一種基于HBase的空間關(guān)鍵字查詢算法*
2015-03-19 00:36:54邵奇峰
計算機(jī)工程與科學(xué) 2015年11期
邵奇峰,李 楓
(1.中原工學(xué)院軟件學(xué)院,河南 鄭州450007;2.中原工學(xué)院計算機(jī)學(xué)院,河南 鄭州450007)
1 引言
隨著智能移動設(shè)備的快速普及,基于位置的服務(wù)LBS(Location Based Services)應(yīng)用隨之大量增長,海量的空間文本數(shù)據(jù)也隨著產(chǎn)生,傳統(tǒng)關(guān)系數(shù)據(jù)庫在橫向擴(kuò)展性與大數(shù)據(jù)的及時處理上已力不從心,以可橫向擴(kuò)展的HBase分布式數(shù)據(jù)庫處理這些海量的空間文本數(shù)據(jù)無疑是最佳方案。針對海量空間文本數(shù)據(jù)集,地理區(qū)域范圍內(nèi)的空間關(guān)鍵字查詢需求日益迫切,如何在HBase數(shù)據(jù)庫中實現(xiàn)高效的空間關(guān)鍵詞查詢成為了研究熱點。基于關(guān)系數(shù)據(jù)庫的傳統(tǒng)地理信息系統(tǒng)通常使用基于樹的索引(如R 樹、四叉樹、k-d樹等)實現(xiàn)空間查詢,以此類索引處理海量空間數(shù)據(jù)效率較差,同時基于行健的HBase數(shù)據(jù)庫也較難支持傳統(tǒng)的多維空間索引。傳統(tǒng)多維空間索引不能適用于HBase數(shù)據(jù)庫,因此對空間數(shù)據(jù)進(jìn)行降維處理,以映射到一維空間進(jìn)行索引和查詢會更加簡單。
Niemeyer G[1]于2008 年 提 出 了Geohash 編碼,其把二維的經(jīng)緯度坐標(biāo)編碼成一維的字符串,可全球唯一地標(biāo)識每一坐標(biāo)點,同時空間上相鄰位置點的Geohash編碼通常具有相同的前綴,這對基于HBase實現(xiàn)鄰近點搜索具有明顯優(yōu)勢。目前Geohash 已被廣泛應(yīng)用于空間數(shù)據(jù)的處理,如Google App Engine、Lucene和Solr等[2,3],但對其在空間關(guān)鍵詞查詢,尤其是基于NoSQL 數(shù)據(jù)庫的空間關(guān)鍵字查詢的探討和研究較少,文獻(xiàn)[4]探討了基于Geohash的面數(shù)據(jù)區(qū)域查詢,但其主要基于關(guān)系數(shù)據(jù)庫實現(xiàn)。為了支持空間關(guān)鍵字查詢,文獻(xiàn)[5]和文獻(xiàn)[6]以R*樹為基本索引結(jié)構(gòu),分別提出了名為IR2樹和IR 樹的混合索引結(jié)構(gòu)。文獻(xiàn)[7]提出了另一名為S2I的混合索引結(jié)構(gòu)。但此類方案都沒有考慮大數(shù)據(jù)情況下如何保證空間關(guān)鍵字查詢的高效性和可擴(kuò)展性等問題。文獻(xiàn)[8]研究了基于HBase的空間關(guān)鍵字查詢,其僅描述了矩形空間區(qū)域內(nèi)的文本檢索,并沒涉及其它幾何形狀區(qū)域內(nèi)的文本檢索。因此,為了解決海量空間文本數(shù)據(jù)的檢索問題,本文依據(jù)HBase數(shù)據(jù)庫的keyvalue數(shù)據(jù)模型及相鄰位置點的Geohash 編碼具有相同前綴的特性,提出了一種結(jié)合Geohash 編碼與分詞技術(shù)的HBase二級索引構(gòu)建方案;實現(xiàn)了對空間信息和文本信息的同時索引,并基于該二級索引提出了一種多邊形區(qū)域內(nèi)的空間關(guān)鍵詞查詢算法;最后通過與傳統(tǒng)經(jīng)緯度索引方案的實驗比較,驗證了該算法的高效性和可擴(kuò)展性。
2 HBase數(shù)據(jù)模型
作為Apache Hadoop項目的子項目及Google BigTable的開源實現(xiàn),HBase是一個分布式的、列式存儲的NoSQL數(shù)據(jù)庫,相對于執(zhí)行批處理任務(wù)的Hadoop平臺,HBase專門用來實現(xiàn)對海量數(shù)據(jù)的實時處理[9]。HBase運行在普通商用服務(wù)器上,可平滑地橫向擴(kuò)展,以支持從中等規(guī)模到數(shù)十億行、數(shù)百萬列的數(shù)據(jù)表。表是HBase展現(xiàn)數(shù)據(jù)的邏輯組織方式,而基于列的存儲則是數(shù)據(jù)的物理組織方式,本節(jié)將從邏輯模型和物理模型兩個方面闡述HBase的數(shù)據(jù)模型。
2.1 邏輯模型
表1為一個HBase表的邏輯模型。

Table 1 Logical model of HBase表1 HBase數(shù)據(jù)的邏輯模型
HBase以表的形式組織數(shù)據(jù),表由行(Row)和列(Column)組成,每行通過唯一的行健(Rowkey)進(jìn)行區(qū)分,所有行按照行健的字典順序升序存儲。每行可以有不同的列,每列屬于一個特定的列族(Column Family)。行和列確定的存儲單元為單元格,每個單元格可以按時間保存多個版本的值,并通過時間戳(Timestamp)標(biāo)識。表1 中每行對應(yīng)一個時間戳,時間戳值越大表示數(shù)據(jù)越新。
2.2 物理模型
在邏輯模型中,HBase表可以被看作稀疏行的集合,但HBase的物理存儲是把邏輯模型中的行按照列族分開存儲。表2和表3為表1的列族cf1和cf2對應(yīng)的物理模型,其表索引由行鍵、列族、列修飾符和時間戳組成。從這些表可以看出,HBase以稀疏方式存儲數(shù)據(jù),為空的單元格并不會占用存儲空間。

Table 2 Physical model of HBase(column family:cf1)表2 HBase數(shù)據(jù)的物理模型(列族cf1)

Table 3 Physical model of HBase(column family:cf2)表3 HBase數(shù)據(jù)的物理模型(列族cf2)
3 Geohash概述
3.1 二維空間索引的不足
對基于經(jīng)緯度編碼的空間數(shù)據(jù)而言,每個維度都同等重要。執(zhí)行空間查詢時,簡單地按二維經(jīng)緯度建立索引,如先按經(jīng)度再按緯度排序數(shù)據(jù),實質(zhì)上是將經(jīng)度看得比緯度更重要,索引處理就會把數(shù)據(jù)進(jìn)行不當(dāng)?shù)呐判颍驗榻?jīng)度上相近的數(shù)據(jù),在空間位置上并不一定鄰近。HBase數(shù)據(jù)庫只能按行鍵來訪問數(shù)據(jù),其模式設(shè)計的關(guān)鍵是行鍵設(shè)計,采用二維經(jīng)緯度坐標(biāo)作為HBase行鍵,會使得先按經(jīng)度再按緯度的順序存儲數(shù)據(jù),這就造成了數(shù)據(jù)的空間位置與存儲位置的不一致。當(dāng)基于行鍵掃描執(zhí)行空間位置查詢(如查詢k個最近的鄰近點)時,會返回大量多余的非鄰近點數(shù)據(jù),這會增加HBase服務(wù)器與客戶端的網(wǎng)絡(luò)I/O 或服務(wù)端過濾器的處理開銷。
兩個維度同等相關(guān)時,簡單地為經(jīng)度和緯度建立復(fù)合索引的方法具有不足之處。為了使空間位置鄰近的數(shù)據(jù)在HBase上也盡量緊密連續(xù)地存儲在一起,保證空間數(shù)據(jù)的空間位置與存儲位置的一致性,以方便構(gòu)建處理海量空間數(shù)據(jù)的及時響應(yīng)的HBase在線應(yīng)用系統(tǒng),就需基于新的空間編碼方法來構(gòu)建索引。
3.2 Geohash的劃分與編碼
為了高效地處理空間數(shù)據(jù),基于key-value的HBase數(shù)據(jù)庫需要一種平等考慮經(jīng)度與緯度、能將二維空間坐標(biāo)轉(zhuǎn)換成為一維值的線性化算法。Peano曲線、Hibert曲線和Cantor曲線等就是此類的空間位置一維編碼算法,屬于空間填充曲線類別,其將二維空間降維成一維曲線,曲線是單一的、不中斷的、接觸空間所有分區(qū)的線條[10]。與其它曲線相比,Peano曲線計算簡單且實現(xiàn)方便,因此本文選擇實現(xiàn)了Peano曲線的Geohash算法為解決方案。
本文以緯度34.75°、經(jīng)度113.59°的二維坐標(biāo)為例,介紹Geohash編碼的計算步驟。如圖1a所示,緯度區(qū)間范圍是[-90°,90°],將該區(qū)間二等分為[-90°,0°)與[0°,90°],目標(biāo)點緯度大于或等于中點用1表示,否則用0表示;因緯度34.75°落在區(qū)間[0°,90°],標(biāo)記為1;繼續(xù)將區(qū)間[0°,90°]二等分為[0°,45°)與[45°,°90],緯度34.75°落在區(qū)間[0°,45°),標(biāo)記為0。通過遞歸對半切分區(qū)間范圍和確定目標(biāo)點落在哪個半?yún)^(qū),計算出一個位序列101。同理如圖1b所示,計算經(jīng)度113.59°的位序列為110。位序列的長度與區(qū)間劃分次數(shù)有關(guān),長度越長則表示的位置精度越高。經(jīng)過在經(jīng)度和緯度上分別執(zhí)行區(qū)間二等分和位選擇過程,再按奇數(shù)位放經(jīng)度、偶數(shù)位放緯度的規(guī)則,以精度遞增的順序?qū)⒔?jīng)度和緯度位序列交叉排列生成一個新的位序列111001(如圖1c 所示),再對該序列進(jìn)行Base32編碼即生成一維的Geohash散列字符串。相對于二維空間索引,不孤立使用單個維度的編碼方式是一維的Geohash 值有空間位置特性的原因。一個Geohash字符串編碼代表著一個矩形區(qū)域,該區(qū)域內(nèi)所有的坐標(biāo)點會以該字符串為共同前綴,越鄰近的點共享的相同前綴字符越長,Geohash字符串越長,表示的矩形范圍越小越精確,即Geohash編碼具有一定的空間局部性,這對構(gòu)建空間索引非常有利。
采用Geohash字符串編碼作為HBase行健是一個極佳的選擇。因為兩個坐標(biāo)點的空間距離越接近,其Geohash字符串前綴匹配越多,這就有利于在HBase行健上執(zhí)行前綴匹配掃描以查詢附件的POI(Point of Interest)信息。HBase按照行健的字典順序升序存儲所有行,兩個坐標(biāo)點的Geohash字符串前綴匹配越多,其在HBase中就會被存儲得越接近,這就有利于實現(xiàn)數(shù)據(jù)本地化,因為HBase按行健范圍劃分Region,空間位置接近的數(shù)據(jù)會被存儲在同一Region或RegionServer[11]。執(zhí)行空間鄰近點查詢時,基于Geohash 字符串執(zhí)行HBase行健掃描,由本地就可直接讀取到所有的鄰近點數(shù)據(jù)。
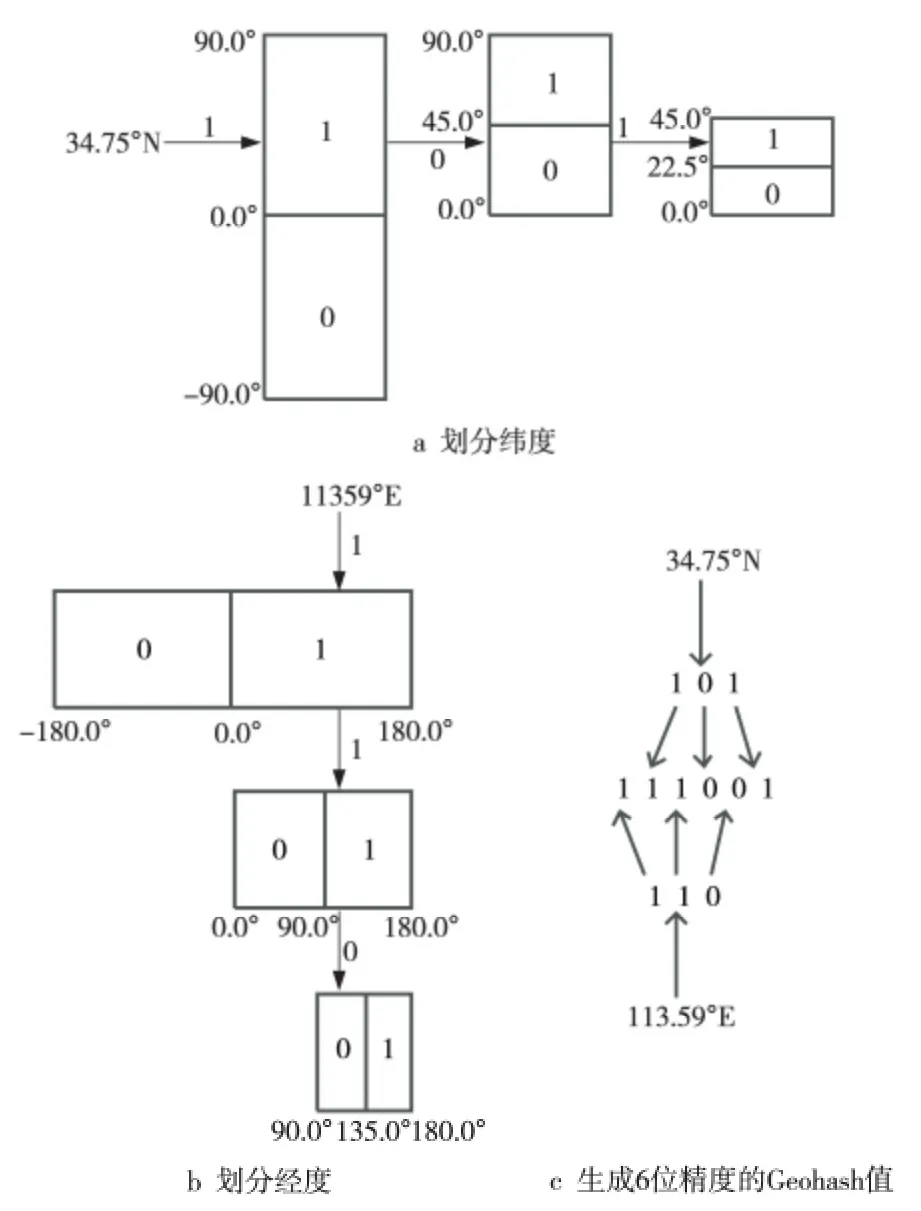
Figure 1 Subdivision and coding of Geohash圖1 Geohash的劃分與編碼
4 基于Geohash的空間文本索引
為了在海量數(shù)據(jù)上實現(xiàn)高效且可擴(kuò)展的空間關(guān)鍵字查詢,本節(jié)針對HBase數(shù)據(jù)庫利用Geohash算法提出了一種新的空間文本索引方法。首先,采用Geohash 算法將空間文本數(shù)據(jù)中代表空間信息的二維空間坐標(biāo)降維為一維散列字符串;然后從空間文本數(shù)據(jù)的文本信息中抽取分詞,并將分詞字符串和Geohash 字符串合理編排,以構(gòu)建HBase二級索引,實現(xiàn)同時從文本和空間兩個維度對空間文本數(shù)據(jù)進(jìn)行高效檢索。以下具體闡述空間文本索引表的組織結(jié)構(gòu)及其行健的生成規(guī)則。
表4中的空間文本數(shù)據(jù)主表即為空間文本數(shù)據(jù)在HBase數(shù)據(jù)庫上的一種簡單的組織方式,該表中的行健idi唯一標(biāo)識了每一行空間文本數(shù)據(jù),列族中的message列存儲了空間文本中的文本信息,location列以二維經(jīng)緯度坐標(biāo)的格式存儲了空間文本中的地理空間信息,date列存儲了空間文本的生成時間。

Table 4 Master table of spatial text data表4 空間文本數(shù)據(jù)主表
表5為基于表4的空間文本數(shù)據(jù)索引表,表中的行健wordi_geohashj_idk由三部分組成:對主表message列進(jìn)行分詞處理提取的關(guān)鍵詞wordi;對主表location列進(jìn)行Geohash計算生成的Geohash字符串geohashj;以及wordi和geohashj對應(yīng)的主表行健idk。一段文本可以切分出多個關(guān)鍵詞,所以主表中的一條記錄會按照切分出的關(guān)鍵詞數(shù)量在索引表中生成多條索引記錄,這些索引記錄會依次按照關(guān)鍵詞、Geohash字符串及id值的字典順序升序存儲,也就是說,空間位置相鄰的同一關(guān)鍵詞將被物理鄰近地存儲在一起,進(jìn)行空間關(guān)鍵字查詢時,HBase通過前綴匹配的行健掃描,即可高效直接地讀取到所需的結(jié)果集。
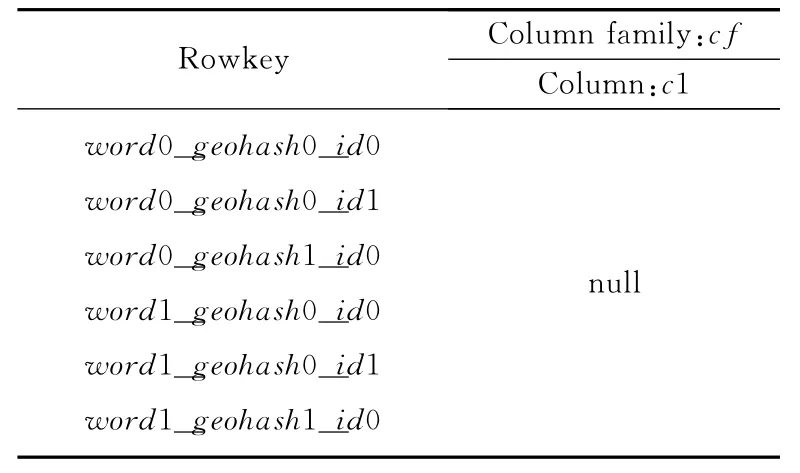
Table 5 Index table of spatial text data表5 空間文本數(shù)據(jù)索引表
索引表中的行健wordi_geohashj_idk將一條空間文本數(shù)據(jù)中的文本信息、空間信息與標(biāo)識信息綜合在一起,實現(xiàn)了在文本和空間兩個維度同時對數(shù)據(jù)進(jìn)行索引。基于索引表查詢時,根據(jù)掃描到的結(jié)果集,能直接在行健中截取到空間文本在主表中的行健id,由該id即可在主表中直接讀取到具體的空間文本數(shù)據(jù),因此索引表中的列族可為“空”,即不需要存儲有具體含義的內(nèi)容。在實際部署時,為了提高存儲及查詢效率,行健的長度要盡量短且固定,因此行健中的關(guān)鍵詞wordi可替換為定長的整數(shù)編碼;對于geohashj可根據(jù)地理精度需求選取盡量短的定長編碼。Geohash編碼支持部分鍵掃描,因此只要滿足精度,查詢者不用給出完整的Geohash編碼。
5 多邊形區(qū)域內(nèi)的空間關(guān)鍵字查詢算法
當(dāng)基于地理空間區(qū)域查詢文本數(shù)據(jù)時,區(qū)域可能是圓形的,如一公里范圍內(nèi)包含“快捷”關(guān)鍵字的酒店信息;區(qū)域可能是矩形的,如手機(jī)屏幕顯示區(qū)域內(nèi)包含“西餐”關(guān)鍵字的點評信息;區(qū)域可能是不規(guī)則多邊形的,如行政區(qū)域內(nèi)包含敏感關(guān)鍵字的言論信息。為了適用于所有查詢場景,本節(jié)基于HBase數(shù)據(jù)庫及前文構(gòu)建的空間文本索引,提出一種多邊形區(qū)域內(nèi)的空間關(guān)鍵字查詢算法,即查找某多邊形地理區(qū)域內(nèi)包含某關(guān)鍵字的空間文本數(shù)據(jù)。因計算步驟較多,所以將其分解為了MBP(Mininum Bounding Prefixes)算 法 和 Within-Query算法。
5.1 MBP算法
實現(xiàn)空間區(qū)域內(nèi)的關(guān)鍵字查詢時,用戶定義的空間查詢區(qū)域可以是不規(guī)則的任意幾何圖形,算法中統(tǒng)一以多邊形表示。一個Geohash字符串編碼代表的是一個規(guī)則的矩形,每個矩形擁有四個拐角,通過在多個Geohash 字符串所表示的多個鄰接矩形區(qū)域的拐角點上取凸包(Convex Hull),即可構(gòu)建一個拼接組合區(qū)域。基于Geohash編碼實現(xiàn)空間關(guān)鍵字查詢的關(guān)鍵就是將被查詢的多邊形區(qū)域轉(zhuǎn)換為多個鄰接的Geohash 矩形區(qū)域,且這些矩形的拼接組合區(qū)域最小包含著多邊形區(qū)域,算法MBP即用于實現(xiàn)該轉(zhuǎn)換。
算法1MBP(queryPolygon)
輸入:被查詢的多邊形區(qū)域queryPolygon;
輸出:最小包含查詢區(qū)域的Geohash 前綴集合geohashs


算法MBP基于查詢多邊形計算最小包圍的Geohash前綴集合,該算法的輸入queryPolygon是用戶手繪或自定義的查詢多邊形區(qū)域,具體實現(xiàn)時可用多邊形拐角的經(jīng)緯度坐標(biāo)集合來表示。輸出geohashs則為計算出的包含查詢區(qū)域且最小包圍的Geohash前綴集合,最小包圍的前綴集合可以把HBase掃描次數(shù)與掃描覆蓋的空間區(qū)域降到最小。
計算Geohash時需要指定字符精度,其取值范圍為整數(shù)1到12,表示Geohash編碼生成字符串的長度,字符串長度越短的Geohash編碼,表示的矩形區(qū)域越大,計算最小包圍的前綴集合的關(guān)鍵在于確定最佳的精度以最快計算出結(jié)果。MBP算法首先計算出查詢多邊形的形心queryCenter,并根據(jù)具體應(yīng)用涉及的地理范圍區(qū)域大小,指定初始的Geohash字符精度INIT_VALUE。while循環(huán)從較高的初始字符精度開始,先計算查詢多邊形形心的Geohash 編 碼candidate[12],再 基 于 該Geohash編碼代表的矩形區(qū)域計算其凸包candidate-Polygon,并檢驗是否包含查詢多邊形,若不包含,則擴(kuò)大至該Geohash及其八個空間方向的直接鄰居所構(gòu)成的組合區(qū)域。若仍沒有包含,則降低Geohash字符精度,以擴(kuò)大Geohash編碼代表的矩形區(qū)域,重復(fù)進(jìn)行上述檢查,直到相應(yīng)區(qū)域正好完全包含查詢多邊形,即獲得了最小包圍的Geohash前綴集合。
5.2 WithinQuery算法
通過調(diào)用算法MBP,算法WithinQuery將查詢關(guān)鍵字和算法MBP 返回的Geohash編碼逐一進(jìn)行合并,然后基于合并字符串在HBase空間文本索引表上執(zhí)行行健掃描,并對返回結(jié)果集進(jìn)行驗證過濾,即得到要查詢的空間文本數(shù)據(jù)集。
算法2WithinQuery(keyword,queryPolygon)
輸入:查詢關(guān)鍵字keyword,多邊形查詢區(qū)域queryPolygon。
輸出:位于查詢區(qū)域的空間文本數(shù)據(jù)的id集合ids。

算法WithinQuery的輸入為查詢關(guān)鍵字keyword和多邊形查詢區(qū)域queryPolygon,參數(shù)keyword和queryPolygon分別描述了要查詢的空間文本數(shù)據(jù)的文本信息和空間信息,而輸出結(jié)果集ids即為查詢到的空間文本數(shù)據(jù)的id集合,根據(jù)該id集合可在主表中獲取到具體的空間文本數(shù)據(jù)。算法WithinQuery首先調(diào)用算法MBP將查詢多邊形區(qū)域轉(zhuǎn)換為最小包含查詢區(qū)域的Geohash前綴集合prefixs,因為空間文本索引表的行健格式為wordi_geohashj_idk,所以將查詢關(guān)鍵字keyword與前綴集合prefixs的每個元素prefix合并后,在索引表indexTable上逐一執(zhí)行前綴匹配的行健范圍掃描;然后在返回的結(jié)果集results的每個元素result上調(diào)用方法getCoordinate(),以檢驗該result代表的空間文本數(shù)據(jù)的空間位置是否落在多邊形查詢區(qū)域內(nèi),以濾除位于前綴集合prefixs區(qū)域但不位于查詢區(qū)域的無效數(shù)據(jù),經(jīng)過空間過濾后的結(jié)果集即為包含關(guān)鍵字keyword且真正位于查詢區(qū)域queryPolygon內(nèi)的空間文本數(shù)據(jù)集合;最后將符合條件的所有result的行健中的id部分返回即可。
為了最大限度利用HBase集群執(zhí)行計算工作并減少返回給客戶端的數(shù)據(jù)量,應(yīng)使用HBase的過濾器或協(xié)處理器(Coprocessor)在服務(wù)器端實現(xiàn)算法中耗時的處理。對算法WithinQuery而言,把“驗證是否位于查詢區(qū)域”的邏輯放在服務(wù)器端的過濾器來實現(xiàn),將極大地減輕HBase服務(wù)器與客戶端的通信量,并可提高算法的查詢效率。
6 實驗與分析
6.1 實驗環(huán)境
本節(jié)通過分析基于Geohash一維空間索引與基于經(jīng)緯度二維空間索引的查詢結(jié)果,以實驗來檢驗提出的多邊形區(qū)域內(nèi)的空間關(guān)鍵字查詢算法的執(zhí)行效率,從而證明該算法的高效性和可擴(kuò)展性。實驗使用HBase 0.94.7和Hadoop 1.1.2,并將其部署在七個物理節(jié)點上,其中一個節(jié)點作為Master,其余六個作為RegionServer。每個節(jié)點含有雙核2.5GHz CPU、8GB內(nèi)存,7 200rpm 的SATA 硬盤,網(wǎng)絡(luò)帶寬為1Gbps,操作系統(tǒng)為Ubuntu 12.04。實驗中的查詢區(qū)域是半徑不超過3km 的任意幾何區(qū)域,測試數(shù)據(jù)使用了五個具有空間位置信息的點評數(shù)據(jù)集,所有數(shù)據(jù)的地理位置均位于半徑30km 的空間范圍內(nèi),數(shù)據(jù)集的文本統(tǒng)計信息如表6所示。
Table 6 Text statistics of datasets表6 數(shù)據(jù)集文本統(tǒng)計信息
6.2 實驗結(jié)果分析
實驗測試了不同數(shù)據(jù)量下的基于不同索引技術(shù)的空間關(guān)鍵字查詢算法的查詢響應(yīng)時間,實驗結(jié)果如圖2所示。從圖2中可以看出,隨著數(shù)據(jù)量的增大,基于經(jīng)緯度二維索引的查詢性能逐漸降低,而基于Geohash編碼一維索引的查詢算法則能保持查詢性能基本不受影響。這是因為基于Geohash編碼的空間索引使空間位置鄰近的數(shù)據(jù)在HBase上連續(xù)地存儲在一起,從而實現(xiàn)了數(shù)據(jù)的空間位置與存儲位置的一致性。將查詢區(qū)域半徑擴(kuò)大至10km 的任意幾何區(qū)域,并基于更大規(guī)模數(shù)據(jù)的實驗發(fā)現(xiàn),基于經(jīng)緯度二維索引的查詢響應(yīng)時間已遠(yuǎn)超出了可等待的范圍,因此,圖3中只測試了基于Geohash編碼一維索引的查詢性能。從圖3可以看出,在更大的查詢區(qū)域內(nèi),隨著數(shù)據(jù)量的增大,該算法的響應(yīng)時間有所增加,但仍處于可接受范圍內(nèi),從而驗證了算法具有良好的可擴(kuò)展性。

Figure 2 Response time of queries圖2 查詢響應(yīng)時間

Figure 3 Scalability of query performance圖3 查詢性能的擴(kuò)展性
7 結(jié)束語
運行在普通服務(wù)器上的HBase可方便地橫向擴(kuò)展支持?jǐn)?shù)十億行的海量數(shù)據(jù)集。Geohash編碼把二維經(jīng)緯度坐標(biāo)降維成一維字符串,且空間位置相鄰的Geohash 編碼具有相同的前綴。所以,基于HBase數(shù)據(jù)庫采用Geohash編碼就非常適于解決海量空間數(shù)據(jù)中的鄰近點搜索問題。本文據(jù)此給出了一種結(jié)合Geohash 編碼與分詞技術(shù)的HBase空間文本索引方案,并基于該索引提出了一種多邊形區(qū)域內(nèi)的空間關(guān)鍵詞查詢算法,為海量空間文本數(shù)據(jù)的高效存儲與處理提供了新的解決方案和思路。如何深入優(yōu)化查詢算法以提高更大地理區(qū)域內(nèi)的空間關(guān)鍵字查詢效率是接下來應(yīng)進(jìn)一步研究的課題。
[1] Niemeyer G.Geohash[EB/OL].[2013-06-20].http://en.wikipedia.org/wiki/Geohash.
[2] The Apache Software Foundation.Apache Lucene 4.2.0 Documentation[EB/OL].[2013-03-11].http://lucene.apache.org/core/4_2_0/index.html.
[3] The Apache Software Foundation.Apache Solr 4.2.0Documentation[EB/OL].[2013-03-13].http://lucene.apache.org/solr/4_2_0/index.html.
[4] Jin An,Cheng Cheng-qi,Song Shu-h(huán)ua,et al.Regional query of area data based on Geohash[J].Geography and Geo-Information Science,2013,29(5):31-35.(in Chinese)
[5] Ian De Felipe,Hristidis V,Rishe N.Keyword search on spatial databases[C]∥Proc of the 2008IEEE 24th International Conference on Data Engineering,2008:656-665.
[6] Li Zhi-sheng,Ken C K Lee,Zheng Bai-h(huán)ua,et al.IR-tree:an efficient index for geographic document search[J].IEEE Trans on Knowledge and Data Engineering,2011,23 (4):585-599.
[7] Joao B Rocha-Junior,Gkorgkas O,Jonassen S,et al.Efficient processing of Top-k spatial keyword queries[C]∥Proc of the 12th International Conference on Advances in Spatial and Temporal Databases,2011:205-222.
[8] Zhang Yu,Ma You-zhong,Meng Xiao-feng.Efficient processing of spatial keyword queries on HBase[J].Journal of Chinese Computer Systems,2012,33(10):2141-2146.(in Chinese)
[9] HBase:bigtable-like structured storage for hadoop hdfs[EB/OL].[2010-08-17].http://hadoop.apache.org/hbase.
[10] Guo Wei,Guo Jing,Hu Zhi-yong.Spatial database indexing technique[M].Shanghai:Shanghai Jiao Tong University,Press,2006.(in Chinese)
[11] George L.HBase the definitive guide[M].Sebastop01:O’Reilly Media,2011.
[12] Heuberger S.Geohash-Java[EB/OL].[2009-12-11].https://github.com/kungfoo/geohash-java.
附中文參考文獻(xiàn):
[4] 金安,程承旗,宋樹華,等.基于geohash的面數(shù)據(jù)區(qū)域查詢[J].地理與地理信息科學(xué),2013,29(5):31-35.
[8] 張榆,馬友忠,孟小峰.一種基于HBase的高效空間關(guān)鍵字查詢策略[J].小型微型計算機(jī)系統(tǒng),2012,33(10):2141-2146.
[10] 郭薇,郭菁,胡志勇.空間數(shù)據(jù)庫索引技術(shù)[M].上海:上海交通大學(xué)出版社,2006.
猜你喜歡
今日農(nóng)業(yè)(2021年9期)2021-11-26 07:41:24
發(fā)明與創(chuàng)新·小學(xué)生(2021年3期)2021-03-25 11:48:49
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
電測與儀表(2015年5期)2015-04-09 11:30:52
