XML 文檔到關系型數據庫的模型映射方法
2015-01-15 05:51:40沈艷霞
服裝學報 2015年5期
史 濤, 沈艷霞
(江南大學 電氣自動化研究所,江蘇 無錫214122)
XML 憑借其獨立于平臺、可擴展性和自描述性等特性[1]廣泛應用于異構數據集成系統的設計中,實現不同數據源之間的信息交換和共享[2]。隨著XML 應用的不斷深入,在諸多領域都產生了海量的XML 數據,如何高效地存儲這些XML 數據已成為值得研究的重要課題[3]。現階段,關系型數據庫仍然是企業應用最廣泛的數據庫,基于此,實現XML與關系型數據庫的數據交換對企業數據集成平臺的設計具有現實意義。
將XML 文檔中的數據有效且精確地分解到關系型數據庫中,要求采用強健且無縫的映射方法。在映射過程中,XML 文檔中節點關系的完整保存更有利于精確地實現用戶檢索過程。用戶檢索可以分為兩種方式,即全文本檢索和結構檢索[4]。全文本檢索只包含關鍵字檢索,沒有具體的限制條件,是使用最普遍的檢索方式,其特點是簡單方便,缺點是檢索結果不精確,效率較低。結構檢索包含多個限制條件,能夠返回更精確的答案。顯然為了在關系型數據庫中得到更為精確的查詢結果,結構檢索方式是不錯的選擇。
目前,國內外學者對映射技術的研究已經取得了一定進展。文獻[5]提出的邊緣(Edge)方法是最簡單直接的方法,主要思路是使用整數標記節點,使用XML 文檔中的元素名標記邊緣這兩種形式將整個XML 文檔存儲在單個關系型表格中,這種方法只適用于簡單的XML 文檔,而針對復雜組合的XML 文檔可能出現“超出表格大小”的錯誤。與Edge 方法相比,屬性[5](Attribute)方法根據XML文檔中的元素名稱創建足夠多的表格來進行存儲。這種方法雖然適用于具有復雜結構的XML 文檔,但是過多的表格會消耗資源和機器內存。文獻[6]提出的DTD 方法在XML 文檔中元素出現頻率的基礎上映射XML 數據,允許更少的空間消耗、簡單的表格模式和有效的表格映射機制,但該方法只適用于XML 文檔模式由DTD 表示的情況,具有局限性。文獻[7]中用來存儲XML 文檔結構的是編碼字符串的大文本字段,這種方法降低了維持XML 文檔結構的代價,但卻提高了查詢XML 文檔的難度。文獻[8]提出一種新的基于模式的方案,其利用分離和連接的操作符來構成模式及其相應的數據元素,易于呈現復雜的映射請求。文獻[9]提出一種數據模型,通過同時表示數據視圖和結構視圖的方式來改寫XML 文檔,進而實現XML 文檔的映射過程。上述兩種映射方法的設計都基于XML 模式,無法支持動態的XML 數據存儲。
綜上所述,很多現存的映射技術在實現結構化檢索的前提下,往往會消耗更多的資源和內存,如文獻[5,7];還有一些映射方案,如文獻[6,8-9],雖然能夠實現高效的結構化查詢,但需要考慮XML 文檔的模式,只支持靜態的XML 數據存儲,無法應用在XML 模式不斷變化的情況。
文中提出一種從XML 文檔到關系型數據庫的高效映射方案,利用特殊的標記節點方法,通過遍歷XML 文檔對節點進行編碼,有效獲取節點關系,實現了高效的結構化查詢。該映射方法不僅實現了高效的結構化查詢檢索方式,同時不需要考慮XML文檔的具體模式,支持任何格式良好的XML 數據的動態存儲。文中將該方法與現有的3 種存儲XML 文檔方法,即Edge、Attribute 以及DTD,在存儲空間、映射時間和檢索時間3 個方面進行比較。
1 理論概述
1.1 XML 數據模型
一個定義良好的數據庫系統的基礎在于具有定義良好的數據模型。XML 數據模型一般被簡化為標記樹或者直觀顯示的圖表,其中攜帶著表示結構數據和屬性值的元素。XML 具有多種不同的數據模型,其中Xpath1.0 和DOM 模型都將XML 文檔轉換為樹結構。Xquery 1.0 和Xpath 2.0 模型使用7 種節點將XML 文檔轉換成圖表[10]。文中采用DOM 模型,具體考慮XML 文檔中4 種類型的節點,分別為根節點、元素節點、文本節點和屬性節點[11]。圖1 是一個XML 文檔的具體實例和通過DOM 模型解析得到的XML 樹結構,實例中包含上文提到的4 種節點類型。

圖1 XML 文檔實例Fig.1 XML documents instance
1.2 XML 節點關系
圖2 顯示的是在XML 文檔中節點的4 種主要關系類型,分別為:a:父-子關系;b:祖先-子代關系;c:同胞關系;d:層級信息[12]。這些信息在映射過程需要被保存下來,滿足檢索用戶的查詢需要。
文中在文獻[13]提出的連續性標記模式方法的基礎上,提出一種標記節點的方法。該方法能夠保存節點間的關系信息,有效支持結構化的查詢檢索方式。也就是,每個節點將被標記為形如(1,np,n),其中:1.XML 樹種節點的層級;n.該節點相對于同胞的位置,稱為節點的區域標記。np. 父節點的區域標記;可以推斷,對于根節點nr,因為沒有父節點,可以被標記為(0,NULL,1),具體實例如圖3所示。

圖3 標記解釋Fig.3 Expalanation of nodes
2 具體算法設計
文中提出的模式映射方法的主要思路是:首先利用特有的標記形式,通過遍歷XML 文檔樹對所有節點進行標記編碼,有效獲取各節點間的關系信息;其次將XML 樹結構中的節點分為葉節點和非葉節點,創建對應的兩個表格將所有節點存儲到關系型數據庫中。具體流程如圖4 所示。其中標記節點和表格映射兩個步驟作用于映射過程中,查詢檢索步驟用于對存儲在關系型數據庫中的XML 文檔進行查詢檢索。算法的具體設計思路在下文詳細說明。

圖4 算法流程Fig.4 Flowchart of the algorithm
2.1 步驟1:標記節點
步驟1 的具體算法(標記節點)實現如下所示。
步驟1)標記節點:
1)輸入:XML 樹,Τ
2)輸出:標記的XML 節點,η
3)int level = 0
4)function labelNode(document)
5)if(ηr= = root node in Τ)
6)then label forηr(level,NULL,sn = 1)
7)level ++
8)for each child node ofηr,ηc(i)do{
9)label for nodeηc(i)(level,np= 1,n = 1)
10)getCNodes(ηc(i),n,level)
11)n ++
12)i ++
13)}//endfor
14)}//endfunction
15)
16)function getCNodes(ηc(i),npc,levelchild)
17){levelchild ++
18)for each child node ofηc(i),ηnextc(i)do{
19)label for nodeηnextc(i)(levelchild,np= npc,n =1)
20)getCNodes(ηnextc(i),n,levelchild)
21)getValue(ηnextc(i),n,levelchild)
22)n ++
23)i ++
24)}//endfor
25)}//endfunction
26)
27)function getValue(ηnextc(i),npleaf,levelleaf){
28)levelleaf ++
29)for each child node ofηnextc(i),ηleaf(i)do{
30)label for nodeηleaf(i)(levelleaf,np= npleaf,n =1)
31)}//endfor
32)}//endfunction
步驟1 中,每個節點都被特定的標記模式所標記,形 如(l,np,n)。XML 文 檔,即 步 驟1 中 的document 能夠被XML 解析器解析出所有節點,具體實現為步驟1 中的第4 行。函數labelNode()標記出根節點ηr。因為根節點沒有父節點,所以如步驟1 中第6 行所示,np被標記成NULL。根節點的子節點,即ηc(i),通過函數getCNodes()標記,具體實現如步驟1 的16 ~25 行。當增加XML 節點的層級時,每一個子節點都被遞歸地送入函數getCNodes()生成隨后的子節點,遞歸函數的結束條件為levelchild 等于層數。葉節點的標記由函數getValue()實現,即步驟1中的27 ~32 行。
2.2 步驟2:表格映射
步驟1 中輸出的信息將被映射到兩張表格,分別為內部節點表格inNodeTable 和外部節點表格exNodeTable。內部節點表格存儲的是非葉節點,即內部節點;外部節點表格存儲的是葉節點,即外部節點。
下面介紹兩個表格的具體字段:
inNodeTable(nodeID,pName,cName,level,lParent,selfLabel):
(a)nodeID:存儲在內部節點表格中的節點唯一識別編號
(b)pName:存儲父節點的元素名
(c)cName:節點名稱
(d)level:層級
(e)lParent:節點的父節點的nodeID
(f)selfLabel:節點所在層級的區域標簽
exNodeTable(nodeID,level,pName,selfLabel,lParent,value):
(a)nodeID:存儲在外部節點表格中的節點唯一識別編號
(b)level:存儲節點在XML 文檔中的層級
(c)pName:存儲父節點的元素名
(d)selfLabel:節點所在層級的區域標簽
(e)lParent:存儲在內部表格中的父節點的nodeID
(f)value:存儲節點的值
步驟2 實現的是節點到表格的映射過程。下文采用和步驟1 同樣的方法對XML 文檔進行遞歸遍歷。從步驟1 推導出的節點標簽,即層級(1),區域標簽(n),父標簽(np)將被分別映射到level,selfLabel 和lParent 三列當中。具體算法實現步驟如下所示。
步驟2:映射XML 節點到關系型數據庫:
1)function createTable(){
2)long timeBefore = System.currentTimeMillis();
3)connect to the database
4)}
5)
6)// 插入根節點
7)function rootN(Doucument doc){
8)insert into inNodeTable(pName,cName,level,selflabel,lParent)values(NULL,root.getNode Name(),level,n,’NULL’)
9)// 插入第1 層的節點
10)insert into inNodeTable (pName,cName,level,selflabel,lParent)values(cNode.getParentNode( ).getNodeName( ),cNode.getNodeName(),level,n,nodeID)
11)}
12)
13)// 插入其他非葉節點
14)function child(ηnextc(i)){
15)insert into inNodeTable (pName,cName,level, selflabel,lParent)values(cN.getParentNode( ). getNodeName( ),cN.getNodeName(),level,n,nodeID)
16)child(ηnextc(i))
17)// 插入葉節點
18)leafNode(ηnextc(i))
19)}
20)
21)function leafNode(ηnextc(i)){
22)insert into exNodeTable (level,selfLabel,lParent,value)values(level,n,nodeID,cData.getNodeValue())
23)}
24)long timeAfter = System.currentTimeMillis();
25)Time taken to map = timeAfter-timeBefore
2.3 步驟3:查詢檢索
步驟3 描述的是查詢檢索過程。如果查詢條件包括一個關鍵詞以及節點間關系的組合,在外部節點表格中檢索lParent 字段,該字段決定了內部節點表格中父-子關系或者祖先-子代關系,如步驟3 中5 ~7 行所示;如果是結構查詢,那么將在內部節點表格中使用lParent 字段值進行搜索查詢如步驟3中8 ~11 行所示。
步驟3:在關系型數據庫中進行查詢檢索過程:
1)輸入:查詢條件,例如元素名,值或者節點間各種關系的組合
2)輸出:從數據庫返回的結果集
3)v:= 節點文本值
4)e:= 節點間關系組合的元素名
5)if(input = = v)
6)then criteria of the query is value = v from exNodeTable
7)endif
8)if(input = = e)
9)if(e = = parent-child relationship)&&
(e = = ancestor-descendant relationship)&&
(e = = leaf node)
10)then trace the node from exNodeTable to inNo deTable by matching lParent from exNodeTable to nodeID in inNodeTable
11)endif
12)if((e = = parent-child relationship)&&
(e = = ancestor-descendant relationship)&&
(e!= leaf node))
13)then trace the node in inNodeTable
14) only match lParent and nodeID in inNode Table
15)endif
16)endif
圖5 描述了利用步驟3 對于文中之前提到的節點間4 種主要關系的檢索過程。由此可以在關系數據庫中實現對XML 文檔中各節點的檢索。

圖5 4 種節點關系的檢索過程Fig.5 Search of four node relations
3 實驗評估
為了驗證提出的模式映射方法的有效性,將文中所提方法與現有的3 種映射方法,即基于邊緣、基于屬性和關系型DTD 3 種方法進行比較。評價指標分別為:將XML 文檔映射到關系型數據庫的時間;映射過程完成后的存儲時間;從關系型數據表中執行查詢的時間。
文中數據源來自于 Washington UW Repository[14]下 載 所 得 的Digital Bibliography &Library Project(DBLP)數據集大小為0.67G。實驗的測試平臺是Altova Spy 和Microsoft Visual Studio 2010 標準環境,采用文檔對象模型DOM 對XML 進行解析處理,將Microsoft SQL server2008 作為關系型數據庫服務器,C#作為算法編程語言。其中記錄的時間由5 組連續執行的平均值確定,以求數據更為準確。
3.1 XML 數據映射到關系型數據庫
第1 個實驗用于測量將XML 數據映射到關系型數據庫的時間,其結果如圖6 所示。在映射過程中一共包含3 個步驟,分別為數據庫創建、表格創建以及加載XML 數據。

圖6 映射時間Fig.6 Time of mapping
由圖6 可知,通過文中方法得到的映射時間為37 254 ms,而關系型DTD 和基于屬性的方法映射時間分別為62 150 ms 和49 987 ms,后兩者時間明顯大于文中方法。其主要原因是關系型DTD 和屬性兩種方法分別根據元素重復出現的頻率和獨立元素的個數生成相應數量的表格,導致創建表格和數據加載這兩個環節的時間過長。相比之下,文中的方法只包含兩個表格來有效地存儲XML 數據,表現最好。
3.2 關系型數據庫存儲容量
第2 個實驗評估通過邊緣、屬性、DTD 和文中所提方法將XML 數據映射到數據庫之后,存儲數據的容量大小比較。圖7 顯示了評估結果。
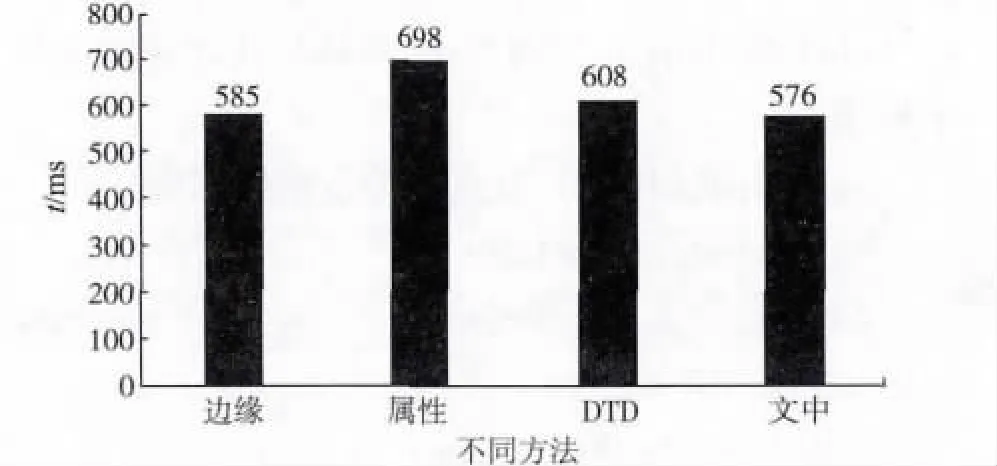
圖7 存儲空間Fig.7 Space of storage
由圖7 可知,基于屬性和關系型DTD 方法所消耗的存儲容量分別為698 MB 和608 MB,利用的空間較高,原因是基于屬性方法根據XML 文檔中獨立元素的個數創建相應多的表格,而關系型DTD 方法根據文檔中元素重復出現的頻率同樣創建相應多的表格,兩者創建更多的表格數,導致空間占有更大。基于邊緣的映射方法存儲容量為585 MB,相比前兩種方法占有的空間更少,原因是該方法將整個XML 文檔都存儲在一個表格中。同理,文中方法創建兩個表格來存儲XML 文檔,消耗的存儲空間較少。
3.3 查詢過程
第3 個實驗對數據庫中存儲的數據集的查詢時間進行評估。實驗分別選用不同存儲容量的源數據,采用目前較為復雜的查詢方法——twig 對數據集進行查詢。具體實驗結果如表1 所示。
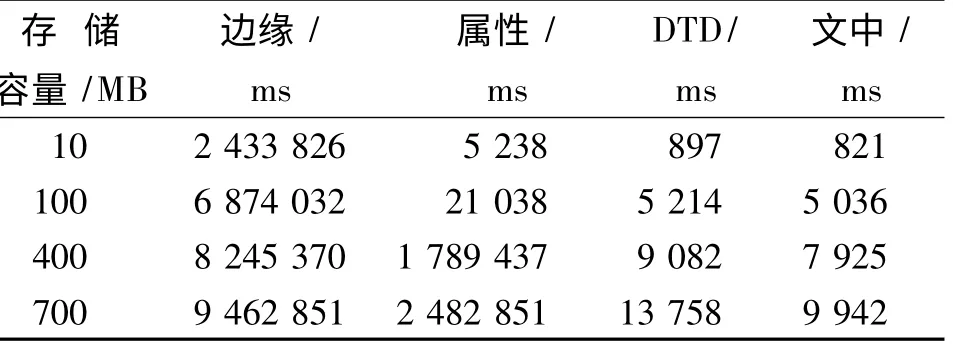
表1 查詢檢索時間對比Tab.1 Time comparison in terms of query
由表1 得出,針對4 種存儲容量不同的元數據,基于邊緣和屬性兩種方法在進行twig 查詢時都耗費更多的時間。相對而言,關系型DTD 方法是一種更好的方法,因為其在處理簡單的結構化XML 樹時具有優勢,但是在處理結構不完整的XML 數據時其表現差于文中所提出的方法。造成這種差異的主要原因是DTD 映射模式創建了大量表格,導致節點關系之間出現大量連接。顯然,文中所提出的映射方法不存在上述情況,相比較其他方法,其在查詢過程中表現出了更高的效率。
4 結 語
XML 文檔要求強健無縫的映射方法來實現將數據有效且精確地存儲到關系型數據庫中。一種好的映射方法應該保存XML 樹結構中的4 種主要關系,分別為父-子,祖先-子代,同胞以及XML 的層級,有效支持結構化的查詢檢索。文中提出的映射方案利用特殊的標記節點方法,在映射過程中保存節點之間的關系,高效實現了結構化檢索。實驗結果表明,文中所提出的方法具有以下幾個特點:(1)在數據庫存儲和數據加載方面表現堅固;(2)支持結構化檢索;(3)不受模式限制,支持任何格式良好的XML 文檔;(4)相比較基于邊緣、屬性和關系型DTD 等現有方法,映射效果更理想。
[1]Femau H.Learning XML grammars[C]//7th International Conference,MLDM 2011.New York:[s.n.],2001,1:73-87.
[2]袁景凌,徐麗麗,苗連超.基于XML 的虛擬法異構數據集成方法研究[J].計算機應用研究,2009,26(1):172-174.
YUAN Jingling,XU Lili,MIAO Lianchao.Research on virtual approach about heterogeneous data integration based on XML[J].Application Research of Computers,2009,26(1):172-174.(in Chinese)
[3]Haw S C,Lee C S,Node labeling schemes in XML query optimization:a survey and trends[J].IETE Technical Review,2009,26(2):88-99.
[4]曹蘭英,嚴義,鄔惠峰.基于模式匹配的XML 自動轉換技術[J].計算機工程與應用,2012,48(25):72-76.
CAO Lanying,YAN Yi,WU Huifeng. Automating XML document transformations based on schema matching[J]. Computer Engineering and Applications,2012,48(25):72-76.(in Chinese)
[5]Florescu D,Kossmann D.Storing and querying XML data using an RDBMS[J].IEEE Data Engineering Bulletin,1999,22(3):27-34.
[6]Shanmugasundaram J,Shekita E,Kiernan J,et al.A general technique for querying XML documents using a relational database systems[EB/OL].http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.118.6801.
[7]耿飚,宋余慶,粱成全,等.XML 文檔到關系數據庫映射方法的研[J].計算機應用研究,2010,27(3):951-954.
[8]LI Xuhui,ZHU Shanfeng,LIU Mengchi,et al.Presenting XML schema mapping with conjunctive-disjunctive views[J].Web-Age Information Management Lecture Notes in Computer Science,2013,7923:105-110.
[9]Eun-Young Kim,Se-Hak Chun.New database mapping schema for XML document in electronic commerce[J]. Multimedia and Ubiquitous Engineering,2013,240:353-358.
[10]Clark J,Derose S. XML path language(Xpath)version 1. 0[EB/OL]. W3C Recommendation. http://www. w3. org/TR/xpath,1999.
[11]QIN Jie,ZHAO Shumei,YANG Shuqiang,et al.Efficient storing well-formed XML documents using RDBMS[C]//International Conference on Services Systems and Services Management.Chongqing:IEEE,2005,2:1075-1080.
[12]Edith Cohen,Haim Kaplan,Tova Milo.Labeling dynamic XML trees[J].Siam Journal on Computing,2002,39(5):271-281.
[13]Gabillon A,Fansi M.A persistent Labeling scheme for XML and tree database[C]//Signal-Image Technology and Internet-Based Systems,2005,1:110-115.
[14]Dan Sucin. XML data repository[EB/OL]. (2001-11-09)[2014-01-20]. http://www. cs. washington. edu/research/xmldatasets/www/repository.html.
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
