基于改進決策樹的入侵檢測算法
2014-12-03 08:07:46平寒
山東科學 2014年4期
平寒
(山東職業學院信息工程系,山東濟南250100)
假如有預謀的、潛在的、未經授權的操作信息和訪問信息造成系統無法使用或者使系統不可靠,那么發覺這樣的企圖或行為被定義為入侵檢測[1]。在入侵檢測系統中使用數據挖掘技術已越來越普遍[2],而基于決策樹的數據挖掘技術,其分類檢測模型具有高效、分類準確率高和易于理解等優點,因而備受歡迎。但該技術也存在缺點[3],一是算法效率低;二是訓練集的選取問題,如果超出內存容量將無法運行。
本文嘗試使用基于多變量綜合策略剪枝算法,使算法效率有所提高,同時提高訓練集選取的有效性。
1 基于改進決策樹的入侵檢測算法的設計
1.1 信息增益ID3算法
ID3算法以信息論為基礎,采用劃分后的樣本集的不確定性作為衡量劃分優劣的標準,利用信息熵和信息增益度進行度量。信息增益度越大,不確定性越小。因此,信息增益ID3算法的設計首先要計算每個屬性的信息增益,然后選取信息增益最大的屬性作為測試屬性。
信息增益度ID3算法[4-5]描述的公式如下:
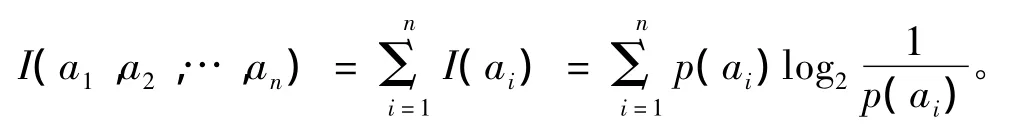
在決策樹分類中,假設S是訓練樣本集合,|S|是訓練樣本數,樣本劃分為n個不同的類C1,C2,…,Cn,這些類的大小分別標記為|C1|,|C2|,…,|Cn|。則任意樣本 S屬于類 Ci的概率[1-2]為
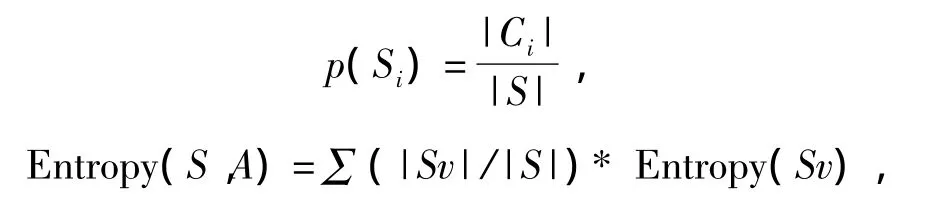
其中,∑是屬性A的所有可能的值,Sv是屬性A有v值的S子集;|Sv|是Sv中元素的個數;|S|是S中元素的個數[4-5]。
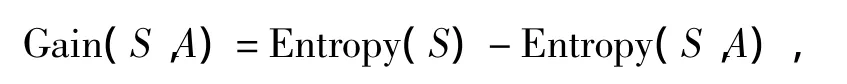
Gain(S,A)是屬性A在集合S上的信息增益。若Gain(S,A)越大,則表明選擇測試屬性對分類提供的信息就會越多[4-5]。
1.2 獨立性檢驗算法[6]
卡方獨立性檢驗用于確定兩個分類變量之間是否存在關系,而本文要研究的是兩種算法結果的關系比較,因此本文在獨立性檢驗之中選擇卡方檢驗。卡方檢驗計算公式[6]為
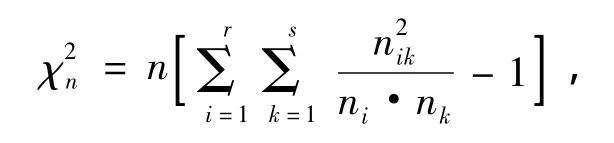
其中,nik代表第i個屬性的第k個屬性值;ni,nk為這一行或列中屬性取值的和,表示的是該屬性與決策屬性的相關性。
1.3 獨立性檢驗與信息熵相結合的分類算法
具體的算法[7]如下:

其中,G(xi)為分類選擇屬性,Gain(xi)表示信息增益的大小。

對所有屬性都運用上式,最后選擇分類選擇屬性G(xi)最大的那個屬性進行分裂。改進的決策樹算法偽代碼如下:

剛剛生成的決策樹由于分類過細,會出現過度擬合現象,使檢測結果下降,而目前避免過度擬合的主要的方法是對決策樹進行剪枝。
2 實驗與性能分析
2.1 KDD CUP99數據集的介紹
本次實驗的數據集采用的是KDD CUP99入侵檢測數據集,該數據集為入侵檢測系統提供統一的性能評價基準,可以仿真各種用戶的類型、模擬各種不同的網絡流量及攻擊手段,使之就像一個真實存在的網絡環境。
每一個網絡連接被標記為Attack(異常)或Normal(正常),Attack(異常)類型被細劃為四個大類,共39種攻擊類型。其中17種Unknown(未知)攻擊類型出現在KDD CUP99(測試數據)集中;22種攻擊類型出現在訓練數據集當中。
2.2 實驗與分析
本算法在Windows 7操作系統實驗平臺、Microsoft Visual Stdio C++6.0環境下實現基于KDD CUP99數據集、采用信息增益與卡方檢驗方法結合的入侵檢測。算法實現主要包括數據集讀入用規格化、采用信息增益結合卡方檢驗方法訓練生成決策樹、采用后剪枝算法對生成的決策樹進行剪枝、測試。
本實驗對數據集的處理采用的是數據文件的形式。實驗數據來自KDD CUP99數據集中的kddcup.data,其大小約為 743 MB,為了使用方便,我們使用 KDD CUP99自帶的 10%的數據集 kddcup.data_10_percent,本文隨機從中提取了6 080個數據。
本文所使用的測試集來自KDD CUP99中的數據集corrected,我們從中提取測試子集,共提取7 009條數據,其中1 009條為攻擊數據。
2.3 訓練過程
具體訓練過程如下:
(1)生成一個決策樹結點,分析當前工作數據表和屬性列表,如果當前決策屬性只有一個值,則該結點為葉結點,其分類為當前屬性列表中決策屬性的值。
(2)如果當前屬性列表中只有決策屬性,則該結點也是葉結點,其分類為當前工作數據表中占多數的決策屬性值。
(3)否則,該結點為中間結點,對工作數據表計算每個屬性的卡方值和信息增益值,然后選擇卡方值與信息增益值之和最大的屬性作為最佳分類屬性,最后以最佳分類屬性標記該結點。
(4)為最佳分類屬性的每個值劃分數據子集、生成一個新的決策樹結點,并生成對應每個最佳屬性值的子工作表和子屬性列表,新生成的結點作為該結點的子結點。
(5)遞歸調用此過程,最終生成決策樹。
具體訓練結果如圖1所示。
其中屬性數42是由41個基本屬性和1個決策屬性所構成。
訓練結果成功地計算出信息增益與卡方值的大小,并以此作為分類建樹的標準,成功地建樹分類,從結果看,完成了建樹的目的,并為測試做了準備。

圖1 訓練過程Fig.1 The training process
2.4 測試過程
當數據訓練結束之后,我們將測試數據集導入,具體測試過程如下:
程序在讀入測試數據集后立刻對測試數據集進行預處理,首先經過對數據集各個數據的完整性檢查清除無效記錄,然后將決策樹根結點的屬性值與測試數據數組相應的屬性值比較決定進入下一個分枝,判斷該節點是否是葉節點,如果該結點是葉結點,則將該結點的分類值與該記錄的分類值比較;再連續的進行此類比較,當全部記錄比較完成后生成統計數據,包括檢出率、誤檢率等數據。而后,對上述數據進行統計分析。將統計信息通過對話框顯示出來。
測試集讀入后屬性輸出結果如圖2所示,檢測結果輸出如圖3所示。
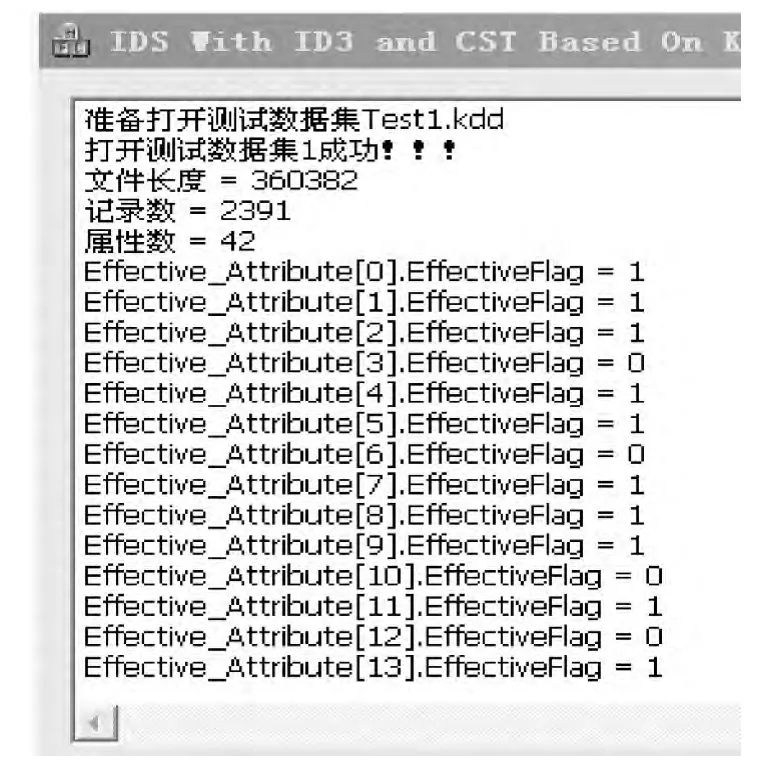
圖2 測試集讀入后屬性輸出結果Fig.2 Attribute output result after test set reading

圖3 檢測結果輸出Fig.3 Detection results output
對數據集2和數據集3的操作同理。經過整理,數據集1,2,3的測試結果如表1所示。

表1 數據集1,2,3的測試結果Table 1 Test results of data set 1,2 and 3
為了對比,將只使用信息熵增益方法的決策樹成樹算法與本文算法相比較,得到結果如表2所示。
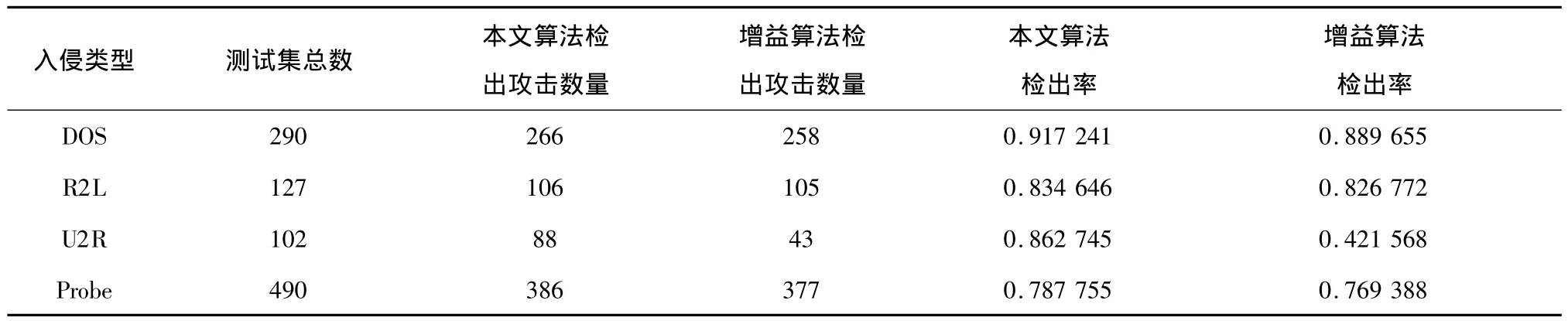
表2 傳統算法與本文算法結果比較Table 2 Result comparison between traditional algorithm and the presented algorithm
由表1和表2可知,本文算法一共檢出846次攻擊,而只基于信息增益算法只檢出783次攻擊,特別是在本算法面對U2R攻擊時,本算法的檢出率比只基于信息增益的方法提高了1倍多,檢測性能更是有了質的提高。
2.5 決策樹的剪枝[8]
(1)用訓練數據集和某一測試數據集對生成的決策樹進行測試,取得測試統計數據,計算未剪枝決策樹的預期分類錯誤率PT值;
(2)遍歷決策樹,一次剪掉找到的一個葉結點,如果剪掉葉結點后,結點t的子結點全部已剪掉,則t為葉結點,t的分類屬性為其數據集中占多數的決策屬性值,計算剪掉一個葉結點后的決策樹預期分類錯誤率PC;
(3)如果 PT≥PC,則結束,生成剪枝后的決策樹,否則PT=Max(PC),遞歸完成剪枝過程。
進行剪枝之后的測試集1的檢測結果如圖4所示。
與未剪枝前的決策樹處理結果(圖3)對比我們可以看到,由于存在著過度擬合現象,導致未剪枝的決策樹的性能比已剪枝的決策樹較差,特別是在誤報率方面,采用本綜合策略剪枝算法生成的決樹與未剪枝決策樹相比有了較大提升。而且對決策樹的剪枝還可以大規模降低整棵樹的復雜性,使所生成決策樹的可用性和性能得到提高。

圖4 進行剪枝之后的測試集1的檢測結果Fig.4 Test results of test set 1 after pruning
2.6 面對未知攻擊時的判斷能力
在訓練集不變的情況下,更改測試集,測試集中的攻擊類型是之前決策樹不曾遇見過的,為了貫徹這一思想,我們選取在訓練集kddcup.data_10_percent數據集中從未出現的一些攻擊類型組成測試集。對未知攻擊的測試結果如圖5所示。
圖5所示的檢出率實際上是攻擊類型的誤檢率,因為這些數據的攻擊類型從未在訓練集中出現,所以我們希望得到的結果是Uknown,而不是上面任何一個具體分類結果,而真正檢測錯誤的數據只有檢測結果為Normal那些數據,由此我們可得到,本文所述算法對上述未知攻擊數據集的檢測率為0.919。
由實驗結果可知,由于訓練集所包含攻擊類型的不完整,本文決策樹在面對未知攻擊時并不能準確地對各類攻擊進行十分準確的分類,有一些數據在攻擊類型的判斷上出現了錯誤,但是可以看到,如果就檢出未知攻擊能力這一點來說,本算法繼承了異常檢測算法對未知攻擊的高分辨能力,對未知攻擊的檢測率還是相對不錯的。
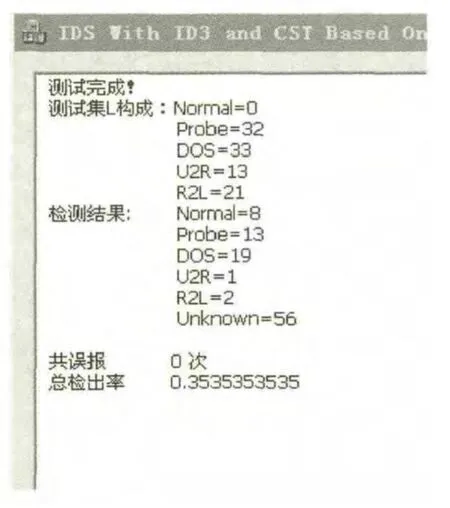
圖5 對未知攻擊的測試結果Fig.5 Test results of unknown attacks
3 結論
本算法對原有單純基于信息熵增益算法進行了改進。實驗證明,該算法可以對已知攻擊進行判斷,取得了較好的預期效果。本算法不但在檢測率和誤檢率上與原算法相比有了較大提高,而且通過結合綜合策略的剪枝算法避免了過度擬合對檢測結果的影響,同時對現有的檢測進行了優化,使檢測結果得到提升。另外,本算法還可以對未知的攻擊進行鑒別,解決了常規算法在異常檢測中的誤報率偏高的問題。從結果來看,本算法與原有算法相比在入侵檢測的性能上得到了大幅度的提高,達到了實驗目的,得到了預期的結果。
[1]JANES P,ANDERSON W.Computer security threat monitoring and surveillance[EB/OL].[2014 -02 -10].http://www.docin.com/p -567457508.html.
[2]LEE W,STOLFO S J,MOK K W.Mining audit data to build intrusion detection models[C]//Proc Conf Knowledge Discovery and Data Mining(KDD'98),1998:66 -72.
[3]LIU H,HUSSAIN F,TAN C L.Discretization:An enabling technique[J].Data Mining and Knowledge Discovery,2002,6(4):393-423.
[4]孫超利,張繼福 . 基于屬性-值對的信息增益優化算法[J].太原科技大學學報,2005,26(3):199-202.
[5]張春麗,張磊.一種基于修正信息增益的ID3算法[J].計算機工程與科學,2008,30(11):46-47.
[6]葉慈南,曹偉麗.應用數理統計[M].北京:機械工業出版社,2009.
[7]孔祥南,黎銘,姜遠,等.一種針對弱標記的直推式多標記分類方法[J].計算機研究與發展,2010,47(8):1392-1399.
[8]鐘慧玲,章夢,石永強,等.基于剪枝策略的改進TDCALT算法[J],同濟大學學報:自然科學版,2012,40(8):1197-1203.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
