基于支持向量機的炒作微博識別方法
2015-02-20 08:15:08董雨辰羅軍勇
計算機工程 2015年3期
董雨辰,劉 琰,羅軍勇,張 進
(數學工程與先進計算國家重點實驗室,鄭州450001)
基于支持向量機的炒作微博識別方法
董雨辰,劉 琰,羅軍勇,張 進
(數學工程與先進計算國家重點實驗室,鄭州450001)
微博是輿論傳播的中心和渠道,同時參與輿論的形成、發展與引導過程,其自媒體發布、意見領袖參與等因素在一定程度上造成了微博謠言、虛假炒作、社會動員等現象。針對炒作微博的傳播特點,分析其群體的隱蔽策劃現象,挖掘出普通微博和炒作微博在傳播網絡結構、轉發增量統計等方面的差異。通過社交網站的應用程序接口對目標微博的所有評論、轉發和點贊用戶進行信息獲取,構建該微博的傳播網絡,利用社團模塊度、平均最短路徑和網絡直徑這3個屬性度量該網絡的緊密程度,基于支持向量機對所抽取的微博進行分類,進而識別出炒作微博。實驗結果表明,該方法對微博傳播用戶的屬性信息依賴小以及傳播網絡結構特征敏感,并且具有較高的炒作微博識別準確率。
社交網絡;炒作群體;炒作微博;社團模塊度;網絡直徑;平均最短路徑;支持向量機
1 概述
隨著移動終端的大規模普及,微博、Twitter、Facebook等社交網站迅速地融入到人們的日常生活中。微博傳播是一把雙刃劍,一方面,為突發事件中的信息公開提供了一個快速響應平臺,在一定程度上彌補了傳統媒體和其他網絡的不足。另一方面,由于微博新聞的發布真實性無法得到保證,可能會被利用成為謠言傳播的載體和不滿情緒的導火索,甚至給國家和社會穩定造成嚴重的后果。顯示社交網絡能量的一個標志性事件是2008年奧巴馬的公關團隊嫻熟地運用Facebook,Twitter,YouTube和Flickr等平臺,為奧巴馬的成功競選起到關鍵作用,在此之后的2010年“茉莉花事件”、2011年的倫敦
騷亂以及2011年和2013年埃及的2次政變等事件,都能看到社交網站在背后推波助瀾的痕跡。研究發現,熱門微博傳播中人為操縱的虛假信息轉發量極大,1%的垃圾消息發送者創造了49%的轉發量[1]。出現在互聯網上的“網絡水軍”、“網絡推手”等利用社會媒體散布謠言和虛假信息,開展不正當商業競爭,買賣粉絲,操控網絡輿論,這些網絡公關行為,嚴重干擾了正常網絡輿論秩序[2]。
社交網站上的熱門微博按轉發、評論、點贊數量以及在一定時間內被轉發和評論的頻率等一系列參數綜合計算排出。這樣就使得一些個體或商家甚至不法分子為了達到某種宣傳作用,不惜借助微博營銷公司,雇傭草根大號、名人微博,乃至于雇傭控制大量僵尸粉絲的黑客對自身的博文進行廣泛傳播,在短時間內造成熱門微博的假象,以此擠進社交網站的熱門微博榜單,然后信息就像被吹開的蒲公英,向不同方向進行擴散,屬于典型的蒲公英式傳播模型,也稱之為裂變式傳播或爆炸式傳播。簡單來說,蒲公英效應就是以一個動作為出發點,最終達到多重效果。事實上,在微博營銷中存在大量蒲公英效應。
本文對炒作微博的轉發、評論行為進行有效預測和識別,并挖掘出起到重要傳播作用的關鍵節點,提出基于支持向量機(Support Vector Machine, SVM)的炒作微博識別方法。在微博傳播網絡中使用模塊度峰值、平均最短路徑和網絡直徑作為傳播網絡結構度量的主要參數,基于SVM綜合多種參數進行分析,進而識別炒作微博。
2 相關工作
隨著Web2.0的發展,社交類網站的影響能力和輻射人群日益壯大,消息的真偽以及是否存在人為的操控言論的走向,逐漸成為網絡輿情研究的新熱點。文獻[3]運用基于關鍵詞的信息監視器,收集數據自動評估信息的新聞價值的方法,對Twitter的信息可信度進行評估。文獻[4]提出基于事件圖表優化的可信度分析方法。文獻[5]提出社會性網絡信息傳播模式下的網絡議題升級模型,從受眾升級、媒體升級、輿情升級3個方面剖析議題的發展趨勢。在傳播時間上,文獻[6]將網絡媒體按信息來源進行區分,發現網絡論壇信息傳播隨時間變化的相似性與論壇作者在發表量上的不平等特征。一些學者利用傳染病傳播模型對輿情傳播進行研究。文獻[7]把傳染病模型應用在媒體環境下,利用免疫的輿情傳播模型對信息的傳播進行控制。網絡結構對社會網絡信息的傳播有很大影響,利用復雜網絡方法對網絡傳播動力機制進行分析開辟了輿情信息傳播的新領域。文獻[8]通過研究發現規則網絡比小世界網絡中信息傳播的范圍更大,速度也更快。文獻[9]認為網絡信息傳播不僅依賴于小世界網絡中的最短路徑,還與網絡行為的多次社會性強化有關。意見領袖在信息傳播中充當了重要的角色,影響力和感召力大的名人,可以影響人們的購買行為和政治觀點。文獻[10-11]使用粉絲數量和微博轉發數量對用戶影響力進行衡量,結果表明粉絲數量多的用戶微博不一定會得到很多的轉發或者評論。文獻[12]借鑒PageRank算法的思想,設計了TwitterRank算法來衡量一個用戶在某一主題內的影響力,主要思想是給定一個主題,用戶的影響力定義為他的所有粉絲的影響力之和。
上述學者對于微博的可信度和用戶的影響力的研究,基本上解決了有關鍵用戶且由其引起的信息傳播的微博輿情分析。實際上網絡炒作中還有一種情況是其傳播的主體為數量龐大的水軍;這些水軍由網絡公關公司雇傭的大批社會閑散人員組成,并由公關公司挑選出來的組長負責管理,統一行動[13]。有的組長是網絡紅人或微博草根大號,炒作的行為是有組織、有計劃、有目的的群體策劃。本文將針對此類炒作微博,在真實的社交網絡環境中,分析其傳播模式,研究其特殊的成員組成結構,梳理出其炒作目標,尋找出其隱含的炒作痕跡。然后運用社團模塊度、平均最短路徑、網絡直徑和基于支持向量機挖掘炒作團體的潛在屬性,識別出炒作微博。
3 炒作微博及傳播節點分析
3.1 炒作微博的群體策劃現象
炒作社團組成結構緊密且封閉,從炒作微博單位時間內的轉發量(某化妝品炒作廣告轉發量見圖1)上看也異于熱門微博的單位時間內的轉發量(2013年4月20日四川雅安地震一條微博轉發量見圖2)。可以看出,一條熱門微博的產生到其傳播量的爆發經歷了一定的潛伏期,并逐漸成指數型增長,在增長到一定數量級后,呈現平衡狀態,隨著時間的增加,逐步衰減消亡。
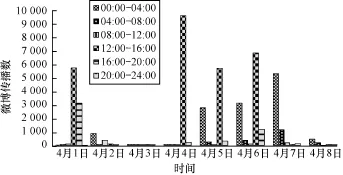
圖1 某炒作微博單位時間內的轉發量
炒作微博單位時間內的轉發量生成圖并沒有出現潛伏期和成長期,而是直接在經過幾個數據量低的時間片后,傳播量飆升到爆發狀態,緊接著便迅速衰落至初始狀態,在隨后的時間片內呈現出極低的傳播量,直至死亡,或者再出現幾次這種規律性的爆發,這是由于博主在付費給水軍客服后,水軍客服安排炒作團體為指定的微博進行轉發和評論;然后博主對效果進行評估,選擇是否繼續雇傭水軍為其博文進行后續炒作,所以炒作微博的轉發圖會呈現出特殊的傳播走勢。
圖3(a)展示了一個典型蒲公英式的熱門微博傳播圖,體現出核爆式一二三級沖擊波和大小V(指在微博上十分活躍、又有著大群粉絲的公眾人物。通常把粉絲在5×105以上的稱為網絡大V)轉發的典型傳播方式。圖3(b)是一條典型的炒作微博信息傳播,其傳播過程中充斥著大量的炒作團體,少有離散節點的信息傳播,主要是依附于大V下的粉絲在擴撒信息。

圖3 典型熱門微博和炒作微博的信息傳播結構
3.2 微博傳播網絡
與人人網、QQ好友等傳統的社交網絡不同,微博的用戶與用戶之間以一種“弱關系”的形式存在的,用戶關注某人成為其粉絲也只需要單方面的認可,人與人之間并不存在太多的感情聯系[14]。圖4(a)是從人人網中提取的一個基于強關系的社交網絡結構,網絡中的節點呈現出同構的特性。圖4(b)為新浪微博的一個弱關系社交網絡結構,其中,黑點是用戶節點;白點是粉絲節點;實線為關注關系;虛線是信息的傳播關系。正是這種微博用戶彼此間“弱關系”的存在,促使信息不斷地向外擴散,以及不同影響力的節點對信息傳播的強弱起到了關鍵性作用,組成了微博特殊的傳播方式。由于微博用戶的社會地位與公眾認知度的不同,使得其在信息傳播的影響力度方面也有天壤之別。因此,若能找出個人或者團體在微博信息傳播中的影響范圍或者說在微博傳播節點存在社團(群體策劃行為)的可能性,是預防與識別網絡惡意炒作、煽動的關鍵[15]。
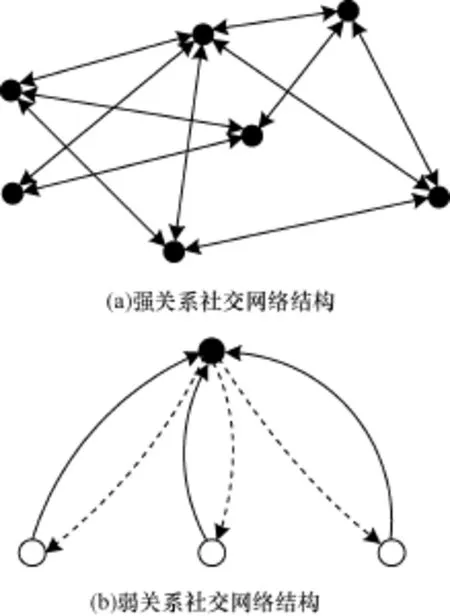
圖4 典型強弱關系社交網絡結構
微博用戶間存在關注關系和傳播關系的雙重特征,以圖4(b)所示微博關注網絡為例,用戶A關注了用戶D,A與D之間存在關注關系A→D;當用戶D發表一條微博M時,A會收到微博M(D的所有粉絲A,B和C都會收到該微博),A與D之間又存在傳播關系D→A;這樣用戶A與D之間同時存在A→D表示的關注關系以及D→A表示的傳播關系。若用A?D統一表示用戶間的這種復合關系,可以定義微博傳播網絡G=(V,E),其中,V為微博用戶集合;?v∈V表示微博中的一個用戶;E={eij|?vi,vj∈V,vi關注vj或vj關注vi}為微博中用戶間的傳播路徑集合,?eij∈E為無向邊,表示用戶間的關注關系和傳播關系。
3.3 傳播節點的重要性
在微博的傳播中,關鍵節點(網絡大V、名人、不同領域的意見領袖)的轉發起到了重要作用[16]。關鍵節點是指在信息傳遞和人際互動過程中具有影響
力和活動力的少數人[17],這些關鍵節點在某種程度上引導人們的消費、言論和政治觀點。使用粉絲數和轉發數對用戶影響力進行研究,發現粉絲數多的用戶微博不一定會有很多的轉發及評論數[11]。由于炒作微博是為了進入運營商的熱門微博榜單,進而被更廣泛的傳播。
4 基于群體策劃現象的炒作微博識別方法
4.1 微博傳播網絡的參數度量與選擇
微博前期的炒作行為伴隨著大量的刻意轉發和評論,這都需要巨大的人力資源投入。為了達到數量上的要求,炒作用戶一般會聚集為一個個團體,聽從某些關鍵人物的領導,對指定微博進行轉發和評論。微博傳播過程中,傳播節點的聚集程度是本文研究和識別炒作微博的關鍵問題。
4.1.1 社團模塊度
微博的傳播網絡符合社團網絡的無向圖結構,為了判斷傳播節點的聚集程度,引入社團模塊度的概念,用一個模塊函數[18]來模擬、判定社團的緊密程度,定量地描述網絡中社團存在的可能性,并衡量網絡社團結構的劃分。模塊度是指網絡中連接社團結構內部頂點的邊所占的比例與另外一個隨機網絡中連接社團結構內部頂點的邊所占比例的期望值相減得到的差值。這個隨機網絡的構造方法為:保持每個頂點的社團屬性不變,頂點間的邊根據頂點的度隨機連接。利用函數Q定量描述社團劃分的模塊化水平:
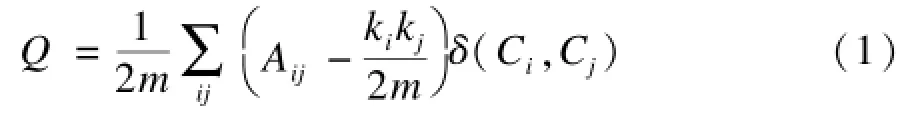
其中,ki和kj是節點的度值;Ci是節點i所屬社團;m是網絡總邊數。當Ci=Cj時,δ(Ci,Cj)=1,否則為0;Q值在0~1之間,一般以Q=0.3作為網絡具有明顯社團結構的下限。如果社團內部頂點間的邊沒有隨機連接得到的邊多,則Q函數的值為負數。相反地,當Q函數的值接近1時,表明相應的社團結構其內部聯系高度緊密。在實際網絡中,Q存在峰值,模塊度越接近峰值,社團結構越明顯,峰值常位于0.3~0.7之間。
4.1.2 平均最短路徑
最短路徑是指在一個賦權圖的2個節點間找出一條最小權的路徑,平均最短路徑是指一個網絡中兩點之間最短路徑的平均值。而社交網絡拓撲特征則體現了現實網絡中最短路徑的一些內在規律。不同于隨機網絡,社交網絡中的大部分節點多在小范圍內相互連接,呈現出一定的高聚集系數特性,也不同于規則網絡,社交網絡結構中任意兩點間的距離都較短,其原因在于一些連接不同簇的“長邊”。文獻[19]提出弱連接,認為弱連接比強連接更能穿越不同的群體,因此能觸及更多的人,穿過更大的社會距離。從這個角度出發,解釋了小團體內部的互動如何匯聚成了大規模的結構形態。因此,弱聯結理論將微觀的和宏觀的社會網模型聯系在一起。在此利用最短路徑來識別微博的擴散范圍。如果2條微博的傳播數目相同,而傳播節點間的平均最短路徑差距較大,便認為平均最短路徑值大的微博,其傳播層數多,影響力大,而平均最短路徑小的微博,傳播多集中在某個或幾個轉發者的粉絲間傳遞,以致于傳播層數少,影響力弱。通過計算微博傳播中節點平均最短路徑,判斷節點間的緊密程度,以此識別出炒作微博。本文先使用Floyd[20]算法求解出微博傳播圖中所有節點之間的最短距離,再求距離的平均值得出平均最短路徑長度。主要思想是從任意2個頂點vi到vj距離的帶權鄰接矩陣開始,依次插入一個頂點vk,然后將vi到vj間的已知最短路徑與插入頂點vk后可能產生的vi到vj的距離比較,取兩者之間的較小值,得到新的距離矩陣。通過循環迭代,得到的最后帶權鄰接矩陣Dn就反映了所有頂點對之間的最短距離信息。算法具體描述如下:
(1)定義初始的距離矩陣D0:

(2)根據以下公式構造迭代矩陣Dk:
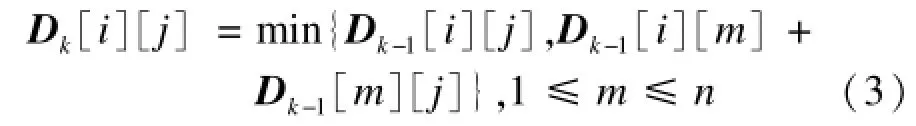
(3)當Dk=Dk+1,終止算法;否則,重復步驟(2)。
4.1.3 網絡直徑
網絡直徑是指網絡中任意節點間距離的最大值,一般用鏈路數來度量。網絡直徑能在一定方面反映社交網絡中信息的傳播廣度,對于傳播節點相同的微博信息傳播網絡來說,網絡直徑越長,傳播的廣度越大。本文用網絡直徑來表示微博信息傳播的廣度。由于炒作微博大多是由水軍團體傳播的,其傳播范圍也僅限于幾個水軍群體之間。而熱門微博符合蒲公英的傳播方式,擴散范圍廣、受眾人群多、網絡直徑大。本文使用網絡直徑來判斷微博傳播的范圍。
4.2 基于SVM的炒作微博識別方法描述
支持向量機的主要思想是:對給定有限數量的訓練樣本的機器學習,通過在原空間或投影后的高維空間中構造最佳超平面,將2種類別的訓練樣本
線性可分,再使用線性可分的原理判斷分類邊界。在高維空間中,它是一種線性劃分,而在原有數據空間中,它是一種非線性劃分。
首先考慮炒作微博和正常微博的分類問題,設置模式樣本點(xi,yi)服從樣本空間X×Y上的某個未知概率分布P(x,y),其中,X代表二維向量(x1表示平均最短路徑,x2表示微博傳播網絡直徑);Y為模塊度(x1∈(1,+∞),x2∈(1,+∞),y∈(0,1))。目的是尋找一個超平面將數據劃分開。本文使用最大間隔法,分類邊界是值從分類面分別向2個類的點平移,直到遇到第1個數據點,2個類的分類邊界的距離就是分類間隔。
分類平面表示為(w·x)+b=0,其中,x是多維向量。分類間隔的倒數為:。所以,該最優化問題表示為:
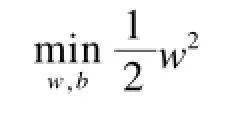
s.t.yi((w·xi)+b)+1)≥1,i=1,2,…,l(4)其中,約束要求各數據點(xi,yi)到分類面的距離大于等于1,yi為數據分類。
4.3 基于SVM的炒作微博識別框架
基于SVM的炒作微博識別框架主要由數據預處理器、SVM分類器、SVM訓練和決策響應等主要部分組成,如圖5所示。
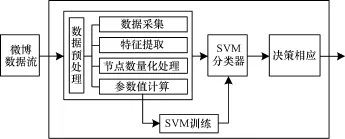
圖5 基于SVM的炒作微博識別框架
其中,數據預處理是對大量微博數據流進行獲取、分類和提取,包括數據采集、特征提取、節點數向量化處理、參數值計算功能。數據采集是通過API對微博社交網站運營商服務器上的數據進行采集。特征提取是對傳播微博的用戶ID及傳播路徑進行提取。節點數據量化處理是對這些TXT文本數據按照微博信息傳遞的路徑和向量的指向性質,對其擴散指向進行量化,映射出整條微博的傳遞方向。參數值計算是計算社團模塊度和最短路徑。SVM分類器是對這些參數進行分類后把結果輸入相應單元進行最后決策。
整個過程由2個階段完成,即訓練階段和測試階段。首先把訓練數據(例如,某冷飲廠商在一時間段的全部微博數據,包括炒作微博和正常微博)通過數據轉換轉化為SVM分類器可識別的數據。在訓練階段,利用訓練數據訓練SVM對炒作微博進行分類,分析訓練結果。在測試階段,將未知的測試數據進行數據預處理,得到判斷參數,進行炒作微博的識別。最后對檢測結果進行人工識別,給出識別準確率,并對識別誤差進行分析。
5 實驗結果與分析
5.1 訓練數據集的選取與采集
本文的訓練數據集采自于2013年5月-10月人工識別某冷飲廠家雇傭水軍炒作傳播數在10 000以上的數據以及微博風云榜上的熱門微博。提取單條微博的傳播路徑和節點信息,對傳播節點進行分析,獲取其粉絲和關注者的數據,用于計算單條微博傳播節點間的緊密程度以及判斷是否有社團存在的可能性。
在對炒作微博的傳播路徑節點信息進行分析后,發現炒作微博的社團模塊度峰值Q都超過了0.8,模塊度峰值最高的是某冷飲廠商雇傭水軍詆毀競爭對手的微博,2天傳播30 883條,模塊度峰值Q=0.903,并且出現微博評論數接近轉發數的狀況。對其官方微博進行分析,其擁有百萬粉絲量,日均微博數4.79條,發布微博分為4類:(1)產品宣傳; (2)別人對其的炒作,官方進行轉發;(3)貶低競爭對手;(4)原創或轉發的一般微博。經對其半年官方微博進行跟蹤發現,對自己產品進行宣傳促銷和詆毀直接競爭對手這2類微博,轉發數和評論數超過其發布的原創微博和轉發微博幾十個數量級。在對其歷史微博數據和粉絲數目演化進行還原,存在明顯買粉絲情況,在個別時期達到50%(25.6×104)的增長量(圖6),而平時僅百余人的粉絲增長數目。對粉絲質量進行分析可見,在大規模粉絲增長的情況下,粉絲明顯呈現出僵尸粉絲和水軍的特性(注冊時間集中、評論及轉發內容多是廣告和詆毀性質的博文)。在與對手競爭最激烈的2013年5月-6月,其雇傭的大量水軍對其博文進行轉發與評論(圖7),造成了極大的社會影響力。
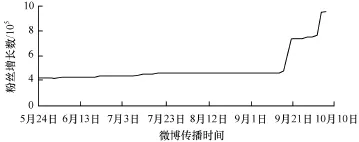
圖6 某冷飲微博粉絲增長趨勢
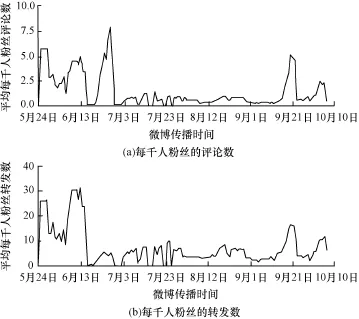
圖7 某冷飲微博每千人粉絲的評論與轉發量
5.2 結果分析
在對某冷飲廠家傳播量超10 000的微博數據進行分析后,再與之前獲取的熱門微博數據進行對比分析,通過SVM分類器對2種類型的微博數據進行分類(圖8),可以看出兩者存在明顯區別,炒作微博的模塊度峰值遠超出正常社團的0.3~0.7的區域,并且平均最短路徑為3.395,也明顯背離六度分隔理論,最長網絡直徑在7以內,與傳播數相同的熱門微博最長網絡直徑23相比,存在明顯差距。對已識別出疑似的炒作微博進行傳播節點的出度分析(一個節點被直接轉發一次,稱其出度值為1)。按節點出度大小進行排列后,可知出度大的節點與出度小的節點存在指數倍差距(圖9)。
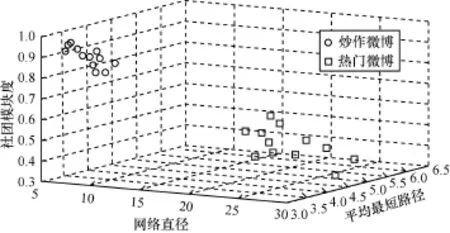
圖8 炒作微博與熱門微博的SVM分類
圖9 炒作微博中的大V參與程度
某些出度較大的節點在此冷飲廠商的多條炒作微博中重復出現,而該廠家正常的微博轉發節點并沒有這些大V參與。
對這些疑似炒作微博中的大V進行分析,提取大V的用戶名,在國內某水軍炒作網站上進行查詢,如圖10的博主列表,在某冷飲廠商的炒作及抨擊競爭對手的博文中,參與轉發的大V,有93%的炒作大號存在于此網站的列表中。
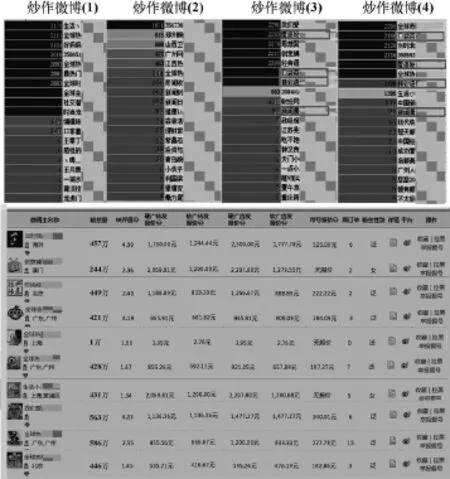
圖10 參與炒作的大V及其報價表
不同的粉絲量、轉評值(一條微博中進行轉發和評論數目的比值)決定了其不同的定價,并且每個炒作大V都表明了硬廣轉發報價、軟廣轉發報價、硬廣直發報價、軟文直發報價和炒作平臺等信息,甲方可根據自己的需求和傳播量進行選擇。本文所選取的炒作微博廠家為了得到更好的傳播效果和影響力,每次發布產品宣傳和詆毀競爭對手的博文,都會雇傭多個炒作大號對其博文進行傳播。如果把其雇傭炒作團體進行轉發與評論的微博從炒作賬號的出度刪除后,炒作微博的平均轉發數目為116.45條,與其正常微博平均轉發數的61.48條相比,炒作微博的影響力并沒有得到有效提升。
圖11反映了圖10中炒作微博(1)的傳播路徑圖。圖10中顯示了此條炒作微博包含了10個出度在2 000以上的大V賬號ID、出度為347和247的2個較小賬號ID以及其余的出度在10以內的賬號ID。展現了10個大V和2個較小賬號的微博傳播消息結構。

圖11 對應圖10炒作微博(1)的微博信息傳播結構
5.3 測試數據集的選取與采集
本文選取國內新浪微博2013年7月2日前轉發量超過10 000的433條微博數據進行測試實驗。通過新浪微博開放API得到相關數據(2013年7月2日API升級后,非授權用戶的數據只能通過business API獲取)。數據及數據間的關系為:
(1)微博屬性:發布時間,轉發數,評論數,轉發者ID,評論者ID;
(2)用戶關系:用戶ID,關注用戶ID,粉絲ID。
5.4 測試結果誤差分析
通過對這433條轉發量超過10 000的微博數據進行實驗,使用基于SVM的炒作微博識別方法發現疑似炒作微博57條,然后對測試數據進行人工識別,確定為炒作微博的有43條,如表1所示。

表1 基于模塊度與最短路徑的炒作微博識別
對誤判為炒作微博的數據進行分析,發現其主要由三部分組成:(1)大V或名人粉絲之間的口水戰;(2)大V或名人重復轉發自己的微博;(3)低俗博主的微博。它們的相同特征是在微博的傳播過程中,參與的人群相對單一。如圖12所示,它的社團模塊度峰值Q=0.776,L=3.739,微博是由一網絡名人L某評論另一網絡名人Z某后,對方回應,而引起的雙方粉絲在此條微博的評論中互相攻擊。參與傳播的人群為雙方的粉絲,這是造成了此條微博的模塊度增高,最短路徑降低的原因。
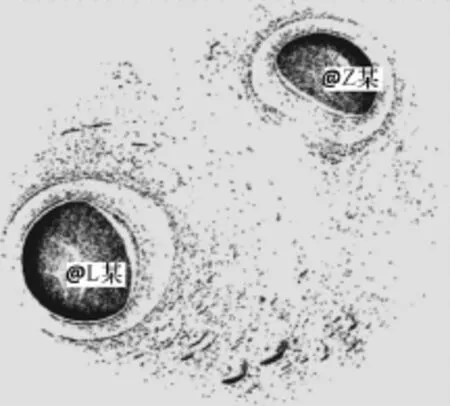
圖12 網絡名人間口水戰的微博信息傳播結構
圖13 社團模塊度峰值Q=0.799,L=3.662,被誤判為炒作微博的原因是此大V為了突出這條微博的重要性,不斷的重復轉發自己的微博,由于在傳播過程中,主要是其粉絲團對本條微博進行轉發或多次轉發,在微博傳播過程中呈現出的社團結構單一,而被誤判為疑似炒作微博。

圖13 大V多次轉發迅速擴散的微博信息傳播結構
圖14 社團模塊度峰值Q=0.817,L=3.657被誤判為炒作微博是其大V博主的特性決定的,此類博主的粉絲多是占廣大網民中基數較大的普通網民,其帶有娛樂感的搞笑微博引發粉絲互動帶動網民跟風,評論數超過了轉發數的2倍以上。微博大V們顧及自己的社會影響力與自身形象往往不會關注與轉發此類博主的微博,從而造成此類微博雖然擁有眾多轉發數,但沒有轉發深度,只是粉絲們的直接轉發,并不能引起深層次的轉發效果。

圖14 某女星的微博信息傳播結構
檢測時間為在API獲取單條微博全部傳播節點后,對數據進行分析的時間。由于新浪微博對不同權限的開發者提供了不同的API調用權限(以Business API為例,作為開發者的最高權限,數據的獲取速度僅和帶寬有關),因此檢測時間并不包括數據獲取的時間消耗。實驗在CPU為2核、主頻2.53 GHz,內存為4 GB的一臺筆記本上運行,其結果如表2所示。
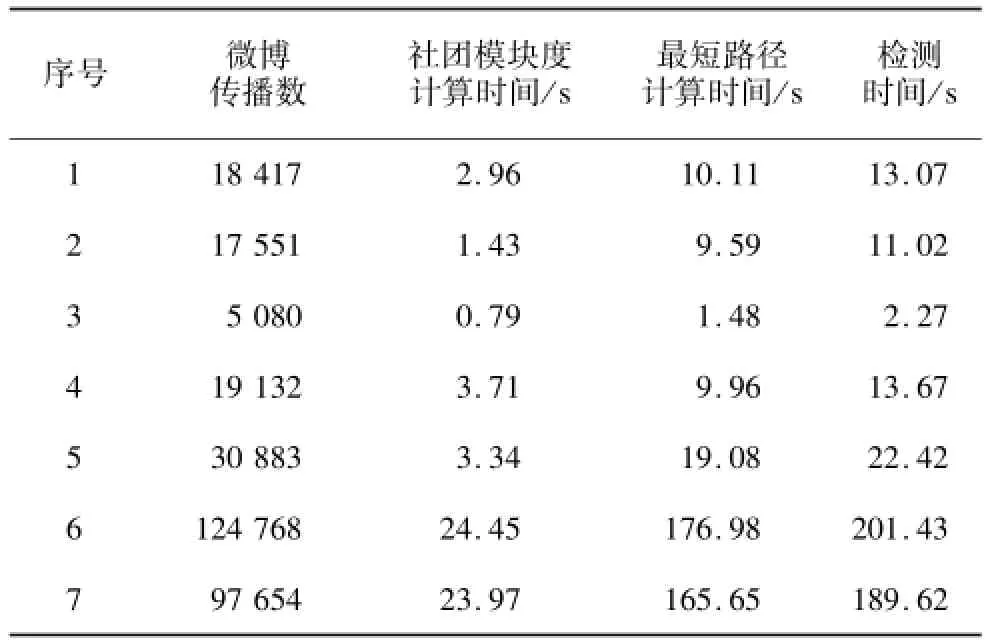
表2 算法檢測時間
從表2可以看出,本文算法復雜度是隨著微博傳播數的增多及傳播節點間聯系的復雜程度成線性增長。測試數據中最大的傳播數為124 768,算法平均消耗時間在3 min以內,其中最快檢測時間達到13.07 s,傳播數為97 654條的炒作微博進入了當日的熱門微博榜單。
6 結束語
在發生有組織的炒作事件后,定位信息發生源和其轉發關鍵用戶,對信息進行實時監控預警是防止惡意網絡造謠事件發生的關鍵。本文基于社團模塊度與六度分隔理論,設計基于群體策劃現象的炒作微博識別方法。實驗結果表明,基于模塊度與最短路徑的炒作微博識別方法,可以有效識別炒作微博,并且具有較高的準確性。通過實驗證明了該方法具有一定的合理性和優勢,但在今后工作中還將對以下問題展開研究:(1)區分炒作微博的類型以鑒別微博營銷的目的,加入情感分析,對于炒作微博的博文情感值和評論的情感值進行分析和判斷,建立炒作微博字典,以便能準確地區分炒作微博是自我營銷行為還是惡意的詆毀和攻擊;(2)對名人或官方微博的影響因子進行細度優化,克服微博名人效應對識別準確率的干擾。
[1]Yu L L,Asur S,Huberman B A.Artificial Inflation:The True Story of Trends in Sina Weibo[C]//Proceedings of 2012 International Conference on Social Computing.Amsterdam,Holland:IEEE Press,2012:514-519.
[2]任一其,王雅雷,王國華,等.微博謠言的演化機理研究[J].情報雜志,2012,31(5):50-54.
[3]Castillo C,MendozaM,PobleteB.Information Credibility on Twitter[C]//Proceedings of WWW’11.New York,USA:ACM Press:[s.n.],2011:675-684.
[4]Gupta M,Zhao Peixiang,Han Jiawei.Evaluating Event Credibility on Twitter[C]//Proceedings of SDM’12.Anaheim,USA:IEEE Press,2012:153-164.
[5]顧明毅,周忍偉.輿情及社會性網絡信息傳播模式[J].新聞與傳播研究,2009,16(5):67-72.
[6]劉 穎,李欲曉.網絡輿情傳播特征分析[J].北京郵電大學學報:社會科學版,2011,13(4):1-6.
[7]陳 波,于 泠,劉君亭,等.泛在媒體環境下的網絡輿情傳播控制模型[J].系統工程理論與實踐,2011, 31(11):2140-2150.
[8]Centola D.The Spread of Behavior in an Online Social Network Experiment[J].Science,2010,329(5995): 1194-1197.
[9]Lu Linyuan,Chen Duanbing,Zhou Tao.The Small World Yields the Most Effective Information Spreading[J].New Journal of Physics,2011,13(12):1230-1235.
[10]Kwak H,Lee C,Park H,et al.What is Twitter,A Social Network or a News Media?[C]//Proceedings of the 19th International Conference on World Wide Web.New York,USA:ACM Press,2010:591-600.
[11]Meeyoung C C.Measuring User Influence in Twitter: The Million Follower Fallacy[C]//Proceedings of the 4th International AAAI Conference on Weblogs and Social Media.Palo Alto,USA:AAAI Press,2010: 174-179.
[12]Weng J.TwitterRank:Finding Topic-sensitive Influential Twitterers[C]//Proceedingsofthe3rdACM International ConferenceonWebSearchandData Mining.New York,USA:ACM Press,2010:261-270.
[13]丁乙乙,周元英.誰在操控網絡輿論?[J].IT時代周刊,2010,(1):5.
[14]Facebook Research Report:TheImportanceofSocial Network of Weak Ties[EB/OL].(2012-05-11).http:// www.sina.com.cn/i/2012-01-18/13286651169.shtml.
[15]Han Yanni,Li Deyi,Wang Teng.Identifying Different Community Members in Complex Networks Based on Topology Potential[J].Frontiers of Computer Science in China,2011,5(1):87-99.
[16]Wang Chenying,Yuan Xiaojie,Wang Xin.An Efficient Numbering Scheme for Dynamic XML Trees[C]// Proceedings of InternationalConference on Computer Science and Software Engineering.Washington D.C.,USA: IEEE Press,2008:704-707.
[17]Lazarsfield P.The People’s Choice[M].New York, USA:Columbia University Press,1948.
[18]Newman M E J,GirvanM.FindingandEvaluating Community Structure in Networks[J].Physical Review E,2004,69(2).
[19]Granovetter M S.The Strength ofWeak Ties[J].American Journal of Sociology,1973,78(6):1360-1380.
[20]Lin S.Computer Solutions of the Traveling Salesman Problem[J].Bell System Technical Journal,1995, 44(10):2245-2269.
編輯 陸燕菲
Hype Microblog Recognition Method Based on Support Vector Machine
DONG Yuchen,LIU Yan,LUO Junyong,ZHANG Jin
(State Key Laboratory of Mathematical Engineering and Advanced Computing,Zhengzhou 450001,China)
Microblog is not only a center or channel of mass media,but also involved in the formation,development and guidance of public opinions.The propagation of speculation microblog which is released from We-media,opinion leaders or some other users,causes microblog rumors,false hype,social mobilization and other problems.This paper analyzes the phenomenon of covert planning,mines the difference of the structure in communication networks and the incremental statistics of forwardings between the ordinary and the speculation.A novel algorithm for hype microblog recognition is proposed in this paper based on Support Vector Machine(SVM)which uses the modularity peak spread and the average diameter of the shortest path in propagation network.The proposed method has advantages of less dependence on user profile information and is sensitive to the structure of propagation networks,and it has higher recognition accuracy.
social network;hype group;hype microblog;community module degree;network diameter;average shortest path;Support Vector Machine(SVM)
董雨辰,劉 琰,羅軍勇,等.基于支持向量機的炒作微博識別方法[J].計算機工程,2015,41(3):7-14.
英文引用格式:Dong Yuchen,Liu Yan,Luo Junyong,et al.Hype Microblog Recognition Method Based on Support Vector Machine[J].Computer Engineering,2015,41(3):7-14.
1000-3428(2015)03-0007-08
:A
:TP393
10.3969/j.issn.1000-3428.2015.03.002
國家自然科學基金資助項目(61309007);國家“863”計劃基金資助項目(2012AA012902);國家科技支撐計劃基金資助項目(2012BAH47B01)。
董雨辰(1988-),男,碩士研究生,主研方向:網絡信息安全,網絡態勢感知;劉 琰(通訊作者),副教授、博士;羅軍勇,教授;張 進,碩士研究生。
2014-04-11
:2014-05-19E-mail:ms_dyc39@aliyun.com
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
