用單一數(shù)據(jù)集導(dǎo)致的實(shí)驗(yàn)結(jié)果缺乏說(shuō)服力,本文采用All But One 算法對(duì)數(shù)據(jù)集進(jìn)行處理。并將數(shù)據(jù)集分為訓(xùn)練集與測(cè)試集兩部分,在最近鄰居k 值的選取對(duì)推薦結(jié)果的影響上,將本文算法與多類屬概率潛在語(yǔ)義的協(xié)同過(guò)濾算法PLSA(Probabilistic Latent Semantic Analysis)[9]相對(duì)比。
4.2 算法的評(píng)價(jià)標(biāo)準(zhǔn)
一般來(lái)說(shuō),評(píng)價(jià)一個(gè)推薦算法質(zhì)量的標(biāo)準(zhǔn)有統(tǒng)計(jì)精度度量方法和決策支持精度度量方法。本文實(shí)驗(yàn)所采用的是屬于統(tǒng)計(jì)精度度量方法的平均絕對(duì)誤差(Mean Absolute Error,MAE)[11]作為檢驗(yàn)推薦算法的標(biāo)準(zhǔn)。MAE 通過(guò)預(yù)測(cè)的用戶評(píng)分與實(shí)際的用戶評(píng)分之間的偏差來(lái)度量預(yù)測(cè)的準(zhǔn)確性。算法的MAE 越小表明算法的預(yù)測(cè)越準(zhǔn)確,意味著算法的推薦質(zhì)量越高。設(shè)預(yù)測(cè)用戶評(píng)分的集合表示為{p1,p2,…,pN},對(duì)應(yīng)的實(shí)際用戶評(píng)分集合為{q1,q2,…,qN},則:
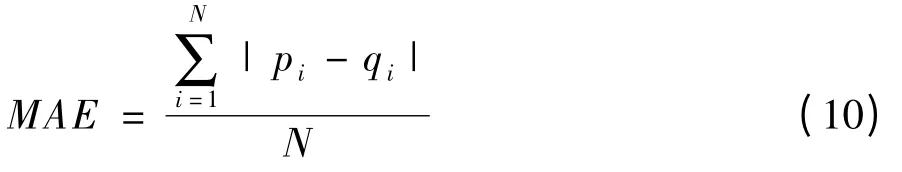
4.3 算法的復(fù)雜度分析
一個(gè)算法質(zhì)量的優(yōu)劣將直接影響到算法乃至整個(gè)程序的效率,為了檢驗(yàn)算法性能與改進(jìn)算法,需對(duì)算法進(jìn)行復(fù)雜度分析。在本文所描述的3 種算法中,算法的時(shí)間復(fù)雜度主要由兩部分組成:計(jì)算相似度矩陣與找出k 鄰近用戶或項(xiàng)目并計(jì)算預(yù)測(cè)評(píng)分所需的時(shí)間來(lái)決定的。假設(shè)某數(shù)據(jù)集中,用戶數(shù)為m,項(xiàng)目數(shù)為n。在IFUBCF 與IFIBCF 算法中,計(jì)算相似度矩陣的時(shí)間復(fù)雜度分別為O(m2n)與O(mn2)。在IFBWCF 算法中則為O(m2n)+O(mn2)。在IFUBCF 與IFIBCF 算法中,時(shí)間復(fù)雜度分別為O(mn2)與O(m2n)。在IFBWCF 中為O(m2n)+O(mn2)。所以,在用戶數(shù)大于項(xiàng)目數(shù)的情況下,3 種算法的時(shí)間復(fù)雜度分別為O(m2n)、O(mn2)與O(m2n),否則分別為O(mn2)、O(m2n)與O(m2n),與傳統(tǒng)的User-based 協(xié)同過(guò)濾算法(O(mn2))和Item-based 協(xié)同過(guò)濾算法(O(m2n))基本一致。
4.4 參數(shù)的取值分析
由于本文對(duì)于數(shù)據(jù)集采用All but one 算法進(jìn)行處理,即每次評(píng)分?jǐn)?shù)據(jù)的隱藏都是隨機(jī)的,相當(dāng)于每次進(jìn)行運(yùn)算的數(shù)據(jù)集都在變化,這也必然導(dǎo)致根據(jù)評(píng)分算法得出的預(yù)測(cè)評(píng)分的上下浮動(dòng)。因此,本文對(duì)于α 值的選取采用在每個(gè)節(jié)點(diǎn)計(jì)算5 次,然后取其均值。本次實(shí)驗(yàn)中在選取不同鄰居點(diǎn)數(shù)目情況下,分別使α取0.5,1.0,1.5,2.0,2.5,3.0,3.5,4.0 對(duì)3 種算法進(jìn)行測(cè)試,以便求出使各算法最優(yōu)的α 值。α 值對(duì)3 種算法影響的實(shí)驗(yàn)結(jié)果如圖1~圖4 所示。
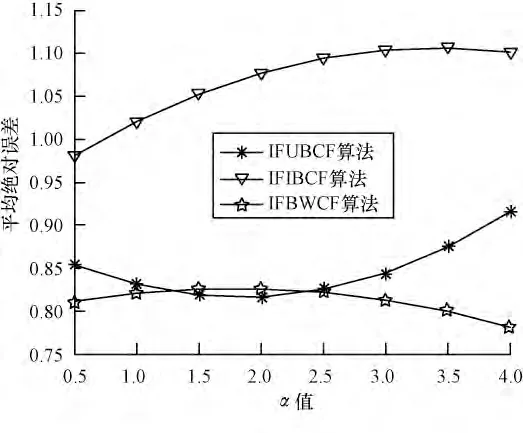
圖1 最近鄰居數(shù)為10 時(shí)α 對(duì)算法的影響
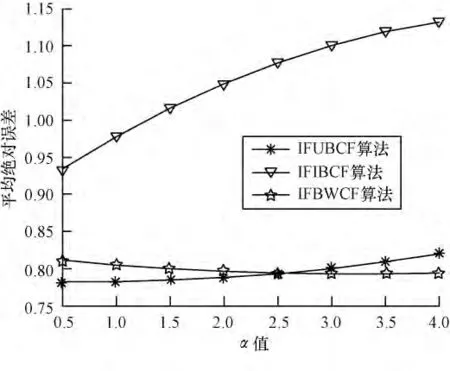
圖2 最近鄰居數(shù)為20 時(shí)α 對(duì)算法的影響
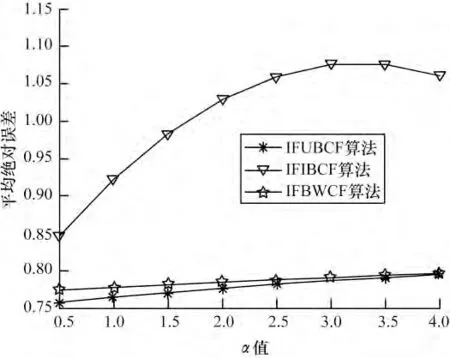
圖3 最近鄰居數(shù)為30 時(shí)α 對(duì)算法的影響

圖4 最近鄰居數(shù)為40 時(shí)α 對(duì)算法的影響
可以看出,隨α 值的增加:圖1 中IFIBCF 算法與IFUBCF 算法呈遞增趨勢(shì),IFWBCF 算法呈遞減趨勢(shì),在1.0 與1.5 處,3 個(gè)算法總體MAE 最小;圖2 中IFIBCF 算法呈遞增趨勢(shì),IFUBCF 算法在1.5~2.0 間取得最小值,IFWBCF 算法在2.5 以后逐漸下降;圖3表明3 個(gè)算法在1.0~1.5 間總體MAE 最小;圖4 中3個(gè)算法都呈遞增趨勢(shì)α 值越小,總體MAE 越好。分析可得,當(dāng)α 取1 時(shí),3 種算法的總體MAE 值較小,也即3 種算法在此時(shí)預(yù)測(cè)評(píng)分最準(zhǔn)確。因此,本文對(duì)算法進(jìn)行評(píng)價(jià)性測(cè)試時(shí),α 統(tǒng)一為1。
4.5 算法分析
通過(guò)對(duì)PLSA 算法與本文所給出的3 種算法進(jìn)行試驗(yàn)對(duì)比,從數(shù)據(jù)集中隨機(jī)抽取98 個(gè)用戶的評(píng)分?jǐn)?shù)據(jù)。對(duì)于這些數(shù)據(jù)采用All But One 算法進(jìn)行隱藏處理,然后對(duì)這些被隱藏評(píng)分的項(xiàng)目進(jìn)行預(yù)測(cè)評(píng)分。最后計(jì)算預(yù)測(cè)評(píng)分與實(shí)際評(píng)分的偏差值,通過(guò)MAE 的值來(lái)度量預(yù)測(cè)評(píng)分的準(zhǔn)確度。在最近鄰居數(shù)分別選取5,10,15,20,25,30,35,40 時(shí)分別運(yùn)行IFUBCF、IFIBCF、IFBWCF、PLSA 算法,對(duì)每個(gè)算法在各鄰居點(diǎn)分別運(yùn)行5 次取其均值。實(shí)驗(yàn)結(jié)果如圖5所示。
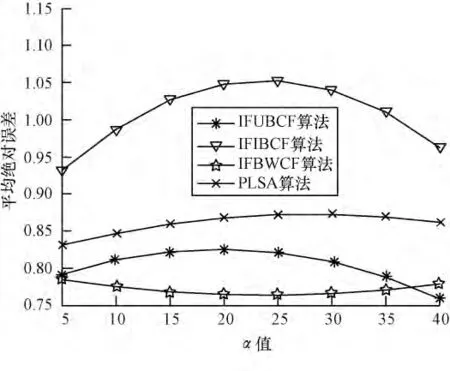
圖5 各協(xié)同過(guò)濾算法的對(duì)比
實(shí)驗(yàn)結(jié)果表明,本文提出的基于影響因子的加權(quán)協(xié)同推薦算法與其他算法相比,具有較小的MAE值,推薦的準(zhǔn)確度較高,能夠獲得更好的推薦質(zhì)量。
5 結(jié)束語(yǔ)
本文從基于用戶與基于項(xiàng)目2 個(gè)角度對(duì)協(xié)同過(guò)濾算法進(jìn)行改進(jìn),在計(jì)算用戶相似性時(shí),考慮了用戶間共同評(píng)分項(xiàng)目的個(gè)數(shù)對(duì)于相似性的影響。在計(jì)算項(xiàng)目相似度時(shí),考慮對(duì)項(xiàng)目有共同評(píng)分的用戶的個(gè)數(shù)對(duì)于相似度的影響。這種方法增加了相似度計(jì)算的合理性,使得對(duì)于未評(píng)分項(xiàng)的預(yù)測(cè)更為準(zhǔn)確。并且在這2 種改進(jìn)算法的基礎(chǔ)上,提出一種基于影響因子的加權(quán)協(xié)同過(guò)濾算法,能更加客觀地把2 種情況下的預(yù)測(cè)評(píng)分綜合起來(lái)平滑2 種情況下的得分,使得預(yù)測(cè)評(píng)分能夠更加接近實(shí)際得分值,進(jìn)而獲得更好的推薦質(zhì)量。下一步將研究一種能夠根據(jù)不同用戶的選擇自動(dòng)修正評(píng)分算法的新方法,以進(jìn)一步提高算法的推薦質(zhì)量與智能性。另外,基于海量數(shù)據(jù)的推薦算法優(yōu)化也是今后一個(gè)重要的研究方向。
[1]胡福華,鄭小林,干紅華.基于相似度傳遞的協(xié)同過(guò)濾算法[J].計(jì)算機(jī)工程,2011,37(10):50-51,54.
[2]Shahab I C,Chen Y S.An Adaptive Recommendation System Without Explicit Acquisition of User Relevance Feedback[J].Distributed and Parallel Databases,2003,14(2):173-192.
[3]Deshpande M,Karypis G.Item-based Top-n Recommendation Algorithms[J].ACM Transactions on Information Systems,2004,22(1):143-177.
[4]夏小伍,王衛(wèi)平.基于信任模型的協(xié)同過(guò)濾推薦算法[J].計(jì)算機(jī)工程,2011,37(21):26-28.
[5]Papagelis M,Plexousakis D,Kutsuras T.Alleviating the Sparsity Problem of Collaborative Filtering Using Trust Inferences[M].Berlin,Germany:Springer,2005.
[6]Lam X N,Vu T,Le T D,et al.Addressing Cold-start Problem in Recommendation Systems[C]//Proceedings of the 2nd International Conference on Ubiquitous Information Management and Communication.[S.1.]:ACM Press,2008:208-211.
[7]Melville P,Mooney R J,Nagarajan R.Content-boosted Collaborative Filtering for Improve Recommendations[C]//Proceedings of National Conference on Artificial Intelligence.London,UK:MIT Press,2002:187-192.
[8]George T,Merugu S.A Scalable Collaborative Filtering Framework Based on Co-clustering[C]//Proceedings of the 5th IEEE International Conference on Data Mining.Texas,USA:IEEE Press,2005:4.
[9]侯翠琴,焦李成,張文革.一種壓縮稀疏用戶評(píng)分矩陣的協(xié)同過(guò)濾算法[J].西安電子科技大學(xué)學(xué)報(bào),2009,36(4):614-618.
[10]Chun Zeng,Xing Chunxiao,Zhou Lizhu.Similarity Measure and Instance Selection for Collaborative Filtering[C]//Proceedings of the 12th International Conference on World Wide Web.Budapest,Hungary:ACM Press,2003:652-658.
[11]汪 靜,印 鑒,鄭利榮,等.基于共同評(píng)分和相似性權(quán)重的協(xié)同過(guò)濾推薦算法[J].計(jì)算機(jī)科學(xué),2010,37(2):99-104.
[12]Sarwar B,Karypis G,Konstan J,et al.Item-based Collaborative Filtering Recommendation Algorithms[C]//Proceedings of the 10th International Conference on World Wide Web.USA:ACM Press,2001:285-295.
[13]Massa P,Avesani P.Trust-awareCollaborative Filtering for Recommender Systems [M].Berlin,Germany:Springer,2004.
[14]Ghazanfar M,Prugel-Bennett A.NovelSignificance Weighting Schemes for Collaborative Filtering:Generating Improved Recommendations in Sparse Environments[C]//Proceedings of 2010 International Conference on Data Mining.[S.1.]:IEEE Press,2010:215-223.
猜你喜歡
中學(xué)生數(shù)理化·八年級(jí)物理人教版(2022年3期)2022-03-16 05:55:08
當(dāng)代陜西(2021年2期)2021-03-29 07:41:24
媽媽寶寶(2017年3期)2017-02-21 01:22:28
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
中國(guó)塑料(2016年3期)2016-06-15 20:30:00
商用汽車(2016年4期)2016-05-09 01:23:12
通信電源技術(shù)(2016年3期)2016-03-26 07:13:38
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
