圖書在版編目自動輔助標引方案初探
2015-04-07 02:38:44耿銳
中國科技產業 2015年10期
耿 銳
(北方工業大學計算機學院,北京 100144)
圖書在版編目自動輔助標引方案初探
耿 銳
(北方工業大學計算機學院,北京 100144)
本文論述了全文檢索技術和中文分詞技術的技術特征,給出了方案的實施思路、實施流程、功能架構等,并對方案進行了實驗驗證。該方案可以實現計算機輔助標引,可以有效提高圖書在版編目(CIP)標引人員工作效率。
圖書在版編目;全文檢索;中文分詞;自動標引
1 引言
圖書在版編目(Cataloguing in Publication,英文縮寫CIP),是指依據有關的國家標準為在出版過程中的圖書編制書目數據,并將其印制在圖書版權頁上的工作。通過這種方式,圖書和它的編目數據可以同時被圖書館、圖書銷售企業、政府管理部門和其他需要這一數據的人們所利用。我國的CIP實施工作從1993年起步至今,已經覆蓋全部580余家圖書出版社98%以上的圖書, 2014年CIP數據的年編制量達到30余萬條。
目前圖書上是否印有CIP數據已經成為出版物標準化、規范化的重要標志之一。與此同時CIP中心已經建立起了一個全國唯一的、信息最全的圖書印前書目數據庫,實現了數據實時傳輸的網絡編目,截至2015年8月底,CIP標準數據庫已有書目數據近340萬條。但逐年增長的圖書出版量與CIP制作人員不足的矛盾日益暴露出來,特別是依靠手工標引圖書主題和分類號的方式,已經無法滿足CIP數據制作周期的要求。
本文探討一種適合CIP工作的自動輔助標引解決方案,以求依托全文檢索和中文分詞技術,實現計算機自動輔助標引,提高標引人員工作效率,促進我國出版行業發展。
2 關鍵技術
2.1 全文檢索技術
全文檢索技術是針對大規模文字信息最高效的檢索技術。全文檢索是一種將數據庫中所有文本與檢索項匹配的檢索方法。計算機索引程序通過掃描文本中的每一個詞,對每一個詞建立一個索引,記錄該詞在文本中出現的次數和位置,當用戶進行檢索時,檢索程序依據事先建立完成的索引進行查找,并將查找的結果反饋給用戶。全文檢索系統是按照全文檢索理論建立起來的,用于提供全文檢索服務的軟件系統。全文檢索系統可實現全文檢索,完全支持模糊檢索、同義詞檢索、布爾檢索等。全文檢索系統可提供每秒上百次的并發檢索支持,保證全面快速的響應用戶檢索需求。
本方案采用Lucene全文搜索引擎。Lucene是一個開源的全文檢索引擎工具包,是一個JAVA編寫的全文檢索引擎的架構,其提供了完整的索引引擎和查詢引擎。Lucene提供的簡單易用工具包和程序接口,可以使軟件開發人員方便的在目標系統中實現全文檢索的功能,也可以此為基礎建立起完整的全文檢索引擎。

圖1 中文分詞處理過程圖
2.2 中文分詞技術
中文分詞是中文信息處理的關鍵,它是信息檢索、文本分類、機器翻譯、自動標引的基礎,如對于東方語言(如中、日、韓等語音)的文字內容,在做文字內容分析之前,一般需要采用分詞技術將文字內容進行分詞。在對文字內容進行分詞的同時,也對整個系統的檢索精度和效率有很大影響。分詞系統在保證分詞的準確、快速的同時,還要保證分詞系統與全文檢索系統的協調、配合。
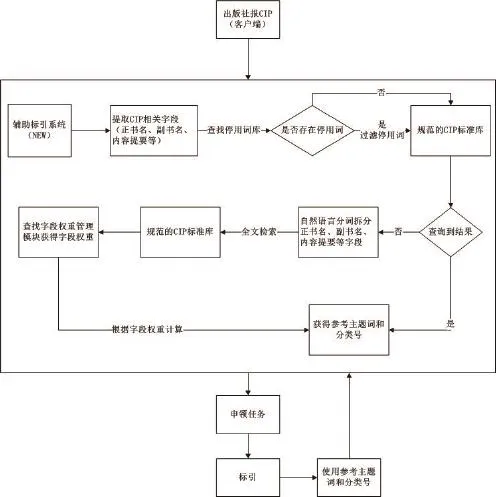
圖2 CIP輔助標引流程圖
現有的中文分詞技術主要有三種方法:(1)基于字符串匹配(詞典)的分詞方法,優點是較容易實現,但是精度不高;(2)基于理解(規則)的分詞方法,優點是精度較高,但是規則不易維護;(3)基于統計的分詞方法,優點是無需切分字典,依據詞頻統計,可以有效識別未登錄詞,但是效率較低。現有的中文分詞工具主要包括:Paoding、Imdict、mmseg4j、IKQueryParser、ICTCLAS等。
經過深入比較,本方案采用中國科學院計算技術研究所研制出的中文分詞工具ICTCLAS (Institute of Computing Technology, Chinese Lexical Analysis System)的 GB2312版本,主要功能包括中文分詞;新詞識別;命名實體識別;詞性標注;同時支持用戶詞典。用戶可以直接自定義輸出的詞類標準,定義輸出格式;用戶可以根據自己的需求,進行量身自助式定做適合自己的分詞系統。分詞精度達到98%以上,API和各種壓縮后的詞典數據均較小,是目前最優秀的漢語詞法分析器。ICTCLAS全部采用C/C++編寫,支持Linux、Windows等多種操作系統,支持C/ C++/C#/Java /Delphi等主流開發語言。ICTCLAS支持當前廣泛認同的分詞和詞類標準。
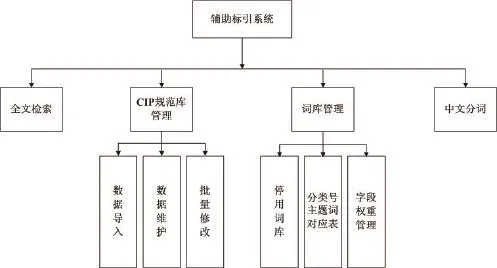
圖3 功能架構圖
3 CIP輔助標引實施方案
3.1實現思路
依據CIP標準庫中的歷史數據:建立CIP規范庫,并生成分類號、主題詞對照表。通過將出版社申報的原始CIP數據記錄中“正書名、副書名、交替書名、合訂書名、并列書名、分冊名、附注項、內容提要”等字段分詞,利用全文檢索搜索引擎技術,在CIP規范庫中查找相似的數據,為標引人員提示建議分類號和建議主題詞,再由標引人員手工選取提示結果。
3.2 實施流程(見圖2)
3.3 功能架構(見圖3)
3.4 功能概述
3.4.1 全文檢索
采用開源全文檢索引擎(Lucene),解決目前數據庫對文本信息模糊檢索效率低問題,同時縮短在線生成輔助標引信息響應時間。中文分詞采用漢語詞法分析系統ICTCLAS。
3.4.2 CIP規范庫管理
CIP規范庫是獨立的CIP數據庫,數據來源為目前CIP系統中標準庫數據。用戶可以通過批量導入的方式將CIP系統的標準庫數據導入到規范庫中,相關用戶在此基礎上不斷地完善規范庫,使其形成CIP數據標準,同時生成分類號主題詞對應表,如圖4所示。
規范庫管理功能包括:
(1)數據導入:在現有標準庫中選中記錄導入到規范庫中;
(2)數據維護:可以對規范庫進行修改、刪除;
(3)批量修改:支持批量修改主題詞和分類號。
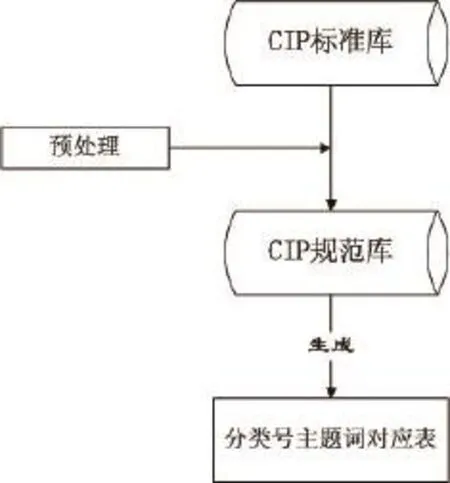
圖4 CIP規范庫管理
3.4.3 詞庫管理
3.4.3.1 停用詞庫
由于書名、內容提要等信息中存在一些時間、地名等停用詞,將這些詞統一維護在停用詞庫,可以提高檢索精度。
3.4.3.2 分類號主題詞對應表
3.4.3.3 字段權重管理
字段權重可以由正書名、副書名、交替書名、合訂書名、并列書名、分冊名、附注項、內容提要等字段組成。字段權重越高,智能生成返回的主題詞分類號的準確率越高。
3.5 實驗結果
3.5.1 實驗環境
聯想ThinkPad T430i筆記本(內存:4G,CPU:i5-3337U),Tomcat 7.0
3.5.2 CIP規范庫的建立
我們用CIP標準庫的340多萬條數目數據位基礎建立CIP規范庫,其中包括“CIPID”、“正書名”、“副書名”、“交替書名、“合訂書名”、“并列書名”、“分冊名”、“附注項”、“內容提要”、“主題詞”、“分類號”等字段。將這些數據分詞、存儲、建索引后數據大小約4G。
3.5.3 檢索輸入
我們將出版社申報的原始圖書信息作為輸入內容。對輸入內容按照中文分詞技術提取關鍵詞,作為搜索引擎的輸入。
3.5.4 檢索輸出
輸出結果是與輸入內容相近的5個CIP規范庫中的書目,包含所有字段內容和每個匹配書目的得分。
3.5.5 實驗結果
單次全新檢索的平均檢索時間小于6秒(包括對輸入內容提取關鍵詞和檢索出結果的整個過程)。通過人工判定,與輸入內容最相近的主題、分類標引內容都排在返回結果的前面。
4 總結
本文在采用Lucene全文檢索引擎包和中文分詞工具ICTCLAS的基礎上,制定了圖書在版編目(CIP)自動輔助標引方案,并對該方案進行了初步測試。依據測試結果可以看出該方案能夠針對出版社新報送的CIP數據快速生成輔助標引提示。實際應用中,可以調節關鍵詞過濾條件(最低詞頻、最小詞長度、最小文檔頻率、最多檢索關鍵詞數等),來優化效率和精確性。
[1]余 春. 自動標引研究進展[J]. 圖書館學研究,2012,04:18-22.
[2]蘇武華. 漢語自動分詞和自動標引方法研究[J].農業圖書情報學刊,2004,07:103-105.
[3]王 莉,許 凱. 淺談文本數據自動標引系統的設計[J].圖書館理論與實踐,2013,06:95-97.
[4]王 昊,鄒杰利,鄧三鴻.面向中文圖書的自動標引模型構建及實驗分析[J].現代圖書情報技術,2013,Z1:55-62.
[5]龍樹全,趙正文,唐 華. 中文分詞算法概述[J].電腦知識與技術,2009,10:2605-2607.
[6]熊泉浩.中文分詞現狀及未來發展[J].科技廣場,2009,11:222-225.
[7]王志嘉,薛 質.一種基于Lucene的中文分詞的設計與測試[J].信息技術,2010,12:50-54.
[8]李穎,李志蜀,鄧 歡.基于Lucene的中文分詞方法設計與實現[J].四川大學學報(自然科學版),2008,05:1095-1099.
[9]黃翼彪.實現Lucene接口的中文分詞器的比較研究[J].科技信息,2012,12:246-247.
主題詞對應表是依據CIP規范庫自動生成,由三個字段組成,關鍵詞串、主題詞和分類號,通過中文分詞工具獲得的詞語通過查找《分類號主題詞對應表》的關鍵詞串可以快速獲得輔助主題詞和分類號。
