基于多類SVM的新聞政要人物自動標識
2015-01-16 05:26:52蘇雪平彭進業
電子設計工程 2015年11期
關鍵詞:方法
蘇雪平,彭進業
(西北工業大學 陜西 西安 710129)
網絡新聞數據包含豐富的文字和圖像信息,并且新聞中的人臉圖像與字幕中的人名存在多對多關系,如何準確的匹配人臉圖像和人名之間的一一對應關系成為一個極富挑戰性的問題。針對這一問題,傳統解決方法主要是基于文本方法和基于內容的圖像方法(即,人臉識別方法)。但是,上述兩種方法不是產生錯誤導致準確率低就是無法獲得良好的性能。
Berg等[1]提出結合概率模型的聚類過程顯著提高了檢索結果。但是實驗僅隨機挑選了一些真實數據集中的人臉,評價為其命名的正確率。Ozkan等[2]提出基于圖論的人臉命名方法,用于尋找與查詢人名相關的最相似人臉子集。蘇等[3]為了減小運算量和提高聚類的準確率,融合文本和視覺的多模信息提高了人名人臉匹配的性能,實驗結果性能優于Berg[1],Ozkan[2]等的方法。Le等[4]用迭代步驟自動將搜索引擎返回的圖像分為相關或無關圖像。該方法是完全無監督,并且訓練的模型可以用于標注新的人臉,但是需要一些經驗參數設置,影響性能的穩定性。
文中結合AP聚類和SVM分類將新聞圖像中的多個人臉和多個人名的匹配問題,轉化為多類分類問題。為了改善訓練樣本的可靠性,文中通過迭代更新挑選訓練樣本并訓練多類SVM。綜上所述,文中提出基于多類 SVM的新聞政治人物自動標識方法。
1 基于多類SVM的新聞政要人物自動標識
讀者瀏覽新聞時,最關注的是誰在新聞中。如何自動挖掘新聞字幕中人名與新聞人臉圖像之間一一對應關系已引起人們的廣泛關注。此外,網絡新聞圖像包含多種表情、姿態、年齡、光照等情況,使得基于文本相關性或基于人臉識別方法都很難適用于網絡新聞數據。針對網絡新聞數據,本文提出基于多類SVM的新聞政要人物自動標識方法。算法流程框圖如圖1所示,具體細節如下所述。
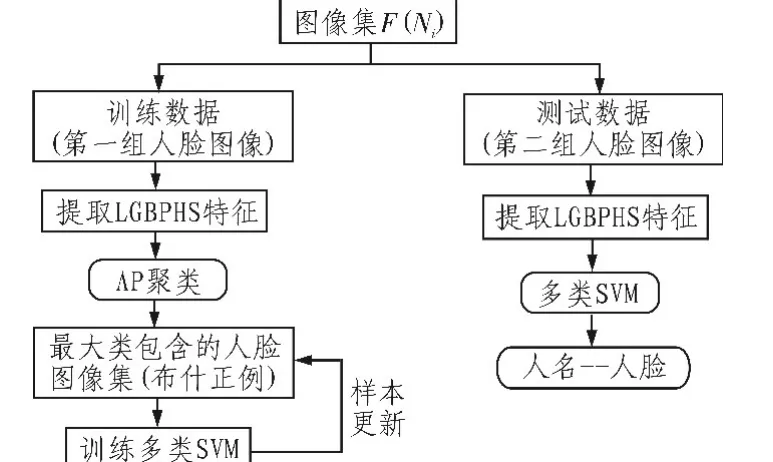
圖1 算法流程框圖Fig.1 The flow chart of the method
1.1 人名檢測
本文使用L.Ratinov[5]的人名識別模型在新聞字幕中檢測人名。然而,一個人的名字經常會以不同形式出現。例如,總統布什、喬治布什、總統喬治布什都是小布什的名字。本文手動融合同一個人名的不同形式,并創建人名字典。
1.2 人臉檢測和描述
針對每一個人名,首先找到與該人名相關的圖像子集,建立人名與人臉的對應關系。其次,對該人名的圖像子集,使用人臉檢測算法檢測人臉圖像。在檢測人臉時,人臉特征點的精確定位對于人臉檢測起著至關重要的作用。但在實際應用中,由于人臉差異、圖像質量等原因,準確定位人臉特征點并非那么容易。例如在人臉特征點定位中,由于光照、表情、遮擋、姿態等影響使得定位的難度加大。
主動形狀模型(Active Shape Model-ASM)[6]是一種常用的人臉特征點定位方法,該方法最初是由 Cootes等人提出并定位圖像中某一特定類型的對象。ASM方法訓練樣本圖像并統計分析得到準確的局部灰度模型,再以此模型為依據,在測試圖像中進行快速定位。它的優點不僅在于通過形狀建模得到目標輪廓的初始位置,選取合理的參數加速定位,并借助特征點周圍的局部紋理特征精確地定位出人臉特征點,而且在搜索目標模型的變形時依賴于訓練集,也保證了目標定位的準確性。本文使用ASM定位人臉特征點,并利用眼睛中心的位置信息將人臉歸一化。
LGBPHS(local gabor binary pattern histogram sequence)是基于多分辨率空間直方圖方法。一方面它結合空間和局部強度信息,對光照、表情、年齡等外觀變量不敏感。另一方面,它也是非統計學習方法,不需要任何學習過程。所以本文用LGBPHS描述人臉特征,具體過程如下:1)采用多尺度多方向的小波濾波器得到多個小波幅值圖;2)局部二元模式將每幅小波幅值圖轉換為局部小波二元模式圖;3)將每個二元模式圖分成指定大小的非重疊塊,并計算每塊的直方圖;4)融合所有二元模式圖的直方圖作為描述人臉的模型。
1.3 AP聚類
AP(Affinity propagation)是 Frey等[7]介紹的一種聚類方法。它將數據點間的相似度作為輸入,并考慮所有的數據點作為潛在的中心進行聚類。它不需要指定聚類數目,也不需要隨機選取初始值,運行時間快,錯誤率小,方法簡單、并適用于大規模數據等優點,所以本文采用AP對人臉圖像進行聚類。
依據Berg等[1]的假設,該人名相關的人臉子集圖像中,使用聚類方法找到的最大類圖像是該人名的真實人臉圖像。此外,為了減少運算量并且提高聚類的準確率,將給定人名的圖像子集分成兩組圖像。第一組人臉圖像由滿足新聞圖像中僅有一個人臉圖像,并且新聞字幕只包含一個人名條件的圖像組成,剩余人臉圖像組成第二組人臉圖像。本文對第一組人臉圖像提取LGBPHS特征,并采用歐氏距離計算人臉圖像間的相似度,使用AP聚類找到最大類,并且最大類的人臉圖像作為該人名的初始訓練樣本圖像,建立了人名與人臉的對應關系。
不幸的是,實際聚類中,由于不同的表情、光照、姿勢等影響,不同的人臉會聚類到同一類中,AP聚類也不例外。然而同一幅圖像中,幾乎不可能同時出現一個人的多幅人臉圖像。所以,當聚類中包含一幅圖像的多幅人臉圖像時,僅保留其中一個人臉圖像。針對這種情況,文中計算這些人臉圖像與中心人臉圖像的相似度,保留相似度最小的人臉圖像,剔除其他人臉圖像。
1.4 多類SVM
支持向量機(SVM)是一種建立在統計學習理論基礎之上的機器學習方法,其最大的特點是根據Vapnik結構風險最小化原則,即在函數復雜性和樣本復雜性之間進行折中,盡量提高學習機的泛化能力,具有優良的分類性能。另外,支持向量機在解決小樣本、非線性及高維模式識別問題中表現出了許多特有的優勢。針對多類分類問題的經典SVM算法主要有一對一(1-vs-1)和一對多(1-vs-all)兩種方法。
對于k類問題,一對一 SVM需要構造k(k-1)/2個分類平面(k>2)。這種方法的本質與兩類SVM并沒有區別,它相當于將多類問題轉化為多個兩類問題來求解。該方法優點在于每次投入訓練的樣本相對較少,因此單個決策面的訓練速度較快,同時精度也較高。但是當k較大的時候決策面的總數將過多,因此會影響預測速度。然而一對多SVM僅需要構造k個分類平面(k>2)。該方法也是兩類SVM方法的推廣,實際上它是將剩余的多類看成一個整體,然后進行k次兩類識別。與一對一方法相比,由于一對多方法每次構造決策平面需用全部樣本數據,因而兩種方法訓練所需要時間相差不多。但是一對多構造的決策平面數相對少很多,其預測速度也快很多。本文數據類別數較多,綜合考慮使用一對多SVM方法進行分類。對于給定人名,AP聚類找到的最大類的人臉圖像作為該人名的初始訓練樣本圖像,對于其他人名,也采取同樣的方法,找到相應的初始訓練樣本圖像;將所有給定人名的初始訓練樣本圖像用于多類SVM訓練。此外,為了提高訓練樣本的可靠性,通過迭代更新挑選訓練樣本和訓練多類SVM。第二組人臉圖像作為測試圖像,提取人臉的LGBPHS特征,并將訓練好的多類SVM用于第二組圖像分類,依據分類結果,標識人臉圖像。但是,訓練一對多的SVM分類器時,正例的數目與反例的數目樣本數量差異很大,也叫數據集偏斜。為了解決數據集偏斜問題,在目標函數中添加懲罰因子,即給樣本數量少的類更大的懲罰因子。目標函數公式如下:
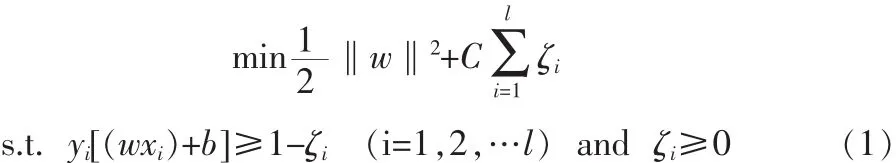
其中C是懲罰因子,ζi是松弛變量,l是樣本的數目。實驗中,對于正類和負類,我們設置不同的懲罰因子,則目標函數中的松弛變量公式如下:
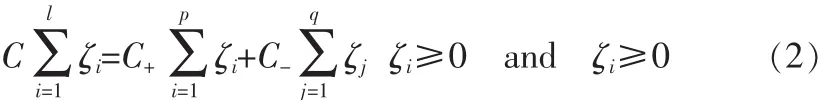
其中,C+/C-分別是正類/負類的懲罰因子,ζi/ζj分別是正類/負類的松弛變量,p/q分別是正類/負類的樣本數目。多類SVM訓練過程如圖2所示。
2 實 驗
本文提出了基于多類SVM的新聞政要人物自動標識方法,并在大規模數據集上進行實驗驗證。首先,本文介紹實驗數據集,并在數據集上進行性能評估。其次,與其他方法比較,討論本文方法與其他方法的優缺點。
2.1 數據集

圖2 多類SVM Fig.2 Multiple SVM
數據集是Berg等[1]在雅虎新聞中搜集的大約50萬個帶有字幕的新聞圖像集。與人臉識別的實驗數據庫相比,該數據集在非標準實驗設置下獲取,同時包含多種光照、姿態、表情、遮擋等因素。
2.2 實驗設置
首先,采用L.Ratinov[5]的命名實體標注方法處理所有字幕,檢測到20 931個人名,每個人名都可以找到一組相關的圖像。然而,一方面一幅圖像中包含多幅人臉圖像,人名相應圖像集中檢測的人臉圖像數目遠遠大于人名在總字幕中出現的次數,另一方面一個特定人名有多種表示方法,本文手動合并這些不同表示方式的人名并建立人名字典。綜上所述,本文只處理人名相應人臉圖像數目多于60個的新聞政要人名,符合該條件的人名總共有54個。人名集及人名出現次數如圖3所示。
其次,采用主動形狀模型定位人臉的特征點[6],該特征點包含68個,主要分布在眉毛、眼睛、鼻子、嘴巴、面頰等區域。利用左右眼睛中心坐標信息歸一化人臉。在LGBPHS方法中,窗口大小的設置影響識別性能。為了保留更多的空間信息和局部信息,當人臉圖像歸一化到80*60像素(左右外眼角像素歸一化為50個像素),劃分為9個區域,融合這些區域的直方圖,得到3600維特征向量。此外,為了減少運算量并且提高聚類的準確率,我們將給定人名的圖像子集分成2組圖像。對第一組人臉圖像采用歐氏距離計算人臉圖像間的相似度,采用AP聚類,聚類中最大類的人臉圖像作為該人名的初始訓練樣本圖像,對于其他人名,采取同樣的方法,找到相應的初始訓練樣本圖像。在迭代更新訓練樣本和訓練多類SVM的時候,設置迭代的次數為3,概率輸出的閾值設置為0.85,只要樣本的輸出概率大于閾值,該樣本選中作為下次訓練的樣本。此外分別計算給定人名的圖像集、第一組圖像使用AP聚類找到的初始訓練樣本和通過迭代更新挑選的訓練樣本的準確率。圖4給出了由不同圖像集獲得訓練樣本的準確率。在訓練多類SVM中,公式(2)中的參數C+/C-設置為正負類樣本的數目比值,參數ζi/ζj都設置為0.1。最后,將多類SVM用于分類給定人名的第二組人臉圖像,實現新聞政要人物的自動標識。

圖3 本文處理的人名及相應出現的次數Fig.3 The names and occurrence number
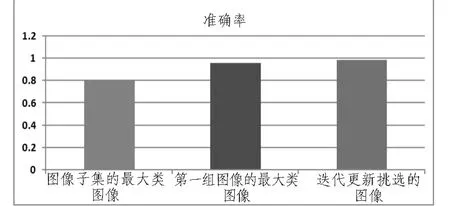
圖4 不同圖像集獲得訓練樣本的準確率Fig.4 The precisions of different image subset
2.3 評價標準
為了有效評價本文方法,本文給出了基于F1-measure的實驗結果。首先分別計算每個人名的召回率、查準率和F1,然后計算整體的權重召回率、查準率和F1。計算公式如下所示:
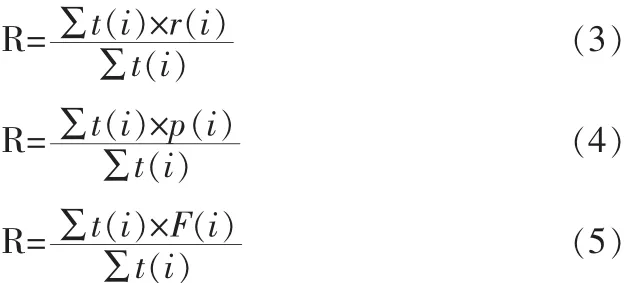
其中 r(i)/p(i)/F1(i)分別是第 ith人名的召回率、查準率、F1,t(i)是第 ith人名相應的總人臉數目。
2.4 分析與結果
在雅虎新聞出現頻率大于60次的54個新聞政要人名的數據集上驗證本文的方法,本文方法的加權平均F1值是77.5%。此外,本文與文獻[1]~[4]的方法進行對比。一方面與文獻[1]~[2]的數據集相同,另一方面本文的假設與文獻[2]~[4]的假設一致,并且實驗數據都包含多種姿態、表情、光照等因素。實驗結果如表1所示。
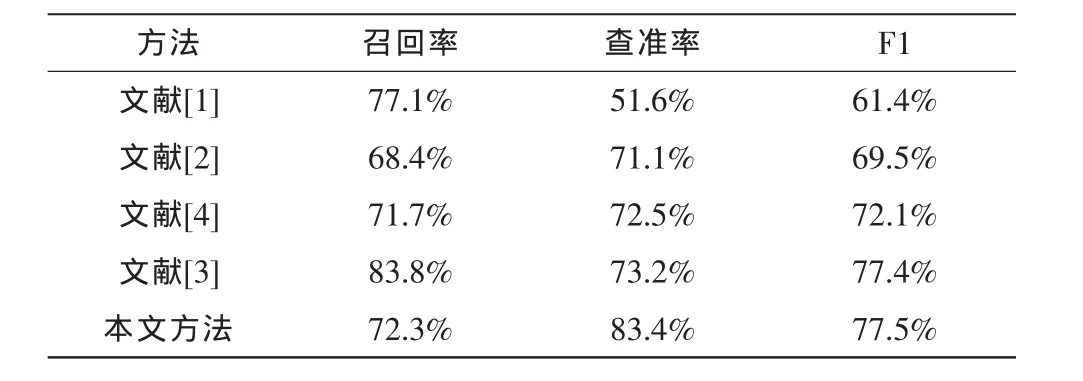
表1 不同方法的實驗結果Tab.1 The results of different methods
從表1可以看出,本文方法得到了較好的實驗性能。文獻[1]使用人名在字幕中位置的文本信息和視覺信息,獲得了較高的召回率。文獻[2]提出的基于圖論中最大密度的方法與本文的最大聚類的方法比較類似,二者之間可以轉化。文獻[3]使用了文本信息和視覺信息,使得召回率較高,本文僅使用了視覺信息,通過改善樣本的可靠性提高了查準率。另外,對比本文與文獻[3]、[4]在挑選訓練樣本的準確率(如表2所示)。
從表2可以看出,通過聚類尋找的訓練樣本正例的準確率優于文獻[3]和[4]的結果。文獻[4]調選樣本正例和反例取決于參數的設定,參數設置直接影響了樣本的可靠性,從而降低了性能。

表2 訓練樣本的準確率Tab.2 The precision of different training samples
3 結 論
本文提出基于多類SVM的新聞政要人物自動標識方法。它不需要任何手工標注,僅使用大規模數據集,并且實驗數據集包含多種姿勢、表情、光照等因素,因而該方法可以普及到一般的人臉識別問題。
在雅虎新聞大約50萬的數據集上進行實驗,驗證了本文方法的可行性。實驗也實現了72%的加權平均召回率和83.4%的加權平均查準率,對于單個人名而言,實現了高達91.6%的召回率和96.5%的查準率。與其他文獻方法進行比較,也實現了較好的性能。但是,對于出現頻率較低的人名,相應的圖像子集數目太少無法聚類找到準確的正例樣本,從而無法正確標識,并且考慮其他附加信息,在保證查準率的同時提高召回率,這將是我們今后工作的重點。另外,本文方法也可以適用于如目標識別、圖像標注等其他問題。
[1]Berg T L,Berg Er C,Edwards J,et al.Who’s in the picture[C].Proceedings of Advances in Neural Information Processing Systems, Cambridge,2005:137-144.
[2]Derya O,Pinar D.Interesting faces:A graph-based approach for finding people in news[J].Pattern Recognition,2010,43(5):1717-1735.
[3]SU Xue-ping,PENG Jin-ye,FENG Xiao-yi,et al.Crossmodality based celebrity face naming for news image collections[J].Multimedia Tools and Application,2013,67 (3):687-708.
[4]D L,S Satoh.Unsupervised face annotation by mining the web[C].In International Conference on Data Mining, Pisa,2008:383-392.
[5]Ratinov L,Roth D.Design Challenges and Misconceptions in Named Entity Recognition[C].In proceedings of the 13th Conference on Computational Natural Language Learning,Boulder,2009:147-155.
[6]Stephen Milborrow and Fred Nicolls.Locating Facial Features with an Extended Active Shape Model[C].Proceedings of the 10th European Conference on Computer Vision,Marseille,2008:504-513.
[7]Frey B J,Dueck D.Clustering by passing messages between data points[J].Science,2007,315(5814):972-976.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
