維基百科中翻譯對的模板挖掘方法研究
2015-04-21 09:26:54段建勇閆啟偉
中文信息學報 2015年2期
段建勇,閆啟偉,張 梅,胡 熠
(1. 北方工業大學 信息工程學院, 北京 100144;2. 騰訊公司 搜索產品部, 上海 200230)
?
維基百科中翻譯對的模板挖掘方法研究
段建勇1,閆啟偉1,張 梅1,胡 熠2
(1. 北方工業大學 信息工程學院, 北京 100144;2. 騰訊公司 搜索產品部, 上海 200230)
雙語翻譯對在跨語言信息檢索、機器翻譯等領域有著重要的用途,尤其是專有名詞、新詞、俚語和術語等的翻譯是影響其系統性能的關鍵因素,但是這些翻譯對很難從現有的詞典中獲得。該文針對維基百科的領域覆蓋率和結構特征,提出了一種從維基百科中自動獲取高質量中英文翻譯對的模板挖掘方法,不但能有效地挖掘出常見的模板,而且能夠發現人工不容易察覺的復雜模板。主要方法包括三步: 1)從語言工具欄中直接抽取翻譯對,作為進一步挖掘的啟發知識;2)在維基百科頁面中采用PAT-Array結構挖掘中英翻譯對模板;3)利用挖掘的模板在頁面中自動挖掘其他中英文翻譯對,并進行模板評估。實驗結果表明,模板發現翻譯對的正確率達90.4%。
雙語翻譯對;維基百科;模板挖掘;信息抽取
1 引言
跨語言信息檢索(CLIR)提供了一種方便的途徑,使得用戶能夠使用自己熟悉的語言提交查詢,檢索另一種語言的文檔。CLIR中常見的方法有同源詞匹配、文檔翻譯、中間語言和查詢翻譯等[1]。查詢翻譯為CLIR中采用最廣泛的方法,查詢翻譯方法在檢索前采用各種資源將查詢翻譯成文檔集合所采用的目標語言,然后進行單語言查詢(MIR)。但是查詢中有很多詞為專有名詞(Proper Names),包括人名、地名等,還有新詞和專業術語,如果不能對這些詞進行正確的翻譯,會使不相關文檔排序較前,從而嚴重降低系統性能。因此未登錄詞(Out of Vocabulary,OOV)的查詢翻譯是影響CLIR性能的關鍵因素之一[2]。
維基百科作為自由、開放的在線百科全書,具有準確性高、領域覆蓋廣的優點。截至2012年8月8日,中文維基百科擁有508 701個詞條,這給未登錄詞的譯文挖掘提供了有利的條件[3]。大部分中文詞條均能通過語言工具欄找到對應的英文翻譯,這是較易獲得和可靠的可用資源。而詞條內容中也包含很多互為譯文的中英文翻譯對。通過挖掘這些潛在的雙語資源,可獲得大量的包括專有名詞、新詞、流行詞、俚語、術語的中英文翻譯對,支持查詢翻譯任務。
2 相關工作
雙語翻譯對挖掘是跨語言檢索中查詢翻譯的關鍵問題。根據所使用的資源不同,查詢翻譯的方法可具體分為:基于詞典的查詢翻譯方法、基于語料庫的查詢翻譯方法和基于搜索引擎的查詢翻譯方法。
基于詞典的查詢翻譯方法,是最簡單的CLIR技術。但是現有的雙語詞典均在充分性、可更新和適用多領域等方面存在局限。而人工添加詞條,雖然具有較高的準確率,但構建大規模的雙語詞典需要耗費大量的人力物力,而且覆蓋面依然受限。
基于語料庫的查詢翻譯方法。Huang等人[4]和Resnik等人[5]利用平行語料庫進行未登錄詞譯文的挖掘。Tao等人[6]和Talvensaari等人[7]利用從網絡挖掘的可比較語料庫進行未登錄詞翻譯。平行語料庫通常質量較高,但可用的平行語料庫很有限,且通常是具體領域的。可比較語料庫不存在互為翻譯關系,從中挖掘的未登錄詞譯文質量較低。文獻[3,5,8]均是首先從雙語網站中抽取雙語文檔,然后使用句子對齊技術,從中挖掘雙語資源。基于語料庫的翻譯方法存在的一個關鍵問題是如何自動構建大規模的、多領域的、及時更新的語料庫[3]。
基于搜索引擎的查詢翻譯方法: 一種是利用搜索引擎返回的鏈接列表,下載全文網頁,然后進行查詢的譯文抽取[9-10],這需要較大的帶寬和更大的存儲空間和更多的計算時間;另一種方法是僅利用搜索引擎返回的混合語言摘要信息進行查詢翻譯。限于復雜性考慮,大部分方法都是利用前N條返回數據,但對于N的值沒有固定的標準,總之,N遠小于搜索引擎的所有返回結果數。但是如果網絡數據中,低頻詞鮮有中英文翻譯對共現的情況,則很難通過搜索引擎找到其翻譯。使用搜索引擎抽取這樣的中英文翻譯對時,中英文共現的網頁出現在查詢結果列表前面的可能性會比較小。
很多研究者均發現東亞(包括中國、日本、韓國)的文本中,經常在專有名詞注釋相關的英文翻譯。Zhang[11]發現,如果英文出現在括號中,那么周圍的中文很可能是其對應的翻譯。她將出現在括號中的英文前面的中文分為兩種情況:一種是前面的中文出現在書名號或者引號當中;另一種是前面的中文不出現在書名號或者引號中。郭稷[12]等先對候選翻譯單元的中文部分進行分詞、詞性標注和命名實體識別,然后使用多種識別特征自動挖掘網站中存在的雙語翻譯對。但主要是處理的固定格式翻譯對,即英文出現在括號中時,其前面的中文出現在書名號或者引號中的中英文翻譯對。由于互聯網中雙語資源格式自由靈活,還有很多以其他形式存在的中英文翻譯對。羅陽[13]面向單一中日雙語網頁,使用以頻繁序列模板為特征的SVM分類方法。Jiang[14]利用網頁DOM Tree的結構特點,采用詞對齊的方法自動進行雙語資源的挖掘,并且允許不規則的噪聲片段。
部分研究者利用維基百科進行未登錄詞譯文的研究[3]。采用頻度變化信息和鄰接信息實現候選單元抽取,并建立基于頻度-距離模型、表層匹配模板和摘要得分模型的混合譯文挖掘策略。但是很多低頻詞不能通過維基百科提供的偽相關反饋獲得,或者不能獲得中英文詞共現的頁面。
本文利用維基百科語言工具欄和中文頁面的中英文翻譯對模板特點,抽取語言工具欄中雙語翻譯對作為啟發式知識,自適應挖掘條目內容中翻譯對模板,進而在條目內容中挖掘中英文翻譯對,對于候選翻譯對,結合多種特征對其準確性進行評估。
3 維基百科中的中英翻譯對考察
維基百科(Wikipedia)是一個自由、免費、內容開放的百科全書協作計劃。大部分的中文詞條都可以通過其語言欄中的多語言鏈接獲得對應的外文翻譯。維基百科在詞條所涉及領域的內容覆蓋方面,文獻[14-16]使用美國國會圖書館3 000篇隨機文章與維基百科的隨機詞條進行對比,大部分領域維基百科幾乎都很好地進行了覆蓋。文獻[15]統計了維基百科詞條數目在不同領域的具體分布,發現與傳統知識庫相比,其在專有名詞、新詞、流行詞、俚語、術語和新近事件等方面具有較大覆蓋優勢,較好地解決了雙語資源領域限制問題。
3.1 存在目標語言鏈接
當某中文詞條在語言欄中存在唯一對應的英文鏈接時,可以直接提取鏈接詞條的標題作為對應的翻譯。若中文條目只有重定向頁面,則暫時將重定向詞條的英文翻譯作為其翻譯,但需要經過進一步驗證,所以將其準確度設為0.9。總結存在目標語言鏈接分為兩種情況:
1) 無歧義的目標語言鏈接;
2) 只存在重定向頁面,而重定向后頁面語言欄中存在英文鏈接。

圖1 存在目標語言鏈接
例如,中文條目“數學”的語言欄中,存在英文鏈接,指向英文維基條目“Mathematics”,屬于第一種情況,將“Mathematics”作為“數學”的對應英文翻譯。中文詞條“歐盟”,是個重定向頁面,指向“歐洲聯盟”這個詞條,而“歐洲聯盟”頁面語言欄中,存在唯一英文鏈接,指向英文條目“European Union”,屬于第二種情況,將“European Union”作為“歐盟”的英文翻譯。
3.2 詞條頁面中存在中英翻譯對
詞條頁面中有些中英文翻譯對的格式自由靈活,很難通過固定的模板去匹配抽取,如圖2所示。

圖2 中文詞條“加利福尼亞”中職位翻譯對
由不同人編輯的頁面,采用的注釋風格往往不同,但對于單個頁面來說,其上下文中注釋風格具有局部效應。可以使用通用模板和個別模板相結合的方式在維基頁面中挖掘中英文翻譯對。
3.3 維基百科內容文件
維基百科提供了所有完整內容的電子文件,下載得到一個大的XML文件,其中包含了所有頁面的詳細內容。每個中文維基頁面均對應該XML中的一個page節點,每個page節點包含了條目的標題、最新版本的貢獻者、詞條內容等信息。與網頁中展示的不同,詞條內容中使用了維基百科自己的標記格式。雙中括號“[[”與“]]”之間的信息對應維基頁面中的超鏈接,“en”表示后面的字符為英文。詞條內容中包括了正文、信息框和語言欄等信息。雙語資源的挖掘主要是在正文和語言欄中抽取中英文翻譯對。
4 主要方法
將維基百科的中英文翻譯對挖掘環境分為兩種: (1)存在目標語言鏈接;(2)詞條頁面中存在中英翻譯的情況。針對這兩種情況,對維基百科中中英文翻譯對的挖掘也分為語言欄抽取、詞條頁面挖掘兩部分,下面分別介紹維基百科翻譯對抽取過程。
4.1 語言欄翻譯對抽取
對于語言欄中存在目標語言鏈接且沒有歧義的中文詞條,直接提取語言欄英文鏈接的題目作為其英文翻譯,即語言欄一次挖掘。而重定向頁面,獲取重定向詞條的英文翻譯作為其英文翻譯。首先從維基百科的XML文件中,解析出每個page節點,并將其存入數據庫中;然后逐條讀取page,抽取其語言欄中的英文鏈接。維基內容文件的page結構中,語言欄英文鏈接使用的是固定格式“[[en:英文詞]]”,抽取方法是使用正則表達式進行匹配。抽取過程如算法1。

算法1:語言欄抽取翻譯對算法輸入:維基百科XML頁面輸出:條目名稱所對應的英文翻譯①對于每一個維基詞條,獲取其條目內容。②如果條目中的語言工具欄中存在英文連接,則抽取英文連接的名稱,作為英文翻譯輸出。設置其狀態位為d1,表示已輸出。賦予權值為α。③如果是重定向頁面,設置其查詢重定向后的頁面的英文翻譯,作為英文翻譯輸出。設置其狀態位為d2,表示已輸出重定向翻譯。賦予權值為β。④重復步驟①,直到沒有未處理的條目為止。⑤對于狀態位沒有設值,且為重定向的頁面,再次查詢其重定向后頁面的英文翻譯,作為該條目名稱的英文翻譯,賦予權值為β。⑥此時語言欄挖掘結束,程序停止。
在抽取過程中參照文獻[18]中的策略將以下三種情況的詞對均移除: (1)中英文詞對完全相同;(2)英文詞條以數字開頭,如“245”、“300BC”、“1991 in film”;或者英文詞條匹配規則“List of .*”,例如,“List of birds”、“List of cinemas in Hong Kong”;(3)中文詞條只包含ASCII碼字符。
通過對維基百科2012年8月22日的XML進行初步處理,得到了524 592個中英文翻譯對。翻譯對的領域廣泛性得益于維基百科的對領域的覆蓋,包括了像“孫中山”、“高德納”這樣的人名,“亳州市”、“上海市”地名,還有“操作系統”、“自由軟件運動”、“諾貝爾獎”等專業術語等,作為下一步挖掘的啟發知識。
4.2 詞條頁面翻譯對模式挖掘
維基百科中的雙語資源具有一定的格式特征,通過匹配這些特征,可以挖掘出詞條文本中大部分的中英文翻譯對。本文提出了一種單詞驅動模型,即以中文文本中出現的英文單詞或詞組為中心,以其所在的語句為候選挖掘單元,進行候選翻譯對模板的識別和抽取,如圖3所示。

圖3 詞條中的中英文翻譯對的抽取過程
詞條中的中英文翻譯對的抽取過程,需要借助語言欄挖掘的結果。主要步驟有: ①候選模板記錄抽取: 利用已有雙語資源在文本中抽取中英文詞對共現的語句片段;②模板挖掘: 從候選模板記錄中利用Pat-Array挖掘模板;③中英文翻譯對挖掘,利用挖掘的模板,抽取文本中存在的中英文翻譯對;④模板啟發式評估,采用啟發策略優化模板抽取的結果。
4.2.1 翻譯模板的挖掘
主要①候選模板記錄抽取和②模板挖掘,這兩步是內容頁面翻譯模板抽取的關鍵環節。內容頁面中中英文翻譯對的一般形式是:
前綴字符 中文詞 模板中間字符 英文詞 后綴字符
符號化為: PREFIX ZH_WORD PATTERN_M EN_WORD SUFFIX
其中,PREFIX表示中英文翻譯對出現位置的前綴字符,ZH_WORD代表中文詞,PATTER_M表示模板中間字符,中英文翻譯對中間的符號,EN_WORD代表英文詞(或詞組),SUFFIX表示翻譯對出現位置的后綴字符。當然中文詞和英文詞的位置也可能顛倒。為方便討論,僅考慮前一種情況。
如果直接從文本中抽取前綴字符和后綴字符,將會發現前綴字符和后綴字符數量龐大,極端情況,整個翻譯對前面和后面的文本都可以作為前綴和后綴字符。從文本中獲取英文詞的對應翻譯往往需要分詞才能進行抽取,而分詞的準確性制約著模板挖掘的效果。如果把所有的中文詞和英文詞分別替換成ZH_WORD和EN_WORD,會發現中文詞的左鄰接熵和英文詞的右鄰接熵均較高。所以從模板中間字符(PATTERN_M)入手,利用從語言欄挖掘出的詞對作為啟發知識,進行模板抽取。
PAT-Array(又稱Suffix Array)是一種數據結構[17],被廣泛用在信息檢索領域。設S=s0s1s2…sn-1為長度n的字符串;Li=sisi-1…s0,Ri=sisi+1…sn-1,分別稱為字符串S中起始位置i的左右后綴字符串(Suffix String)。
在使用PAT-Array時只對目標字符抽取左右后綴字符串,分別對左右后綴字符串排序,然后抽取左右最長共有前綴(Longest Common Prefix,簡稱LCP)作為模板的左右邊界。對詞條中存在的中英文翻譯對的模板抽取過程如算法2所示。
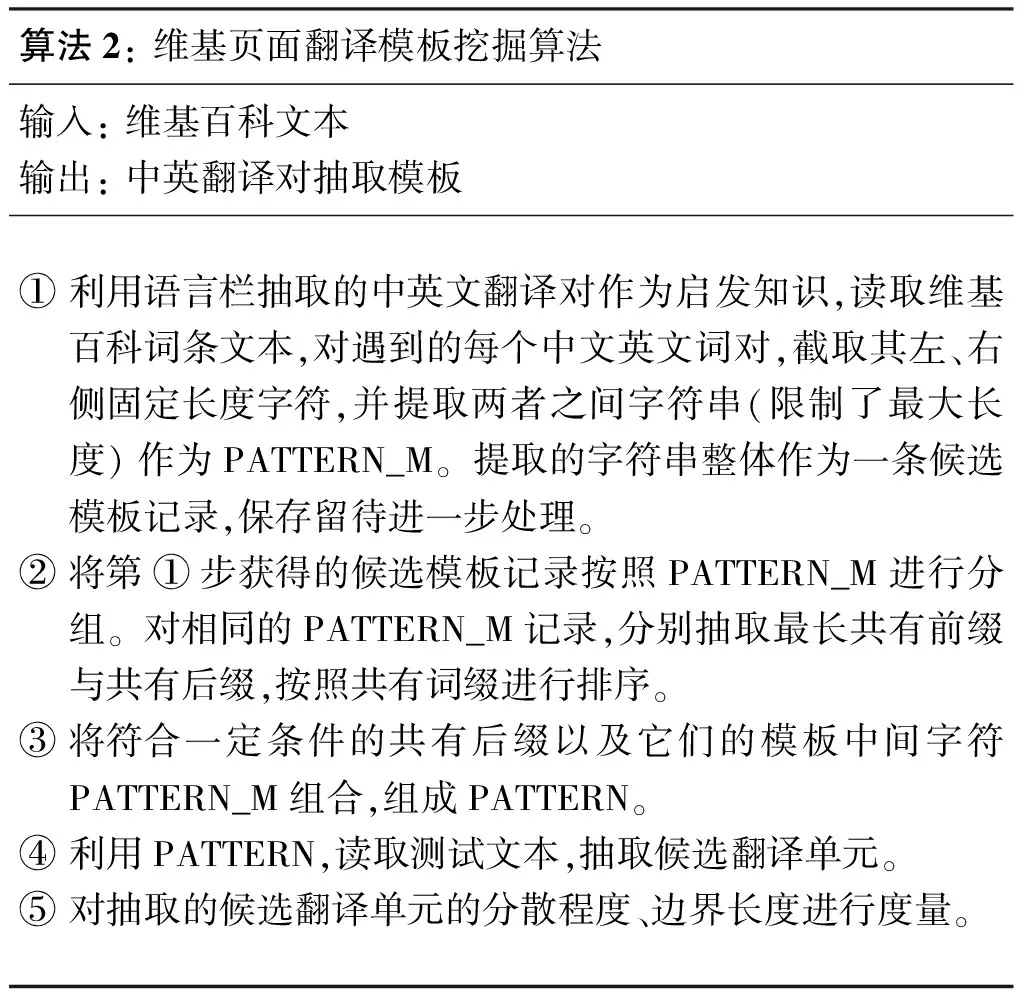
算法2:維基頁面翻譯模板挖掘算法輸入:維基百科文本輸出:中英翻譯對抽取模板①利用語言欄抽取的中英文翻譯對作為啟發知識,讀取維基百科詞條文本,對遇到的每個中文英文詞對,截取其左、右側固定長度字符,并提取兩者之間字符串(限制了最大長度)作為PATTERN_M。提取的字符串整體作為一條候選模板記錄,保存留待進一步處理。②將第①步獲得的候選模板記錄按照PATTERN_M進行分組。對相同的PATTERN_M記錄,分別抽取最長共有前綴與共有后綴,按照共有詞綴進行排序。③將符合一定條件的共有后綴以及它們的模板中間字符PATTERN_M組合,組成PATTERN。④利用PATTERN,讀取測試文本,抽取候選翻譯單元。⑤對抽取的候選翻譯單元的分散程度、邊界長度進行度量。
抽取最長共有前綴可能得到多個最長共有前綴,需要進行進一步的篩選。如何過濾掉低頻的邊界字符串,并且保留適量個數的邊界字符串來生成模板呢?也就是第⑤步的翻譯模板的量化評價,分兩步進行。
(1) 定義SUF_ENT為右邊界字符串的分散程度的度量值,其計算公式為式(1)。

(1)
其中numi為第i個右邊界字符串的頻次。同理定義左邊界字符串的分散程度PRE_ENT = info(num1,num2,numi…numn),使用信息論中的熵如式(2)所示。
(2)
左右邊界字符串的分散程度越低,表明相應的邊界字符串越固定,生成的中英文翻譯對模板越準確;反之邊界字符串越豐富,表明有多種翻譯對的模板中間字符串PATTERN_M相同。
(2) 定義LCP_NUM為保留的右(左)邊界字符串的個數,計算方法為式(3)。
(3)
對多個右(左)邊界字符串,按照頻次從高到低排序,只使用前LCP_NUM個生成翻譯對模板,其他的暫視為噪聲,可能是人為輸入錯誤或者其他原因導致的。
維基百科中很多專有名稱,雖然沒有對應的詞條,但是人為添加了超鏈接,不用分詞即可比較準確地獲取翻譯單元。例如,詞條“民族”中“印刷-資本主義”雖然沒有對應的中文詞條,但在XML文件中,標識了這可以創建詞條,對其進行特征匹配,獲取其英文翻譯為“print-capitalism”,是由Benedict Anderson提出的一種國家理論。這避免了分詞劃分邊界可能造成的無法找到正確的中文詞問題。
4.2.2 翻譯模板的啟發式評估
對抽取獲得的候選翻譯單元,需要進行評估,才能進一步確定其正確性。評估采用的評價特征,包括:
(1) PATTERN本身的頻度P_PATTERN。抽取中文維基百科前8 000個頁面得到,候選模板記錄14 361個,其中PATTER_M串“]](”的個數為2 603,分布在649個頁面中。而PATTERN_M串“]] ”共有409個,分布在61個不同的頁面中。因此PATTERN_M串“]](”的頻度和分布廣泛性要高于PATTERN_M串“]] ”。
(2) PATTERN中是否包含配對的符號。如果PATTERN中,包含配對的符號,例如前綴中有符號“(”,模板中間字符中包含“)”,則正確成詞的概率更高。
(3) 中文詞和英文單詞的長度比例。如果抽取的中文詞的長度過長或過短,其與英文互為翻譯的可能性越小。如果過長,需要截斷,如果過短,則需要向前擴展。語言欄抽取獲得136 397個中英文翻譯對,對這些中英文翻譯對的中文詞和英文詞的長度進行統計,中文詞的長度取漢字的個數,英文詞的長度為單詞的個數,得到中文詞和英文詞的平均長度比值為2.01,即一個英文單詞平均對應2.01個漢字。
(4) 利用簡易英漢詞典進行對齊。英漢詞典中僅包含常用英文單詞或詞組的中文翻譯,對于組合詞,拆分后查詢英漢詞典,可以對其正確性進行評估。對于中文詞長度過長或過短的情況,需要進行截斷或者向前擴展,以已有的中英詞典為基礎,對英文單詞或詞組進行直譯,并利用標點符號,對候選挖掘單元進行分割。實驗中使用的英漢簡易詞典,包含18 016個常見的英文單詞或詞組。另外,對于英文詞中包含數字,而對應的中文詞中不包含數字或者數字的英文,可以將這樣的候選翻譯對過濾掉。
5 實驗結果及分析
5.1 實驗數據 實驗所使用的數據是中文維基百科截止2012年8月22日的所有頁面,包括詞條頁面和重定向頁面。下載的源文件zhwiki-20120822-pages-meta-current.xml.bz2,大小為934MB,解壓后大小為4.99 GB,對其進行分割和解析,共獲得890 579個頁面節點。
5.2 實驗結果
從語言欄翻譯對挖掘、頁面中翻譯模板挖掘及其翻譯對抽取方面進行三個實驗。
5.2.1 語言欄翻譯對挖掘實驗
從語言欄中抽取得到524 592個中英文翻譯對。語言欄一次挖掘和通過重定向得到的翻譯對情況如表1所示。

表1 語言欄挖掘結果
可以看出,重定向獲得的翻譯對占了比較大的一部分。說明保留重定向頁面的翻譯是很有必要的,這能夠降低跨語言信息檢索時的未命中率。
將從維基百科語言欄中挖掘的中英文翻譯對與LDC 2.0*美國語言數據聯盟(The Linguistic Data Consortium簡稱LDC)由大學、公司及政府研究部門于1992年建立的非盈利組織。的數據重合度計算得到。

表2 語言欄挖掘數據與LDC 2.0比較
其中的LDC 2.0的數據,是綜合了中英和英中兩個詞典后的數據。LDC詞典是人工編制的,比較耗費人力。從維基百科語言欄中挖掘的中英文翻譯對中,與LDC 2.0重合的部分只占很小一部分,其他絕大部分均是像LDC這樣的詞典所沒有的,維基百科中的翻譯對在跨領域方面表現出了較好的覆蓋性能,而且維基百科本身是動態增長,挖掘其中的翻譯對在查詢翻譯等方面的意義非常大。
5.2.2 頁面中模板挖掘實驗
取前10 000個頁面作為頁面挖掘的數據,使用其中80%,即8 000個頁面進行模板抽取,剩余2 000個頁面進行后期抽取翻譯對的評估測試。
利用語言欄挖掘獲得的中英文翻譯對作為啟發知識,對8 000個頁面進行模板抽取。共得到14 361個候選模板記錄。其中不相同的PATTERN_M個數為4 875。去掉只出現一次的低頻序列和只適用于單個頁面的序列,以及PATTERN_M中包含換行符的記錄。這些模板中間字符序列并不具備一般適用性。最終得到200個候選PATTERN_M。
這200個候選PATTERN_M中,大部分均與人的直覺相符,并且發現了一些人工不易察覺的模板。對這200個候選PATTERN_M進行分組,分別抽取后綴字符和前綴字符的LCP,最終利用后綴字符和前綴字符的最長共有前綴和對應的模板中間字符PATTERN_M組合,得到用于抽取的PATTERN個數為241個。表3為部分模板。

表3 挖掘得到的部分中英文翻譯對模板

續表
5.2.3 模板方法挖掘翻譯對的性能評價實驗
本文使用了241個通用模板,在2 000個頁面中進行抽取。得到5 424個中英文翻譯對。我們同時考察了針對具體頁面的抽取過程,發現相同類型頁面所使用的模板具有相似性,這為后期結果優化提供了很好的支撐。
隨機選取其中200個頁面進行人工驗證。采用的評測標準是正確率、召回率和候選包含率。正確率評價指標計算公式為式(4)。

(4)
其中,n表示200個頁面中抽取得到的正確的中英文翻譯對個數。N表示200個頁面抽取得到的
所有翻譯對個數。召回率評價指標計算公式為式(5)。
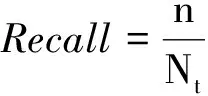
(5)
其中,Nt為人工查看200個頁面得到的中英文翻譯對個數。候選包含率評價指標公式為式(6)。
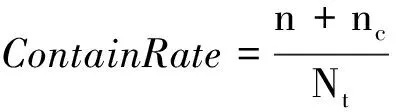
(6)
其中,nc為抽取的中英文翻譯對中包含正確的中文詞,但中文串長度過長的個數。實驗結果表明,從200個頁面中抽取出的428個中英文翻譯對結果如表4所示。

表4 未評估的實驗結果
計算得到Accuracy=76.63%,Recall=54.76%,ContainRate=63.44%。抽取的翻譯對中,存在一些錯誤的中英文翻譯對,主要原因是由于維基百科是由群體編纂的方式形成的,編寫風格上難免有不統一的地方,由機器學習抽取出來的模板在一些情況下可能會失效,需要對這些模板進行評估(表5)。

表5 錯誤的中英文翻譯對示例
錯誤類型1、2、4,計算中文詞和英文單詞的長度比例,可以檢測出異常。錯誤類型1、2,需要對翻譯對中的特殊字符,包括數字,橫線等是否對應;錯誤類型4,則一般需要向左進行截取獲取擴展。這需要借助簡易英漢詞典進行對齊,尋找正確的邊界;錯誤類型3,存在一個模板能夠獲取到正確的翻譯對,可通過比較沖突模板的頻率和是否包含配對的符號,過濾掉錯誤的翻譯對。
在翻譯對獲取任務中,為了獲取高質量的翻譯對,將準確率的閾值提高,但是這也同時會降低召回率。實驗加入中英文翻譯對的評估后,準確率由原來的76.63%提高到90.4%。結果表明通過翻譯對模板挖掘候選翻譯對,進行評估能得到較高質量的中英文翻譯對。
5.3 實驗結果分析及改進
實驗結果表明,利用模板抽取中英文翻譯對的召回率偏低。對未召回的情況,分析發現很多特征明顯的翻譯對未能正確抽取,初步分析是由于模板的數量不足導致。前面對8 000個頁面進行模板抽取,其中不相同的PATTERN_M個數為4 875,最終使用的候選PATTERN_M為200個,因此,設計如下兩組對比實驗查看模板的數量對實驗結果的影響。利用所有的890 579個頁面進行模板抽取,下表為前后兩次模板抽取的數據對比,如表6所示。

表6 模板抽取數據對比實驗結果
使用第二組實驗的6 103個模板,在所有 890 579 個page中進行挖掘,共得到候選翻譯對587 900個,進行中英文翻譯對評估后,剩余352 454個中英文翻譯對。
第一組實驗選取的200個頁面,采用相同的評測標準,統計得到: Accuracy=92%,Recall =67.8%, ContainRate =70.8%。
第二組實驗的結果表明,增加模板數,使翻譯對挖掘的召回率相比第一組實驗,提升了13%,而且準確率也有所提高。分析剩余的仍沒有被召回的翻譯對,發現超過三分之一的翻譯對,沒有明顯的符號邊界,屬于專業術語,還有部分是由于包含特殊字符不能通過模板獲取到。但仍有很多不相鄰的翻譯對模板,很難通過模板挖掘出來。
6 總結
本文介紹運用模板方法從維基百科中獲得高質量中英文翻譯對。首先從語言工具欄中抽取詞條的中英文翻譯對,這些翻譯對中絕大部分是人工編制的詞典中所沒有的;然后在詞條文本中利用抽取的翻譯對作為啟發知識,結合模板方法挖掘存在的中英文翻譯對。
未來的工作中有以下兩個地方需要研究: 首先,在詞條頁面翻譯對挖掘時,沒有保留所有的左右邊界字符串,這樣犧牲了召回率。如何在提高召回率的情況下,保證較高的準確率以及翻譯對模板數量增多時提高系統性能需要進一步探究;其次,中英文翻譯對評估時,應該加入音譯模型。
[1] JianYun Nie. Cross-Language Information Retrieval. Morgan & Claypool Publishers.2010.
[2] 孫常龍,洪宇,葛運東等.基于維基百科的未登錄詞譯文挖掘[J]. 計算機研究與發展,2011,6: 1068-1076.
[3] Lei Shi, Cheng Niu, Ming Zhou, et al. A DOM Tree Alignment Model for Mining Parallel Data from the Web[C]//Proceedings of the ACL2006, 2006: 1-8.
[4] Huang F,Zhang Y, Vogel S. Mining key phrase translations from Web corpora[C]//Proceedings of the ACL2005,2005: 483-490.
[5] Resnik P,Smith N A. The Web as a parallel corpus [J]. Computational Linguistics, 2003, 29(3):349-380.
[6] Tao Tao, Zhai Chengxiang. Mining comparable bilingual text corpora for cross-language information integration[C]//Proceedings of the KDD2005, 2005: 691-696.
[7] Talvensaari T, Laurikkala J, Jarvenlink, et al. Creating and exploiting a comparable corpus in cross-language information retrieval[J]. ACM Trans on Information Systems, 2007, 25(1):1-21.
[8] J-Y Nie, M Simard, P Isabelle et al. Cross-Language Information Retrieval Based on Parallel Texts and Automatic Mining of parallel Text from the Web[C]//Proceedings of the SIGIR1999, 1999:74-81.
[9] M Nagata, T Saito, K Suzuki. Using the web as a bilingual dictionary[C]//Proceedings of the ACL 2001 Workshop Data-Driven Methods in Machine Translation. 2001: 95-102.
[10] W H Lu, L F Chien,H J Lee. Translation of web queries using anchor text mining [J]. ACM Trans. Asian Language Information Processing(TALIP).2002, 1(2):159-172.
[11] Y. Zhang and P. Vines. Detection and Translation of OOV Terms Prior to Query Time[C]//Proceedings of the SIGIR2004, 2004: 524-525.
[12] 郭稷,呂雅娟,劉群.一種高效的基于Web的雙語翻譯對獲取方法[J].中文信息學報,2008,22(6):103-109.
[13] 羅陽,季鐸,張桂平,等.面向單一雙語網頁的雙語資源挖掘方法[J].中文信息學報,2011,25(1): 375-382.
[14] HALAVAIS A, LACKAFF D. An analysis of topical coverage of Wikipedia [J]. Journal of Computer-Mediated Communication, 2008, 13(2): 429-440.
[15] KITTUR A, CHI E H, SUH B W. What’s in Wikipedia? Mapping topics and conflict using socially annotated category structure [C]//Proceedings of the 27th International Conference on Human Factors in Computing Systems, 2009:1509-1512.
[16] 張海粟,馬大明,鄧智龍.基于維基百科的語義知識庫及其構建方法研究[J].計算機應用研究,2011,28(8):2807-2811.
[17] MANBER U, MYERSG. Suffix arrays: a new method for on-line string searches[J]. SIAM Journal on Computing, 1993, 22(5):935-948.
[18] D Lin, S Zhao, B Durme et al. Mining Parenthetical Translations from the Web by Word Alignment[C]//Proceedings of the ACL-08. 2008: 994-1002.
Mining Translation Pairs with Learnt Patterns from Wikipedia
DUAN Jianyong1,YAN Qiwei2,ZHANG Mei1,HU Yi2
(1. College of Information Engineering, North China Univesity of Technology, Beijing 100144, China; 2. Searching Product Section, Tencent Corporation, Shanghai 200230,China)
Bilingual translation pairs play an import role in many NLP applications, such as cross language information retrieval and machine translation. The translation of proper names, out of vocabulary words, idioms and technical terminologies is one of the key factors that affect the performance of the systems. However, these translations can hardly be found in the traditional bilingual dictionary. This paper proposes a new method to automatically extract high quality translation pairs from Wikipedia based on the wide area coverage and data structure, the method not only can learn common patterns, but also learn many patterns that can hardly be found by human beings. The method contains three steps: 1) extract translation pairs from the language toolbox of the Wikipedia. They can be heuristic for the next step; 2) learn patterns of translation pairs with the knowledge of PAT-Array gained from the previous work; 3) extract other translation pairs automatically using the learned patterns. Our experimental results show the accuracy can reach 90.4%.
bilingual translation pairs; Wikipedia; pattern mining; information extraction

段建勇(1978—),博士,副教授,主要研究領域為中文信息處理。E?mail:duanjy@hotmail.com閆啟偉(1989—),碩士研究生,主要研究領域為中文信息處理。E?mail:593202314@qq.com張梅(1980—),碩士,講師,主要研究領域為中文信息處理。E?mail:javoncool@163.com
1003-0077(2015)02-0190-09
2013-07-12 定稿日期: 2013-10-22
國家自然科學基金(61103112);北京市哲學社會科學規劃基金(13SHC031);北京市青年拔尖人才培育計劃(CIT&TCD201404005);國家語委十二五規劃基金(YB125-10)。
TP391
A
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
鄱陽湖學刊(2016年6期)2017-01-16 13:05:41
中國遠程教育(2016年6期)2016-12-07 10:07:02
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
財經(2016年19期)2016-08-11 08:17:03
中國遠程教育(2016年5期)2016-06-29 10:13:42
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
