融合形態特征的最大熵維吾爾語詞性標注
2015-01-01 03:14:24帕力旦吐爾遜房鼎益
西北大學學報(自然科學版) 2015年5期
帕力旦·吐爾遜,房鼎益
(1.西北大學信息學院,陜西 西安 710127;2.新疆大學軟件學院,新疆 烏魯木齊 830046)
詞性標注(Part-of-Speech Tagging)是詞法分析的一個重要部分,主要目的是給句中每一個詞賦以正確的分類標記。詞性標注的難點是如何正確判斷兼類詞的詞性以及對生詞詞類的判別。
目前詞性標注的方法有基于統計及基于規則的方法。最早提出的是基于規則的一種方法,主要是詞類消歧規則[3]的建立要依據兼類詞之間的搭配情況,在考慮語境以及上下文的含義。由于應用的范圍廣,要求高,被標注的語料的規模也會增大,原來的人工的方法提取規則雖然有其一定的優點,但是也有很大的缺點,同時浪費了時間和精力,再加上在不同的領域詞性標注系統的要求都不一樣,針對各種語言標注系統也不可通用,基于以上種種原因,在對大規模語料進行處理時我們選擇了另一種標注方法,也就是基于統計方法來進行詞性標注,這個方法克服了前一種方法的缺點,也可以進行移植,現在也成為了包括經英語和漢語在內的一些語言進行詞性標注方面研究的一種常用的方法,而且這個方法的效果也是令人滿意的。
維吾爾文的詞性標注的研究方面開展得比較晚一些,而且最開始大家都使用了基于詞典的方法以及基于規則的一種方法[4-6],同時也使用了基于N-gram的HMM模型[7],盡管它們的效果也都比較好,但在處理維吾爾文等黏著型的語言時也有一定的問題,由于維吾爾語在融入語言知識上有一定的不足,因此在使用它時就受到了一定的局限。在維吾爾語的詞性標注研究時遇到的一個很大的難點就是該語言的詞形變化十分豐富,舉例來說,如果在一個詞干的后面加上不同詞綴的附加成分,那么這個單詞就可以構成不同的單詞。采用上述方法盡管取得了較好的成績,但仍然有大量的未登錄詞無法避免,而且也使得維吾爾文的詞性標注出現了更加嚴重歧義的現象,如果不能使用足夠的特征信息來進行處理,就會對兼類詞消歧產生很大的影響,并且也會在對未知詞進行標注時影響它的詞性標注的準確度,一般采用猜測的方法對上述模型中未登錄詞的詞性進行標注。
本文充分利用維吾爾文形態特征建立了一個基于最大熵理論的維吾爾文詞性標注模型,由于最大熵模型使用的特征豐富,而且充分利用了上下文的信息,因此它的概率分布在給定的約束條件之下可以達到與訓練數據大致一致,同時也因為選擇并使用了一些豐富的上下文信息,就使得在對未登錄詞的詞性標注進行預測時結果也非常理想[8-10]。通過對實驗的結果進行分析,最后證明在對維吾爾文兼類詞進行消歧以及對未知詞的詞性進行標注時,使用最大熵模型對其進行預測就能夠得到較滿意的效果,而且該方法取得的標注的效果也會優于其他方法。
1 維吾爾文詞性標注
1.1 維吾爾語詞類分析
維吾爾文按照詞的大的類型來劃分,則可以將其分為實詞、虛詞、感嘆詞等類型,如果對其中的實詞再細分還能分成動詞、靜詞兩種,其中靜詞還可分成副詞、數詞、名詞、形容詞、量詞、代詞、擬聲詞等幾種類型;虛詞還可分成語氣詞、連詞、后置詞等幾種類型。實詞中包含的分類有形態的變化并可以表達意義,虛詞詞類則沒有形態變化[11]。維吾爾語靜詞的不同詞綴有65個,其中形容詞的不同詞綴有55個,名詞的不同詞綴49個,數詞的不同詞綴57個,動詞有150多個不同詞綴。維吾爾文實詞詞綴的各種組合中靜詞總計可達1 502種,動詞可達1 500種。而實際上語料庫卻只有368種組合方式。
1.2 維吾爾語詞性標記集
維吾爾語沒有一個統一詞性標記集的規范,新疆多語種信息技術重點實驗室[7]和新疆師范大學[5]的標注規范有自己的標準。本文采用的維吾爾文詞性標注標記集是新疆多語種信息技術重點實驗室采用的。該標記集在對英文、中文詞性標注標記集參考的基礎上,在維吾爾文原有12個基本詞類的基礎上(表1),制定的詞性標注規范[7]中具有一級標記集15個,二級標記集71個,三級標記集51個。本文進行建模與實驗時采用一級標記集是由于語料庫規模不大。

表1 新疆多語種信息技術重點實驗室維吾爾語詞性一級標記集Tab.1 First level POS tagging set proposed by the key laboratory of multilingual information technology in Xinjiang
1.3 詞性標注難點
維吾爾語形態會有變化,所以需要考慮詞性標注前是否需要對維吾爾語單詞進行形態分析的問題。若對單詞不進行詞干提取的話,則詞性標注時同一個單詞的不同變體被系統認為不同的單詞,大量的未登錄詞可能會出現;若對單詞進行詞干提取的話,雖然在一定程度上減小了數據稀疏的問題,但是同時卻又增大歧義現象的可能。例如:
(拉丁文轉寫):m?ning ?timbek oruq,hazirche beygige yarimaydu,s?ning?tingniat beygisge qatnashturup baqsaq qandaq?
(翻譯成):我的馬太瘦了,現在還不能參加賽馬,你的馬參加一下如何?
“馬”這個單詞在以上的句子中出現了3次,每一次都是不一樣的形態。若訓練庫中只有?tim和at的形式,而?tingni(你的馬)形式卻沒有,則模型將?tingni判斷為未登錄詞,實際上該單詞的詞干形式已在訓練庫有了,由于單詞形態的變化使得已有詞被識別為未登錄詞的現象產生。即便如此,對單詞進行詞干提取后也可能有更多的歧義產生。比如,單詞at在以上句子中的還有“射擊”的意思,是動詞,對?tim詞干提取之后,at就有了歧義。若利用當前連接的詞綴模型或規則就能確定當前詞干at不是動詞而是個名詞。另外,詞性轉移概率一定程度上受在訓練語料庫中的形態影響。文獻[7]中基于HMM的詞性標注方法的研究中就遇到了該問題。HMM模型不能利用有利于歧義消除或未登錄詞預測的特征信息而只能用發射概率、單詞的前后搭配出現概率等。故本文建立維吾爾語統計詞性標注模型時采用最大熵模型。
近幾十年來研究者研究了基于支持向量機、隱馬爾科夫、條件隨機場、最大熵等模型的詞性標注工作[1]。由于最大熵模型可以和自然語言模型很好地匹配,還能對多類約束信息進行融合,因此在用其進行詞性標注研究時效果較好。在英語的詞性標注中使用最大熵方法其準確率達到了97%以上,已和人工標注的準確度[2]相似。
2 基于最大熵的維吾爾文詞性標注模型
2.1 最大熵的模型及原理
自然語言處理的方法中最大熵模型經常被使用[8]。可以將它應用到自然語言處理里的詞性標注、分詞、詞義排歧、文本分類、機器翻譯等方面。
首先建立一個隨機過程的模型p,把自然語言看作隨機過程,p∈P;輸出值的集合為Y,y∈Y;上下文集合X,x∈X;N個樣本的集合S={(x1,y1),(x2,y2),…,(xN,yN)},(xi,yi)是對一個事件的觀察,事件空間為X×Y;用特征表示語言知識,特征為一個2值函數f:X×Y→{0,1}。
模型p的熵

其中C是滿足約束條件的模型集合,接下來就要在C中尋找具有下面形式的p*
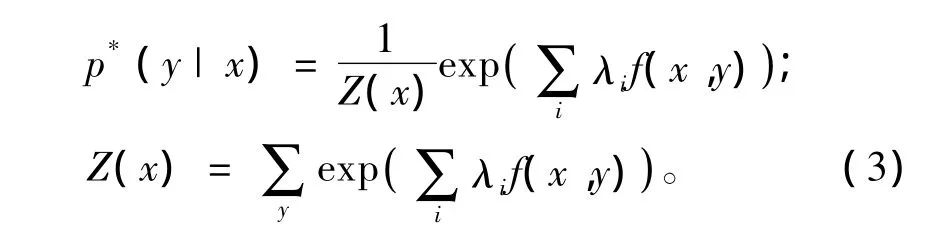
式中Z(x)是模型的參數,表示一個歸一化常量。
也可以將它看作是特征的權值,而權值的大小則由λi每個特征的貢獻來決定。
2.2 特征選擇方法
模型中針對問題選取特征集合[8]是最大熵模型的關鍵。將復雜的語言現象轉化為簡單的特征表示。使用最大熵模型構建序列對模型進行標注,即標注結果y是根據x的上下文特征來確定的,由此可見合適的特征集合的建立十分重要。本文中建立維吾爾文詞性標注模型的特征集合的方法:
1)常規特征:詞的詞性和它的上下文環境有很大關系,故判斷當前詞的詞性時應當考慮這個詞w的前n個詞及后m個詞的含義及其他信息。
2)維吾爾文中構詞的特點:維吾爾語是黏著型的語言,屬于阿爾泰語系突厥語族,其他如蒙古語、滿語、土耳其語、日語、韓語、匈牙利語、芬蘭語、泰米爾語均屬于黏著型語言。它的特點是時態的變化可以通過在單詞的詞尾加上各類詞綴來實現。
維吾爾文詞語在結構上分為詞根和詞干兩部分,詞根不可再分,為最小的語義單位。幾個詞根連接在一起,或者詞根和詞綴連接在一起就組成了詞干。例如:詞根為 ish(事宜,事情,職業,事),通過這個詞根后面連接構詞詞綴chi,可以得到詞干ish+chi=ishchi(工人)。在維吾爾文文本中的單詞一般由詞干和連接詞尾的幾個構形詞綴來表達句中的語法功能。例如:ishchi(工人)+ning(構形詞綴)=ishchining(工人的)。
經新疆多語種信息技術重點實驗室的《維吾爾語百萬詞詞法標注語料庫》進行統計得知,平均每條句子中出現形態變化的單詞約有66.54%,句子中單詞連接兩個以上詞綴的詞匯有37.39%。因此,對維吾爾文詞性標注模型而言,詞干是能夠有效減小數據稀疏問題的重要信息,構形詞綴是有利于消除歧義及識別未登錄詞詞類的重要線索之一。
2.3 特征模板定義
本文中,文獻[8-9]是在詞性標注模型特征模板的基礎上,根據維吾爾文的構詞特點,設計了維吾爾文詞的內部特征、前后依存特征及混合特征。
2.3.1 維吾爾文詞內部特征 詞干和詞綴信息統稱詞內部特征。在維吾爾文文本中的單詞一般由詞干和連接詞尾的幾個構形詞綴來表達句中的語法功能。本文設計的詞內部特征模板如下:
1)詞干信息
維吾爾語中詞干附加構形詞綴原詞干的詞性不變,只是表達語法功能,所以對句子中的單詞進行詞干提取不影響詞干詞性的識別。例如:kitab(書)+ta(構形詞綴)=kitabta(書上),所以句子中只考慮kitab的詞性就可以,特征函數定義為

2)詞綴信息
作為黏著語言,維吾爾語有豐富的形態變化,名詞有49個詞綴,數詞有57個詞綴,形容詞詞綴有55個,動詞詞綴有150多個。不同組合數可以達到3 002種,動詞詞綴超過1 500種,但在實際語料庫中出現的有368種組合方式。詞綴的主要作用是表達語法功能,在句中什么位置連接什么樣的詞綴,要看具體的上下文。因此,詞綴在識別未登錄詞詞性和排除兼類詞詞性時能夠提供線索。例如,at是兼類詞,詞類是名詞和動詞,at+ing=?ting(你的馬),根據詞綴ing就可以判斷當前詞類是名詞,at+ma=atma(不要射擊)就可以判斷當前詞類是動詞。特征函數定義為

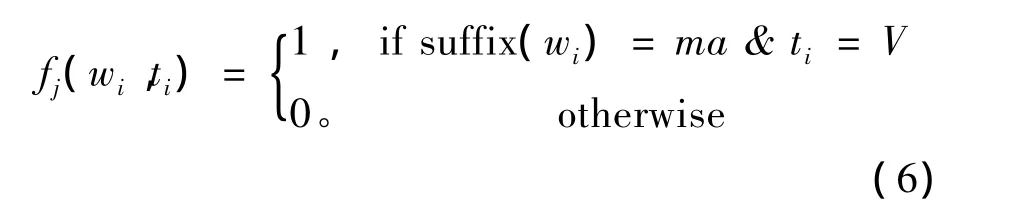

表2 詞內部信息特征模板Tab.2 Inner word information feature template
2.3.2 前后依存特征 前后依存詞特征指的是與句子中的當前詞聯系緊密的詞之間的關系,對于兼類詞可以根據前后依存詞的相關信息予以解決。例如,句子1:“men dora yeyishni untup qaptimen.(我忘了吃藥。)”;句子2:“sen meni dorima.(你不要模仿 我。)”。單詞dora有藥品、模仿等意思,可以看作名詞或動詞。消歧處理時可以利用其前后詞的詞類特征來進行。

表3 前后依存詞信息特征模板Tab.3 Word context information feature template
2.3.3 混合特征 就是混合當前詞的詞干、詞綴、前驅詞的詞干、詞綴、后續詞的詞干、詞綴等特征信息,混合信息特征定義如表5所示。

表4 混合信息特征模板Tab.4 Mixed information feature template
3 分析實驗結果
3.1 維吾爾語語料庫
本文的實驗使用的語料庫是較為權威的,新疆多語種信息技術重點實驗室的《維吾爾語百萬詞詞法標注語料庫》,該語料庫包含詞性標注,詞干、詞綴等信息,選用的規模為60 041條句子、詞次1 119 565,不重復的詞匯為98 941條,詞干為42 258,平均每條句子中出現形態變化的單詞約有66.54%,句子中單詞連接兩個以上詞綴的詞匯有37.39%,其中兼類單詞詞干1 848條、出現頻率為16 347次。

表5 實驗數據Tab.5 The experimental data
因為語料庫主要包括文學、醫學、農業、法律、新聞等內容,領域覆蓋度并不高,所以本文中對句子進行了隨機抽取,其構成如表6所示。可看出,各種詞性在訓練語料庫和測試語料庫中分布均勻。形容詞、動詞、名詞、標點符號稍多一些。

表6 訓練和測試語料庫詳細統計Tab.6 Detailed statistics on training and testing corpus
一般詞性標注準確度是評價標注結果的有效數據,其定義如下

3.2 實驗設置及結果分析
在本文中,采用SharpNLP的MaxEnt工具包進行實現最大熵模型,采用新疆大學多語種信息技術開發的XJUNLP基于N元語法的HMM模型進行對比分析。由前所述,對各種不同組合的特征進行實驗,選出最適合于維吾爾文詞性標注的特征組合。表3作為基本特征組合使用,用T1表示。
采用常用的詞依存特征進行實驗,準確度達到了94.21%,以此為基準。實驗2、實驗3、實驗4、實驗5、實驗6等加入了詞干特征,隨著增加上下文詞干特征,提高了模型準確度。分析結果可得當前單詞之前單詞詞干、當前單詞詞干及后一個單詞詞干特征對準確度貢獻較高。為了測試詞綴對模型的影響,實驗7加入了當前詞的詞綴特征,準確度比基準系統提高了0.47%。實驗8中加入了連續兩個詞綴的混合特征,模型性能得到了明顯的提高。該特征證明了維吾爾文詞綴表達語法功能的說法,大部分詞綴根據前一個單詞詞綴進行連接。例如,menging kitabim(我的書),ing(的格詞綴),im(人稱詞綴),前一個詞綴ing要求一定要連接一個人稱詞綴,而人稱詞綴只能附加到名詞。根據實驗5和實驗8的結果,設置了實驗9和實驗10。分析結果可得,當前單詞的前綴和后綴、前一個單詞詞綴和當前單詞詞綴及后一個單詞詞綴等特征對模型準確貢獻較大。
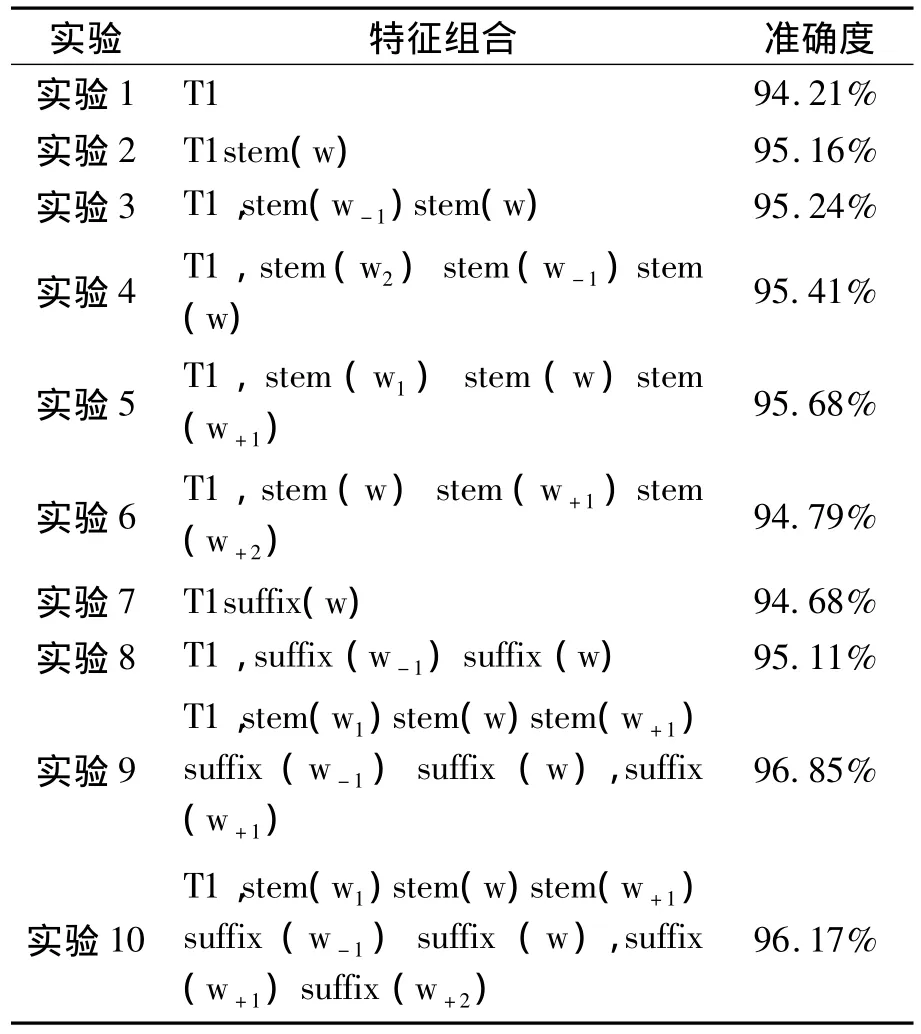
表7 實驗結果Tab.7 The experimental data
為了對比HMM模型與最大熵模型的性能,采用相同的語料庫進行了實驗,實驗結果如表8所示。

表8 HMM與最大熵對比實驗結果Tab.8 Comparative experimental results of HMM and maximum entropy method
從實驗結果可看出,最大熵模型能夠較好地處理名詞、動詞、形容詞等類,同時能夠較高地識別未登錄詞。
3.3 錯誤分析
經過對錯誤數據分析得出,主要錯誤是名詞、形容詞被標注為動詞的情況比較多,占32.8%;還有名動詞、形動詞、副動詞等被標注為名詞、形容詞、副詞的情況較多,占27.6%。
另外,實驗中出現的普通外國人名和漢族人名對系統的性能產生的正確率下降為12%左右。根據對錯誤進行分析發現,除了句子頭部出現的外國人名、漢族人名以及一個詞的外國人名(只用名的情況,例如奧巴馬,而不是巴拉克·奧巴馬)以外的其他人名基本上給予錯誤的標注。因為外國人或漢族人的姓名中間有空格或”?”,一般出現連續兩個或3個人名,這嚴重地削弱上下文信息量。例如:
Junggo xelq tashqi dostluq jem'iyitining bashliqi①ch?n xawsu,afghanistan diplomatiye ministirlikining muaw?n ministiri ②muhemmed kabir falahi ziyapetke qatnashti hemde tebrik s?zi qildi.
以上句子中,用①標注的是漢族人名,按照維吾爾語的正字法,漢族人的姓和名之間留一個空格,所以在這個位置出現連續兩個未登錄詞。用②標注的是阿富汗外交部副部長的姓名,由3個單詞組成,除了第一個名詞“muhemmed”以外,連續出現的其他兩個人名均是未登錄詞。
4 總結與展望
本文介紹了維吾爾文融合語言特征的最大熵詞性標注的研究工作,其亮點在于最大熵模型特征的選擇上,根據維吾爾文的形態特征特點,選取當前詞詞干、詞綴等混合形態特征信息,構建了基于最大熵的維吾爾文詞性標注系統。分析實驗結果發現最大熵適合于構建維吾爾文詞性標注序列標注模型,通過融合多種特征,能夠顯著提高標注準確率。在本文實驗中準確度達到了96.85%,準確度比原基準系統提高了2.64%。由于所使用語料規模和覆蓋面還需進一步提高,因此所做詞性標注的整體效果也受到一定影響。在以后的工作中,繼續擴建標注語料庫,進一步考慮融合詞典和規則,把無歧義的感嘆詞、量詞、數字表達式等通過規則或詞典進行標注,然后把這個結果融入到模型,從而提高模型的魯棒性。
[1] 宗成慶.統計自然語言處理[M].北京:清華大學出版社,2008.
[2] 張貫虹,斯·勞格勞,烏達巴拉.融合形態特征的最大熵蒙古文詞性標注模型[J].計算機研究與發展,2011,48(12):2385-2390.
[3] 劉開瑛.中文文本自動分詞和標注[M].北京:商務印書館,2000.
[4] 吐爾根·依布拉音,阿里甫·庫爾班,阿不都熱依木.基于詞典的現代維吾爾語詞性自動標注系統的研究[C].北京:中文信息處理會議,2006年10月.
[5] 玉素甫·艾白都拉,張海軍,艾孜爾古麗.信息處理用現代維吾爾語詞干詞類標記集研究[J].信息技術與標準化,2011(6):45-481.
[6] 吐爾根·依布拉音,阿里甫·庫爾班.基于規則的維吾爾語詞性自動標注系統的研究[C].合肥:第二屆全國少數民族青年自然語言處理學術研討會,2008:210-214.
[7] 買合木提·買買提,吐爾根·依布拉音.基于N-gram的維吾爾語詞性自動標注系統的研究[C].合肥:第二屆全國少數民族青年自然語言處理學術研討會,2008:206-209.
[8] ADWAIT R.A maximum entropy model of part-ofspeech tagging[C].Proceedings of the Conference on Empirical Method in Natural Language Proeessing,1996,1:133-142.
[9] 張磊.基于最大熵模型的漢語詞性標注研究[D].大連:大連理工大學,2008.
[10]趙巖,王曉龍,劉秉權,等.融合聚類觸發對特征的最大熵詞性標注模型[J].計算機研究與發展,2006,43(2):268-274.
[11]哈密提·鐵木爾.現代維吾爾語語法[M].北京:民族出版社,1987.
猜你喜歡
紅河學院學報(2021年4期)2021-11-19 08:59:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
西夏研究(2017年1期)2017-07-10 08:16:55
語言與翻譯(2014年3期)2014-07-12 10:31:56
河南科技(2014年23期)2014-02-27 14:19:15
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
