基于MapReduce的并行PLSA算法及在文本挖掘中的應用
2015-04-21 09:26:38羅文娟莊福振史忠植
中文信息學報 2015年2期
李 寧,羅文娟,莊福振,何 清,史忠植
(1. 中國科學院計算技術研究所 智能信息處理重點實驗室,北京 100190;2. 中國科學院大學,北京 100190;3. 河北大學 數學與計算機學院機器學習與計算智能重點實驗室, 河北 保定 071002)
?
基于MapReduce的并行PLSA算法及在文本挖掘中的應用
李 寧1,2,3,羅文娟1,莊福振1,何 清1,史忠植1
(1. 中國科學院計算技術研究所 智能信息處理重點實驗室,北京 100190;2. 中國科學院大學,北京 100190;3. 河北大學 數學與計算機學院機器學習與計算智能重點實驗室, 河北 保定 071002)
PLSA(Probabilistic Latent Semantic Analysis)是一種典型的主題模型。復雜的建模過程使其難以處理海量數據,針對串行PLSA難以處理海量數據的問題,該文提出一種基于MapReduce計算框架的并行PLSA算法,能夠以簡潔的形式和分布式的方案來解決大規模數據的并行處理問題,并把并行PLSA算法運用到文本聚類和語義分析的文本挖掘應用中。實驗結果表明該算法在處理較大數據量時表現出了很好的性能。
概率主題模型;MapReduce;并行;語義分析
1 引言
當我們得到一個大規模的文本數據集或者是其他類型的離散數據集合時,為了便于理解,總是希望找到這個龐大的數據集的一個簡短描述和概括,來代表或是反映出整個數據集的特征信息。對文本數據來說,就是抽取出一個或幾個主題這樣的抽象概念來描述整個文本數據集。例如,一本期刊,我們如果知道它主要是關于娛樂和時尚的,那么它里面所有的文章自然也是這兩個主題相關的,由此可以根據自己的愛好選擇是否閱讀這些文章。
傳統的VSM模型使用關鍵字來表示主題。但這種表達方式比較局限于對文檔貢獻較大的詞,很多用于表示文檔的詞語,由于存在二義性,對于文檔的語義上的描述,效果往往差強人意[1]。為了克服VSM 模型的這些缺點,有學者提出了主題模型。
主題模型(topic model)又稱層面模型(aspect model),是近幾年興起的一種對數據進行挖掘、分析的一種建模方法,它們不僅在場景分類、對象識別等領域取得了好的效果,也成功地應用于圖像的自動標注和檢索[2-5]。其主要思想為:給定多項分布的潛在變量,捕獲詞的共現模式。一個文檔不再表示為一組詞的共現集合,而是在給定一個潛在變量的情況下,經過建模表示為一系列的詞共現集合的混合。這些詞共現集合建模為詞匯表上的多項分布,可稱為文檔集中的“主題”。將這個詞上的多項分布解釋為主題能夠給文檔集一個直觀的結構,所以這類概率模型常常稱為主題模型。
主題模型的思想最早來源于隱含語義索引(Latent Semantic Indexing,LSI)[6]。其工作原理是利用矩陣理論中的“奇異值分解(SVD)”技術,將詞頻矩陣轉化為奇異矩陣,通過去除較小的奇異值向量,只保留前K個最大的值,將文檔向量和查詢向量從詞空間映射到一個K維的語義空間(主題)。在該空間中,來自詞語—文檔矩陣的語義關系被保留,同時詞語用法的變異(如同義性,多義性)被抑制。
主題模型的第二次重大突破是Hofmann提出的PLSA(Probabilistic Latent Semantic Analysis)模型[7-8]。PLSA使用圖模型來表示文檔、主題和詞語三者之間的關系,將文檔和詞語映射到同一個主題空間。
在文檔層面上,PLSA可以將文檔映射到各個主題,這些主題可以看作文本類別,每一文本所屬類別中概率最大的那一類可作為文本最終所屬類別[9],這樣PLSA的建模過程實際也是對文本進行聚類的過程,從而可以將PLSA模型用于文本聚類。
在詞語層面上,每個詞語對每個主題都有相應的概率值,我們可以將概率值最大的那個主題來作為這一詞語所對應的最終主題。反過來,每一主題下會有多個詞語與之對應。這些詞語被認為是主題相關的,即在主題角度上語義相近的。因此,我們可以將PLSA模型用于文本中詞語的語義分析。
隨著信息技術和網絡的迅猛發展,網絡中積累了各個行業的海量數據。如何從這些數據中挖掘出人們感興趣的主題成為了一個新的研究課題。傳統PLSA算法采用EM迭代算法來進行求解,使其在處理大數據上性能不夠好,將其并行會是一種比較好的解決方案。
對PLSA相關算法的并行已有一些工作。文獻[10]中,作者采用共享內存的OpenMP編程模式,基于Lemur[11]中的TEM對PLSA算法進行了并行實現,并提出了分塊算法和塊調度算法,以達到負載平衡。Wan等人[12]對上述算法進行了擴展,將OpenMP與MPI結合,采用了共享內存和分布式存儲。OpenMP這種模式不適合集群環境,而MPI雖適合于各種機器,但它的編程模型復雜。需要分析及劃分應用程序問題,并將問題映射到分布式進程集合,并且需要解決通信延遲大和負載不平衡兩個主要問題。
Hadoop[13]是一個實現了MapReduce[14-17]計算模型的開源分布式并行編程框架,借助于MapReduce,我們可以輕松地編寫并行程序,將其運行于計算機集群上,完成海量數據的計算。與OpenMP和MPI相比,MapReduce這種并行編程模式通過主節點的JobTracker來調度和分發構成一個作業的所有任務,無需人工干預,其實現算法的機理是不同的。
本文采用MapReduce編程模式對PLSA算法進行并行實現,文獻[18]中提出了兩種并行策略P2LSA和P2LSA+,P2LSA在Map階段進行PLSA算法中的E步操作,在Reduce階段進行M步操作,這種并行方式需要在Map和Reduce之間進行大量數據的傳遞,會加重網絡和總的運行時間開銷。P2LSA+首先將E步和M步進行整合,設計兩個job來完成迭代更新操作。本文設計了一種新的并行策略,迭代過程只涉及一個job,取得了更好的并行效果。
本文的安排如下:第二部分介紹PLSA算法和MapReduce的相關知識;第三部分給出基于Map-Reduce的并行PLSA算法的詳細實現過程;第四部分實驗結果及在文本聚類和語義分析中的應用;第五部分對整篇文章進行了總結。
2 相關知識
2.1 PLSA算法 概率潛在語義分析(Probabilistic Latent Semantic Analysis(PLSA))模型,是在主題建模(Topic Modeling)領域發展成熟的一種統計技術,主要用于雙模態(two-mode)和共生(co-occurrence)型數據。PLSA模型提出了對文本集進行主題建模的基本思想,通過對潛在語義分析(LSA)模型進行一層概率封裝,可以將一個文本文檔建模為若干潛在主題的混合,而每個主題都表示為一個詞的多項分布。
PLSA模型使用圖模型來表示文檔、主題和詞語三者之間的關系,將文檔和詞語映射到同一個主題空間。文檔可以用主題的混合比重來表示,建模可以使離散的共現矩陣降維成固定主題集下的概率分布。其原理圖如圖1所示。
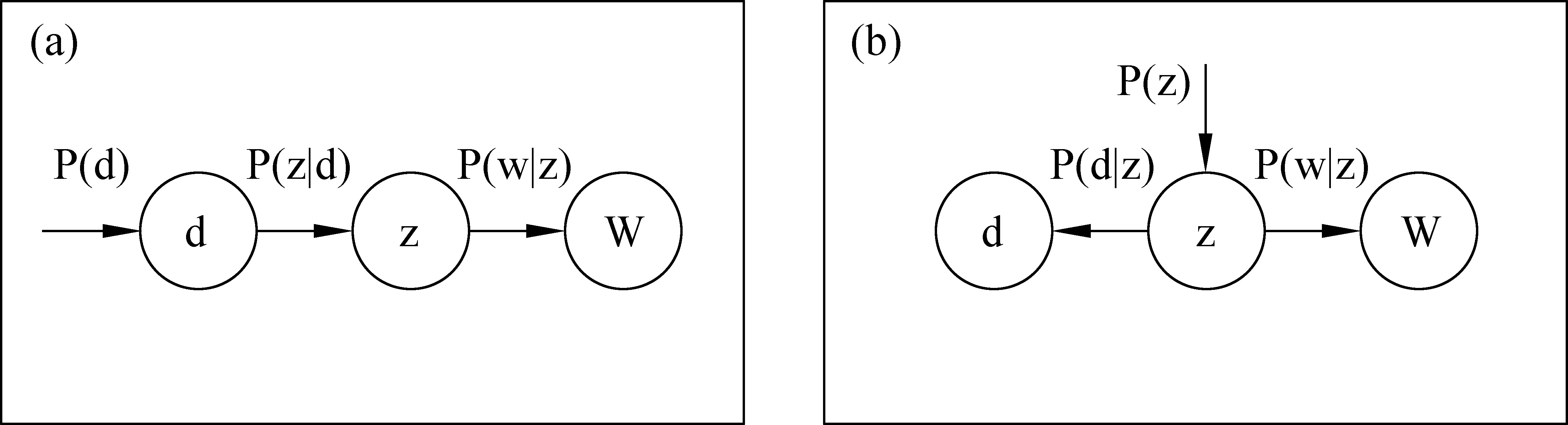
圖1 PLSA模型的兩種圖模型表示
PLSA模型的主要任務是針對共現矩陣尋求一個生成模型。圖1(a)中d表示文檔,詞以 w∈W,W={w1,…,wM} 表示,其中字典W相當于是M個字詞所形成的集合。假定每個字詞由給定文檔下的語義主題(隱藏變量)z∈Z={z1,…,zK} 產生,整個文檔生成過程如下:
? 選擇一篇文檔,其概率表示為p(d);
? 基于當前文檔條件下,挑選一個潛在主題z,其概率為P(z|d),服從多項分布;
? 基于當前主題下,產生一個詞的概率為P(w|z),服從多項分布。


(1)
由上述生成過程,可得出共現矩陣的聯合概率模型如式(1)所示,式中對所有可能的z模擬意向模型,條件概率 P(w|z) 是K個關于主題的條件概率平面P(z|d) 的凸組合。文檔由其P(w|z) 的因子的混合描述。PLSA主要基于兩個方面的工作,即基于統計的潛在主題模型和兩個獨立性假設:
? 在潛在主題z狀態下,文檔和詞是獨立產生的;
? 詞和潛在主題也是獨立產生,與具體的文檔沒有關系。
根據上述兩個獨立性假設,可將模型轉化潛在主題z下的對稱模型,如圖1(b)所示。則式(1)中的聯合概率可改寫為式(2)中的形式。
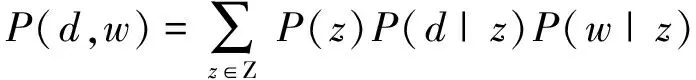
(2)
PLSA的模型參數是兩個條件概率分布P(w|z) 和P(z|d),這兩個參數都滿足多項分布,可以使用EM算法計算得到[19]。EM算法的兩個步驟表示如式(3)~(6)所示。
(1)E步:
(3)
(2)M步:
(4)
(5)
(6)
2.2MapReduce
MapReduce將復雜的運行于大規模集群上的并行計算過程高度的抽象到了兩個函數:Map和Reduce,適合用MapReduce來處理的數據集(或任務)有一個基本要求: 待處理的數據集可以分解成許多小的數據集,而且每一個小數據集都可以完全并行地進行處理。
圖2說明了用MapReduce來處理大數據集的過程,這個MapReduce的計算過程簡而言之,就是將大數據集分解為成百上千的小數據集,每個(或若干個)數據集分別由集群中的一個節點(一般就是一臺普通的計算機)進行處理并生成中間結果,然后這些中間結果又由大量的節點進行合并,形成最終結果。

圖2 MapReduce計算流程
計算模型的核心是Map和Reduce兩個函數,這兩個函數由用戶負責實現,功能是按一定的映射規則將輸入的
3 基于MapReduce的并行PLSA算法
通過對PLSA算法的分析我們可以看出,其主要的求解步驟為通過EM算法來計算P(w|z),P(z|d)和P(z)。為了方便說明問題,將n(d,w)P(z|d,w)用A表示,代入公式(4)~(6),得式(7)~(9)。
(7)
(8)
(9)
整個迭代過程主要是計算 ∑dA,∑wA 和R,而計算每篇文檔的A和 ∑wA是相互獨立的,互不干擾,可以在不同節點上并行完成。R的計算過程為一個計數過程,即將文檔中所有出現單詞的詞頻求和。因此,可以設計兩個job來完成以上計算,一個job用于計算∑dA和∑wA,另一個job計算R。
對于計算 ∑dA和 ∑wA的job,在Map階段完成每一篇文檔的A和 ∑wA的計算,輸入為一系列的
對于R的計算,在Map階段完成一篇文章的 ∑wn(d,w), 如CountRMapper所示。在此基礎上,計算所有文檔的 ∑d,wn(d,w) 在Reduce階段完成,如CountRReducer所示。

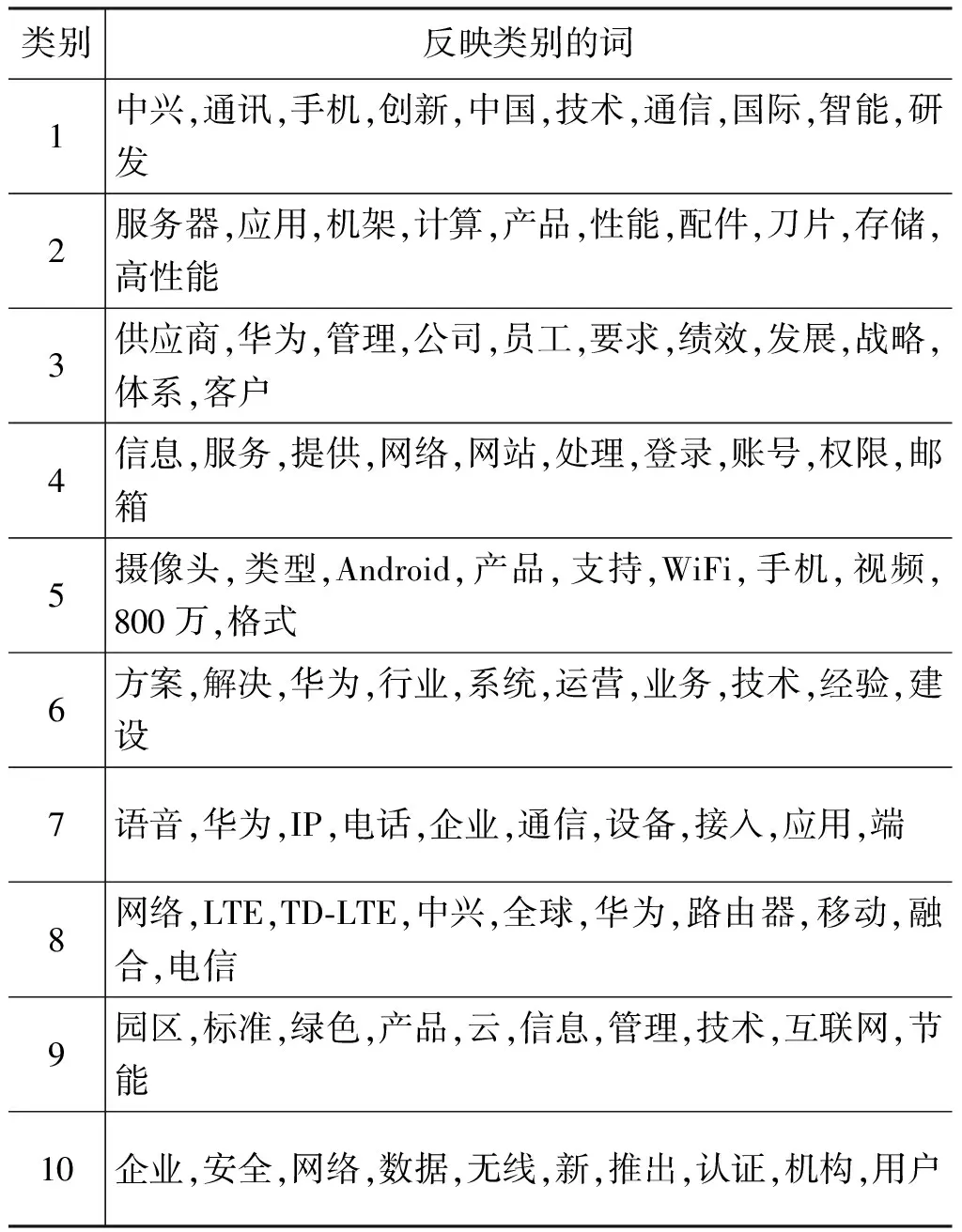
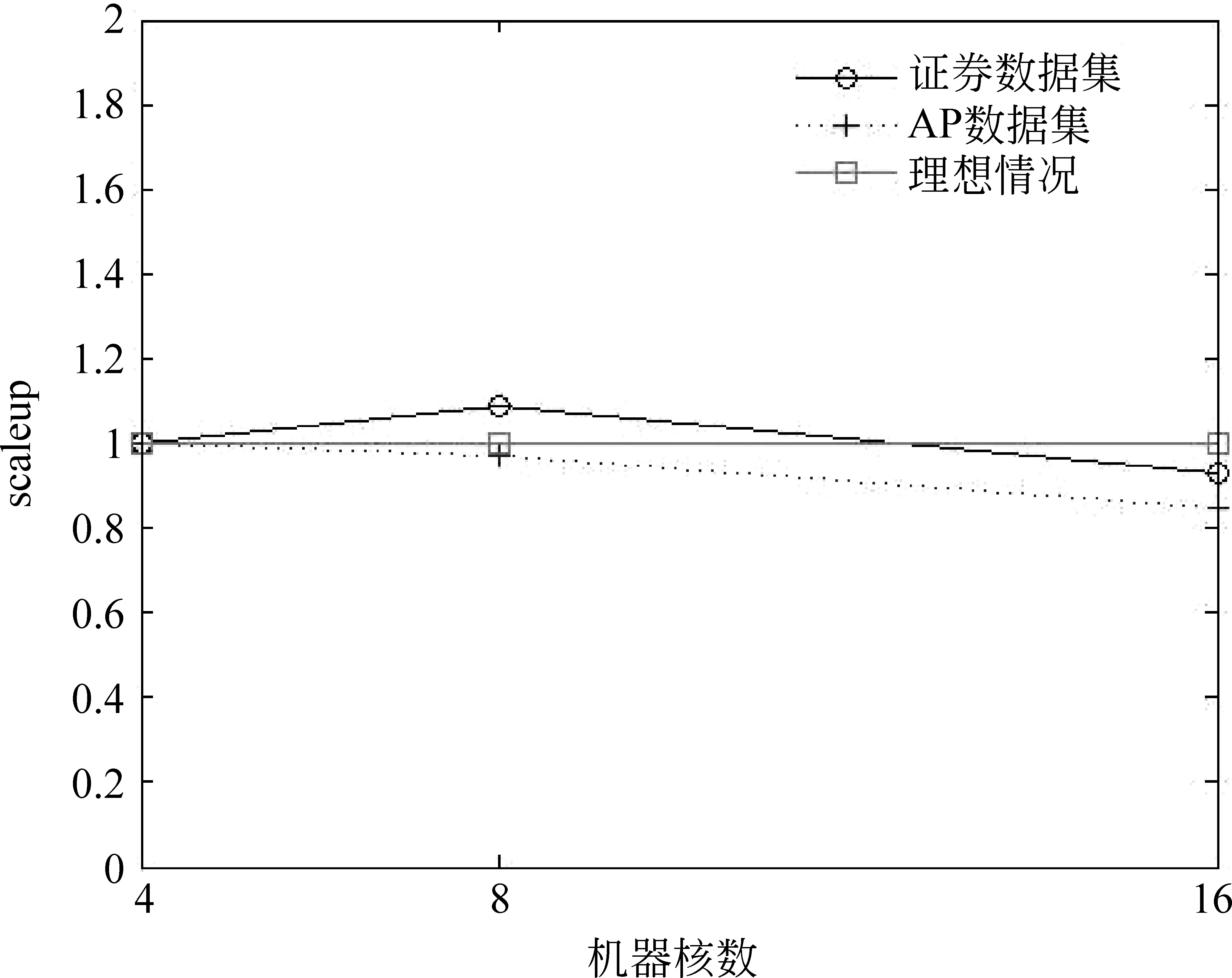
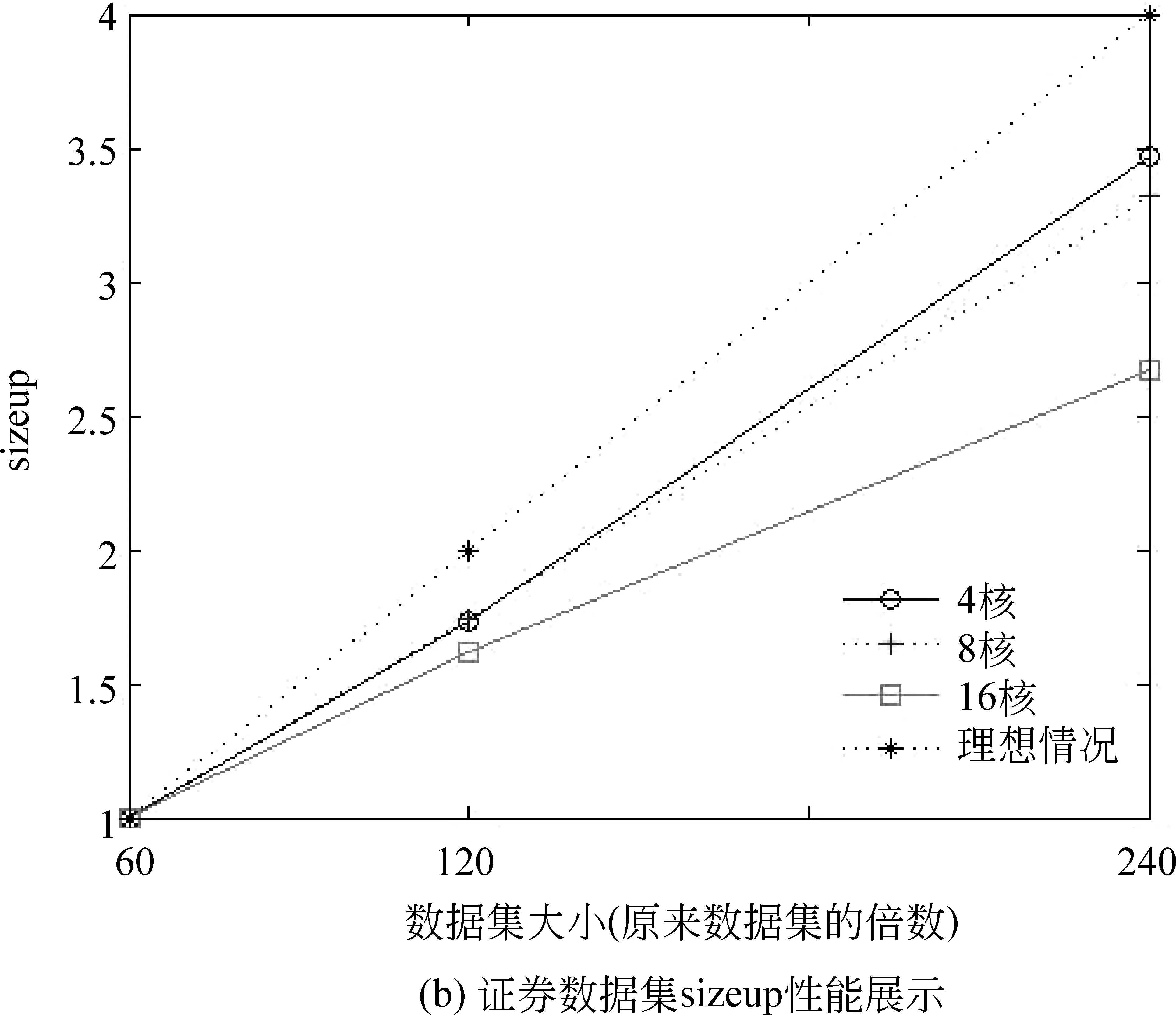
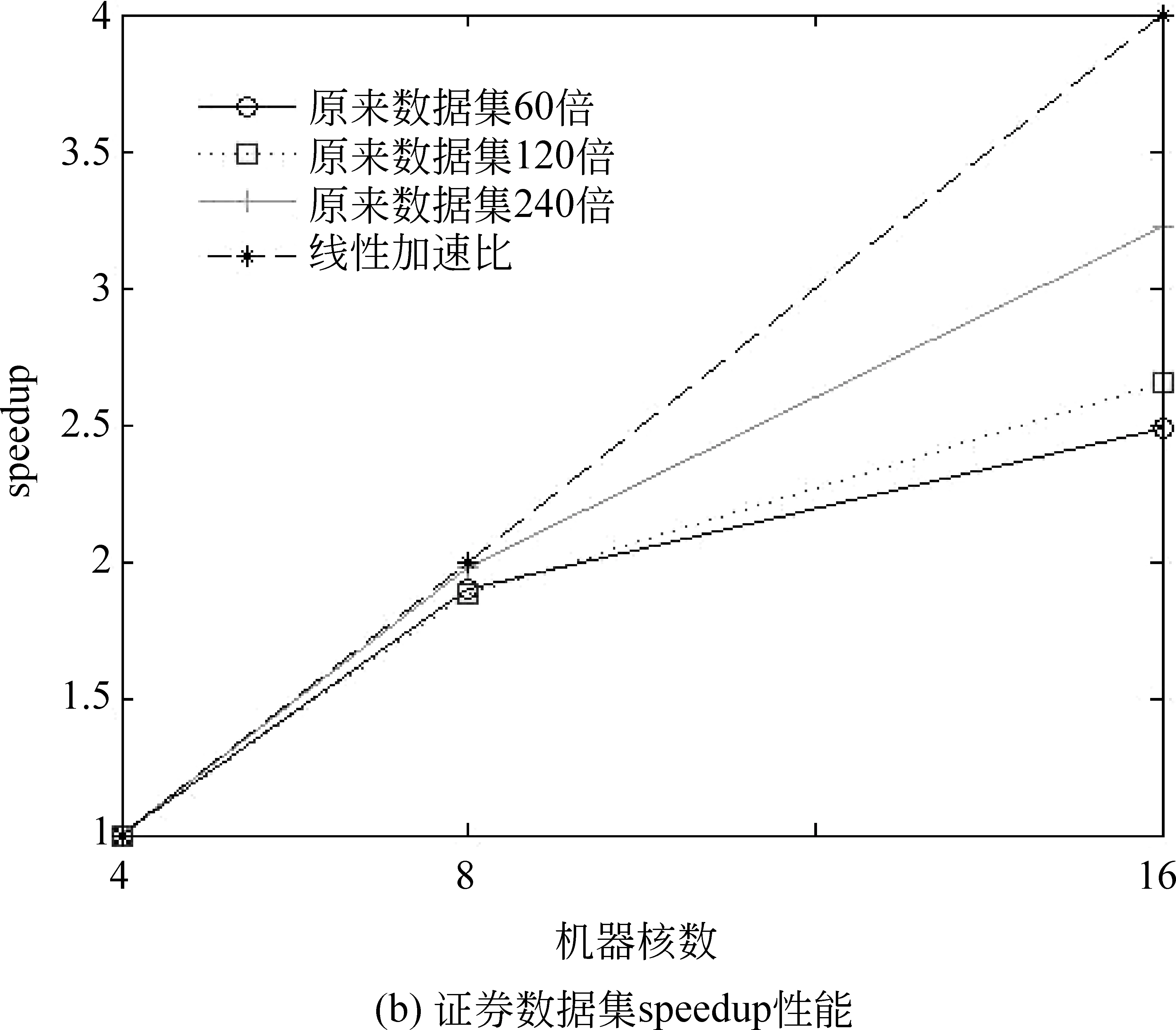
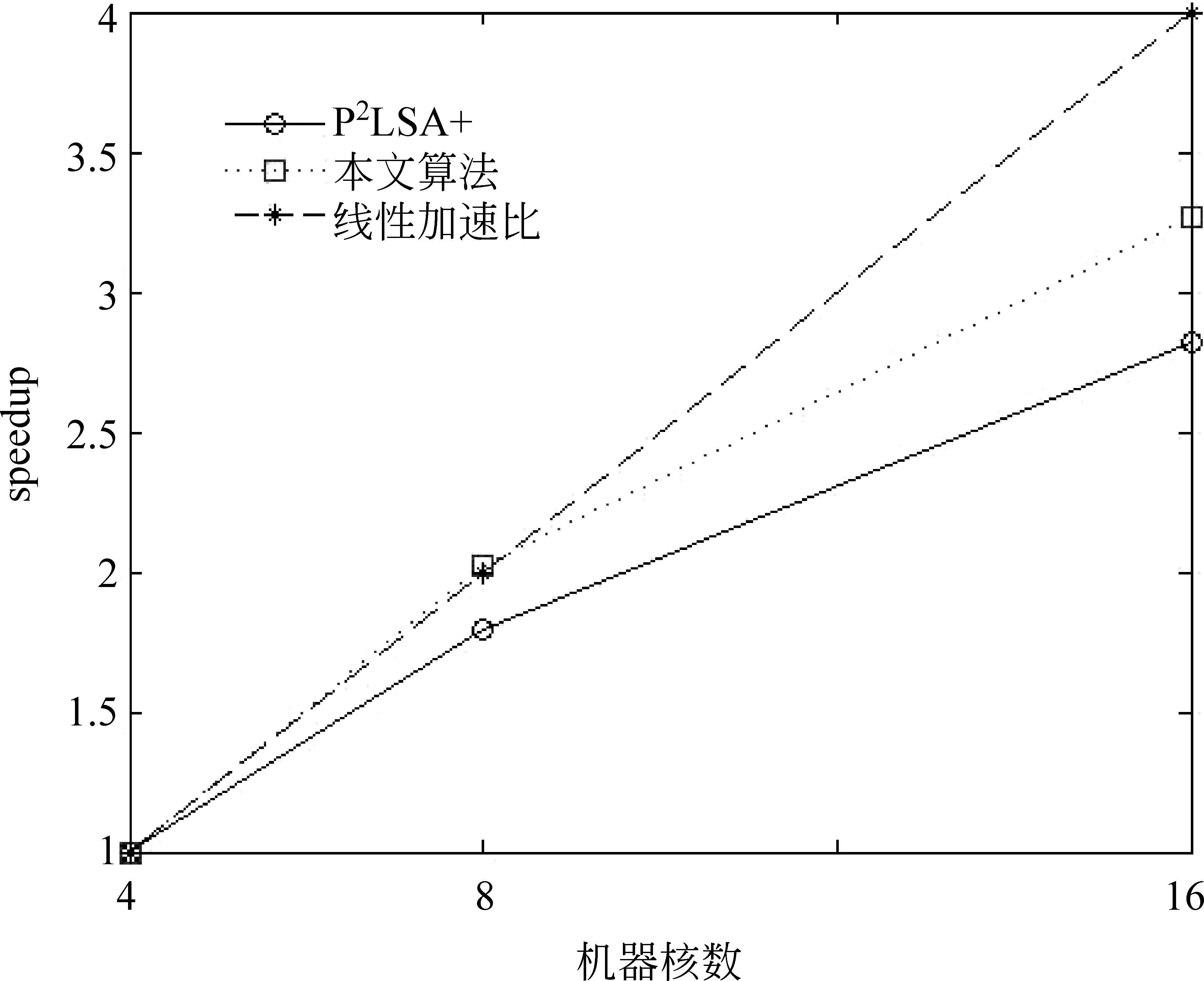
CountAMapperMap(key,value)輸入:pz,pdz,pwz,,偏置key,字符串value輸出: CountAReducer Reduce(key,value)1.初始化計數器sum=0;2.for(Textvalue:values)3. sum+=value/?對具有相同key值的value值求和?/4.end5.輸出(key,sum); CountRMapper Map(key,value)輸入:偏置key,字符串value輸出: CountRReducer Reduce(key,value)1.初始化sum=0;2.for(Textvalue:values)3. sum+=value;4.end5.輸出(key,sum); 根據以上并行策略,我們給出完整的并行 PLSA 算法。如算法PPLSA所示。 算法PPLSA1.初始化p(z),p(w|z),p(d|z);2.執行計算R的job;3.for(circleID=1;circleID<=numCircle;circleID++)/?numCircle為最大循環次數?/4. 執行計算∑dAand∑wA的job5. 計算∑d,wA;6. 更新p(z),p(w|z),p(d|z);7.end8.輸出p(z),p(w|z),p(d|z). 為驗證所提出的并行PLSA算法的性能,我們將其置于云計算平臺上運行。實驗環境為由10臺計算機搭建的集群,我們選用其中的四個節點來運行,每個節點CPU配置為2.8GHz,內存為4GB。MapReduce系統所采用的Hadoop版本為0.20.2,Java版本為1.5.0_14。 4.1 實驗設計 文本聚類技術可以有效組織網絡文本、幫助使用者獲得他們想要的信息[20-21]。本文中,我們將并行PLSA算法應用于文本聚類和語義分析上。用于文本聚類的數據來源于從中興、華為主頁及相關論壇上采集的網頁文本。網址如下: http://www.zte.com.cn, http://www.huawei.com/cn, http://bbs.c114.net, http://www.hwzte.com。 對于語義分析,我們將證券相關網頁作為訓練數據,對給定的檢索詞,輸出與其主題相關的詞。對于一個文檔數據集,PLSA算法可以找到每個單詞所對應的主題并輸出相對應的概率值,我們可以由此找出每個單詞所對應的主題,即概率值取值最大的那個主題。從而建立單詞-主題-概率值這樣的映射關系。 建立映射之后,可以根據映射關系找到每個主題下所有的單詞及其所屬概率值,對于輸入的檢索詞,首先根據映射關系找到其所屬的主題,然后輸出這一主題下概率值最大的前幾個詞作為語義分析的輸出。 為了驗證并行PLSA算法在處理大數據集時的性能,我們選用兩個數據集來進行實驗,其中一個為TREC AP文檔集,包含2 246篇文檔,10 473個單詞。另一個為從證券相關網頁上采集到的網頁文本,包含216個html文檔,27 925個單詞。 性能指標方面,采用scaleup,sizeup,speedup來評價PLSA算法的并行性能。 Scaleup: 度量了不同處理器規模下,處理不同規模數據的性能。具體定義公式為式(10)。 Scaleup= (10) Sizeup: 度量了在平臺固定的情況下,不斷增大數據集時的性能。具體定義公式為(11)。 (11) Speedup: 度量了并行計算比串行計算加快的程度。具體定義公式為(12)。 (12) 為說明本文所提算法的高效性,與文獻[18]中的P2LSA+算法進行了時間上的對比。 4.2 實驗結果 4.2.1 在文本聚類中的應用 我們從中興、華為主頁及相關論壇上對網頁文本進行了采集,經過網頁解析,文本凈化,詞頻統計,向量表示,特征選取等預處理過程,將網頁文本表示成可以直接處理的向量。然后用并行PLSA對其進行聚類。表1列出了聚類結果,共聚出了10類文本,每類文本分別用10個詞來描述其主題。 表1 PLSA聚類結果 從表1中可以看出,PLSA算法可以很好的應用到文本聚類中。 4.2.2 在語義分析中的應用 我們對308個證券相關網頁進行處理,表2列出了所得到的結果。 表2 主題相關的語義分析結果 從此結果可以看出,PLSA算法可以找到在主題層面上語義相關的詞,而不單單是詞義相近的。 4.2.3 Scaleup 為驗證算法在多處理器下處理大數據集的性能,我們將原數據集擴大至原來的60倍,120倍,240倍,分別在4,8,16臺機器上運行。將四個節點的運行時間做為基準,所得到的scaleup性能如圖3所示。 圖3 Scaleup性能展示 從圖3中可以看出,隨著數據規模和節點規模的增大,所得到的scaleup曲線幾乎保持為常數1,顯示了很好的擴展性能。 4.2.4 Sizeup 為驗證算法的sizeup性能,我們分別固定節點數為4,8和16,對于每種固定節點,不斷增大數據規模,圖4展示了兩個數據集的實驗結果。 從圖4中可以看出,算法表現出了較好的sizeup性能,隨著數據規模的增大,性能提升也越明顯。原因在于,增大數據規模會增加I/O操作和文檔處理,使得非通信時間增大,進而導致通信時間在整個算法運行時間中的比例減少。而CPU處理又有著很好的擴展性能,因此我們得到了比較好的sizeup性能。 圖4 Sizeup性能展示 4.2.5 Speedup 我們用四核機器的數據作為基準來驗證加速比性能。結果如圖5所示。 圖5 speedup性能展示 從圖5可以看出,當核數比較少的時候,并行PLSA算法可以達到線性加速比。當節點數增長時,提高的性能并不明顯。原因在于隨著節點數增多,節點間相互通信的絕對時間增大,其在整個執行時間中所占比例也隨之增大。當計算時間減小時,增加節點數已經不能提高更多的加速比。 另外,算法在大的數據集上表現出了比較好的加速比性能。因為數據集增大,每個節點處理的數據量相應增加,計算時間在整個執行時間中所占比例提高,因此,算法可以有效地處理大數據集。 4.2.6 與其他方法的比較 如前所述,文獻[18]中提出了兩種并行策略P2LSA 和P2LSA+,后者比前者表現出了較好的并行效率,執行速度更快。本文針對240倍大小的AP數據集,在相同實驗環境下,用四核機器的數據作為基準,與P2LSA+進行了speedup的對比,結果如圖6所示。 圖6 與P2LSA+算法的speedup對比結果 由于本文所提算法用一個job來完成PLSA算法中的迭代過程,而P2LSA+則需要兩個job來完成,因此本文算法有著更好的并行性能,從圖6也可以看出,本文所提算法比P2LSA+顯示了更好的加速比性能。 針對串行PLSA算法難以處理大數據集的問題,本文提出了一種基于MapReduce的并行PLSA算法,并將其應用到文本聚類和主題語義分析中。實驗證明所提算法有著較好的并行性能,并且在聚類和語義分析中有著很好的應用。 [1] 宋曉雷,王素格, 李紅霞, 等. 基于概率潛在語義分析的詞匯情感傾向判別[J]. 中文信息學報, 2011, 25(2): 89-93. [2] Blei D M, Jordan M I. Modeling annotated data[C]//Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Los Alamitos: IEEE Computer Society, 2003: 127-134. [3] Monay F, Gatica-Perez D. Modeling semantic aspects for cross-media image indexing [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(10): 1802-1817. [4] Li Z-X, Shi Z-P, Liu X, et al. Automatic image annotation with continuous PLSA[C]//Proceedings of the 35th IEEE International Conference on Acoustics, Speech and Signal Processing. Los Alamitos: IEEE Computer Society, 2010: 806-809. [5] Mark Steyvers. Probabilistic Topic Models[C]//Proceedings of Latent Semantic Analysis: A Road to Meaning. Laurence Erlbaum,2007:420-440. [6] Scott CD, Susan TD, Thomas KL,et al. Indexing by latent semantic analysis[J]. Journal of the American Society for Information Science, 1990,41(6):391-407. [7] Hofmann T. Probabilistic Latent Semantic Analysis[C]//Proceedings of 15th Conference on Uncertainty in Artificial Intelligence, San Francisco: Morgan Kaufmann, 1999: 289-296. [8] Hofmann T. Unsupervised learning by probabilistic latent semantic analysis [J]. Machine Learning, 2001, 42(1): 177-196. [9] 張玉芳, 朱俊, 熊忠陽. 改進的概率潛在語義分析下的文本聚類[J]. 計算機應用, 2011, 31(3): 674-676. [10] Hong C, Chen W, Zheng W, et al. Parallelization and characterization of probabilistic latent semantic analysis[C]//Proceedings of Parallel Processing, 2008. ICPP’08. 37th International Conference on. IEEE, 2008: 628-635. [11] The Lemur Toolkit for Language Modeling and Information Retrieval. Available at http://www.lemurproject.org. [12] Wan R, Anh V N, Mamitsuka H. Efficient probabilistic latent semantic analysis through parallelization[M]Information Retrieval Technology. Springer Berlin Heidelberg, 2009: 432-443. [13] Hadoop: Open source implementation of MapReduce, Available: http://hadoop.apache.org, June 24, 2010. [14] Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters[C]//Proceedings of Operating Systems Design and Implementation, San Francisco, CA, 2004: 137-150. [15] Ghemawat S, Gobioff H, Leung S. The Google File System[C]//Proceedings of Symposium on Operating Systems Principles, 2003: 29-43. [16] Lammel R. Google’s MapReduce Programming Model—Revisited. Science of Computer Programming 70, 2008: 1-30. [17] 李銳,王斌.文本處理中的MapReduce技術[J].中文信息學報, 2012, 26(4):9-20. [18] Y Jin. P2LSA and P2LSA+: Two Paralleled Probabilistic Latent Semantic Analysis Algorithms Based on the MapReduce Model[C]//IDEAL 2011, LNCS 6936, 2011: 385-393. [19] Qiaozhu Mei, ChengXiang Zhai. A note on EM algorithm for probabilistic latent semantic analysis[C]//Proceedings of the International Conference on Information and Knowledge Management (CIKM),2001. [20] 趙世奇, 劉挺, 李生. 一種基于主題的文本聚類方法[J]. 中文信息學報, 2007, 21(2): 58-62. [21] 劉遠超, 王曉龍, 徐志明, 等. 文檔聚類綜述[J].中文信息學報, 2006,20(3): 55-62. MapReduce Based Parallel Probabilistic Latent Semantic Analysis for Text Mining LI Ning1,2,3, LUO Wenjuan1,2, ZHUANG Fuzhen1, HE Qing1, SHI Zhongzhi1 (1. The Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. University of Chinese Academy of Sciences, Beijing 100190, China; 3. Key Lab. of Machine Learning and Computational Intelligence, College of Mathematics and Computer Science, Hebei University, Baoding, Hebei 071002, China) PLSA((Probabilistic Latent Semantic Analysis) is a typical topic model. To enable a distributed computation of PLSA for the ever-increasing large datasets, a parallel PLSA algorithm based on MapReduce is proposed in this paper. Applied in text clustering and semantic analysis, the algorithm is demonstrated by the experiments for s its scalability in dealing with large datasets. probabilistic latent semantic analysis; MapReduce; text clustering; semantic analysis 李寧(1982—),博士,講師,主要研究領域為機器學習,數據挖掘,主題模型。E?mail:lin@ics.ict.ac.cn羅文娟(1987—),博士,主要研究領域為社交網絡,文本挖掘,個性化推薦。E?mail:wenjuan.luo@renren?inc.com莊福振(1983—),博士,副研究員,主要研究領域為遷移學習,機器學習與并行數據挖掘。E?mail:zhuangfz@ics.ict.ac.cn 1003-0077(2015)02-0079-08 2013-06-09 定稿日期: 2014-02-19 國家自然科學基金(61175052,61203297,61035003);國家863高技術研究發展計劃(2014AA012205, 2013AA01A606, 2012AA011003)。 TP391 A



4 實驗及在文本挖掘中的應用



5 結語
 猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24開放教育研究(2020年2期)2020-03-31 01:54:14制造技術與機床(2019年10期)2019-10-26 02:48:08電子制作(2018年18期)2018-11-14 01:48:06光學精密工程(2016年6期)2016-11-07 09:07:19現代語文(2016年21期)2016-05-25 13:13:44小學教學參考(2015年20期)2016-01-15 08:44:38大連民族大學學報(2015年2期)2015-02-27 08:28:11
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24開放教育研究(2020年2期)2020-03-31 01:54:14制造技術與機床(2019年10期)2019-10-26 02:48:08電子制作(2018年18期)2018-11-14 01:48:06光學精密工程(2016年6期)2016-11-07 09:07:19現代語文(2016年21期)2016-05-25 13:13:44小學教學參考(2015年20期)2016-01-15 08:44:38大連民族大學學報(2015年2期)2015-02-27 08:28:11
