固態(tài)硬盤混合存儲數(shù)據(jù)庫的數(shù)據(jù)分布優(yōu)化算法
2015-01-02 02:00:52周世民柴云鵬
計算機工程 2015年4期
周世民,柴云鵬,王 良,王 鑫
(1.中國人民大學a.數(shù)據(jù)工程與知識工程教育部重點實驗室;b.信息學院,北京100872;2.天津大學計算機科學與技術學院,天津300072)
1 概述
聯(lián)機事務處理(On-line Transaction Processing,OLTP)數(shù)據(jù)庫在IT系統(tǒng)中占有非常重要的地位,很多應用系統(tǒng)大多離不開數(shù)據(jù)庫,系統(tǒng)整體性能往往也由數(shù)據(jù)庫的性能所制約。因此,提升數(shù)據(jù)庫的性能具有非常重要的意義。傳統(tǒng)數(shù)據(jù)庫一般基于磁盤,磁盤具有穩(wěn)定、非易失、大容量、成本低等優(yōu)點,但主要的問題是訪問速度比較慢,因此不利于構造高性能的數(shù)據(jù)庫。
近年來,閃存存儲得到長足發(fā)展,不僅容量迅速增大,而且制造成本也逐漸降低,目前已經(jīng)以固態(tài)硬盤(Solid State Drive,SSD)的形式進入了很多實際的存儲系統(tǒng)中,獲得實際的應用。但SSD的成本目前仍然比磁盤高很多,因此目前多和磁盤構成混合存儲,這樣既能提升系統(tǒng)性能,又能用較低的成本得到很大的存儲容量。基于SSD-磁盤混合存儲來構造OLTP數(shù)據(jù)庫系統(tǒng)是一種提升數(shù)據(jù)庫性能的有效方法。
OLTP數(shù)據(jù)庫要處理大量的交易請求,既需要大量的查詢等讀操作,同時也需要更新表和索引,有大量的隨機寫操作。在存儲層引入SSD,尤其是用來存儲一些訪問頻繁的數(shù)據(jù),能夠充分利用SSD的訪問性能明顯高于磁盤的優(yōu)點,尤其是對于隨機讀寫操作,從而提升OLTP數(shù)據(jù)整體的性能和服務能力。
但各種應用情況下數(shù)據(jù)庫中數(shù)據(jù)特征、訪問特征都有很大差別,數(shù)據(jù)庫不可能出廠時就確定一種普適的、面向混合存儲的數(shù)據(jù)分布優(yōu)化策略,最理想的情況就是在運行時能夠自適應,根據(jù)應用特征自動調(diào)節(jié)數(shù)據(jù)分布。
本文提出一種面向混合存儲的OLTP數(shù)據(jù)庫數(shù)據(jù)分布自適應優(yōu)化算法,可自動適應應用的特征,并通過觀測判斷各個數(shù)據(jù)元素的性能,從而在SSD和磁盤之間自動形成理想的數(shù)據(jù)分布。
2 相關工作
2.1 閃存和固態(tài)硬盤
隨著閃存在容量上的迅速增長和成本的降低,以閃存作為存儲介質(zhì)的新型固態(tài)硬盤已經(jīng)在企業(yè)得到實際的應用。SSD最大的優(yōu)點就是隨機讀寫性能高,較普通磁盤的讀寫性能要高出1個~3個數(shù)量級[1],其中隨機讀性能比隨機寫性能更好。對于連續(xù)讀寫操作,SSD較普通磁盤高出2倍~4倍[2]。
SSD的隨機和連續(xù)的讀性能都比相應的寫性能要高,這個特性稱為讀寫不平衡[3],這不同于磁盤的讀寫性能平衡的特性,在一些情況下可能帶來不利的影響。比如數(shù)據(jù)從一塊SSD讀出并寫入另一塊SSD,那么由于讀性能高于寫性能,讀操作就必須等待寫操作。
SSD的另一個缺點是不支持寫覆蓋[3],和磁盤不同,SSD無法直接重用已經(jīng)寫入數(shù)據(jù)的存儲單元,只有先進行擦除操作后才能執(zhí)行下次的寫操作。而且,對于每塊存儲單元,允許擦除的總次數(shù)是存在上限的,即SSD的使用壽命有限。在SSD內(nèi)部,如果部分存儲單元頻繁的執(zhí)行擦除寫入操作,相應的存儲芯片就很容易出現(xiàn)擦寫壽命耗盡,從而變?yōu)閴膲K的問題,從而導致SSD無法使用。目前主流SSD中閃存芯片的每個單元只能擦除5 000次~10 000次[4-5]。
2.2 OLTP數(shù)據(jù)庫和性能測試
數(shù)據(jù)庫產(chǎn)品一般可以簡單分為聯(lián)機事務處理(OLTP)和聯(lián)機分析處理(On-line Analytical Processing,OLAP)兩大類。OLTP是傳統(tǒng)關系型數(shù)據(jù)庫的主要應用形式,例如銀行交易等。OLTP數(shù)據(jù)庫對性能要求非常高,因此引入基于SSD的混合存儲能夠有效緩解I/O瓶頸,提升OLTP數(shù)據(jù)庫的性能。
針對OLTP數(shù)據(jù)的性能測試,一般都采用數(shù)據(jù)庫性能委員會發(fā)布的TPC-C測試[10]。TPC-C模擬了一個比較復雜并具有代表意義的OLTP應用環(huán)境:一個大型的商品批發(fā)銷售公司,它擁有若干個分布在不同區(qū)域的商品倉庫。當業(yè)務擴展時,公司將添加新的倉庫。每個倉庫負責為10個銷售點供貨,其中每個銷售點為3 00個客戶提供服務,每個客戶提交的訂單中,平均每個訂單有10項產(chǎn)品,所有訂單中約1%的產(chǎn)品在其直接所屬的倉庫中沒有存貨,必須由其他區(qū)域的倉庫來供貨。同時,每個倉庫都要維護公司銷售的100 000種商品的庫存記錄。
2.3 基于SSD的混合存儲
盡管SSD在性能等方面有明顯的優(yōu)勢,但由于其價格相對較高,而且具有擦除壽命的限制,因此一般企業(yè)還是多以混合存儲的形式使用SSD,即由SSD和HDD來構成混合存儲。具體混合的方式分為兩大類:(1)SSD作為內(nèi)存之下的二級緩存;(2)SSD代替部分磁盤,負責存儲一部分數(shù)據(jù)。
由于SSD緩存接入系統(tǒng)就可以直接使用,不需要對原有系統(tǒng)進行修改,因此現(xiàn)在基于這種結(jié)構的技術比較多,包括:EMC 的 FAST Cache[6],Intel的Turbo Memory[7],Solaris ZFS 文件系統(tǒng)中 L2ARC 算法管理的閃存緩存[8],以及Oracle數(shù)據(jù)庫中的智能閃存緩存[9]等。但是SSD緩存的主要挑戰(zhàn)是SSD的寫入量太大,容易導致SSD較短時間就報廢。SSD代替部分磁盤構成混合存儲的方案如果設計合理,可以避免寫入量過大的問題,也能夠得到更好的性能加速,也是本文所關注的方案。
3 自適應優(yōu)化算法
3.1 數(shù)據(jù)分布自適應優(yōu)化算法
圖1給出了數(shù)據(jù)分布自適應優(yōu)化算法的流程,算法周期性執(zhí)行,每個周期中分為觀測、決策、數(shù)據(jù)遷移幾個主要步驟。

圖1 數(shù)據(jù)分布自適應優(yōu)化分布算法流程
首先經(jīng)過較長時間的觀測期,算法會記錄每個表和索引的訪問特征,以便進行后續(xù)的決策。在決策步驟中,會根據(jù)SSD的空間,以及各個表和索引的訪問特征對其進行排序,排序方法由具體的決策策略決定。在決策之后,算法會判斷是否需要執(zhí)行數(shù)據(jù)遷移方案:如果是第一次決策,SSD還是空白狀態(tài),或者此次決策方案和目前SSD中存儲的數(shù)據(jù)差異較大,則執(zhí)行數(shù)據(jù)遷移;否則不執(zhí)行,此周期結(jié)束。如果需要執(zhí)行數(shù)據(jù)遷移,則目標是將決策中排序最前面的若干個表和索引存入SSD中,直至SSD空間基本被占滿。
3.2 混合存儲優(yōu)化策略
自適應數(shù)據(jù)分布優(yōu)化算法框架中,數(shù)據(jù)分布決策部分是整個算法的核心。但實際上算法框架可以支持多種決策策略,每種策略有自己的特點,可以在不同環(huán)境下選擇不同的策略。
(1)I/O吞吐量優(yōu)先策略
SSD的數(shù)據(jù)訪問性能全面高于磁盤。當把SSD和磁盤組成混合存儲時,SSD應該承擔更多的I/O訪問,這樣才能充分發(fā)揮SSD的性能優(yōu)勢;但是SSD的空間有限,因此SSD中單位容量的數(shù)據(jù)應該承擔更多的I/O數(shù)據(jù)訪問。具體來說,數(shù)據(jù)庫中表和索引的按照rw/space因子進行排序,rw/space因子的含義是某個數(shù)據(jù)元素(表或索引)單位存儲空間數(shù)據(jù)的讀寫總量的貢獻值。
(2)I/O次數(shù)優(yōu)先策略
由于SSD相對于磁盤在隨機讀、寫方面的性能優(yōu)勢更為明顯,因此應該將小塊數(shù)據(jù)的隨機讀寫請求更多的數(shù)據(jù)元素存儲的SSD上。如果將盡可能多的I/O次數(shù)放到SSD上,那么很多小塊數(shù)據(jù)的隨機訪問都將由SSD承擔,而磁盤則承擔自己比較擅長的連續(xù)讀寫,即使訪問的數(shù)據(jù)量較大,性能相對也會比較高。因此,本文提出的I/O次數(shù)優(yōu)先策略按照io/space因子對所有表和索引進行排序。io指每秒鐘完成的I/O請求次數(shù),它反映的是數(shù)據(jù)I/O訪問的頻繁程度。io/space因子的含義是某個數(shù)據(jù)元素單位空間的數(shù)據(jù)對訪問次數(shù)的貢獻值。
4 實驗結(jié)果與分析
4.1 實驗環(huán)境
OLTP數(shù)據(jù)庫的性能測試一般采用國際標準的TPC-C測試(見2.3節(jié)的介紹),因此本文采用TPCC測試來進行數(shù)據(jù)分布自適應優(yōu)化算法的實驗。實驗中生成的TPC-C測試數(shù)據(jù)總量約為13 GB,其中所涉及的9個表和11個索引,它們各自所占空間如表1所示。

表1 TPC-C測試中表元素和索引元素所占空間
為進行準確的測試,在服務器上搭建了完整的實驗環(huán)境。服務器為HP Proliant DL380,其中包括Intel Xeon E5-2609 CPU 2.40 GHz、16 GB 內(nèi)存、4 塊SAS 1 TB 7200RPM構成的RAID5磁盤陣列,以及1塊三星的128 GB SSD。
數(shù)據(jù)庫軟件采用開源的PostgreSQL,PostgreSQL是當前最流行的對象關系型數(shù)據(jù)庫之一,主要用于OLTP應用。其主要特點是開源、功能完備、高可擴展性、可編程性強等[11]。而TPC-C測試工具采用開源的 BenchmarkSQL[12]。
4.2 性能測試
本部分在上述實驗環(huán)境中應用本文提出的數(shù)據(jù)分布自適應優(yōu)化算法,分別測量了以下2種優(yōu)化策略的性能。性能指標采用了TPC-C測試中常用的tpmC指標,即平均每分鐘可以完成多少次事務處理。
(1)I/O吞吐量優(yōu)先策略
I/O吞吐量優(yōu)先策略在觀測階段會按照數(shù)據(jù)元素單位存儲空間的讀寫訪問總量對所有數(shù)據(jù)元素進行排序,并優(yōu)先選擇排名靠前的數(shù)據(jù)元素進入SSD存儲,TPC-C測試實驗中排名前10位的數(shù)據(jù)元素如表2所示。

表2 I/O吞吐量優(yōu)先策略對數(shù)據(jù)元素的排序
基于表2的結(jié)果,圖2給出了不同SSD大小的情況下,整個數(shù)據(jù)庫系統(tǒng)的tpmC值,即性能情況。由圖2可知,隨著混合存儲中SSD空間占總空間比重的增大,數(shù)據(jù)庫系統(tǒng)的性能提升非常明顯,基本上是線性增加。其中當SSD空間占混合存儲總空間的比例約為40%左右時,性能提升更為迅速。

圖2 OLTP數(shù)據(jù)庫性能隨SSD空間增長的變化曲線1
值得注意的是SSD空間比例在40%附近經(jīng)歷一個性能快速上升的階段后,有一個性能短暫下降的過程。其原因主要是增大SSD空間存儲更多內(nèi)容時,按照本文方案,SSD中新增內(nèi)容的熱度比之前有所下降;但新增數(shù)據(jù)卻要搶占有限的SSD訪問帶寬。由于新增數(shù)據(jù)熱度和之前SSD中數(shù)據(jù)相差較大,因此導致性能有短暫的下降。
(2)I/O次數(shù)優(yōu)先策略
相對于前一種策略,I/O次數(shù)優(yōu)先策略更傾向于把小塊數(shù)據(jù)的隨機訪問定向到混合存儲中的SSD,獲得更好的性能提升。在算法的觀測階段,I/O次數(shù)優(yōu)先策略會以數(shù)據(jù)元素單位存儲空間的讀寫I/O總次數(shù)來作為排序標準。觀測結(jié)果如表3所示,其中,IO/space為單位存儲空間每小時的 IO次數(shù)。
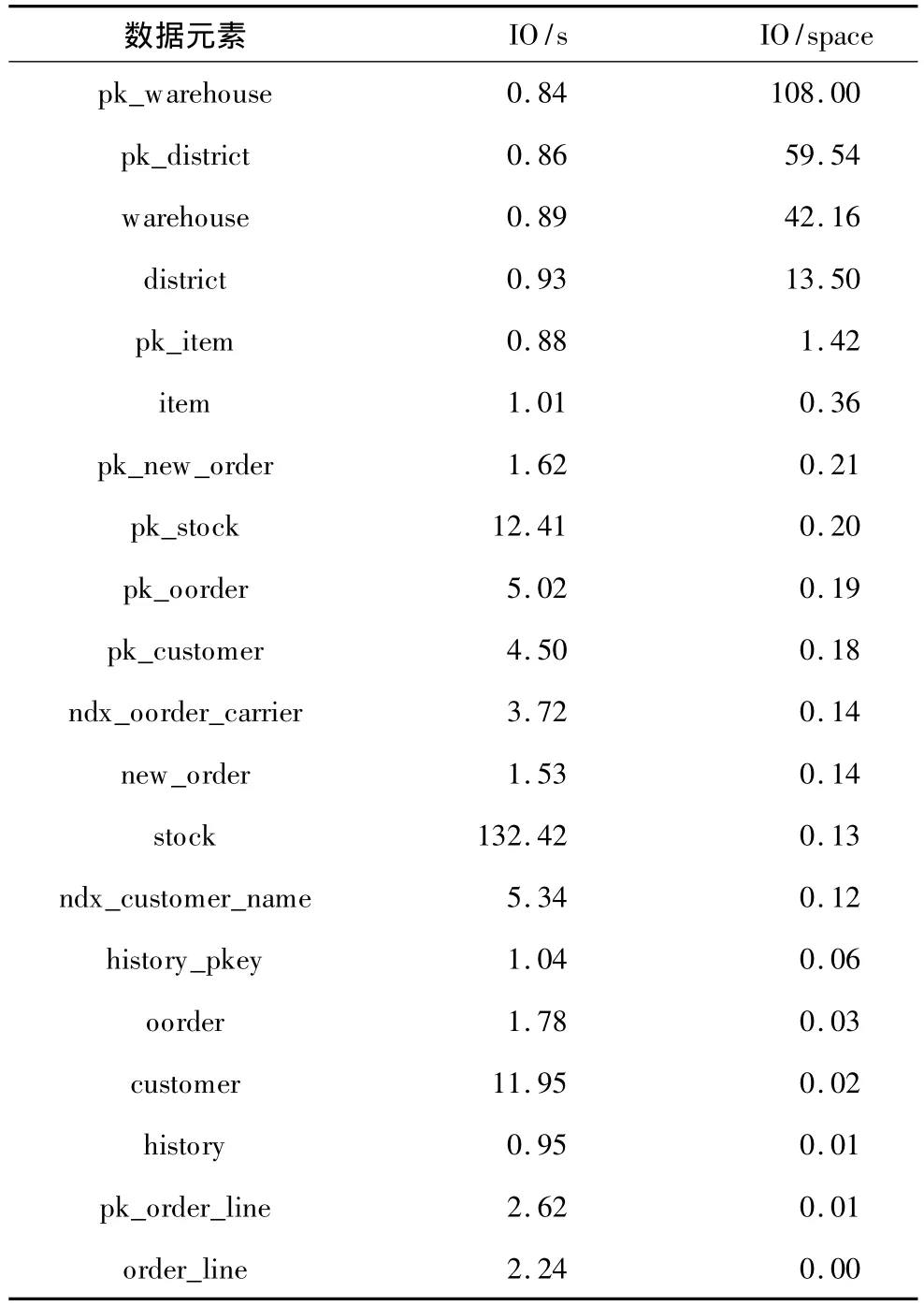
表3 I/O次數(shù)優(yōu)先策略對數(shù)據(jù)元素的排序
基于表3的決策結(jié)果,圖3給出了不同SSD大小的情況下,整個數(shù)據(jù)庫系統(tǒng)的tpmC值。由圖3可知,I/O次數(shù)優(yōu)先策略的規(guī)律與I/O吞吐量優(yōu)先策略非常相似,區(qū)別并不大。這也說明不論是以吞吐量為標準,還是以I/O次數(shù)為標準,只要將I/O更集中的數(shù)據(jù)元素存儲于SSD,混合存儲方案對OLTP數(shù)據(jù)的性能提升效果就非常明顯,基本可以達到線性提升。投入越多的SSD,就可以得到近乎同比例的更高性能。

圖3 OLTP數(shù)據(jù)庫性能隨SSD空間增長的變化曲線2
對于I/O吞吐量優(yōu)先策略,SSD空間占比從5.5%提升到65.9%時,tpmC 可以提高到 5.44倍(1 220/224.3);而I/O次數(shù)優(yōu)先策略,當SSD空間占比從5.5%提升到66.3%時,tpmC可以提高到5.53 倍(1 227.4/222.1)。
5 結(jié)束語
本文提出了一種基于混合存儲的OLTP數(shù)據(jù)庫的數(shù)據(jù)分布自適應優(yōu)化算法,可通過自動觀測決定數(shù)據(jù)庫在SSD和磁盤之間的優(yōu)化數(shù)據(jù)分布。基于實際數(shù)據(jù)系統(tǒng)的TPC-C實驗結(jié)果證明,本文提出的優(yōu)化算法和2種優(yōu)化策略,可以實現(xiàn)OLTP數(shù)據(jù)庫性能的線性提升。
[1] 陳明達.固態(tài)硬盤(SSD)產(chǎn)品現(xiàn)狀與展望[J].移動通信,2009,(11):29-31.
[2] Bausch D,Petrov I,Buchmann A.On The Performance of Database Query Processing Algorithms on Flash Solid State Disks[C]//Proceedings of the 22nd International Workshop on DatabaseandExpertSystemsApplications.Toulouse,F(xiàn)rench:IEEE Press,2011:139-144.
[3] Solid-state Revolution:In-depth on How SSDs Really Work[EB/OL].(2013-10-21).http://arstechnica.com/information-technology/2012/06/inside-the-ssd-re volution-how-solid-state-disks-really-work.
[4] Andersen D,Swanson S.Rethinking Flash in the Data Center[J].IEEE Micro,2010,30(4):52-54.
[5] Gal E,Toledo S.Algorithms and Data Structures for Flash Memories[J].ACM Computing Surveys,2005,37(2):138-163.
[6] EMC.EMC FAST Cache:A Detailed Review[EB/OL].(2011-12-12).http://www.emc.com/collateral/soft ware/white-papers/h8046-clariion-celerra-unified-fast-ca che-wp.pdf.
[7] Matthews J,Trika S,Hensgen D,et al.Intel? Turbo Memory:Nonvolatile Disk Cachesin the Storage Hierarchy of Mainstream Computer Systems[J].ACM Transactions on Storage,2008,4(2).
[8] Bitar R.Deploying Hybrid Storage Pools with Sun Flash Technology and the Solaris ZFS file System[EB/OL].(2011-02-13).http://wikis.sun.com/download/attach ments/190326221/820-5881.pdf.
[9] Oracle.Exadata Smart Flash Cache and the Sun Oracle Database Machine[EB/OL].(2009-03-06).http://www.oracle.com/technetwork/middleware/bifoundation/exadata-smart-flash-cache-twp-v5-1-128560.pdf.
[10] TPC-C標準文檔[EB/OL].(2010-05-06).http://www.tpc.org/tpcc/spec/tpcc_current.pdf.
[11] PostgreSQL Introduction[EB/OL].(2013-08-09).http://www.postgresql.org/about.
[12] BenchmarkSQL[EB/OL].(2014-09-10).http://sourceforge.net/projects/benchmarksql.
猜你喜歡
房地產(chǎn)導刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
中學生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數(shù)學大世界(2018年1期)2018-04-12 05:39:14
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
