
情報學基本原理在其智能化處理機制中的運用
2015-02-10 11:35:14王瑋
科技視界 2015年20期
王瑋
(沈陽市科學技術情報研究所,遼寧 沈陽110003)
0 引言
信息技術的快速崛起促進了情報處理系統的大踏步發展,互聯網的應用更是使情報收集、檢索和分析面臨著前所未有的海量信息處理壓力。因此情報的智能化處理需求變得越來越迫切,同時情報的智能處理也能為決策部門提供更加科學、客觀的依據。然而,在大數據時代,信息的海量性、異構性和無序性使得情報的即時獲取、智能解析和準確評價等方面都存在著許多困難。
另一方面,情報學作為一門新興學科,與其他學科一樣具有一些帶有普遍意義的、基礎性的思想和原則,這些思想和原則主導著情報學的發展,我們稱其為情報學的基本原理。無論時代怎么發展,技術怎樣創新,這些基本原理作為獨立的理論或規律在情報學中的作用和地位是不會改變的。
由此可以得出,情報的智能化處理機制和系統的建立,一定要基于情報學的基本原理,否則將使情報工作陷于紛繁復雜的泥淖之中不能自拔。情報應該是對關注對象所處環境與狀態的全面監測過程,即通過廣泛搜集相關的大量信息,經過篩選、提煉和綜合分析,對關注對象進行綜合評定,進而提出相應對策的過程。這是一個計算機高效處理性能與情報分析人員判斷相結合的智能系統,從智能處理的系統性和情報學的基本原理出發,可以將智能情報處理系統分為信息/數據層、邏輯業務層和功能層三個層次,而情報學的基本原理在這三個層次中都有不同程度的運用和體現。
1 基于離散分布原理選擇信息源
信息/數據層,是將分布在世界各地的感興趣的信息資源采集下來并進行初步處理,形成網絡信息資源庫,進一步按照所屬領域構建相關的知識庫。這項工作是情報智能化處理機制的基礎部分,工作量巨大,且時效性很強,因此可交由計算機按照事先設定好的程序自動檢索完成。其檢索程序的設計應遵循情報的離散分布原理。
信息、知識和情報是以離散形式分布的,在離散的基礎上趨于集中。情報的離散分布現象是全部情報活動的基石,因此對情報分散規律的研究不僅有助于信息資源庫和知識庫的建立,也將對情報學的發展起到奠基性的作用。迄今為止對情報離散分布現象研究最富盛名的成果是布拉福德(Bradford)定律,它與描述科學生產率分布的洛特卡(Lotka)定律,詞頻分布的齊夫(Zipf)定律,文獻增長老化的指數定律具有共同的淵源和機理。布拉德定律在研究中創造了頻次-等級排序法:按某一具體事項(如標題、作者、關鍵詞等)在其主體來源(如期刊、作者集合等)中出現的頻次按遞減順序排列,就會導出布拉德福分布,其特點在于所考察的具體對象大多數都集中于少數主體來源[1]。例如,某一主題的科學論文約三分之二集中在少數期刊上。導致這種結果的主要原因是,作者在寫文章或發表文章時,總是希望選擇常用的、傳遞功能強的詞匯和期刊。這種現象實際上是情報離散分布基礎上形成的核心趨勢,是成功經驗積累的結果,也是“馬太效應”的表現形式。
因此,在運用計算機自動檢索技術搜集情報過程中,應充分考慮情報的這一基本原理,首先選擇相關領域的權威期刊或網站,這些期刊或網站往往集中了大量的有價值的知識和情報。以這些期刊或網站作為相關領域情報的主要來源,不僅能提高情報檢索的效率,而且能保證所搜集情報的質量。
2 利用有序性原理對情報進行“深加工”
搜集到信息資源庫或知識庫里的“情報”,準確的說還不能稱之為情報,只能稱其為有價值的但未經處理的信息。按照情報智能化處理機制的要求,接下來在信息資源庫和知識庫的支持下,計算機將完成信息的邏輯計算,包括對相關信息的進一步分/聚類、信息的訪問與傳遞、信息的業務管理,以及為情報分析人員提供交互工具、評估工具、建模環境等,這部分工作在情報智能化處理機制中稱之為邏輯業務層,由計算機和情報分析人員共同完成,其工作的機理同樣需要遵循情報學的基本原理——有序性。
情報結構無論是以自然系統存在還是以人工系統存在,都具有某種“序性”。研究和揭示這種“序性”是設計最優情報系統的基礎。情報的有序性結構既來自情報創造過程的機理,也來自知識體系自身的組織功能。在知識體系結構中具有不同的功能,但都會通過知識的自組織而形成有序性結構。20世紀70年代中期,布魯克斯曾提出描述情報作用的基本方程式:
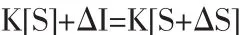
式中K[S]為原有的知識結構,K[S+ΔS]為吸收情報以后的知識結構,ΔI為增加的情報。這個方程式說明新的知識結構形成是由于吸收情報的結果。30多年來這個以偽數學形式表達的簡單方程式引起了人們廣泛的興趣和關注,認為它對描述情報的概念和作用是最基本的。
情報不僅僅是簡單的邏輯計算,更重要的是情報分析人員對信息的解讀和加工。這種對情報的“深加工”是以新知識結構的產生為目的,是以人為中心的信息處理過程。因此情報智能處理系統的設計應利用情報的有序性原理,模擬情報人員工作時的動態思維過程,綜合人的認知判斷能力與計算機的邏輯運算能力。這不僅需要通常意義上的算法、建模與仿真,更重要的是啟發人們對新知識結構的認知,為進一步的科學決策提供有價值的和有競爭力的情報服務。
3 面向實際應用提供多功能情報服務
情報最突出的特點就是“智慧”,它不是簡單的數據堆積,也不是簡單的信息加工,而是要注入許多創造性的智力勞動,從反映客觀事物的信息中,通過識別、分析、評價,最終形成新的增值情報產品,并服務于科學決策[2]。因此,智能情報處理機制必須要面向實際應用,為用戶提供如標準事件、可能性事件、突發事件等多種應對方案,以及決策性咨詢服務等。
在此過程中應體現出情報的準確性、預見性和易用性原理。隨著獲取信息渠道的不斷拓寬以及信息智能處理技術的研發,情報服務也從最初的“比多比全”發展為現代的“比精比準”[3]。情報的準確性,不僅指情況的真實、數據的準確,更重要的是分析判斷的準確。這種提前的判斷體現了情報的預見性。情報是為計劃、決策提供依據的,是為將要實施的行動服務。因此,情報的準確性和預見性,是情報服務的最高價值體現。
此外,在提供情報服務過程中,還應充分考慮其易用性的原理。人類交流、獲取和利用信息、知識、情報,總是趨向簡捷、方便、易用和省力。穆爾斯定律指出,一個情報檢索系統,如果用戶從它取得情報比不取得情報更傷腦筋和麻煩的話,這個系統就不會得到利用。因此,智能情報處理機制一定是從用戶的角度出發,建立在易于存取、易于利用的基礎之上的,甚至在某些情況下用戶對于情報的易用性比情報本身的要求都高。
4 結束語
綜上所述,智能情報處理機制應該是以情報學基本原理為基礎建立和發展的,網絡信息技術為智能情報服務系統的開發提供了實踐的土壤。相信在不遠的未來,以情報學基本原理為基礎、以用戶實際需求為導向的智能情報服務系統必將得到長足的發展和廣泛的應用。
[1]馬費成.論情報學的基本原理及理論體系構建[J].情報學報,2007(1).
[2]呂志堅,王冠宇,崔霞.網絡環境下情報智能處理機制研究[C]//北京科學技術情報學會年會.,2009,12.
[3]陳佳.網絡信息智能處理技術在企業競爭情報系統的應用[C]//第十八屆全國計算機信息管理學術研討會論文集.2004,10.
猜你喜歡
時代人物(2019年30期)2019-12-16 02:07:44
電子制作(2019年14期)2019-08-20 05:43:34
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
中華手工(2017年2期)2017-06-06 23:00:31
西部廣播電視(2015年5期)2016-01-16 03:45:06
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2010年1期)2010-01-23 06:35:12
