基于特征值的重力場定位新方法 *
2015-03-15 01:37:11周學文
艦船電子工程 2015年10期
胡 鵬 劉 鈞 周學文
(中國艦船研究設計中心 武漢 430064)
?
基于特征值的重力場定位新方法 *
胡 鵬 劉 鈞 周學文
(中國艦船研究設計中心 武漢 430064)
利用重力場定位方法來確定載體的準確位置的方法,是近年來研究較多的新技術之一。但由于地球重力場分布具有差異性,所以不是所有的區域都適合應用重力場定位方法。論文提出綜合利用重力場特征值及灰關聯分析的定位的新方法,即根據重力場特征值的不同由訓練好的BP網絡來判斷該區域是否適合進行匹配定位,如適合則根據灰關聯匹配的閾值,找出最佳匹配點,進而確定載體位置。論文分析了該算法的理論基礎并提出了具體的實現算法,經過仿真實驗表明,此算法的運算速度快、匹配精度高、具有一定的抗測量誤差的能力。
重力場特征值; 重力場匹配; 閾值; 綜合特征參數
Class Number U666
1 引言
慣導能夠不依賴外界信息,不受外界條件限制,全天候提供載體的速度、位置、姿態等信息。但慣導有隨時間積累的誤差,如果不定期修正,就會限制其發揮效能。目前主要采用衛導校正、無線電校正和天文導航校正等方法對慣導進行校正。這些方法都會增加載體被探測和發現的危險,因此需要一種不必載體靠近水面又不發射信號,就能對慣導進行修正的方法。重力場輔助導航技術為實現這一目標提供了新的技術途徑。
2 重力場導航的原理
地球表面的重力場在不同地區的差異性構成了一種典型特征,利用這種特征來確定載體所在的地理位置,就是重力場導航所依據的基本原理。重力場匹配(Gravity field contour matching)是一種自主式航行器導航方法,通過實時采集一維重力場場強度來獲得二維定位。
在載體進行運動之前,需要首先把預先測量好的相應區域的重力場信息存儲起來,構成數字重力場基準數據庫。當載體運動到待匹配區域時,由專用重力傳感器測量所處位置的重力場特征,載體運動一段時間后,測量得到一系列實時重力場特征值,簡稱測量序列。把測量序列與基準數據進行相應的匹配,找出基準數據中與測量序列最相匹配的位置序列,以此作為載體的位置估計信息。這就是重力場導航的基本原理。
3 重力場特征值介紹
重力場導航方法雖然有其獨特的優勢,但是也有其局限性:
1) 該方法只能作為輔助的導航方法,必須和慣性導航系統結合使用;
2) 重力場導航方法需要以高精度、高分辨率的重力場測量數據和重力場特征圖為基礎,重力場特征的豐富與否直接關系到重力場匹配的定位精度。如果重力場特征信息不夠豐富則會極大地影響定位精度。所以在應用重力場定位方法之前必須對適用區域進行區分。
通過對重力場區域特征的分析,可以確定哪些區域適合進行重力場匹配定位,而哪些區域并不適合進行匹配定位,可為下一步的匹配定位工作奠定良好的基礎。
通常情況下,數字重力場圖采用網格矩陣的形式存儲在計算機內,以離散點的形式表示重力場的變化規律,每一組離散點都包含了重力場的位置信息和強度信息。由于目前還沒有統一的標準描述重力場場的特征,所以可以運用數理統計、隨機場理論及信息論的相關知識,借鑒其它地理場特征參數定義,對重力場特征進行研究,并以此作為重力場匹配區域選擇的特征向量。
設某區域重力場的經緯度跨度為M×N的網格,f(i,j)為網格點(i,j)處的重力場值,其中,(i,j)對應一組經緯度坐標(φ,λ)。通過對重力場圖數據的統計分析,可獲得常用的重力場特征值如下。
3.1 重力場標準差
標準差反映了一個樣本集合總體上偏離其平均水平的程度,由此可知,重力場場標準差可以反映重力場場強度的離散程度以及整個重力場場的起伏程度。重力場標準差越大,重力場場所含有的信息量越大。設M×N區域的重力場的平均值為f,則重力場場標準差可定義為
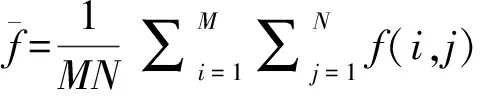
3.2 重力場費歇信息量
費歇信息量來自于著名的克拉美—勞(Cramer-Rao)不等式(簡稱C-R不等式),利用該信息量可以度量重力場場所包含的重力場信息量。重力場信息量是指在一定的重力場場區域內,對任意點的重力場特征值能夠估計出該點在區域內位置的可能性度量。
式中xij是在重力場區域內平均分布的平面位置點坐標。理論上,重力場費歇信息量的取值范圍是從0到無窮大,但實際上不可能得到無窮大的重力場費歇信息量,它的上界是一個很大的數,其值越大,表明其含有的重力場信息越豐富。
3.3 重力場粗糙度
重力場粗糙度可以反映整個區域的平均光滑程度,刻畫細微的局部起伏,通常用σf表示。
其中
粗糙度σf與標準差之間沒有必然的聯系,但粗糙度與標準差之間的比值可以作為重力場起伏特征的度量。比值小表示相鄰采樣點間變化比較小,比值大表示相鄰采樣點間變化比整個區域起伏劇烈,含有的信息量相對豐富,更適合作為重力場匹配區。
3.4 重力熵
其中,pij為點坐標處的歸一化重力場強度,H為重力熵。重力熵反映了該重力場含有信息量的大小,因此可以用來描述重力場的性質。重力強度變化越劇烈,信息量越豐富,重力熵越小。同時由于其對噪聲不敏感,可起到剔除離散點的作用。
4 多特征參數的匹配方法
在基于單一特征參數對適配性進行評價時,一般先設定閾值,根據特征參數是否達到閾值來判斷該區域是否適合匹配。但只使用一種參數也會經常犯兩種錯誤:
1) 該區域適合進行匹配,但其特征參數未達到閾值;
2) 該區域不適合進行匹配,但其特征參數達到了閾值。
只選用了粗糙度這一種參數對多個試驗區域進行適配性評價和分析仿真試驗,結果發現只有63%的區域經判別是適合的區域,而且最后經過匹配定位取得了滿意的效果。如此大的誤判概率是不能滿足實際需求的,因此單一特征參數不適合作為適配性評價的有效依據。
在本文中提出綜合使用多種參數進行適配性的衡量指標,不妨將其稱為綜合參數來判定某個區域是否適合進行匹配定位,其定義如下:
令a為重力場標準差;b為重力場費歇信息量;c為重力場粗糙度;d為重力熵;則綜合參數X=[a,b,c,d]。
綜合參數會含有多個特征量的信息能夠避免某種特征信息量對其有過大或過小的影響,需要對各種參數進行歸一化處理。此參數具有可擴展性,如果后期有更多更合適的參數則可以方便的加入。問題的關鍵就轉化為了如何根據綜合參數來判別某個區域是否適合進行匹配定位。本文采用樣本學習的方式,利用BP網絡進行判別。
BP網絡是一種具有三層或三層以上的階層型前向神經網絡。上、下層之間各神經元實現全連接,即下層的每一個神經元與上層的每一個神經元都實現權連接,而同一層各神經元之間無連接。
BP網絡按有教師示教的方式進行學習,學習過程分為兩個階段。第一階段是信號正向傳播過程:當一對學習模式提供給網絡后,神經元的激活值從輸入層經各隱含層向輸出層傳播,在輸出層的各神經元獲得網絡的輸入響應;第二階段是誤差修正反向傳播過程:若在輸出層未得到期望的輸出值,則逐層遞歸地計算實際輸出與期望輸出之間的誤差,按減小期望輸出與實際輸出的誤差的方向,從輸出層經各隱含層逐層修正各連接權,最后回到輸入層。
本文將特征參數的向量作為BP網絡的輸入,而輸出值只有一個:1代表適合進行匹配,0代表不適合進行匹配。由于各個特征量的量綱不一致,數據差別也較大,所以在進行訓練前需要對其進行歸一化處理。通過對184塊區域的學習來確定如何進行根據綜合參數進行匹配。經過對184塊區域的綜合參數的反復學習和訓練后,該網絡訓練成熟可以進行適配區域的判斷了。
5 算法和仿真試驗
論文提出的基于特征值重力場定位算法的核心思想,是根據前期訓練好的BP網絡對區域進行適配性衡量,如果該區域適合進行匹配則進行匹配定位計算,否則給出不適合進行匹配定位的提示。算法的詳細步驟如下:
1) 計算待匹配區域的重力場標準差、重力場費歇信息量、重力場粗糙度和重力熵;
2) 將四種重力場特征量進行歸一化處理;
3) 將處理后的四種重力場特征量構成綜合參數;
4) 將綜合參數輸入訓練好的BP網絡中,由網絡進行判別該區域是否適合進行匹配;
5) 如適合進行匹配則直接使用關聯度分析法將其與經驗閾值進行比對確定定位點,如不適合進行匹配則給出提示信息。
為了驗證算法的功效,特選擇了32塊不同的區域作為試驗區域,且都為正方型的地塊,并被均分為20×20單元,每個區域的綜合參數值都有差異。在進行匹配前,首先計算出了此32塊區域的綜合參數值,經過網絡判別,有19個區域適合進行匹配定位,則只對這19個區域進行仿真定位試驗。對灰關聯度閾值的選擇參考了前期所完成的試驗的結果,但并未與最佳匹配點的灰關聯度值完全一致,一般比其小一些,這是為了防止錯過匹配點,同時也可使算法具有一定的抗噪聲能力。
為簡便起見,假設載體在每個區域的中心點開始分別沿0°、90°、180°、270°方向作勻速直線運動,在其經過試驗區域時可等間距獲得10個測量值,這10個測量值可構成待匹配的實測序列,將此序列和按各個方向從基準圖上所獲得的基準序列按算法進行匹配定位計算。所得到的仿真計算結果如表2所示。

表2 試驗情況
根據對仿真結果的分析,可以發現本文所提出的算法,對于重力特征較為明顯,即綜合參數特征較明顯的區域都能取得較好的匹配效果,能順利地找到匹配點。
6 結語
重力場匹配定位方法是一種新興的導航定位方法,和慣導結合可極大提高載體的水下導航能力。本文提出了一種新的根據重力場特征值和灰關聯度進行定位的方法,該方法在仿真試驗中的效果較好。但是目前該方法只使用了四種特征參數進行仿真試驗,還有一定的局限性,后期可以考慮利用更多的參數進行更大范圍的試驗驗證工作。
[1] 徐遵義,晏磊,鄒華勝,等.海洋重力輔助導航的研究現狀與發展[J].地球物理學進展,2007,22(1):104-111.
[2] 袁書明,孫楓,劉光軍,等.重力圖形匹配技術在水下導航中的應用[J].中國慣性技術學報,2004,12(2):13-17.
[3] 魏東.重力匹配定位方法研究[D].哈爾濱:哈爾濱工程大學,2004.
[4] 劉承香,劉繁明,劉柱,等.快速ICCP算法實現地形匹配技術研究[J].船舶工程,2003,25(3):54-56.
[5] 程力,張雅杰,蔡體菁.重力輔助導航匹配區域選擇準則[J].中國慣性技術學報,2007,15(5):559-563.
[6] 閆利,崔晨風,吳華玲,等.基于TERCOM算法的重力匹配[J].武漢大學學報(信息科學版),2009,34(3):261-264.
[7] 張飛舟,陳嘉,耿嘉洲,等.基于水下重力差異熵的導航匹配算法仿真研究[J].北京大學學報(自然科學版),2010,46(1):136-140.
[8] 吳太旗,黃謨濤,邊少峰.高精度慣性導航系統的重力場影響模式分析[J].測繪通報,2009,(5):5-8.
[9] 鄭彤,蔡龍飛,王志剛,等.地形匹配輔助導航中導航區域的選擇[J].中國慣性技術學報,2009,17(2):191-196.
[10] 王志剛,邊少峰.基于ICCP算法的重力輔助慣性導航[J].測繪學報,2008,37(2):147-157.
[11] 李姍姍,吳曉平.GAINS中重力傳感器信息的擾動改正[J].測繪科學技術學報,2007,24(4):270-273.
[12] 李斐,束蟬方陳武.高精度慣性導航系統對重力場模型的要求[J].武漢大學學報(信息科學版),2006,31(6):508-512.
A New Gravity Field Localization Algorithm Based on Feature Value
HU Peng LIU Jun ZHOU Xuewen
(China Ship Development and Design Center, Wuhan 430064)
Using gravity positioning method to discover the precise location of the carrier is one of new method developed in recent years. Because of the gravity field otherness of different area, this method is not fit to aplly in all regions. This paper puts forward one new algorithm of making use of gravity feature value and grey correlation analysis to determine carrier position, first of all building comprehensive feature value the of the matched area, secondly according to the comprehensive feature value to determine whether this area is fit to use gravity positioning method by trained BP network, finally finding out the best match point and then determining the position of the carrier in these fitted area. This paper analyzes the theoretical base of the algorithm and proposes the practical implementation algorithm. Simulation results show that the speed of that algorithms is fast and the precision of matching is high, simultaneously which has the good resistance to the measurement error.
feature value of gravity field, gravity field match, matching threshold value, comprehensive feature value
2015年4月3日,
2015年5月28日
胡鵬,男,工程師,研究方向:導航系統設計,隱蔽導航。劉鈞,女,工程師,研究方向:電力系統設計。周學文,男,工程師,研究方向:導航系統效能評估。
U666
10.3969/j.issn.1672-9730.2015.10.016
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
